To enable CIC to make recommendations, predict outcomes, or raise warnings for large scale enterprise projects, you need to establish settings in the ML Workbench page of the CIC Administration application. The settings on this page control the data eventually displayed in CIC.
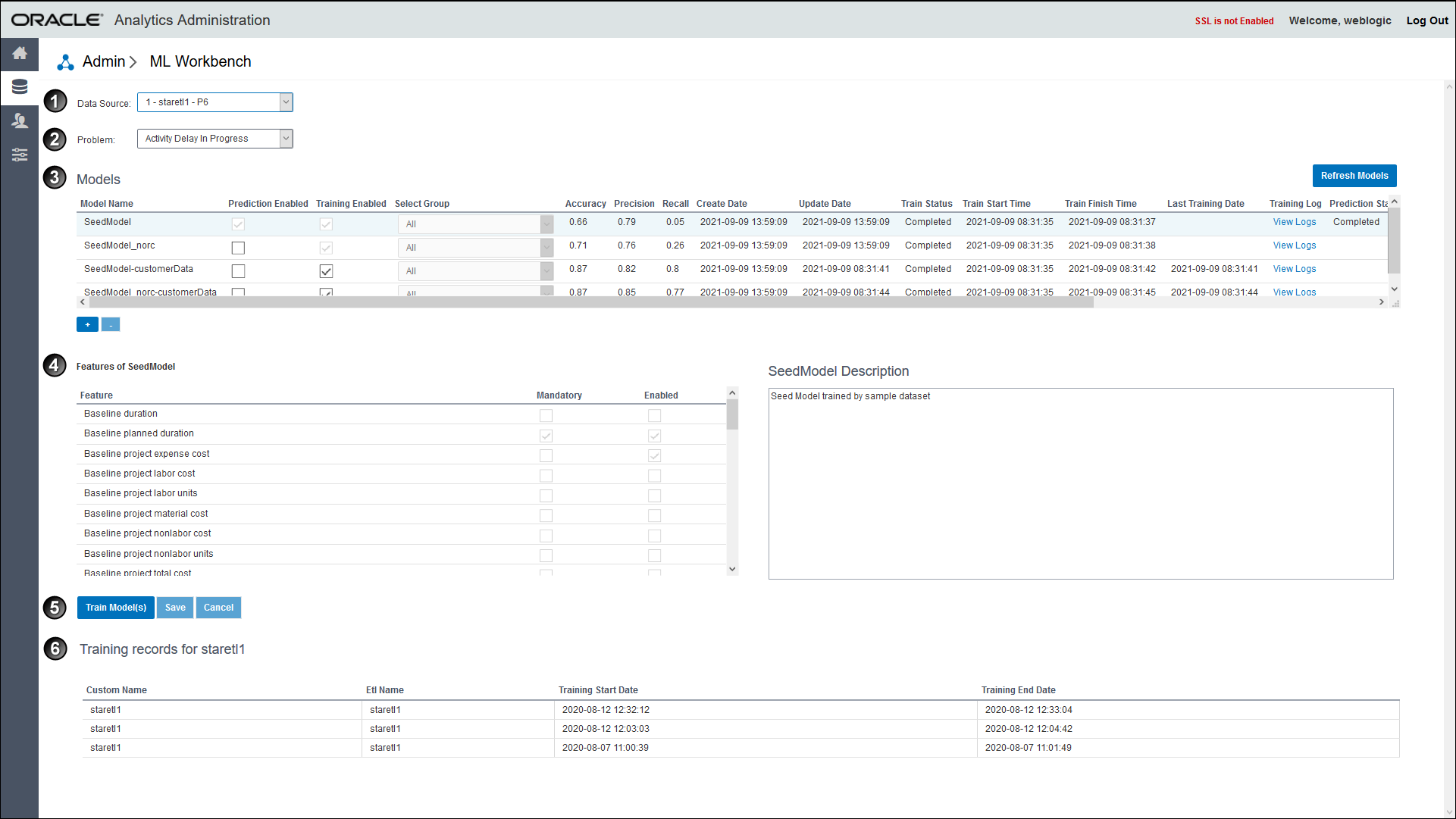
Item | Description |
|---|---|
1 | Data Source: The data from a source application that is being analyzed to predict future outcomes, success rate, risks, anomalies, etc. |
2 | Problem: The administration application delivers a set of predefined problems or scenarios for a product-specific data set. These problems represent recurrent issues and significant challenges that are widespread across the construction industry. |
3 | Models Table: Machine learning is a technique of data analysis that uses algorithms to analyze large sets of data to identify patterns in data. Models are machine-learning algorithms that generate predictions by finding patterns in data. You train a model to learn from a data set. A model can be generated to analyze each real-life problem in a data set. The inference from this analysis is built into a model. Additionally, multiple models can be generated to analyze a specific objective for a problem.
Note: Oracle recommends you retrain the model for each problem before using it for predictions. For each problem you can train multiple models simultaneously with a different combination of features selected in each model. However, you can only select one model for prediction for each problem. |
4 | Features of a Model: A feature is a characteristic or an attribute of the data set. Feature lists can vary for each problem identified in a data set. To analyze problems, specific combination of features can be enabled or disabled in a model. Therefore, you may create multiple models each associated and enabled with a different combination of features to analyze a problem. |
5 | Train Models: Train models with data and feature sets using seed models or existing custom models with new customer-specific training data set to learn from and provide better predictions. As the model learns, its accuracy also increases over time. Models are built using trends identified in the data from past projects. These models then serve as the engine that drives predictions. These models can be retrained through user feedback to identify patterns and trends specific to the way the organization chooses to run its projects thereby enhancing the accuracy of the predictions. Initially, you will need to make decisions for a data set when the application recognizes patterns in the data set. The application begins to learn from past decisions to predict outcomes. A vast data pool provides greater exposure to train a model. |
6 | Training records for staretl<n>: View the model training history executed for a selected data source. |