Setting Up Auto Scaling
Cloud Manager integrates with Oracle Data Science services to take advantage of machine learning techniques. This enables Cloud Manager to learn from past usage and detect the current state and take corrective action if any, so that your users experience smooth, reliable performance.
Auto Scaling Prerequisites
Prerequisites include:
Subscription to Oracle Data Science.
Set up Data Science in OCI.
See the tutorial Create Data Science Resources for Auto Scaling in Cloud Manager (Optional) at https://docs.oracle.com/en/applications/peoplesoft/cloud-manager/index.html#InstallationTutorials.
Configure Data Science in Cloud Manager Settings.
Enable Monitoring Flag in Cloud Manager Settings Page.
Setting Up the Target Managed Instance
The environment that is managed by the auto scaling policy must meet these requirements:
Target managed instance must include OpenSearch (or Elasticsearch) instance with OpenSearch Dashboards (or Kibana).
Note: The search server machine (OpenSearch or Elasticsearch) should have network access to connect to OCI telemetry (monitoring) API. The custom image used for OpenSearch or Elasticsearch must include OCI Python SDK. The Marketplace Linux image includes the OCI Python SDK.
Target managed instance must be on PeopleTools 8.58 or above.
Enable Monitoring on the target managed instances.
There are several ways to enable monitoring for an environment:
Enable monitoring on the template used to create the environment.
Enable monitoring after the environment is created.
This starts collecting performance data and indexes that information in an OpenSearch (or Elasticsearch) instance.
Train the system with a minimum load of typical business transactions for at least 3 or 4 weeks in order to collect enough samples for prediction.
Note: When the number of database connections exceeds the number of available processes, the connection may fail intermittently, resulting in ORA-12520 error. This error can be resolved by increasing the value of process parameter.
See Intermittent TNS-12520 or TNS-12519 or TNS-12516 Connecting via Oracle Net Listener (Doc ID 240710.1) and JDBC Connections Fail with ORA-12520 (Doc ID 2660207.1) for more information.
ECL_DATA_UPD runs weekly to collect performance data for the instance and pushes the performance data to the Object Storage bucket.
ECL_ML_JOBS runs weekly to pull this performance data, train the model and publish the Machine Learning Model in Data Science.
Adding Auto Scaling Policy
Once the Data Science model is trained, define the auto scaling policy.
For an auto scale policy, use the following:
This example shows the Add Policy page with a sample Auto Scale policy.
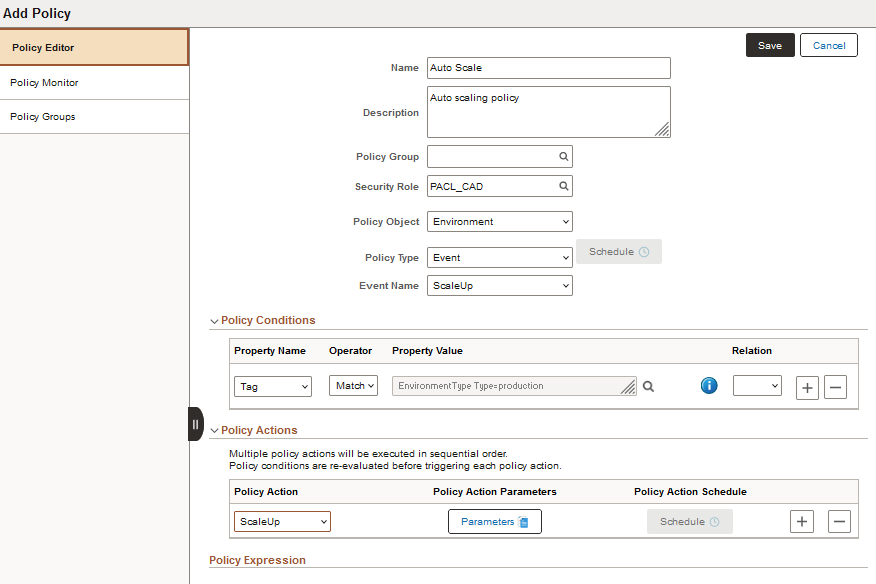
|
Field |
Value |
|---|---|
|
Policy Object |
Environment |
|
Policy Type |
Event |
|
Event Name |
ScaleUp (positive anomaly) or ScaleDown (negative anomaly) |
|
Policy Conditions |
Select the environments by name or tag. |
This example illustrates the Policy Action Parameters page for ScaleUp.
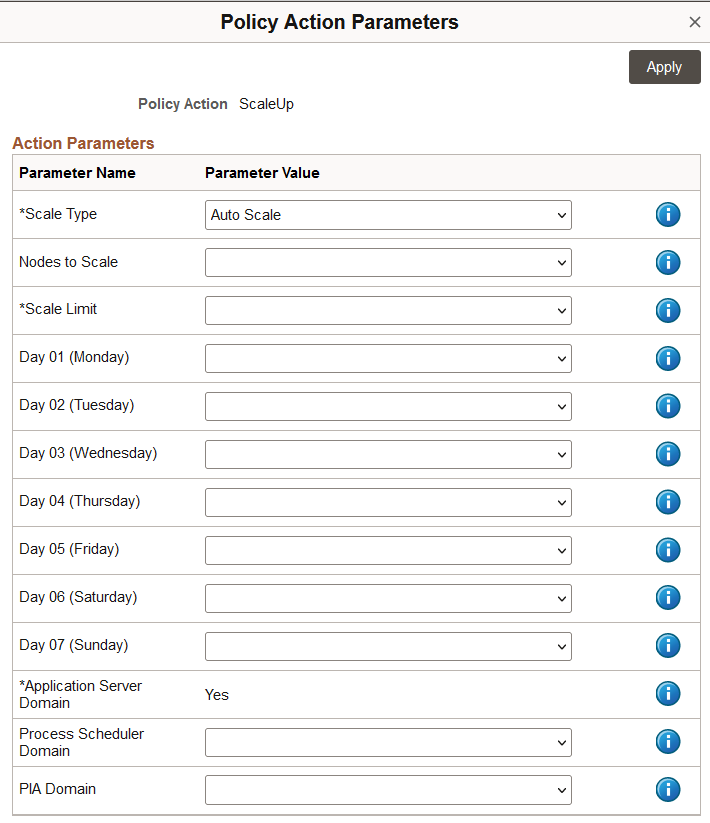
|
Field or Control |
Description |
|---|---|
|
Scale Type |
Select Scale Type:
|
|
Nodes to Scale |
Number of nodes to be scaled. Set to Auto when deploying an auto scale policy. |
|
Scale Limit |
For a ScaleUp policy set this field to the maximum number of nodes that can exist in the environment. For a ScaleDown policy set this field to the minimum number of nodes that should remain on the environment. |
|
Day 01 (Monday) through Day 07 (Sunday) |
Select the desired number of nodes for the day. |
|
Application Server Domain |
Select Yes to scale Application Server Domain. (Required) |
|
Process Scheduler Domain |
Select Yes to scale Process Scheduler Domain. |
|
PIA Domain |
Select Yes to scale PIA Domain. |
Detecting Anomaly
When environment monitoring is enabled, Cloud Manager will send performance data every 5 minutes to Data Science prediction API.
If Scaling policies are active and Scale Type is set as Auto Scale, when there is a confirmed positive anomaly, additional nodes(s) will be added. Adding a new node typically takes 15 to 20 minutes.
System will add nodes until the Scale Limit set in the Scale Up policy is reached in case of successive scale up events.
After a scale up event is triggered, the system, by default, waits a lock down period of three hours before bringing the system back to the base configuration by removing nodes. The system needs to detect a negative anomaly after the lock down period in order for the system to remove nodes. System will remove nodes until the Scale Limit set in the Scale Down policy is reached.
Note: Nodes can be removed below the base configuration level if the Scale Limit for a Scale Down event is less than the number of nodes in the original environment.
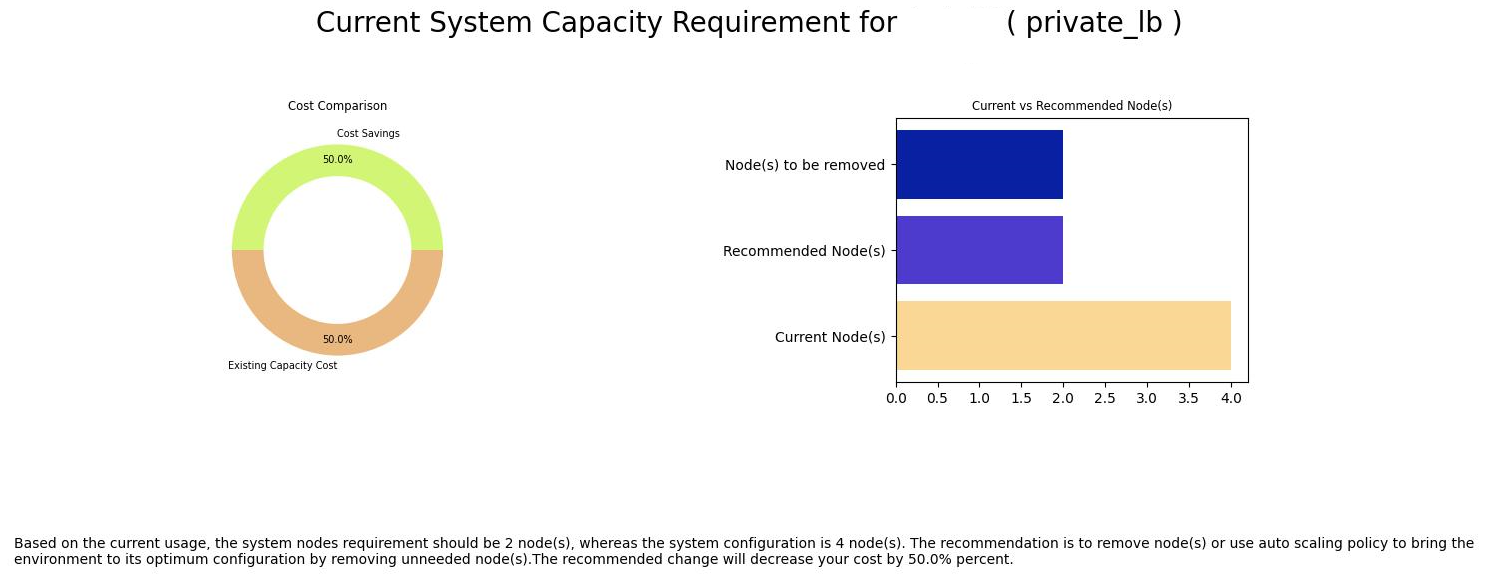
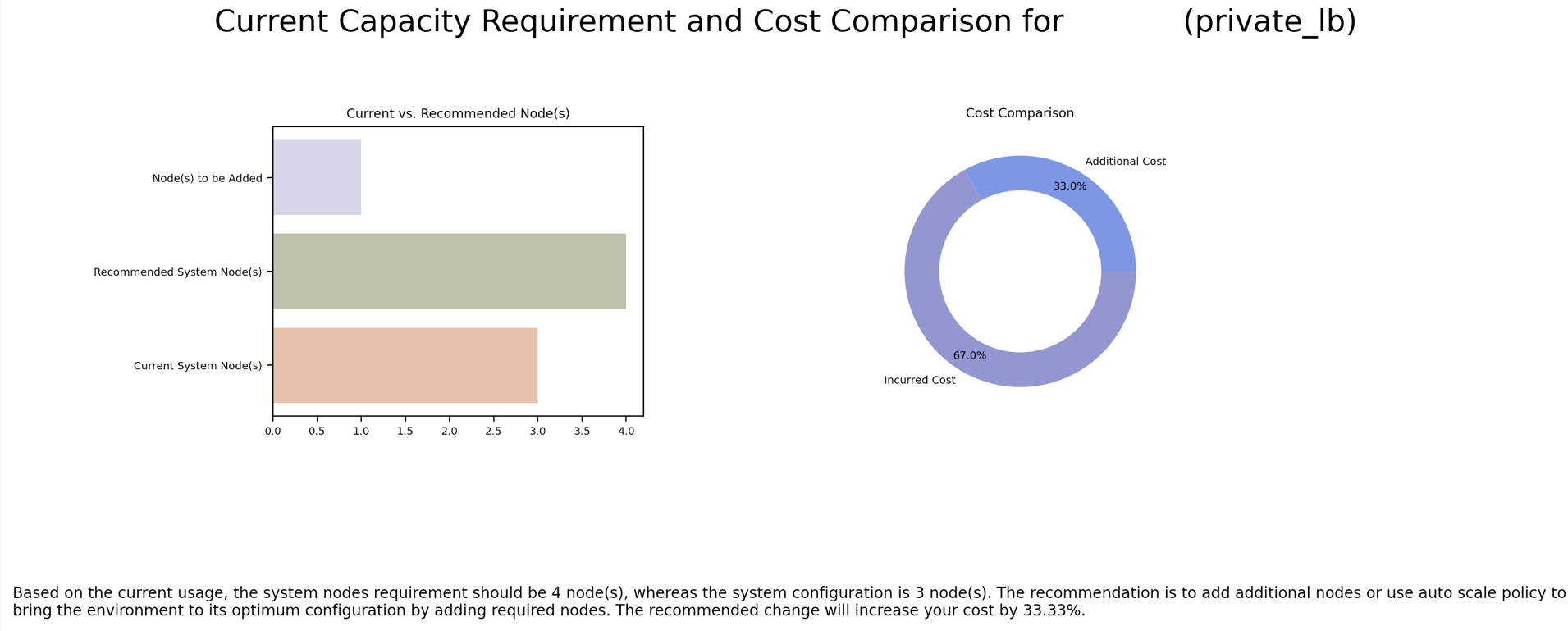
If Scaling policies are active and Scale Type is set as Notification, a notification will be sent to you when there is a confirmed positive or negative anomaly. The notification can also be viewed in the notifications alert window. You must manually take corrective action based on the notification. On clicking the notification, you can view a graph that includes recommendations for increasing or decreasing the number of nodes according to the current capacity and usage.
This example illustrates the chart representing the current capacity requirement and cost comparison for adding nodes to an environment. It appears on clicking the notification specific to an environment on the Alerts section under Notification panel on the home page.
This example illustrates the chart representing the current capacity requirement and cost comparison for removing nodes from an environment. It appears on clicking the notification specific to an environment on the Alerts section under Notification panel on the home page.