Cycle Results Data Cleanup
It is recommended to regularly clean AsCycle and AsCycleDetail tables, ideally daily, if Cycles are run each day during nightly batch process. Cycle results may be required for reporting purpose. The data can be off-loaded to an alternate tables, or may be kept for a week and must clean weekly, if number of activities processed per day is not large. This process can be automated by enabling Cycle.cleanup = true in Cycle.properties configuration file. By default, this will schedule for daily purges.
Logging
Logging can be bottleneck, if lot of data is being written to the log files. Following are some of the general best practices.
-
Ensure log rotation is on on each of the server. Log rotation, will keep the log file size in check, and will not let I/O process slow down when writing to large byte size files.
-
Ensure only INFO logging is on. Reducing amount of logging to bare minimum in extensions as well as other application components such as coherence, application serve logs etc.
-
Ensure SQL logs are switched off in PAS properties.
-
Ensure generated classes are switched off, when not needed, only in case of DEBUG.
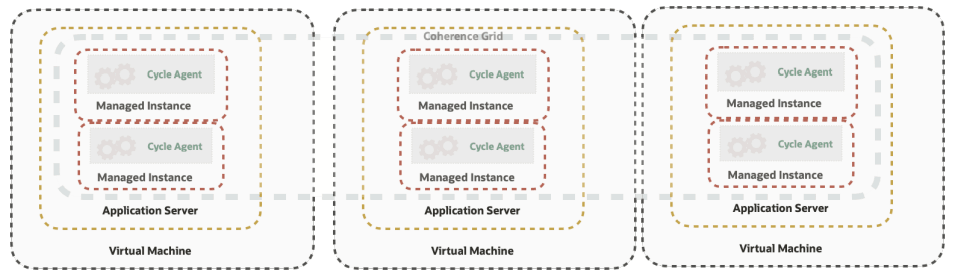
Coherence Grid
TaskProcessorDefinition:
In coherence-cache-config.xml there is a “task processor” definition. Coherence creates task processor per storage-enabled nodes. Each task processor responsibility is to own a thread pool. Test and experiment with the following change in the coherence-cache- config.xml.
Existing configuration
<!-- MAKE SURE THAT ALL IDs ARE UNIQUE ACROSS THE CLUSTER, OR THE MEMBER WILL NOT PARTICIPATE IN GRID PROCESSING - -!>
<processing:taskprocessors>
<processing:taskprocessordefinition id="CycleTaskProcessor" displayname="Cycle Task Processor" type="SINGLE">
<processing:default-taskprocessor id="CycleTaskProcessor" threadpoolsize=“25”></processing:default- taskprocessor>
</processing:taskprocessordefinition>
</processing:taskprocessors>
* SINGLE means that a single node has this TaskProcessor.
Recommended configuration
<!-- MAKE SURE THAT ALL IDs ARE UNIQUE ACROSS THE CLUSTER, OR THE MEMBER WILL NOT PARTICIPATE IN GRID PROCESSING —>
<processing:taskprocessors>
<processing:taskprocessordefinition id="CycleTaskProcessor" displayname="Cycle Task Processor" type=“GRID">
<processing:default-taskprocessor id="CycleTaskProcessor" threadpoolsize=“25”/>
</processing:taskprocessordefinition>
</processing:taskprocessors>
*GRID means that all storage-enabled nodes are expected to have this processor - This should be the default
setting.
By doing this change, coherence will create DefaultTaskProcessors with id=CycleTaskProcessor in each storage-enabled nodes.
In the above topology there should be at least two storage- enabled nodes per four node cluster to have high availability. Though, every cycle agent node can run as a cache server (storage-enabled), be advised, that more than one Task Processors can have better performance, since each Task Processor has it’s own thread pool and thread allocation per DefaultTaskProcessor. This will entail less thread pool size per DefaultTaskProcessor, as there are more than one running per cluster.
Note: Cycle Client must run as storage-disabled node, since cycle client does not act a a cache node. Cycle client is a command line tool for Cycle command execution.
Example:
Virtual Machine 1
-
2 CycleAgent JVMs - At least one of them should be storage-enabled=true
-
JVM Argument: -Dtangosol.coherence.distributed.localstorage=true
-
1 Cycle Client running with storage-enabled=false.
-
JVM Argument: -Dtangosol.coherence.distributed.localstorage=false
Virtual Machine 2
-
2 CycleAgent JVMs - At least one of them should be storage-enabled=true.
-
JVM Argument: -Dtangosol.coherence.distributed.localstorage=true
-
The above pattern can be repeated for horizontal scaling nodes