Specifying Document Types for Web Source
Access the Document Types page by selecting PeopleTools, Search Framework, Search Designer Activity Guide, Search Definition and selecting a Source Type of Web Source. Then click the Document Types tab.
Use the Document Types page to specify the document types of the documents to be crawled. Document types are expressed as MIME types.
Image: Web Source — Document Types page
This example illustrates the fields and controls on the Web Source — Document Types page. You can find definitions for the fields and controls later on this page.
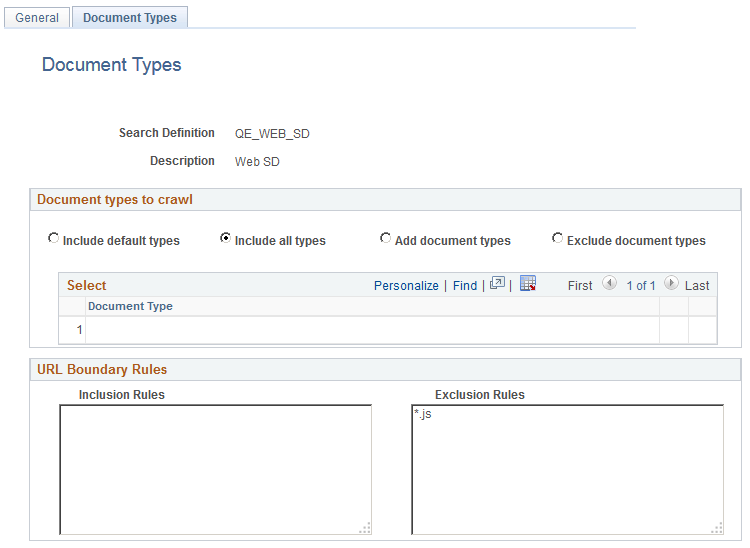
Document Types to Crawl
|
Field or Control |
Definition |
|---|---|
| Include default types |
Crawl only on the default document types, as defined by the search engine. The search engine default document types for crawling are:
Note: When you select this option, notice that you cannot add or remove items from the Document Type grid. Note: Exclusion rules take precedence. For example, if you enter *.doc in the Exclusion Rules edit box, none of the Microsoft Word documents will be processed. |
| Include all types |
Crawl all document types supported by the search engine. To see this list of supported document types, expressed as MIME types, select either the Add these types or Exclude these types radio button and click the lookup button for the Document Type column. Note: When you select this option, notice that you cannot add or remove items from the Document Type grid. |
| Add document types |
In addition to the mandatory document types, which are HTML and TXT files, the system also crawls any document type added to the Document Type grid. |
| Exclude document types |
Excludes specific document types added to the Document Type grid. Assume the majority of the document types supported by the search engine crawler apply to your configuration, except for a small number of document types. In this case you can specifically include those document types in the Document Type grid. When the search engine crawls the file location, the search engine crawls all document types on the supported MIME list, except for those document types included in the Document Type grid. |
URL Boundary Rules
|
Field or Control |
Definition |
|---|---|
| Inclusion Rules |
Specify an inclusion rule that a URL must contain. For example: www.*.example.com In this case, the search engine crawls all content within www.*.example.com. |
| Exclusion Rules |
Specify an exclusion rule that a URL can't contain. For example: www.*.uk.example.com In this case, the search engine does not crawl anything within www.*.uk.example.com. |
URL boundary rules limit the crawling scope. When you add boundary rules, the crawler is restricted to URLs that match only the rules you specify. Inclusion and Exclusion rules can be formed to filter documents with patterns of begins with, ends with, contains or regular expressions. Rules with regular expression should start with the character R.
|
Rule |
Description |
|---|---|
|
Begins With: http://www.uk.example.com* |
In this case, the search engine considers URLs starting with www.uk.example.com. |
|
Ends With: *.xml |
In this case, the search engine considers URLs ending with .xml. |
|
Contains: *contacts* |
In this case, the search engine considers URLs containing string contacts. |
|
Regular Expression: R^http://www.example.com/code.*./verson[1-9].html$ |
In this case, the search engine considers URLs from example.com with sites starting with string code, and has versions numbered from 1 to 9 and ends as .html. |
When working with these rules, keep in mind:
Exclusion rules always override inclusion rules.
Multiple inclusion and exclusion rules can be separated by a space or in a new line.
Use an asterisk to represent a wildcard.
Inclusion and exclusion rules are case-insensitive.