Understanding Data Distribution Framework
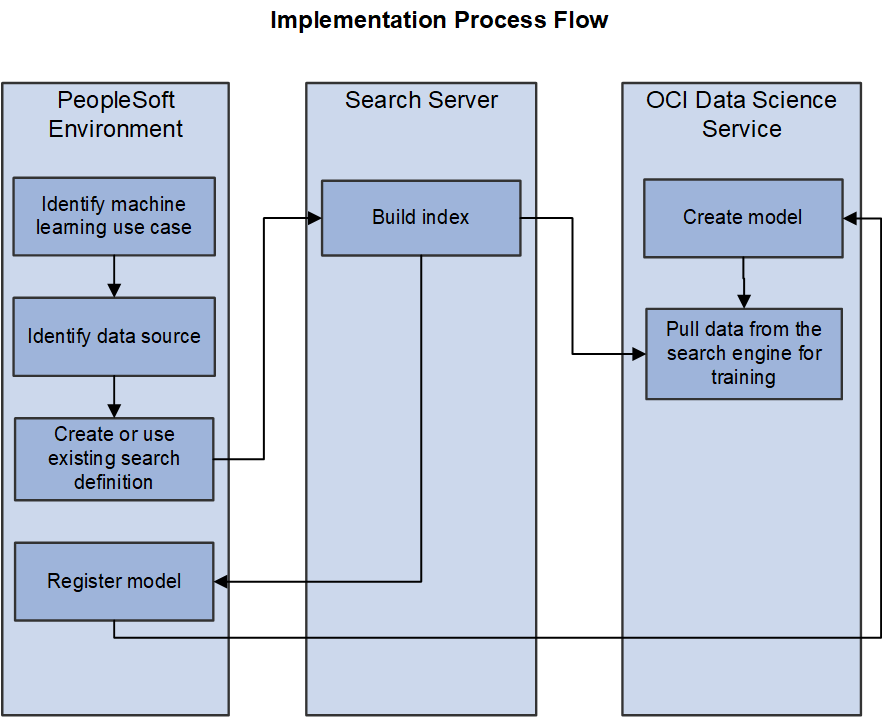
The data distribution framework enables PeopleSoft users to build index and register a model. In PeopleSoft, a search definition is the primary data definition, which mines data using PSQuery or connected query as a data source. Search engine then builds an index and maintains indexes. PeopleSoft enables you to register a model created in OCI Data Science service.
The process flow involves the following steps:
PeopleSoft sends data to the search engine using Direct Transfer.
OCI Data Science service pulls data from the search engine.
The data is used to train the machine learning model in the Jupyter notebook on the OCI Data Science service.
When the model is created, it can be saved in the OCI object storage.
The saved model can be deployed as a REST service using OCI Functions and OCI API Gateway.
PeopleSoft registers the REST endpoint.
The following diagram illustrates the process flow among PeopleSoft, search server, and OCI Data Science service.
This documentation covers the tasks that are performed in PeopleSoft. For tasks that should be performed on the OCI Data Science service, such as creating a model, deploying model as REST service and so on, refer to the OCI Data Science documentation on Oracle Cloud Infrastructure Documentation website.
PeopleSoft provides a navigation collection – Data Distribution Setup – that enables you to perform the following tasks:
Set up data source.
Specify OCI Data Science server.
Build an index in the search engine.
Register a model.