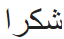 in
the Arabic script but is transliterated in the Latin script as shukraan.
in
the Arabic script but is transliterated in the Latin script as shukraan.
Transliterating a word does not tell you the meaning of
the word. It tells you how the how the word is pronounced in a foreign
language. This makes the language a little more accessible to people who
are unfamiliar with the alphabet of the foreign language. This is opposed
to translation, which,
put in simple terms, gives you the meaning of a word that’s written
in another language. For example, the greeting
in Arabic is translated as in
the Arabic script but is transliterated in the Latin script as shukraan.
General transforms provide a general-purpose package for processing Unicode text. They are a powerful and flexible mechanism for handling a variety of different tasks, including:
· Uppercase, lowercase, or title case conversions
· Normalization
· Hex and character name conversions
· Script to script conversion
The reference data sources supported by Customer Screening are all provided in the Latin character set, and some in the original scripts. The screening process can also be used with non-Latin data. Non-Latin data can be screened against the Latin reference data sources which are supported by performing transliteration of data from the non-Latin character set to the Latin character set.
Non-Latin customer data can be screened against non-Latin reference data without any changes to the product, although certain fuzzy text matching algorithms may not be as effective when used to match data with the non-Latin character set. Text is processed on a left-to-right basis.
Topics:
· Input fields for Individual screening
· Input fields for Entity screening
To match the original script data against reference data, follow these steps:
1. Prepare customer and external entity data such that non-Latin names are populated in the Original Script Name fields.
2. Enable Original Script Name match rules and clusters.
This section lists the REST input fields used when screening individuals via the real-time process.
The following table provides the input attributes for the individual screening process. They are available for any additional inputs required by your screening process.
Table : Input fields for Individual screening
Field Name |
Expected Data Format |
Notes |
v_given_name |
String
|
The individual matching process is based primarily on the name supplied for the individual.
|
v_family_name |
||
v_full_nm |
||
v_aliases_family_name |
||
v_aliases_given_name |
||
v_aliases |
This section lists the inputs fields used when screening entities via the real-time process.
The following table provides input attributes for the entity screening process. They are available for any additional inputs required by your screening process.
Table : Input fields for Entity screening
Field Name |
Expected Data Format |
Notes |
v_org_nm_bus_strip |
String
|
The entity matching process is based primarily on the name supplied for the entity. |
v_last_nm |
||
v_full_nm |
||
v_org_nm |
||
v_alias_nm |
||
v_aliases |
||
v_first_nm |