類似アカウント・モデルの作成
独自の類似アカウント・モデルを作成する方法を次に示します。
- 「機械学習モデル」ページにナビゲートします。
- 「機械学習モデル」ページで、「処理」(ハンバーガー・アイコン)をクリックし、「類似アカウント」モデルの「複製」を選択します。
処理により、事前定義済モデルのコピーが「ドラフト」ステータスで作成されます。
- 「基本情報」ステップで、名前と摘要を入力します。 これらは管理ページにのみ表示されます。

- 「次」をクリックします。
- 「属性の選択」ページには、次に示すように、Oracleによって提供されるモデルの属性がリストされます:
.
- モデルで使用する属性を有効または無効にします。 たとえば、Oracleが提供するモデルには、属性の1つとして郵便番号が含まれます。 個別の値が多すぎると、モデルの有用性が低下し、実行が遅くなります。したがって、たとえば複数の国で販売している場合は、郵便番号を削除してください。
- 「アクション」領域で、チェック・ボックスを選択または選択解除して、不要な属性を有効または無効にします。
- 検索フィールドを使用して、関連オブジェクト属性を追加します。
- 「データの準備」をクリックして、選択した属性からモデルを作成するのに十分なデータが存在するかどうかを検証します。
検証プロセスの実行中に、機械学習ページの「ステータス」列に「実行中」ステータスが表示されます。
-
ステータス変更を確認するには、「リフレッシュ」をクリックします。
- ステータスが「エラー」の場合、モデルに選択した一部の属性に十分なデータがないことを意味します。 少なくとも30%のレコードに属性の値が必要です。 操作方法:
- モデルの名前リンクをクリックします。
- 「属性選択」ステップをクリックして、エラーのリストを表示します。
- 使用できない属性を削除します。
- 「データの準備」を再度クリックします。
- モデルが「準備済」ステータスの場合、モデルをさらに分析および調整するのに十分なデータがあります。
- 「次へ」をクリックして、「データ機能」ステップに移動します。
- 任意の属性のをクリックして、値を分類することでモデルを微調整します。
- 「計算タイプ」ページでは、モデルで考慮するカテゴリを1つ以上指定できます。 カテゴリは、モデルの学習方法およびレコードのクラスタの作成方法に影響します。 たとえば、モデルに特定の属性に対する一意の値が多すぎることがわかった場合は、ここでそれらをグループ化できます。 使用可能な計算タイプは、属性によって異なります。
- 経過日バケット: この計算タイプは、作成日などの日時属性に使用します。 日付ではなく、0-1年、1-2年、2-3年などで経過グループを定義できます。 その結果、モデルでは、構成された経過グループ内で類似アカウントが検索されます。
- 数値バケット: この計算タイプは、潜在的売上や組織規模などの数値属性に使用します。 たとえば、ディール金額で検索するかわりに、0から100,000、100,000から200,000などの均等範囲の数値バケットを作成できます。 モデルでは、構成された数値バケット内にディール金額がある類似アカウントが検索されます。
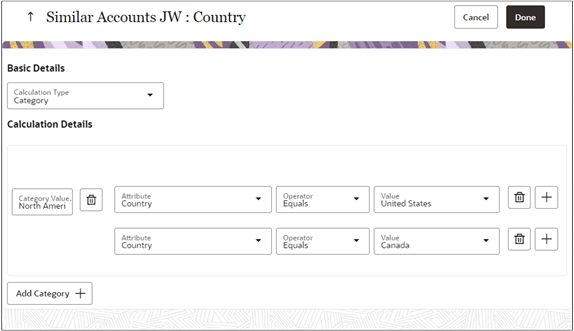
- カテゴリ: この計算タイプを使用して、属性条件に基づいてカテゴリを作成できます。 たとえば、国をラテン・アメリカ、北米、アジア太平洋およびヨーロッパとしてグループ化することで、アカウントを世界の地域別に分類できます。 または、商談売上または組織規模を使用して、アカウントを大、中、小に分類できます。
- 次に、ビジネスを行う国を地理的地域別に分類する方法を示します。
- 国のをクリックします。
- 「計算タイプ」リストから、「カテゴリ」を選択します。
- 「カテゴリ値」フィールドに、North Americaと入力します。
- 「演算子」リストから、「次と等しい」を選択します。
- 「値」フィールドで、North Americaのいずれかの国を検索して入力します。
- 「別のルールの追加」(プラス記号)をクリックし、2番目の国を追加します。
- カテゴリのすべての国を追加するまで、プロセスを繰り返します。
- 「カテゴリの追加」をクリックして、カテゴリを追加します。
- 「完了」をクリックします。
- 計算タイプの追加が完了したら、「送信」をクリックしてモデルを実行します。
- ステータスをリフレッシュするには「リフレッシュ」をクリックします。
- モデル・ステータスが「実行中」から「準備完了」に変わったら、をクリックします。 「処理」メニューは、ページの右側にあるハンバーガー・アイコンです。
- 「レビュー」ステップをクリックして、選択したアカウントについてモデルが検索する類似アカウントを確認します。
- 「アカウント」フィールドから、モデルによって予測される類似アカウントを表示するアカウントを選択します。
- 「分析」をクリックして、分析レポート・ページでモデルに関する情報を確認します。
-
レポートには、モデルの改善方法に関するヒントが含まれています。 たとえば、一意の値が少なすぎるフィールドや、一意の値が多すぎるフィールドがあることがレポートに示されます。
フィールドの値が少なすぎる場合は、より多くのデータをインポートするか、その属性をモデルから削除することが必要になります。 値が多すぎる場合は、「機能」ステップでそれらをカテゴリにグループ化する必要があります。
その他の有用な情報を次に示します。
- 選択済アルゴリズム: モデルに対して実行されたアルゴリズム。 このアルゴリズムは、データと選択したユース・ケースに最適化された最適なモデル・パフォーマンスを実現するために自動選択されます。 アルゴリズムを変更できないため、現時点ではこのフィールドは無視できます。 ノート: 25Dリリース以降、選択したアルゴリズムを手動で上書きして、特定のアルゴリズムを使用してモデルを実行できます。 モデルが再構築されるたびに、選択したアルゴリズムを手動で選択できます。 2つの異なるモデル実行間でデータ・セットが大幅に変化する場合は、最適なアルゴリズムが自動的に選択されます。
- モデル正確性: モデルの正確性をパーセンテージで表示します。 優れたモデル正確性は90%を超えます。 値が小さい場合は、属性を変更して正確性を向上させます。
- クラスタ数: モデル内のアカウントのグループの数。 モデル内のクラスタが多いほど、類似したアカウントが少なくなります。 クラスタの数は20個程度が適当です。
- 「データ分析」タブには、各属性の個別値の数や空の値の割合などが表示されます。
- 「モデル分析」タブには、クラスタの数とその分布の円グラフが表示されます。
- 選択済アルゴリズム: モデルに対して実行されたアルゴリズム。 このアルゴリズムは、データと選択したユース・ケースに最適化された最適なモデル・パフォーマンスを実現するために自動選択されます。 アルゴリズムを変更できないため、現時点ではこのフィールドは無視できます。
- 「次」をクリックします。
- 「デプロイ」ページ: モデルおよび繰返しスケジュールの実行を開始する日時を入力します。
- 日時: スケジュールを開始する日時を入力します。
- 繰返し: データ変更の頻度に応じて、モデルを再作成する頻度を設定します。
- 日次
- 週次
- 月次
- 「デプロイ」をクリックします。
モデルがアクティブになります。
ノート: アクティブにできるのは、一度に1つのモデルのみです。 アクティブなモデルがすでにある場合は、置き換えることを確認する必要があります。