ビルド・レポートを使用したネイティブ実行可能ファイルのサイズの最適化
ネイティブ・イメージに付属する様々なツールを利用して、ネイティブ実行可能ファイルを最適化できます。このガイドでは、ビルド・レポート・ツールを使用して、生成されたネイティブ実行可能ファイルの内容をよく理解する方法、およびセマンティクスの変更を伴わないアプリケーション内の小さな変更が最終的なバイナリ・サイズにどのように影響するかを示します。
ノート: ビルド・レポートは、GraalVM Community Editionでは使用できません。
前提条件
GraalVM JDKがインストール済であることを確認します。最も簡単に始めるには、SDKMAN!を使用します。その他のインストール・オプションについては、「ダウンロード」セクションを参照してください。
デモでは、入力文字列からi番目の単語を抽出する単純なJavaアプリケーションを実行します。単語はカンマで区切られ、任意の数の空白文字で囲むことができます。
- 次のJavaコードをIthWord.javaという名前のファイルに保存します:
public class IthWord { public static String input = "foo \t , \t bar , baz"; public static void main(String[] args) { if (args.length < 1) { System.out.println("Word index is required, please provide one first."); return; } int i = Integer.parseInt(args[0]); // Extract the word at the given index. String[] words = input.split("\\s+,\\s+"); if (i >= words.length) { System.out.printf("Cannot get the word #%d, there are only %d words.%n", i, words.length); return; } System.out.printf("Word #%d is %s.%n", i, words[i]); } } - アプリケーションをコンパイルします:
javac IthWord.java(オプション)任意の引数を使用してアプリケーションをテストし、結果を確認します:
java IthWord 1出力は次のようになります:
Word #1 is bar. - ビルド・レポートとともに、クラス・ファイルからネイティブ実行可能ファイルをビルドします:
native-image IthWord --emit build-reportこのコマンドは、現在の作業ディレクトリに実行可能ファイル
ithwordを生成します。ビルド・レポート・ファイルithword-build-report.htmlは、ネイティブ実行可能ファイルとともに自動的に作成されます。レポートへのリンクは、ビルド出力の最後にある「Build artifacts」セクションにもリストされます。レポートに別のファイル名またはパスを指定するには、それをbuild-reportオプションに追加します(--emit build-report=/tmp/custom-name-build-report.htmlなど)。(オプション)同じ引数でこの実行可能ファイルを実行します:
./ithword 1出力は前の出力と同じになります:
Word #1 is bar. -
ビルド・レポートはHTMLファイルです。ブラウザでレポートを開きます。最初に、イメージ・ビルドに関する一般的なサマリーが表示されます。「Image Details」チャートの右上に、合計イメージ・サイズが表示されます:
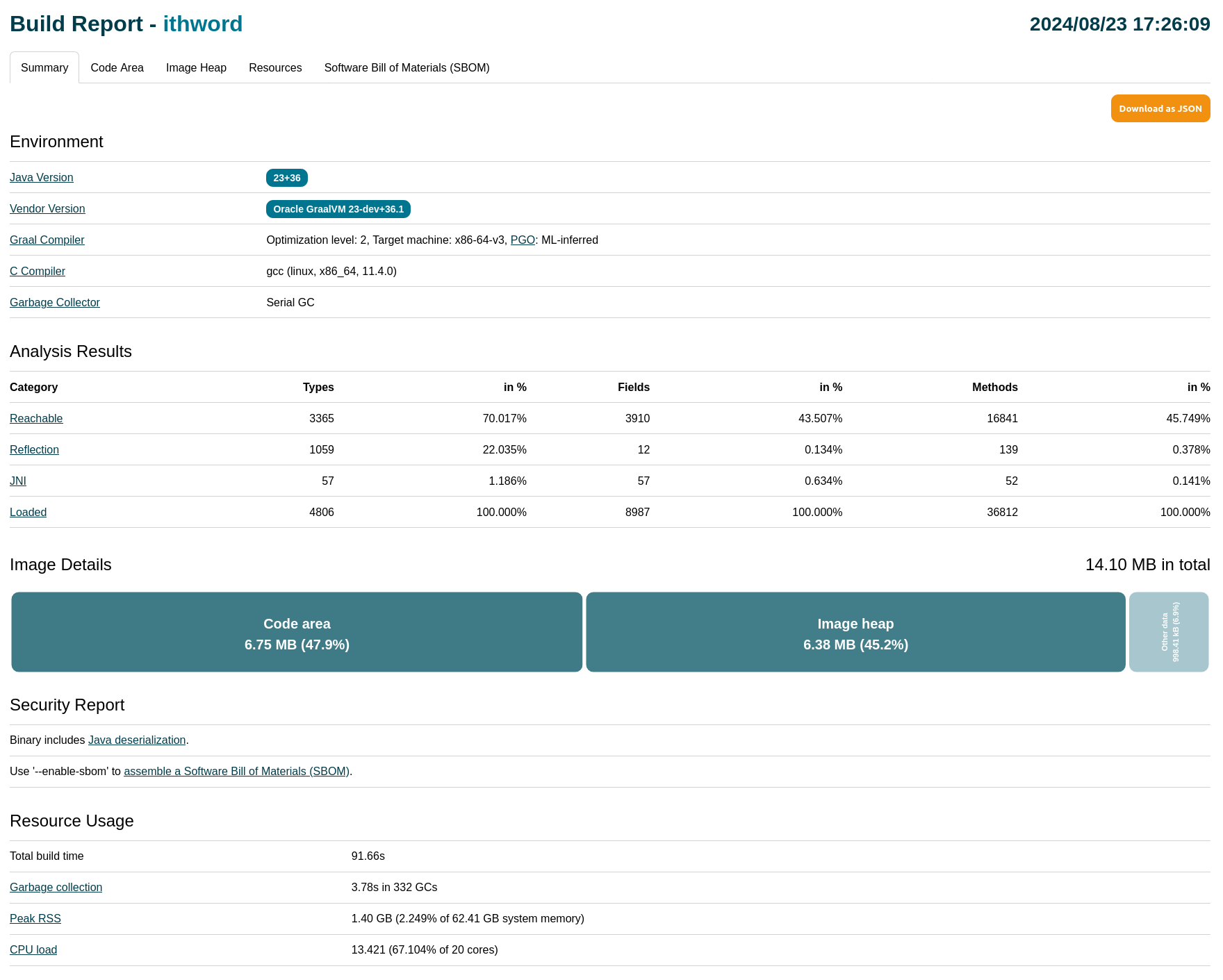
初期サイズは想定どおりに見えますが、参考までに、HelloWorldアプリケーションのサイズは約7MBです。つまり、コードが非常に単純であるという事実にもかかわらず、その違いはかなり大きくなっています。調査を続行します。
-
ナビゲーションのタブまたはチャートの対応するバーをクリックして、「Code Area」タブに移動します。
表示される内訳チャートでは、異なるパッケージがバイトコード・サイズに関して相互にどのように関連しているかがビジュアル化されるようになりました。表示されるパッケージには、静的分析によって到達可能であると検出されたメソッドのみが含まれていることに注意してください。つまり、表示されるパッケージ(およびそのクラス)は、最終的にコンパイルされ、最終バイナリに含まれる唯一のパッケージです。
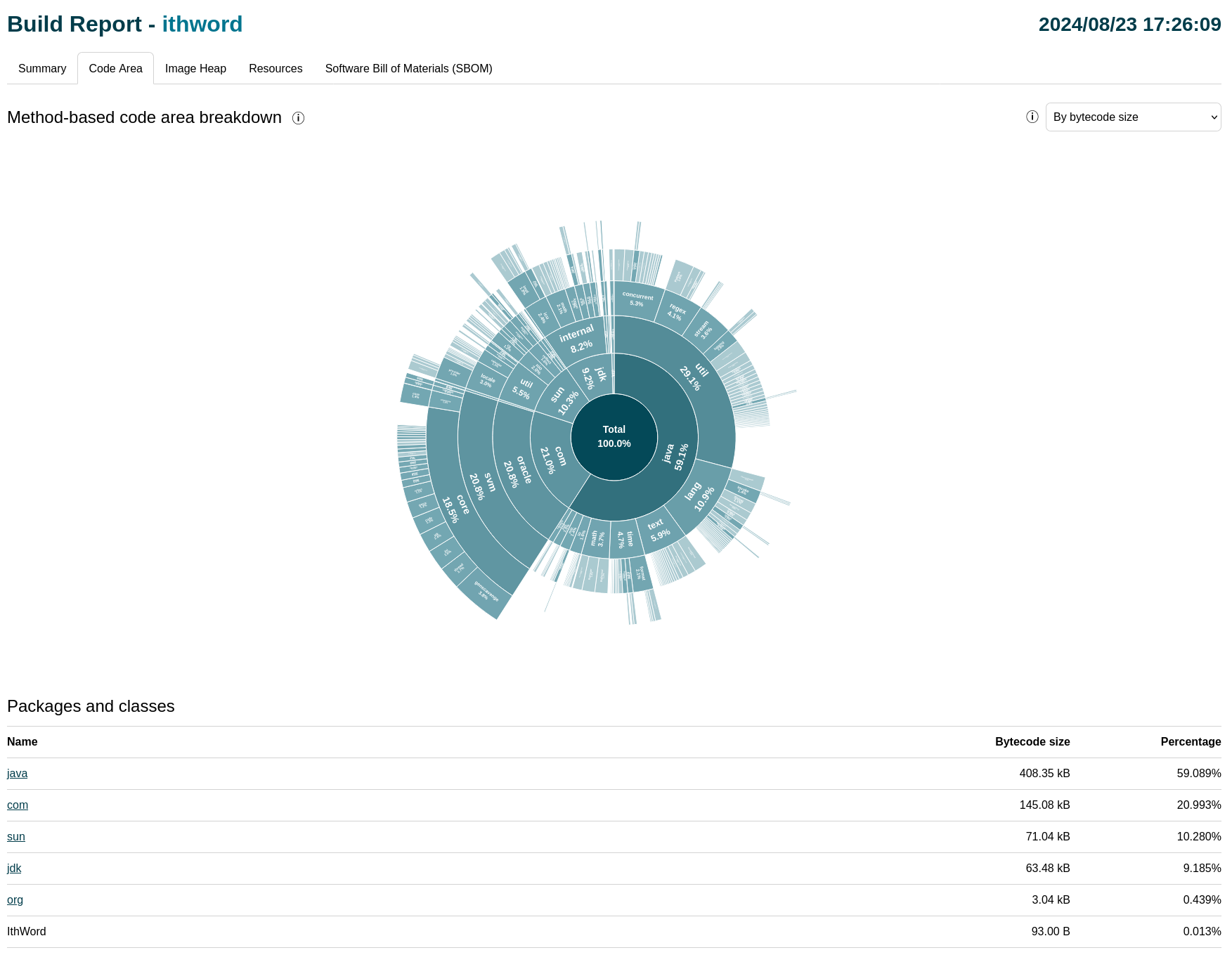
これからわかる最初の結論は、コードの大部分がJDKまたはネイティブ・イメージの内部コードに由来しているということです。
IthWordクラスの割合は、到達可能なすべてのメソッドの合計バイトコード・サイズの0.013%のみであることがわかります。 -
javaパッケージをクリックしてドリルダウンします。到達可能なコードの大部分(ほぼ半分)は、java.utilパッケージに由来しています。また、java.textおよびjava.timeパッケージは、javaパッケージ・サイズのほぼ20%を占めることがわかります。しかし、アプリケーションはこれらのパッケージを使用しているのでしょうか。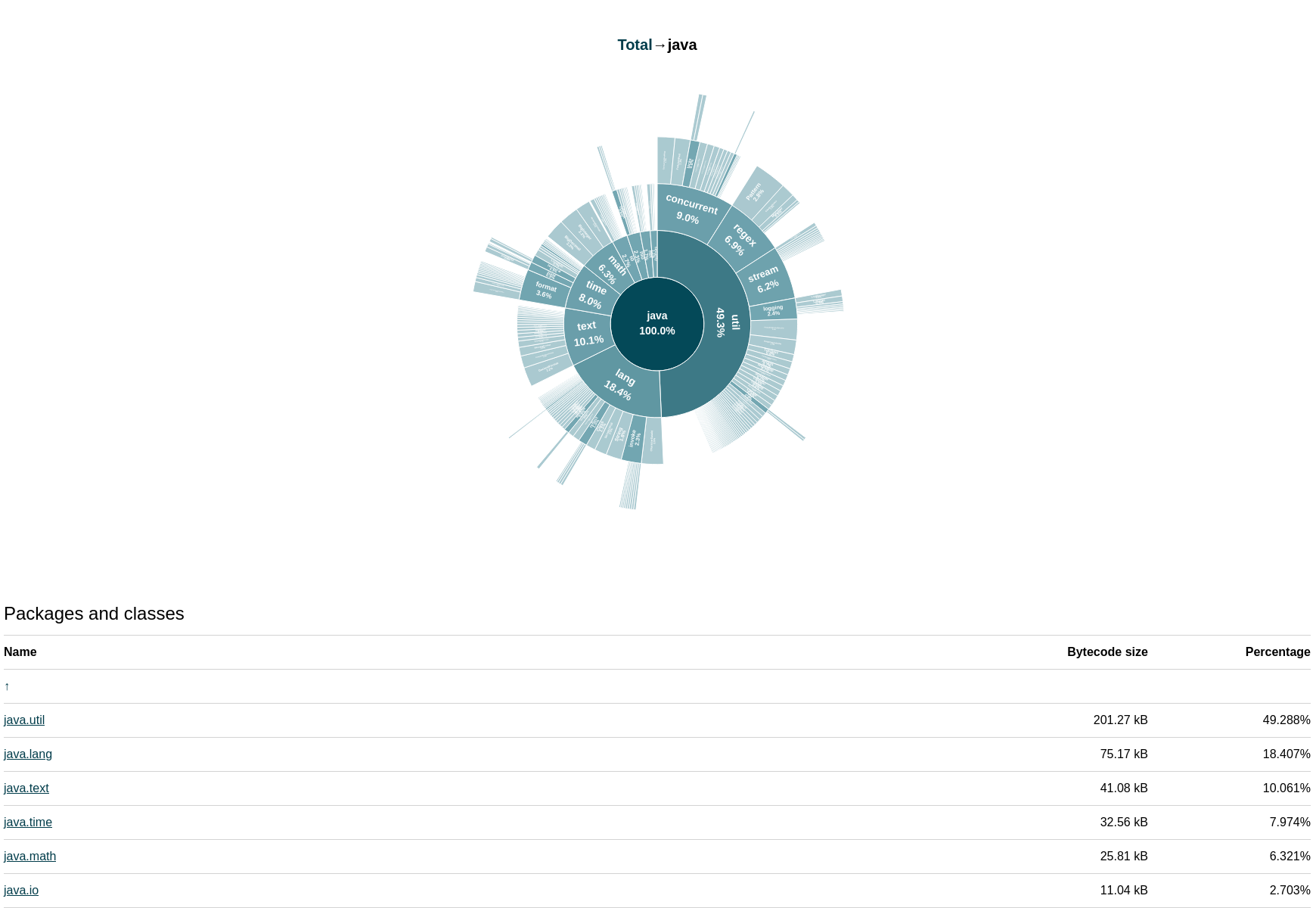
-
textパッケージにドリルダウンします: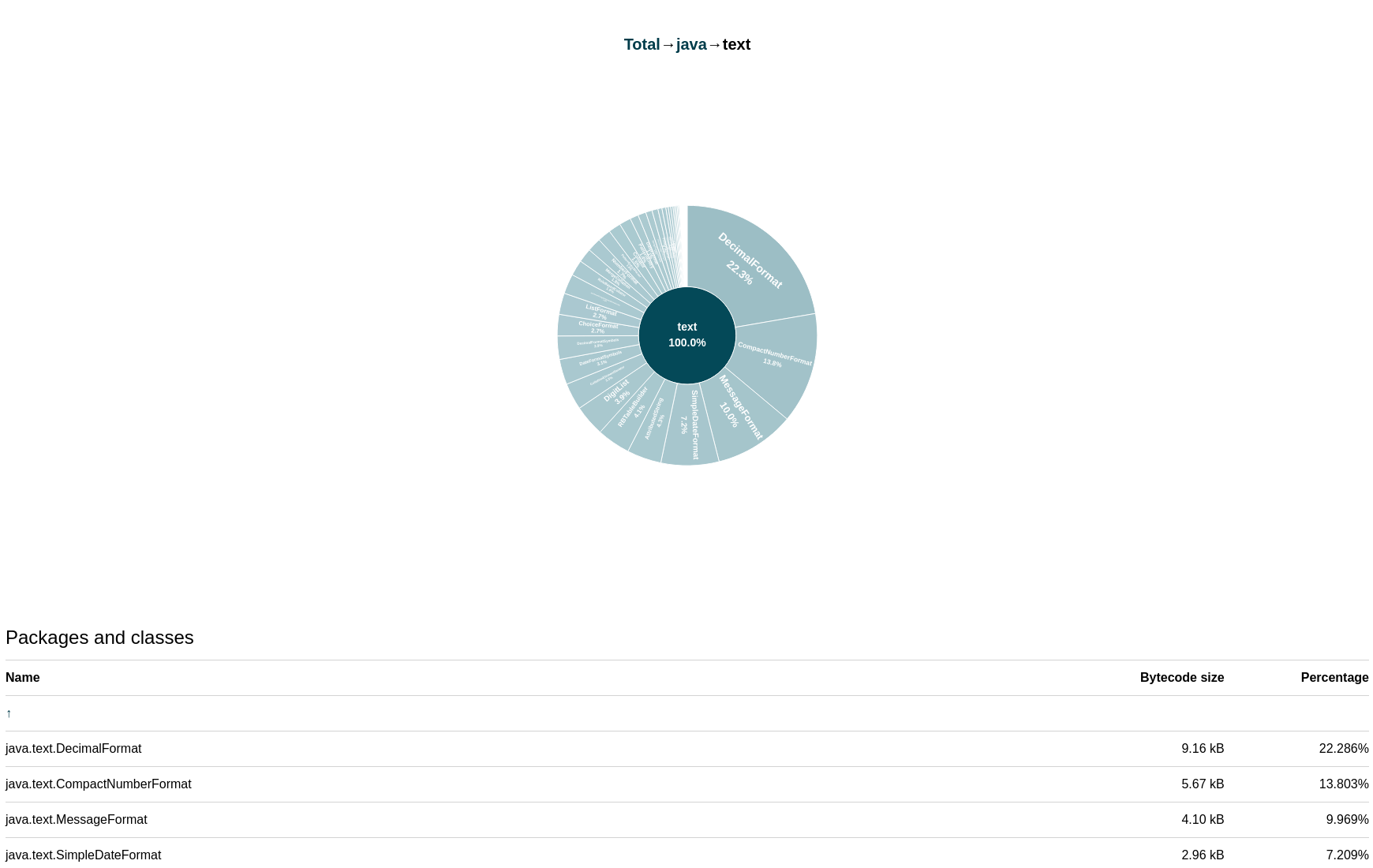
到達可能なクラスの大部分がテキストのフォーマットに使用されることがわかりました(次のパッケージとクラスのリストを参照)。ここまでで、含まれているフォーマット・クラスは、次の1つの場所からのみ到達可能であると考えられます(実際は使用されていません):
System.out.printf。 -
javaパッケージに戻ります(中央の円をクリックするか、チャートの上部にあるjavaという名前をクリックします)。 -
次に、
timeパッケージにドリルダウンします: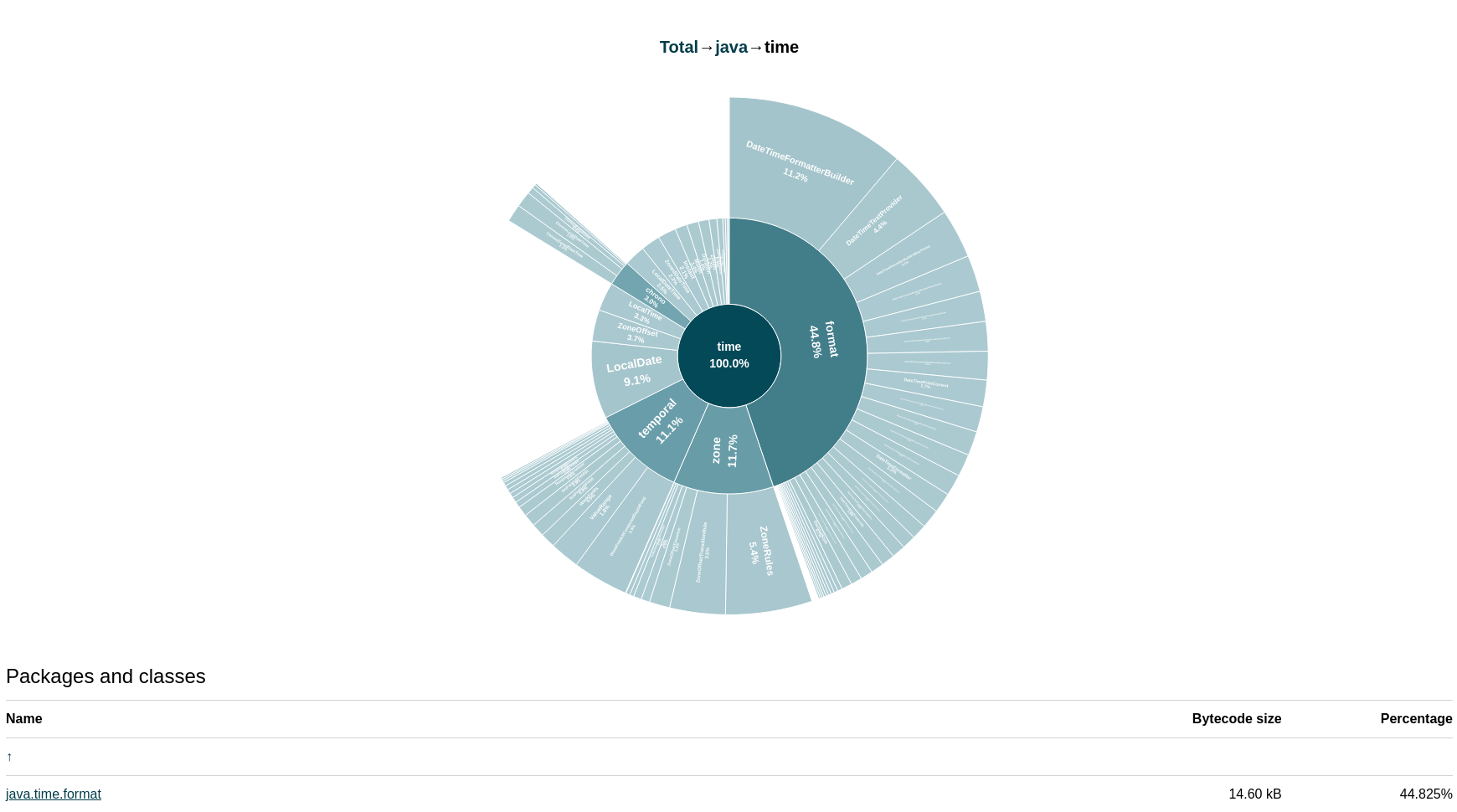
パッケージ・サイズのほぼ半分は、その
formatサブパッケージに由来しています(java.textパッケージの状況と同様)。そのため、System.out.printfがバイナリ・サイズを改善する最初の機会です。 - 最初のアプリケーションに戻り、
System.out.printfの使用からSystem.out.printlnに切り替えます:public class IthWord { public static String input = "foo \t , \t bar , baz"; public static void main(String[] args) { if (args.length < 1) { System.out.println("Word index is required, please provide one first."); return; } int i = Integer.parseInt(args[0]); // Extract the word at the given index. String[] words = input.split("\\s+,\\s+"); if (i >= words.length) { // Use System.out.println instead of System.out.printf. System.out.println("Cannot get the word #" + i + ", there are only " + words.length + " words."); return; } // Use System.out.println instead of System.out.printf. System.out.println("Word #" + i + " is " + words[i] + "."); } } -
ステップ2から4を繰り返します(クラス・ファイルをコンパイルし、ネイティブ実行可能ファイルをビルドして、新しいレポートを開きます)。
-
「Summary」セクションで、合計バイナリ・サイズがほぼ40%削減されたことを確認します:

-
「Code Area」タブに再度移動して、
javaパッケージにドリルダウンします。最初の仮定が正しいことがわかります。java.textパッケージとjava.timeパッケージには両方ともアクセスできなくなりました。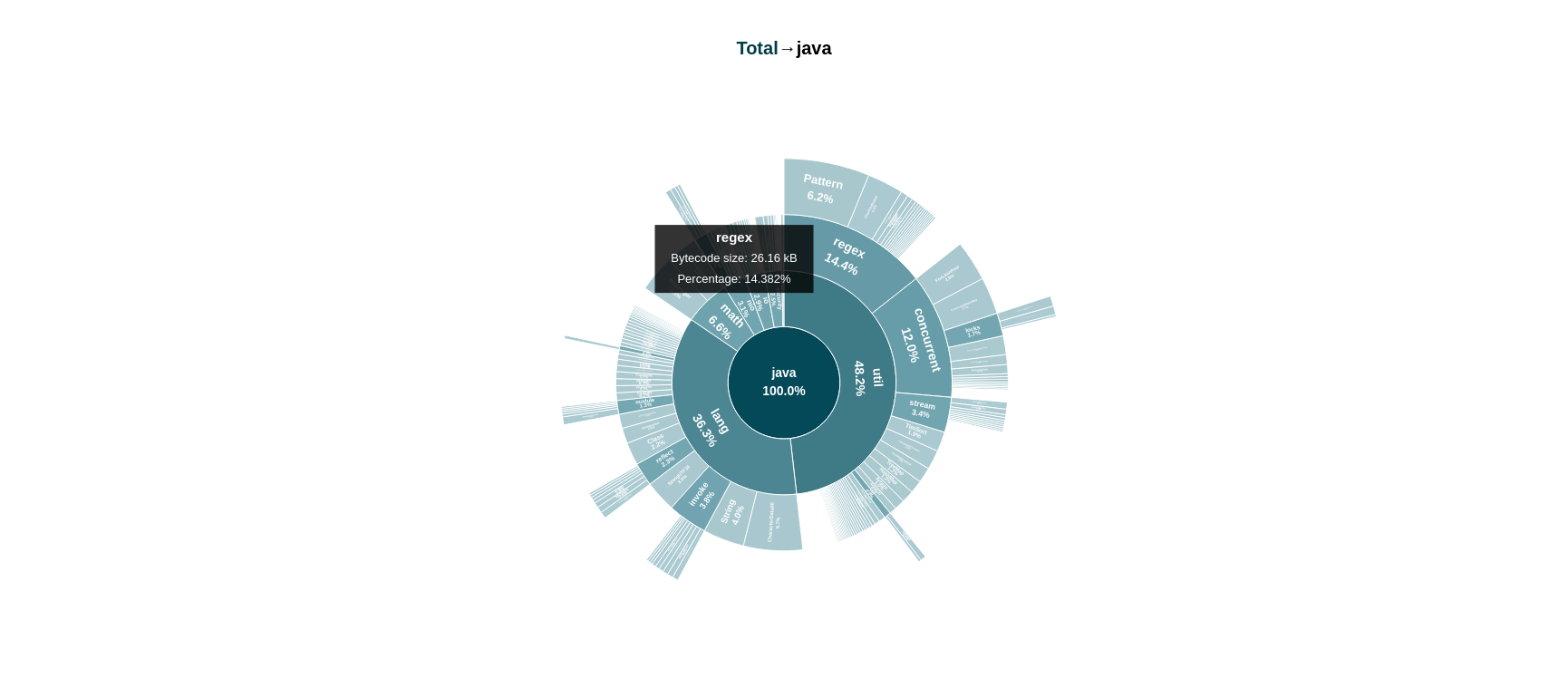
アプリケーションが必ずしも必要としない、到達可能なコードがさらにあるかどうかの確認を続けます。
すでに予想しているとおり、他の候補は、
java.utilパッケージ内に存在するregexサブパッケージです。このパッケージ単独では、現在のjavaパッケージ・サイズの15%近くを占めています。正規表現(\\s+,\\s+)は、元の入力を単語に分割するために使用されます。非常に便利ですが、これにより前述のregexパッケージは不要な依存関係になります。正規表現自体は複雑ではなく、別の方法で実装できます。 -
次に、「Image Heap」タブに移動して、調査を続行します。このセクションは、イメージ・ヒープ(様々な目的で静的アプリケーション・データ、メタデータ、バイト配列などの到達可能なオブジェクトを含むヒープ)に含まれるすべてのオブジェクト型のリストを示します。この場合、リストは通常どおりに見えます。サイズの大部分は、専用のバイト配列に格納されているRAW文字列値(約20%)、
StringオブジェクトとClassオブジェクト(約20%)、およびコード・メタデータ(20%)に由来しています。
このアプリケーションのイメージ・ヒープに大きく影響している特定のオブジェクト型はありません。ただし、予期しないエントリが1つあります。小さいサイズの影響(~2%)は、イメージ・ヒープに埋め込まれたリソースが原因です。アプリケーションは明示的なリソースを使用しないため、これは予期されていません。
-
「Resource」タブに切り替えて、調査を続行します。このセクションは、構成ファイルを介して明示的にリクエストされたすべてのリソースのリストを示します。他の種類のリソース(欠落リソース、注入リソースおよびディレクトリ・リソース)を切り替えるオプションもありますが、このガイドの範囲を超えています。詳細は、「ネイティブ・イメージ・ビルド・レポート」を参照してください。

この部分の結論としては、同じようにイメージ・ヒープに影響しているが、アプリケーション・コードから明示的にリクエストされていない
java.baseモジュールに由来する唯一のリソース(java/lang/uniName.dat)があります。これについては何もできませんが、(ユーザー・コードから間接的に到達可能な) JDKコードでも追加のリソースを使用できるため、サイズに悪影響を及ぼすことに注意してください。 - ここで、アプリケーション・コードに戻り、正規表現を使用しない新しいアプローチを実装します。次のコードでは、
String.substringおよびString.indexOfを使用してセマンティクスを保持しますが、そのロジックは比較的単純です:public class IthWord { public static String input = "foo \t , \t bar , baz"; public static void main(String[] args) { if (args.length < 1) { System.out.println("Word index is required, please provide one first."); return; } int i = Integer.parseInt(args[0]); // Extract the word at the given index using String.substring and String.indexOf. String word = input; int j = i, index; while (j > 0) { index = word.indexOf(','); if (index < 0) { // Use System.out.println instead of System.out.printf. System.out.println("Cannot get the word #" + i + ", there are only " + (i - j + 1) + " words."); return; } word = word.substring(index + 1); j--; } index = word.indexOf(','); if (index > 0) { word = word.substring(0, word.indexOf(',')); } word = word.trim(); // Use System.out.println instead of System.out.printf. System.out.println("Word #" + i + " is " + word + "."); } } -
ステップ2から4を再度繰り返します(クラス・ファイルをコンパイルし、ネイティブ実行可能ファイルをビルドして、新しいレポートを開きます)。
-
もう一度、「Summary」セクションで合計バイナリ・サイズの改善(約15%)を確認できます:

また、以前に登録されたリソースは、生成されたバイナリの一部ではなくなりました(確認するには、「Resources」セクションを再度参照してください):

このガイドでは、ビルド・レポートを使用してネイティブ実行可能ファイルのサイズを最適化する方法を示しました。ビルド・レポートを使用すると、生成されたネイティブ実行可能ファイルの内容をより詳細に調査できます。どのコードが到達可能であるかをより深く理解することで、不要なJDKの依存関係を削除しながらセマンティクスを保持する方法でアプリケーションを実装できます。