Creating Queries
You can create several types of queries to use with PeopleSoft Cube Builder, all of which you must define as user (ad hoc) queries rather than role queries or database agent queries.
Dimension queries enable you to define the dimension structure using query results instead of, or in addition to, a tree. However, remember that you are using queries to create a tree-like structure.
You can convey hierarchical information by parent/child relationship or by a narrow query.
In PeopleSoft Cube Builder, dimension queries can be dynamic or static. A dynamic query indicates that any incremental change in the tables that the query uses are reflected in the next run of PS2Essbase. A static query indicates that further changes to the tables used to create the first hierarchy will not be reflected unless the hierarchy is reloaded manually.
PeopleSoft Cube Builder uses dynamic queries to populate members at the leaf levels of a hierarchy and under the same parent.
Data source queries define the data that you bring into the cube. Writing a data source query is straightforward; the query must return one column for each dimension and one column for the measure. Assume that you want to build a data source query for a cube containing amounts that are dimensioned by account, department, and period.
The output of your query has four columns, as shown in the following table.
|
Account (Dimension) |
Department (Dimension) |
Period (Dimension) |
Amount (Measure) |
|---|---|---|---|
|
XXX XXX |
XXX XXX |
XXX XXX |
XXX XXX |
You can use several queries as the data source for a single cube, to load data into the measure. Every data source query that is used must include an output column for every dimension that is used and for the measure. In the version of the cube builder, only one measure is allowed per cube.
The following tables show examples of how you can use two separate queries as a data source for a cube. Note that both queries return columns for every dimension, as required, and that they differ only in which measure they include.
Results of Query 1.
|
Account (Dimension) |
Department (Dimension) |
Period (Dimension) |
Budget Amount (Measure 1) |
|---|---|---|---|
|
1000 1100 |
DEV SALES |
Q4 2003 Q4 2003 |
4000 6000 |
Results of Query 2.
|
Account (Dimension) |
Department (Dimension) |
Period (Dimension) |
Actual Amount (Measure 2) |
|---|---|---|---|
|
1000 1100 |
DEV SALES |
Q4 2003 Q4 2003 |
3000 5000 |
Resulting cube using Query 1 and Query 2 as data sources.
|
Account (Dimension) |
Department (Dimension) |
Period (Dimension) |
Budget Amount (Measure 1) |
Actual Amount (Measure 2) |
|---|---|---|---|---|
|
1000 1100 |
DEV SALES |
Q4 2003 Q4 2003 |
4000 6000 |
3000 5000 |
Incremental Updates
Two types of incremental updates are available:
Metadata
Incremental updates for metadata refers to the addition, removal, or modification of dimension members and/or their properties.
Data
Incremental updates for data refers to the aggregation of delta values to the cube data cells product of dimensional intersections of members.
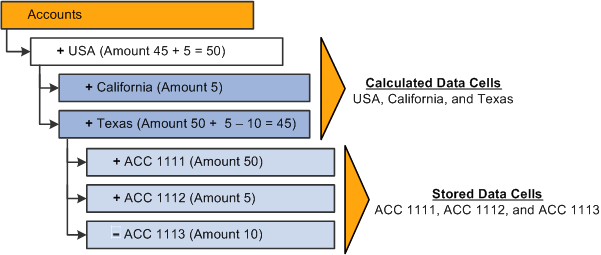
Data Cell Types
By default, two categories of data cells are available for incremental data updates:
Calculated data cells (or non-leaf nodes)
Calculated data cells store values of dimensional intersections of non-level zero members (branch nodes), which are calculated based on the consolidation properties of their children.
Stored data cells (or leaf nodes)
The stored data cells store values of dimensional intersections of level zero members (leaves) assigned manually.
Note: You can modify the stored properties, calculated properties, or both on any member at any level.
Image: Example of how to calculate upper data cells based on stored data cells
This example shows how to create data queries for incremental updates, taking as a reference the next Accounts dimension.
Aggregations on Load Tool
Essbase uses the term Aggregations on Load (replace, addition, and subtraction) as incremental updates for stored data cells. Essbase supports three data Aggregations on Load options:
Replace current value
Use the Replace option to overwrite or replace the currently stored value in the data cell with the value being passed. Basically, if the data file has multiple rows with the same dimensional intersection, then the last value in the data cell is stored and the previous ones are ignored.
Add to existing values
Use the Addition option to add all the values for the stored data cell to the currently stored value. Use this option for instances in which loads are always additive, for example, an implementation that loads transactions to an already stored summary amount.
Subtract from existing values
Use the Subtraction option as the opposite of the Addition option. It subtracts the values passed from the currently stored value. This option is rarely used, but you can use it to perform an additive load that then needs to be backed out.
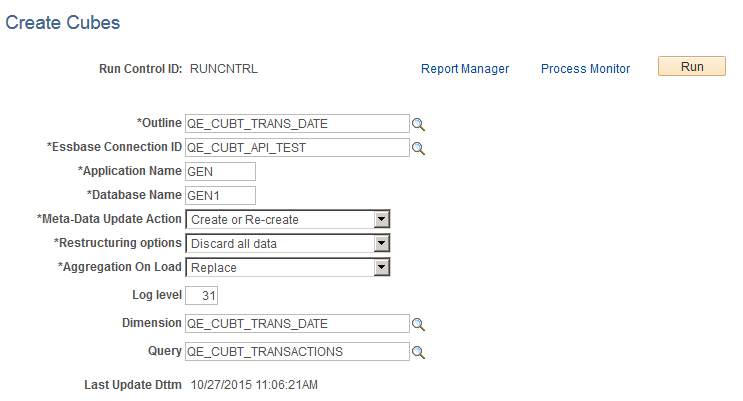
Image: Create Cubes page with the Aggregations on Load options of Replace, Addition, and Subtraction
This example shows the aggregations on load options in the run control ID of the Create Cubes page (CUB_RUNCNTL).
Note that:
The aggregations on load options are ignored when only metadata (dimension) is built.
When you build multiple factories (multiple data queries) in the same build, the same Aggregations on Load option is used for all of the factories.
The default value of the Aggregations on Load drop-down list is Replace.
After you run the PS2Essbase process, the Aggregations on Load option serially builds each dimension and then serially builds each factory. The factory creates a data file with all the data cells to be loaded to the Essbase server.
Example: Designing Data Queries for Incremental Updates
Image: Example of how to create data queries for each Aggregations on Load option, next Accounts dimension
This example shows how to create data queries for each Aggregations on Load option, taking as a reference the next Accounts dimension.
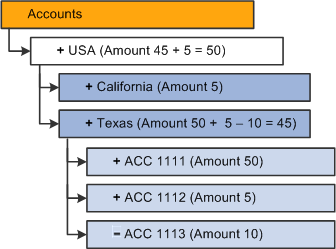
Image: Example of how to create data queries for each Aggregations on Load option, next staging table
This example shows how to create data queries for each Aggregations on Load option, taking as a reference the next staging table that contains the data cells to be loaded.

Essbase Cube Builder can be used to produce three different results:
Results of replacing the existing data cells.
Image: Results of replacing the existing data cells
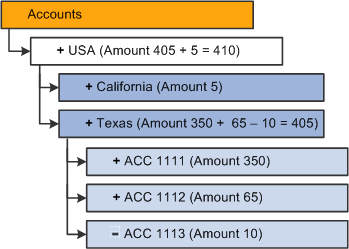
This diagram illustrates the resulting dimension if the Replace (replace data load) option is selected.
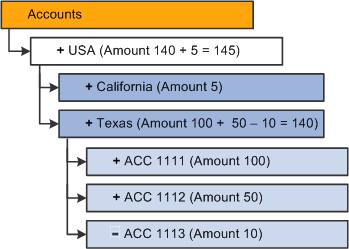
Note: The last value passes for each cell is the valid value. In this example, cells ACC 1111 ($200) and ACC 1112 ($10) are ignored.
When you want to perform an additive incremental update using the Replace Aggregations on Load option, you need to create a data query that summarizes repeated fields into one field. For example, to achieve an additive incremental update on stored data cells, you need to create a data query that summarizes repeated fields into one field.
Image: Example of summarizing repeated fields into one field
This example illustrates how to create a data query that summarizes repeated fields into one field to achieve an additive incremental update on stored data cells.
This example illustrates the SQL query for summarizing repeated fields into one field:
SELECT DISTINCT A.ACCOUNT, ( SELECT SUM(B.AMOUNT) FROM STAGING_TABLE B WHERE A.ACCOUNT = B.ACCOUNT ) FROM STAGING_TABLE A;Image: Results of replacing incremental updates
This example illustrates the results of replacing incremental updates.
Note: The current stored value is overwritten and lost, therefore, in the staging table used for the data query loads, you must not eliminate the previous increments that are already loaded into Essbase. These previous increments are required to recalculate the total summarized amount in each load.
In this section, the concept of staging tables is used frequently; notice that the staging tables are not tables that PeopleTools creates or maintains, the staging tables are optional customer or application tables. A staging table is any table that is used to store temporary increments to be loaded into Essbase. Depending on the option selected in the Aggregation on Load drop-down list, the staging tables may be cleaned up or maintained.
Results of additive incremental updates.
Results of additive incremental updates are the previously stored values plus each one of the new cells that corresponds to the cube intersection are added.
Image: Results of additive incremental updates
This example illustrates the resulting dimension when the Addition (addition data load) option is selected.
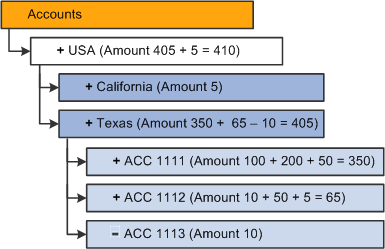
The resulting amounts in the dimension after the build is the same as when you want to perform an additive incremental update using the Replace Aggregations on Load option.
Results of subtractive incremental updates.
Results of subtractive incremental updates are the previously stored values minus each one of the new cells that corresponds to the cube intersection conforms to the result for the stored data cells.
Image: Results of subtractive incremental updates
This example illustrates the resulting dimension when the Subtraction (subtraction data load) option is selected.

In almost all instances, Replace is the preferred option over Addition and Subtraction because Replace makes forming queries against relational sources easier (it summarizes data to the dimensional intersection versus having duplicate rows in the load file). The Replace option is also a better alternative because it reduces the number of records to be passed to Essbase, thus improving performance. Moreover, the Addition and Subtraction options make the recoverability more difficult after the database fails while loading the data. Although when a recover is required, Essbase lists the number of the last rows committed in the application event log file, which is used to restart the build process.
If you run the cube using the Addition or Subtraction options, you need to clear the staging table after each build so that the values that are already loaded is not required again. However, PeopleSoft Cube Builder does not modify or remove the loaded cells from the staging table; either you or the application that uses the Cube Builder is responsible for cleaning up the staging table after the incremental data is loaded. If the staging table is clear, the notification of the Process Scheduler shows that the cube building process runs successfully. To successfully clear the staging table, you should create a PSJob that first runs the PS2Essbase process and then runs another AE program to clear the specific staging table.
Note: PSJob and the AE program are not provided by PeopleTools.