Implementing Agnostic Integration
This topic provides an overview of Agnostic Integration and discusses how to set up the integration between the third-party inventory software and PeopleSoft IT Asset Management.
|
Page Name |
Definition Name |
Usage |
|---|---|---|
|
IT_PLOAD_RUN |
Set run control options to submit the IT_LOAD_PRE Application Engine process, Select to process all Batch IDs and all errors or specific Batch IDs and errors. |
|
|
AM_IT_PRE_LOAD_ERRORS |
Run this query to identify errors from the IT_LOAD_PRE process. The query lists the Serial IDs of the devices that fail any of the pre-stage error edits. |
The purpose of Agnostic Integration is to provide alternative options to integrate inventory data from third-party discovery applications to PeopleSoft ITAM without employing the Request/Response model. However, the Request/Response model remains an option for the integration and the functionality is not impacted by Agnostic Integration.
Agnostic Integration is designed to leverage open interface tables called pre-staging tables. This eliminates the need to build a tightly-coupled XML connector, which is required for the Request/Response model. Agnostic Integration provides efficiency for those organizations that are implementing ITAM as well as flexibility for those who rely on a third party's connector. The data still needs to be integrated into a delivered web service or directly into the pre-staging tables.
The pre-staging tables can be populated directly using a custom program or via a one-way asynchronous inbound web service. The agnostic approach assumes that a third party can already provide an export of the discovery data as part of their native product. In this case, the third party does not need to understand a request from PeopleSoft ITAM. The only requirement is to transform the data directly into the pre-staging tables or into the web service in order to populate the pre-staging tables. This integration model is more loosely coupled than the Request/Response model, which remains an option for integration.
The following describes terms that are commonly used when describing the Agnostic Integration framework:
Term |
Definition |
|---|---|
Request/Response Model |
This is the asynchronous XML Request/Response integration option. A request is submitted using the Request Discovery Data run control page and a message is published by Integration Broker to the 3rd party. The request provides the parameters for the data from the discovery system. The response contains the assets matching those request parameters. Once the response is received, the IT_LOAD_PROC is automatically submitted to perform data translation and mapping edits. This integration is considered tightly coupled with the third party suppliers. |
Pre-Staging Tables |
The pre-staging tables are interface tables for the hardware and software attributes of the discovered IT assets. They are used to integrate discovery or inventory data from third-party discovery applications. They are IT_DISCO_HW_PRE and IT_DISCO_SW_PRE. One of the options available in the Agnostic Integration feature is to utilize these tables as the integration point. The tables can be populated manually through a custom program or through the a web service |
Web Service |
Web service, as used in this section, refers to the inbound asynchronous XML message. It is one of the two additional integration options made available by the Agnostic Integration framework. |
Integrate Discovery Data |
This is the run control page that is used to submit the data load Application Engine process, IT_LOAD_PRE. Select to process all Batch IDs and all errors or specific Batch IDs and errors. |
The following diagram represents the process flow for the Agnostic Integration framework:
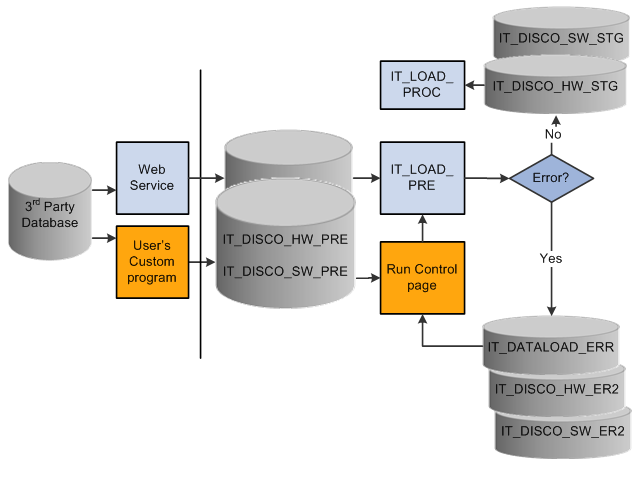
This section discusses how to:
Select an integration option.
Run the data load process (IT_LOAD_PRE).
Identify preload errors.
View preload errors.
The following section discusses the two options for Agnostic Integration:
Manual
Web Service
Note: The two options, Manual and Web Service, are processed as mutually exclusive tasks (TASK_ID). If you elect to use both options to integrate discovery data, you may lose the ability to filter out duplicate Serial ID errors. Since the two sources of data are processed separately, the data validation performed by the IT_LOAD_PROC will only check for duplicate Serial IDs within the one source.
Manual Option
This option is selected when using a custom program to manually load the pre-staging tables for hardware and software discovery data (IT_DISCO_HW_PRE and IT_DISCO_SW_PRE). When using this method, keep in mind the following points:
Create a custom program or use a third-party program to populate the pre-staging tables.
Fix or remove duplicate or invalid Serial IDs before loading the pre-staging tables. An example of an invalid Serial ID might be a blank value.
After ensuring that all discovery data is loaded to the pre-staging tables, use the run control page, Integrate Discovery Data, to submit the IT_LOAD_PRE Application Engine program, which processes data from the pre-staging tables and loads them to the staging tables. This process also calls the IT_LOAD_PROC Application Engine process to perform validations, translations, and transformations of the data.
Ensure there is no orphan software data. All integrated software data (IT_DISCO_SW_PRE) must have a parent record (IT_DISCO_HW_PRE). This is consistent with the existing expectation of data that is provided to ITAM from third party systems.
Web Service Option
The web service option uses an asynchronous inbound XML message to populate the pre-staging tables for hardware and software discovery data (IT_DISCO_HW_PRE and IT_DISCO_SW_PRE). When using this method, keep in mind the following points:
This method does not require a tightly coupled XML connector or dependence upon a preexisting partnership with a particular discovery supplier to populate the pre-staging tables.
The web service (PROCESS_DISCOVERYDATA) populates the pre-staging tables and submits the IT_LOAD_PRE Application Engine process automatically; however, reprocessing of web service errors is submitted from the Integrate Discovery Data run control page.
The web service implements an xml file-counting solution, which leverages the xml node FILE_CNT. After receiving all of the xml files, the IT_LOAD_PRE process is submitted automatically.
Do not introduce duplicate or invalid Serial IDs in the xml. An example of an invalid Serial ID might be a blank value.
Ensure that the BATCH_ID node value is the same throughout the XML file.
Use the Integrate Discovery Data run control page to submit the IT_ LOAD_PRE Application Engine process when the pre-staging tables are populated manually by a custom program. Additionally, this page can be used to process pre-staging errors resulting from either method (manual or web service).
Use the Integrate Discovery Data page (IT_PLOAD_RUN ) to set run control options to submit the IT_LOAD_PRE Application Engine process, Select to process all Batch IDs and all errors or specific Batch IDs and errors.
Navigation:
This example illustrates the fields and controls on the Integrate Discovery Data page. You can find definitions for the fields and controls later on this page.
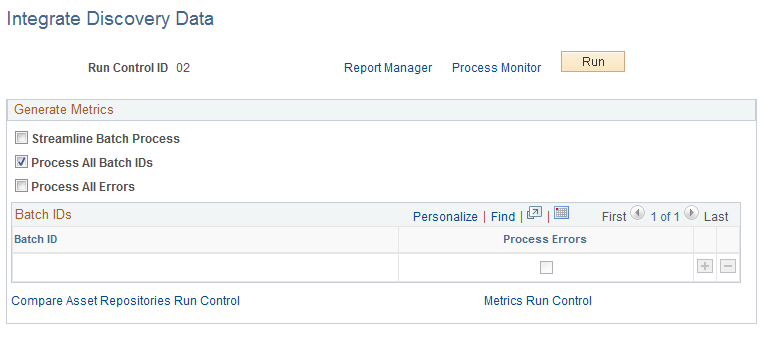
Field or Control |
Description |
|---|---|
Streamline Batch Process |
Select to enable the option to automatically submit (streamline) the Compare Asset Repository and Generate Metrics processes. |
Process All Batch IDs |
Select to process all the unique Batch IDs in the pre-staging table. When selected, any existing rows in the grid are disabled. The IT_LOAD_PRE batch program processes all data in the pre-staging tables and overrides the Batch IDs that are specified in the grid. However, if there are rows in the grid where Process Errors is selected, the errors related to that Batch ID are also included as input for the IT_LOAD_PRE batch process. |
Process All Errors |
Select to process all the rows in the pre-staging error tables. When selected, the Process Errors check box is disabled in any existing grid row, The IT_LOAD_PRE batch program processes all data in the pre-staging error tables. It overrides the Process Errors option at the grid level. |
Batch IDs
Field or Control |
Description |
|---|---|
Batch ID |
Select one or more specific BATCH_IDs for the IT_LOAD_PRE Application Engine program to process. If the Process All Batch IDs check box is selected, this field is disabled. |
Process Errors |
Select to specify if pre-stage errors are to be processed for the selected BATCH_ID. If Process All Batch IDs or Process All Errors is selected, this field is disabled. |
Field or Control |
Description |
|---|---|
Compare Asset Repositories Run Control and Metrics Run Control |
Click the links that are provided to access the Compare Asset Repository and Generate Metrics run control pages. Verify or change the run control parameters for the two automatically-created run controls. |
Note: When using the web service to populate the pre-staging tables, the IT_LOAD_PRE process is launched automatically when all the xml files are received successfully by Integration Broker. The user ID that is used to automatically submit the process is the user ID that is specified by the publishing Integration Broker node (&From Message Credential). If the user ID that is defined on the external node is used to enter the run controls on the Integrate Discovery Data page, and if a Web Service is received that has the same RUN_CNTL_ID, it will take precedence over the one entered on the page. (The Web Service utilizes the same tables to store the run control parameters. In this example, the records that are entered on the page are replaced by the parameters in the Web Service. The records are then deleted when the Web Service is processed).
The following table provides a description of the preload errors that can result from the edits performed by the IT_LOAD_PRE Application Engine process:
|
Preload Errors |
Description |
|---|---|
|
Orphan Software error (100) |
This is the first edit that is performed. It is only performed when directly populating the pre-staging tables using a custom program. This is done in order to validate the parent/child relationship for hardware and software data. To fix this error, a parent hardware record is needed. A record could be inserted in the IT_DISCO_HW_ER2 table; or, if resubmitting all of the data, the record should be inserted in the IT_DISCO_HW_PRE table. |
|
Software Title/Known As Mapping error (090) |
This is the next edit performed (first one for the Web Service option). To fix this error, ensure that the KNOWN_AS value in the xml is mapped on the ITAM Code Mappings page. Add the mapping and then use the run control page to reprocess the errors. |
|
IT Resource Mapping error (080) |
This is the third edit that is performed. To fix this error, ensure that you have the IT_RESOURCE value mapped on the IT Subtype page. It should be an active Third Party Value that is listed in the grid. |
Run the delivered query, AM_IT_PRE_LOAD_ERRORS, to retrieve a report that lists the Serial IDs of the devices that fail any of the preload (pre-stage) error edits resulting from the IT_LOAD_PRE process. ITAM requires that Serial IDs be unique in each application in order to successfully integrate the discovered assets into ITAM. This query identifies duplicate Serial IDs.
Use the IT Assets Pre-load Errors page (AM_IT_PRE_LOAD_ERRORS) to run this query to identify errors from the IT_LOAD_PRE process.
The query lists the Serial IDs of the devices that fail any of the pre-stage error edits.
Navigation:
This example illustrates the fields and controls on the AM_IT_PRE_LOAD_ERRORS query.

The report provides the following fields Serial ID, IT Load Error Code, Third Party Value and Source Key ID.