| Oracle Retail AI Foundation Cloud Services Implementation Guide Release 22.2.401.0 F72321-01 |
|

 Previous |
 Next |
| Oracle Retail AI Foundation Cloud Services Implementation Guide Release 22.2.401.0 F72321-01 |
|
Previous |
Next |
This chapter describes the Advanced Clustering application. It provides details on configuration and implementation.
Advanced Clustering (AC) lets users create store clusters based on common features such as customer demographics in order to manage merchandise assortments and pricing strategies in a targeted way. Clusters can help retailers understand who shops in their stores and what their preferences are. Clusters can be used to inform decisions about assortment, pricing, promotion, forecasting, allocation, and supply chain processes based on selling patterns in stores. An understanding of the characteristics of the customers who shop in a store and what they buy can help a retailer target specific customers
The application optimizes clusters in order to determine the minimum number of clusters that best describes the historical data used in the analysis and that best meets the business objectives defined when the clusters are designed. Users can define a hierarchy cluster of stores based on a store attribute such as format and then cluster further using performance attributes in order to determine which stores have high, medium, and low sales. What-if scenarios and ranking can be used to compare how cohesive and well separated clusters are in each scenario as the number of cluster centers is increased. The application uses scoring to indicate which clusters fall below defined thresholds and may require manual intervention. Business Intelligence graphics illustrate the patterns in the data and the attributes that are important in each cluster.
The key features available in AC are:
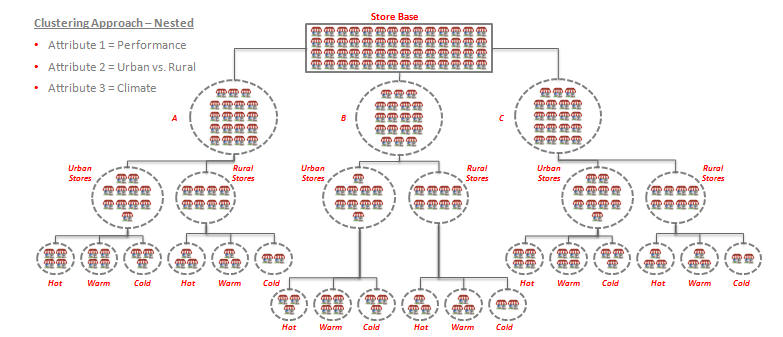
Dynamic nested clustering, in which a user can cluster on a criteria, analyze the results, and then decide whether or not to further sub-cluster.
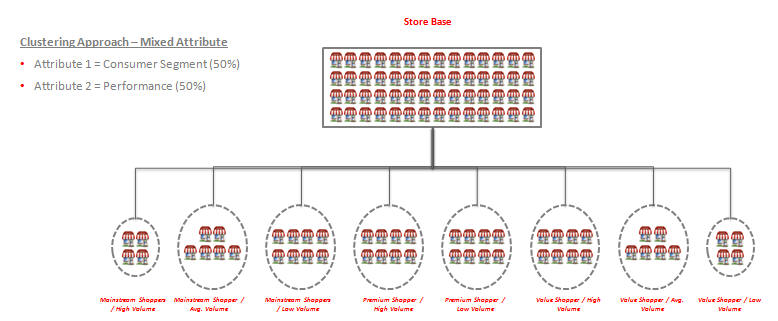
Mixed attribute clustering. A cluster can be created on continuous attributes such as performance (sales, revenue, and gross profit) as well as discrete attributes such as store size, demographics, and seasonality, all at the same time.
Configurable clustering criteria such as customer profiles, product attributes, performance, and store attributes.
Recommendations are made for the optimal number of clusters and the scores for each cluster. These are based on the quality of the clusters: how cohesive and well separated the clusters are.
Advanced Clustering relies on following data and it uses ETL to load the data.
Table 6-1 Data Requirements
| Objects | Granularity | Required/Optional |
|---|---|---|
|
Hierarchies |
Product, Location, and Fiscal |
Required |
|
Location Attribute |
Store |
Required |
|
Product Attribute |
SKU |
Required |
|
Aggregate Sales Data |
Week/SKU/Store |
Required |
|
Customer Segment Profiles |
Store/Customer Segment/(Category or All Merchandise) |
Optional |
|
Alternate Hierarchy |
CM Group or Trade Area |
Optional |
|
Like Locations |
Store |
Optional |
|
Product Attribute Group and Value |
Category or Subcategory |
Optional |
|
Aggregate Forecast Sales Data |
Week/SKU/Store |
Optional |
Store clusters can be generated for the following combinations of hierarchies.
Product Hierarchies
This includes:
Core merchandise hierarchy
Alternate hierarchy
Clusters can be defined for either of the hierarchies and for different hierarchy levels. For example, clusters can be defined for Chain, Department, or Category along the product hierarchy.
Note that store clustering can only be defined for a product hierarchy level higher than Item. Item level store clustering is not supported. However, store clusters can be generated for item groups by defining an item group as a level in the alternate hierarchy.
Location Hierarchies
This includes:
Core location hierarchy
Alternate hierarchy (optional)
Clusters can be defined for either of the hierarchies and for different hierarchy levels. For example, clusters can be defined for Chain, Trade Area, or Region along the location hierarchy. Store clusters can be generated for channel, if channels are configured as a level in the location hierarchy.
Calendar Hierarchies
This includes:
Core fiscal calendar hierarchy (week, month/period, quarter, half, year)
Gregorian calendar (week, month, quarter, half, year). Leverages a start and stop date (day level date range)
Planning period. Leverages alternate hierarchies, including planning period, buy periods, and defined holiday time periods such as back to school and fourth of July. This is optional.
Clusters can be defined for any of these three calendar hierarchies (the cluster effective period). Note that the source time period for historical data only uses the core fiscal calendar hierarchy, supporting hierarchy levels that include week, month/period, quarter, half, and year.
In store clustering, the cluster criteria are a set of attributes that define store clusters. These attributes can be either discrete or continuous. A group of these clusters is called "Cluster by." For example, demographic data such as income and store properties such as store formal can be grouped into a store attribute Cluster by.
These default Cluster by are supported.
Customer Profile
Stores are clustered based on the similarity in the mix of customer profiles shopping in the stores and trading areas. These clusters form the basis for further analysis to understand which customers shop in which stores and how they shop. Retailers obtain market data from market research firms such as the Nielsen Corporation and use the data to create customer profiles for their stores. An application feed can be used to provide this information to AC at the category or all merchandise level.
Location Attribute
Stores are clustered based on how shopping behavior varies by store attribute. This provides information about who is shopping in a store or trading area as well as demographic data such as ethnicity, income levels, education, household size, and family status. Retailers can analyze the cluster composition and related business intelligence in order to better understand the shopping behavior of their customers. This can help retailers make assortment and pricing decisions.
Product Attributes
In this type of clustering, stores are grouped together that have similar sales shares for one or more product attributes (for example, coffee brands such as premium, standard, and niche). The percentage of each store's contribution is calculated using the Sales Retail $ for each product attribute value to the total retail sales of the category or subcategory of each location.
Product attributes can be configured only at category or sub-category levels.
Performance Criteria
Stores are clustered based on historic sales by considering performance at different merchandise levels while performing store clustering and analyzing how the shopping behavior varies by category. This can help to identify high, medium, and low volume stores.
Forecast Criteria
Stores are clustered based on forecast sales by considering future sales at different merchandise levels while performing store clustering and analyzing how the shopping behavior varies by category. This can help to identify high, medium, and low volume stores based on the predicted sales.
Mixed Criteria
Discrete and continuous attributes are combined together. Retailers can cluster stores using attributes from all the above defined criteria at the same time.
Cluster by uses a collection of attributes, including consumer profile attributes, sales metric attributes, location attributes, and product attributes.
Sales Metrics
Store clustering uses a fixed set of sales metrics. These attributes cannot be extended. Supported attributes include Sales Retail $, Sales Unit, Sales AUR, Gross Margin R, and Gross Margin %.
Forecast Sales Metrics
Store clustering uses a fixed set of predicted sales metrics. These attributes cannot be extended. Supported attributes include Forecast Sales Retail $, Forecast Sales Unit, Forecast Sales AUR, Forecast Gross Margin R, and Forecast Gross Margin %.
Location Attributes
Store clustering relies on location attributes that can loaded into the application as either core attributes or as user-defined attributes. These attributes are defined for stores. They define the store properties, including demographic and geographic details. During installation, only attributes that have 15 distinct values are configured. Attributes with higher discrete values are not considered for store clustering.
Product Attributes
Product attributes based on store clustering use two types of attributes, raw attributes and grouped attributes. The former are product attributes, identified as important attribute values. The latter are fed into the application and are available to the store clustering process only when the CDT application is enabled. The clustering process groups together stores that have similar attributes values for a product category. A store share is calculated using Sales Retail $, which is the ratio of the sales retail of each product attribute value to the total sales retail of the category or subcategory of the specific location.
Each category or subcategory must have raw attributes and grouped attributes.
Grouped attributes (the default) classify the items in the class or subclass. This set of attributes differs from class to class. For example, for yogurt, the attributes are: size, flavor, brand, fat percentage, and pack size. For chocolate, the attributes are: size, brand, milk/dark, nut type, and package type. The two classes can both have the attribute of brand, but the brand attribute will have different values for each of the categories. Group attributes have a mapping of each item in the category to its set of attribute values. This information is provided as a data feed to the application. If grouped attributes are not available then raw attributes are used for the store clustering of product attributes.
Raw attributes typically have a large number of attribute values. For example, the brand attribute for yogurt may list 50 different brands at a large grocer. Using raw attributes, the system runs a preprocess to identify n (default = 3) attributes values that are most frequently sold for each attribute in a category or subcategory.
Default configuration occurs during the installation and upgrade. The configuration process is responsible for installing or upgrading any new attributes in the application. This process ensures that any existing manual overrides introduced by the retailers are not overridden and any new additions are brought into the clustering process. The default configuration includes the following:
All attributes are enabled by default and weights are normalized among all the configured attributes.
Any discrete location attribute that has more than n=15 attributes values is not configured by default. Note that the value of n is a configuration and can be modified at the time of deployment.
The UI formatting of each attribute is identified based on the data type of the attributes.
Nesting is enabled by default for all types of Cluster by (except mixed, which is an alternative approach to clustering).
The deployment of clusters at multiple hierarchies or levels is enabled.
The following configurations may require manual overrides if the default configuration is not acceptable or data is not available.
Table 6-2 Manual Overrides
| Name | Description |
|---|---|
|
Enable or disable Cluster by |
Disable Cluster by. For example, for the consumer profiles for each store for a retailer, the Cluster by for the consumer segment must be turned off. |
|
Enable or disable nesting |
Allow multiple nesting levels under an existing Cluster by. For example, cluster first by product performance, with nested clustering by store attributes. |
|
Enable or disable attributes |
Enable an attribute to be considered for clustering or contextual BI. For example, label the population density attribute as a BI attribute instead of a clustering attribute, as very few stores have data for population density, and it is not significant enough for store clustering. |
|
Change UI formatting |
Change formatting associated with the attributes, such as label, decimals, percent, and currency. These are configurations for each attribute and do not rely on XLIF entries. |
|
Cluster deployment |
Enable or disable hierarchy at which clusters can be deployed. For example, if CMPO store clusters are only defined for categories, then only clusters at the category level will be approved. The other levels can be enabled if needed. |
|
Outlier Rule |
Change default outlier rules for a Cluster by. By default, the distance from centroid rule is enabled. See section below for other supported outlier rules. |
|
New Store Rule |
Change default store rules for a Cluster by. By default, the like location rule is enabled. See section below for other supported new store rules. |
Table 6-3 Enable or Disable Cluster By
| Cluster By | Description | Example | Enable |
|---|---|---|---|
|
Customer segment profile |
Cluster store using consumer segment distribution |
20% soccer mom, 30% empty nesters |
Enable if consumer segment profiles are available for each store. |
|
Store attribute |
Cluster store using location attributes |
Income, climate, size, store format |
Enable if location attributes are available for each store |
|
Performance |
Cluster store using sales metrics |
Sales revenue, sales unit, gross margin $ |
Enable if retailer wants to cluster store using performance metrics |
|
Product attribute |
Cluster store using product attribute sales shares |
Brand, color, seasonality, size/fit |
Enable if retailer wants to cluster store using product attributes sales share |
|
Mixed attributes |
Cluster store using mixed attributes, combining attributes across all the cluster criteria |
Income, climate, size, store format, sales revenue, sales unit, gross margin |
Enable if retailer wants to cluster store using combination of attributes |
|
Product forecast |
Cluster store using predicted sales metric |
Forecast sales revenue $, forecast sales unit, forecast gross margin $ |
Enable if retailer wants to cluster store using future sales metrics |
Advanced Store Clustering supports copying clusters from other products by defining like product mapping. Some of a retailer's products, such as tea, may not be mature enough, so the retailer must copy clusters from a mature category such as coffee. The solution copies clusters that have already been approved from that category to a new category and then make the clusters available to the execution solution during export. This feature also supports the requirement in which categories in certain departments may want to borrow clusters from a higher product hierarchy such as Department or Division. In both use cases, clusters must be borrowed from another product (department or category) with minimal effort by the end user to define and approve the cluster criteria.
The retailer can define a like product interface that the retailer can use to provide mapping between a mature product and a new or poorly performing product. This product mapping can vary by location (for example, the tea category mapped to coffee in Trade Area East, and mapped to other beverages in Trade Area West).
This category mapping is selected automatically during export, based on the like products, and is assigned clusters from the mapped category that have already been approved by the end user. Cluster copy will respect product mapping if it is updated or removed using the effective period, and exports will be generated accordingly. Retailers can review the cluster composition of the mapped category via the UI from which it is borrowing the clusters; however, the copied clusters for the category will not be available for the user to review in the UI.
The Copy Clusters feature using like product mapping is only supported for the basic Store Clustering interface that is available for Oracle Retail Predictive Application Server applications such as Category Management; it is not be supported as part of the Store Clustering generic interface or the REST API.
Store clustering supports three types of clustering: simple, nested, and mixed. By default, all three approaches are enabled. These approaches are applicable to all Cluster by. Store clustering functionality supports dynamic nesting capabilities. For example, the user can cluster on a criteria, analyze the results, and then decide to further sub-cluster.
Mixed attribute clustering is also supported. For example, it is possible to cluster on continuous attributes such as performance (sales, revenue, and gross profit) as well as discrete attributes (store size and demographics) at the same time.
Simple
Users can select attributes from a Cluster by. For example, users can select location attribute Cluster by and generate clusters using location attributes such as store size.
Users select the most important store attribute (based on category) and group the stores accordingly. Clusters may or may not cross trade areas, regions, and districts.This depends on the approach as well as the responsibility of the planning team.
Nested
All Cluster by, except Mixed Attributes, can use a nested hierarchy by default. For example, performance clusters can be further clustered using location attributes. This approach allows a dynamic hierarchy of clusters. Nesting can be enabled or disabled in the AC configurations.
Users can select the most important store attributes (based on the category and the group of stores selected during the wizard process) and group the stores accordingly to ensure that a more refined assortment can be created by category or location selection. Clusters may or may not cross trade areas, regions, and districts. This depends on the approach as well as the responsibilities of the planning team. Once the initial clusters are created, users can further cluster using attributes to define nested clusters. This can be done within a trade area as well as at the total company level. The number of clusters is granular, as compared to mixed attributes.
Mixed
Mixed attributes, including Cluster By such as consumer segment, location attributes, performance, and product attributes, are supported by default. Users can combine attributes from different Cluster by. For example, users can combine attributes from consumer segment and performance Cluster by and generate clusters using sales revenue and consumer segment distributions.
Users can use the most important store attributes (based on the category and the group of stores selected during the wizard process) and group the stores accordingly. Clusters may or may not cross trade areas, regions, and districts. This depends on the approach as well as the responsibilities of the planning team. These clusters are the final ones used in assortment process. The number of clusters in this case is confined, compared to the nested clustering approach.
Store clustering supports three rules for allocating new stores to a cluster. These rules can be configured for each Cluster by. A rule is applied after the clusters are generated.
These rules require a feed into the application that defines a mapping between a location and like locations. This mapping can be configured by merchandise. One location can be mapped to multiple locations with different weights.
Like Stores (Default Rule)
Stores with new history or poor history are allocated to the same cluster in which the like locations are allocated. For example, a new store or a store whose poor history has been corrected can be allocated to a valid performance cluster.
Largest Clusters
New stores or stores with a poor history can be allocated to the largest cluster identified by the clustering analytics. For example, a new store that has not yet formed a customer base can be allocated to a larger cluster until significant customer profiles have been collected.
Cohesive Clusters
New stores or stores with poor history are allocated to the most compact cluster identified by the clustering analytics. For example, stores can be assigned to a cluster that has not been not affected by outliers.
Store clustering supports two rules that identify stores as outliers in a cluster. These rules can be configured for each Cluster by. The rule is applied after the clusters are generated.
Distance from Centroid (Default Rule)
The distance from a store to the centroid is identified. If the distance is beyond a defined limit of the configured threshold from the centroid, then the cluster is identified as having outliers. The user must investigate such clusters.
Cluster Size
The percentage of stores that are allocated to certain clusters is identified. If they fall beyond a certain limit in comparison to total number of stores, the cluster is identified as having outliers. The user must investigate such clusters.
To use any reporting tool with an Excel file exported from Advanced Clustering, you may need to adjust the format. Here are some examples of possible formatting adjustments.
The Text column should remain as is.
If the Percentage column uses a percent symbol, then that symbol must be removed.
If the Currency column uses either commas or currency symbols, then those must be removed.
If the Number column uses commas, then they must be removed.