抽出コンポーネント
HCM抽出機能は、データ・ファイルおよびレポートを生成するための柔軟性のあるツールです。 このトピックでは、抽出コンポーネントを使用して、アプリケーションで抽出したりレポートする情報を定義する方法について説明します。
抽出定義
抽出定義とは、抽出データ・グループ、基準、レコード、属性、拡張条件および出力提供オプションで構成される抽出の完全な設定を指します。 抽出定義は次のもので構成されます。
-
抽出する論理エンティティの数に応じて、1つ以上の抽出データ・グループ。
-
収集する情報のグループの数に応じて、1つ以上の抽出レコード。
-
収集するデータの個別フィールドの数に応じて、1つ以上の属性。
HCM抽出を使用して、Oracle Fusion HCMデータベースから大量のHCMデータを抽出、アーカイブ、変換、レポートおよび提供します。 出力は、次の形式で生成できます。
-
CSV
-
XML
-
Excel
-
HTML
-
RTF
-
PDF
データ・グループ
拡張データ・グループは、個人、アサイメント、福利厚生などのビジネス・エリアまたは論理エンティティを表します。 アプリケーションは、この情報を使用してデータベース・アイテム・グループを取得します。 1つのデータ・グループをプライマリまたはルート・データ・グループとして定義し、このデータ・グループがデータ抽出の開始ポイントとなります。
抽出データ・グループ接続は、現在のデータ・グループと親データ・グループの間の関連詳細を収集します。 データ・グループ接続によって、データ・グループ間の階層関係が形成されます。
抽出データ・グループ基準を使用して、抽出データ・グループに対してアプリケーションで実行する必要がある一連のフィルタリング条件を定義できます。 基準条件は、式またはFastFormulaを使用して指定します。
抽出レコード
抽出レコードは、抽出に必要なすべてのフィールドの関連データまたは物理コレクションのグループ化を表します。 たとえば、従業員データ・グループには、基本詳細、支払詳細、事業所詳細、プライマリ連絡先などのレコードを設定できます。 抽出レコードは、必要な順序で編成できる属性のコレクションです。 たとえば、データ・グループに3つのレコードがある場合、アプリケーションがレコードを処理する順序を指定できます。 次のデータ・グループを選択して、アプリケーションが次にどのデータ・グループを処理するかを指定することもできます。属性
属性は、抽出レコード内の個別フィールドです。 HCM抽出の最下位の属性レベルであり、個人名、個人姓、個人生年月日などの情報を表します。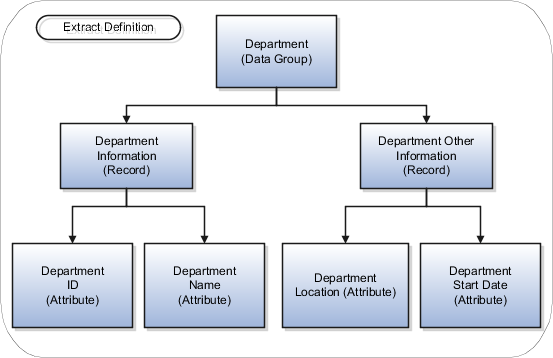
スレッド・データベース・アイテム
スレッド・データベース・アイテムは、抽出されたレコードを一意に識別するための特定のユーザー・エンティティの一意の識別子です。 スレッド・データベース・アイテムを構成すると、「変更のみ」抽出の変更の比較および識別がいっそう効率的に実行されます。 ルート・データ・グループまたは子データ・グループ・レベルで1つのスレッド・データベース・アイテムを定義できます。
条件付き処理
条件付き処理は、条件付き式または事前定義済FastFormulaの結果に基づいて、実行する処理を識別し、必要に応じてメッセージを出力します。 条件付き処理は、抽出前に適用される基準条件と同様に、抽出済データに適用されます。 処理およびメッセージは参照に事前定義されていますが、参照に新規値を作成すると、独自のメッセージを追加できます。条件が満たされると、この機能を使用して特定の事前定義済処理を実行できます。 たとえば、事前定義済の国から来たすべての従業員など、条件を満たす従業員を除外できます。 従業員の給与がブランクまたは特定のレベルを超えている場合に警告を発行するようにこの機能を構成することもできます。
抽出実行の実行時パフォーマンスに悪影響を及ぼす可能性のある条件付きアクションを使用しないことを強くお薦めします。
除外ルール
除外ルールを使用して、要件に合わないレコードを除外したり、独自のレコードで上書きできます。 抽出プロセスでは、除外されたレコードを国別仕様データ・グループに基づいて処理しません。
除外ルールは、レコードが除外されるときにトラブルシューティングが非常に困難であるため、使用しないことを強くお薦めします。 かわりに、BIパブリッシャ・テンプレートを使用して条件付き処理および除外ルールを処理してください。