HCMデータ・ローダー(HDL)を使用したバルク・データのインポート
HCMデータ・ローダーを使用してバルク・データをインポートする統合を設計できます。 このユースケースでは、概要を説明します。
- Oracle HCM Cloud情報を含むJSONサンプルを提供するRESTアダプタを作成します。
- 「リソース構成」ページで、エンドポイントURI、エンドポイントで実行するアクション(この例ではPOST)および構成オプションを指定します。 この例では、「このエンドポイントのリクエスト・ペイロードの構成」および「レスポンスを受信するようにこのエンドポイントを構成」が選択されています。

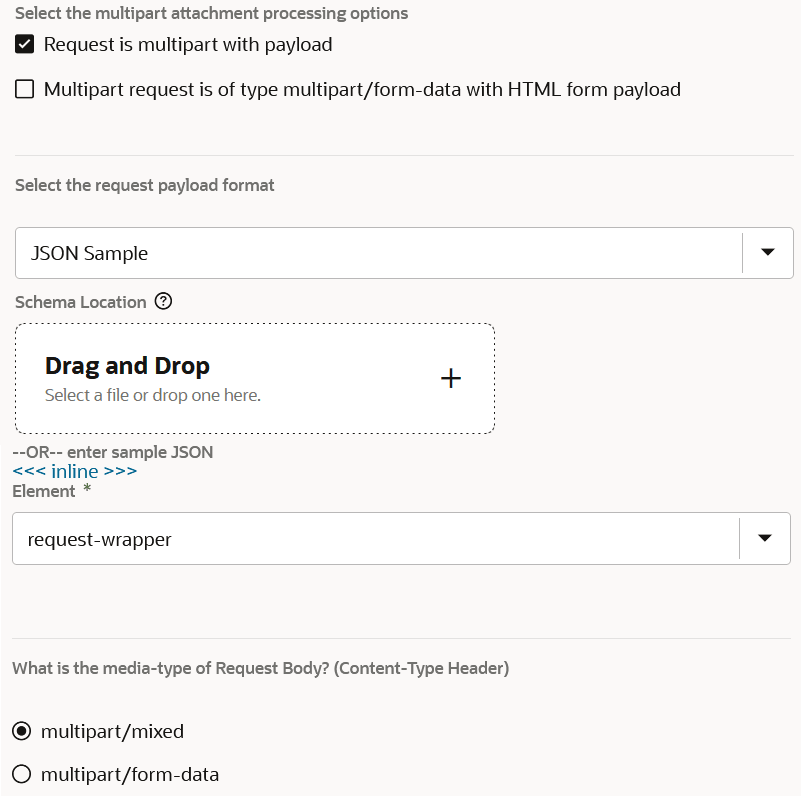
- リクエスト・ページで、マルチパート・アタッチメント処理オプション(この例では、「リクエストはペイロードでマルチパートです」が選択されています)、リクエスト・ペイロードの形式とファイル(この例では「JSONサンプル」)およびリクエスト本文のメディア・タイプ(この例では、multipart/mixed dが選択されています)を指定します。
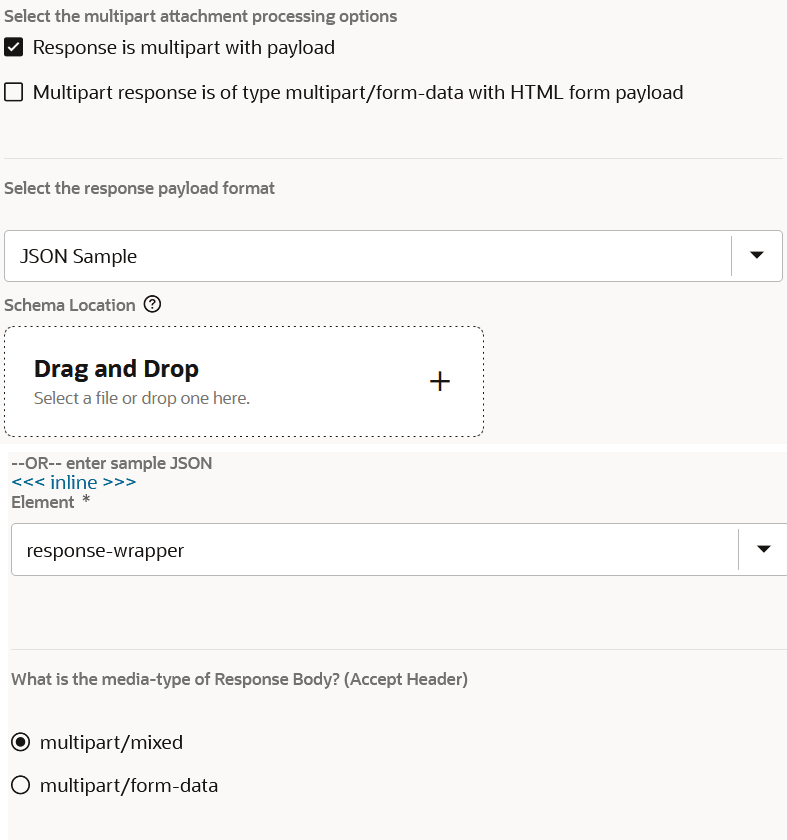
- レスポンス・ページで、マルチパート・アタッチメント処理オプション(この例では、「レスポンスはペイロードでマルチパートです」が選択されています)、リクエスト・ペイロードの形式とファイル(この例では「JSONサンプル」)およびリクエスト本文のメディア・タイプ(この例では、multipart/mixed dが選択されています)を指定します。
- 「リソース構成」ページで、エンドポイントURI、エンドポイントで実行するアクション(この例ではPOST)および構成オプションを指定します。 この例では、「このエンドポイントのリクエスト・ペイロードの構成」および「レスポンスを受信するようにこのエンドポイントを構成」が選択されています。
- Oracle HCM Cloudアダプタを統合に追加します。
- アクション・ページで、「HCMデータ・ローダー(HDL)を使用したバルク・データのインポート」を選択します。

- 操作ページで、「HCMデータ・ローダー・ジョブの発行」を選択します。

- アクション・ページで、「HCMデータ・ローダー(HDL)を使用したバルク・データのインポート」を選択します。
- リクエスト・マッピングの場合、必要なエレメントをソースからターゲットにマッピングします。 「添付参照」は「ファイル参照」にマップされ、「添付ファイルのプロパティ」は追加のプロパティを送信するために「ファイル名」にマップされます。

- レスポンス・マッピングの場合、必要な要素をソースからターゲットにマップします。 「プロセスID」はHDL PROCESS IDにマップされます。 ターゲットのSTATUS要素は「開始済」に設定されます。
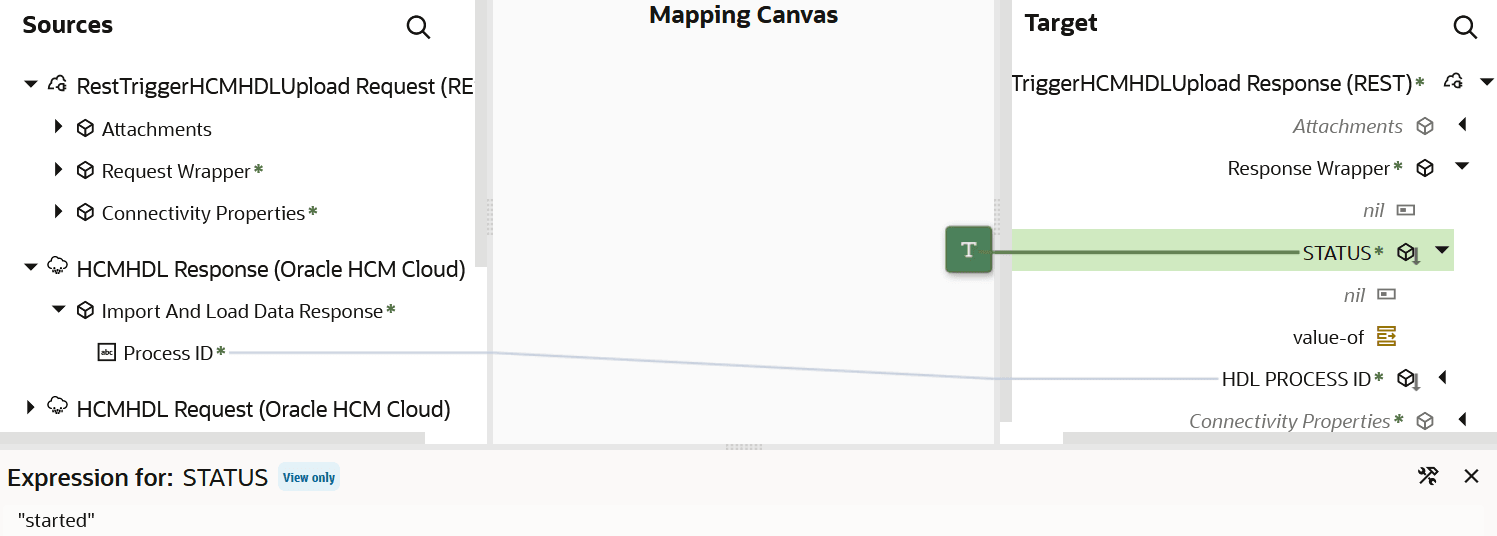 完成した統合は次のようになります。
完成した統合は次のようになります。