Importing Case Record Data
Overview of Importing Case Record Data
Case Record Data upload may be used when data is mined and prepared in an external system and imported into Oracle Adaptive Intelligence for Manufacturing for quick analysis to obtain insights and predictions on historical data and in-progress work orders. Case Record Data files captures the work order data in a flattened file format. Each row in the spreadsheet corresponds to one work order and contains all related entities data like items, operation, routing, and so on, in the same row. Work order records with an actual end date are considered as completed work orders and the records are used for insights analysis. Work order records with no actual end date are considered current in-progress work orders and the records are used for predictions analysis.
Note: While you can bring in historical work orders, or in progress work orders using the case record data ingestion method, note that pending work orders, or operations that are pending are not included.
The data file contains context data which includes information on item, BOM, operation, transactions, and so on. It also includes details of input predictors and target test results. This ingested data can be analyzed to identify key patterns and correlations that affect manufacturing efficiencies. The data ingested through this template, can be used in the Insights and the Predictions module.
If you only plan to use the Insights and Predictions features, consider using the Case Record Data upload. Other key features like Genealogy and Trace, and Factory Command Center cannot be used with data imported through Case Record Data files.
The Case Record Data file uploads data for the following entities:
-
Creates setups required for the business context such as Item, Recipe, Routing, and so on.
-
Uploads transaction records such as work order, serial transactions, and so on.
-
Uploads attributes which could be targets or input features.
-
Enables quick creation of a data set using the uploaded data.
Select to use Case Record Data:
-
When flattened records are already available.
-
For the flexibility of stitching data outside AIAMFG.
-
For the flexibility of creating features outside AIAMFG.
-
For simpler ingestion of data into AIAMFG using the single CSV template that is provided.
-
When a quick track analysis is required.
-
For initial proof of concept validation.
Note: Select to first use case records data for insights before using business entity data.
Case Record Data Import Steps
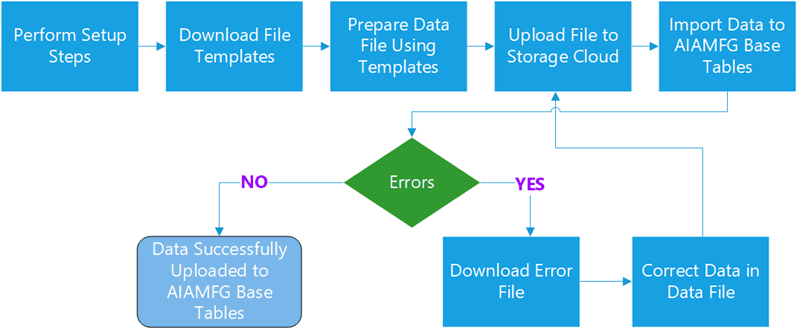
-
Perform the setup steps required to import data.
-
Download the file templates for either a process or discrete organization.
-
Prepare or enter the data into CSV files following the template guidelines.
-
Submit the file for upload to Oracle Storage Cloud Service.
-
Run the data import program to import data into the target base tables.
-
If errors occur, download the error file, correct the data, remove the error message columns, save the error file as a new CSV file, and then upload the file again.
Uploading CSV Files Using the Case Record Data User Interface
Oracle Adaptive Intelligent Apps for Manufacturing provides specific templates which you can download and use to add case record data information. You can use the Case Record Data user interface to download the provided data and metadata templates, add data to these templates, and save the files in the CSV format. You can then upload the saved files, and create a dataset for further analysis.
To use the Case Record Data page
-
Navigate to the Data Ingestion Page.
From the Home Page, click Insights or Predictions, then click the Data Ingestion link, and then Case Record Data.
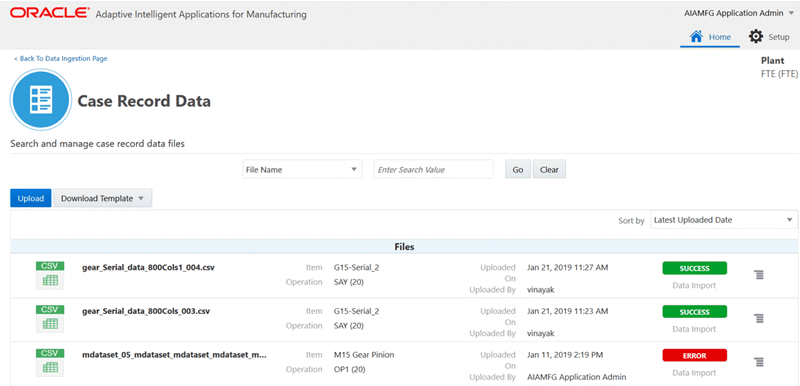
Click Download Template to download the Case Record Data template. Click Upload to upload a case record data file in the CSV format.
To download file templates
-
In the Case Record Data page, click Download Template.
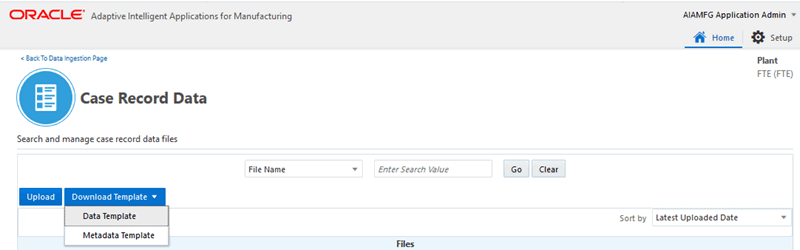
You can download the following Case Record Data templates:
-
Data Template - Use the DataTemplate.xlsx that is downloaded in your local system to enter mandatory context information like item number and operation code, reference information like work order number and actual start date, and the attributes.
Note: Enter the actual end date for completed work order records to ensure the records are used for insights analysis.
Leave the actual end date blank for in-progress work orders to ensure the records are used for predictions analysis.
-
Metadata Template - Use the MetaDataTemplate.xlsx that is downloaded in your local system to enter optional attribute metadata information like attribute name, category, data type, unit of measure, and so on.
Based on the organization type of the context organization, either a discrete manufacturing or a process manufacturing template is downloaded.
Use the instructions in the ReadMe and Field Information sections of the template to enter the required information.
-
-
On completion of Case Record Data entry in the data and metadata spreadsheest, save the file in a CSV format. It is required that the data be entered in the same format as defined in the template for processing to be completed successfully.
-
In the Case Record Data page, click the Upload Button to upload the Case Record Data file you have saved
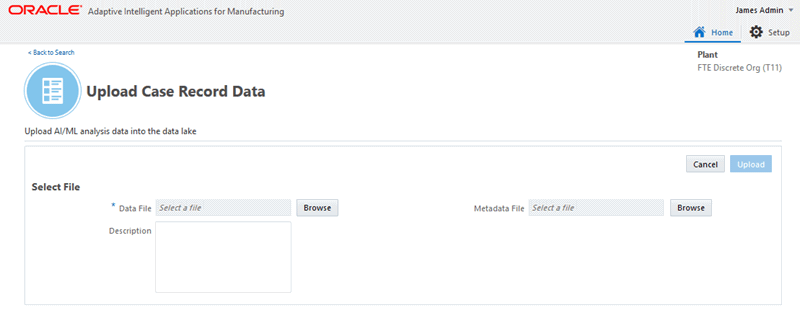
To upload a Case Record Data file you will complete the following steps:
-
Browse and select the data file to be uploaded.
-
Optionally, browse and select the metadata file to be uploaded.
-
Review the context and attributes derived from the uploaded data and make changes if required.
-
Upload the file for processing.
-
-
In the Select File region use the following fields:
-
Data File to select the data file you want to upload. Click Browse and then choose the CSV spreadsheet from the local system. This is a mandatory step.
-
Description to enter a meaningful description to represent the data upload.
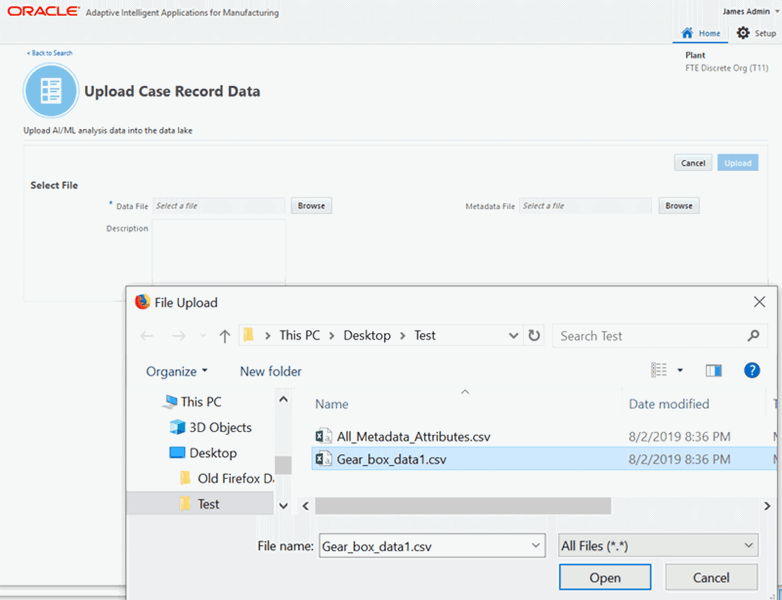
-
-
In the Context region, review the data context information that displays.
The data context is extracted from the data uploaded in the spreadsheet. The data context information is part of the standard mandatory columns. Enter the first row to provide the context information. Any additional rows with context information is ignored. Note that you will upload one file for a single context information.
The context information that displays for your review consists of the following fields:
-
For discrete manufacturing organizations:
-
Item Number
-
Operation Code
-
Item Description
-
BOM Type
-
BOM Revision
-
Routing Type
-
Routing Revision
-
Operation Sequence Number
-
-
For process manufacturing organization:
-
Item Number
-
Operation Code
-
Item Description
-
Item Category
-
Item Revision
-
Recipe Number
-
Recipe Revision
-
Step Number
-
-
-
In the Attributes region, you can search for attributes, and review the information in the All tab which shows information of all attributes derived from the data file you uploaded.
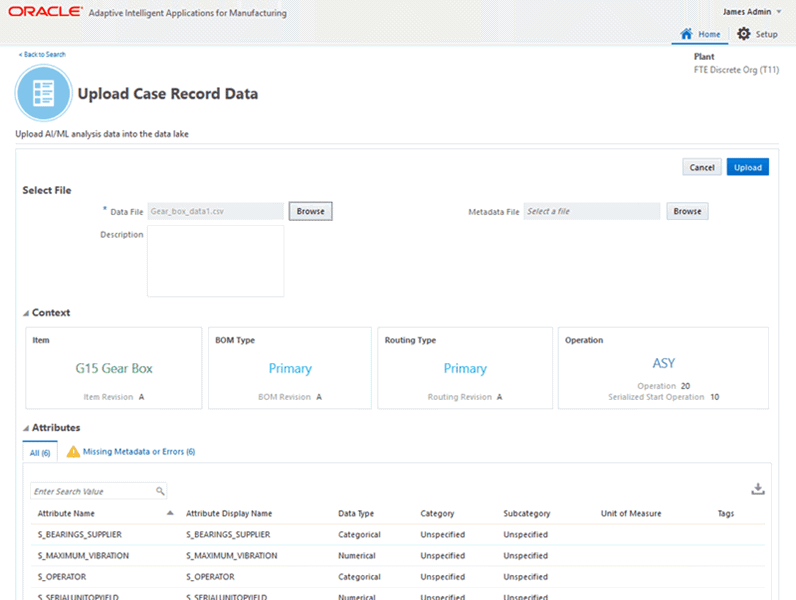
Also, in the Attributes region, the Missing Metadata or Errors tab shows the attributes that have not passed validation. You can view the following attributes for missing information, or invalid value or format, or an incorrect value:
-
Attribute Name - This is mandatory. Ensure that the name of the attribute matches the column name in the case record data template.
-
Attribute Display Name - The display name of the attribute. If the display name is not provided, the value defaults to the attribute name.
-
Data Type - Values can be numerical or categorical. If no value is provided in the metadata file, the data type of the attribute is derived from first 100 records in the data file. If there are no values for the first 100 records for an attribute in the data file, the data type displays as Unknown. You can then use the Metadata file to provide the data type.
-
Category - The value can be any of the 5Ms: Manpower, Machine, Method, Material, or Management. If a category is not provided, the value defaults to Unspecified.
-
Subcategory - If a subcategory is not provided, the value defaults as Unspecified.
-
Unit of Measure - The specified unit of measure for the attribute.
-
Tags - Key value pair format separated by '::' are supported. For example, Department::Manufacturing::Operation::10.
-
-
You can optionally upload metadata information. Click Browse to select and choose a metadata file in the Metadata File field.
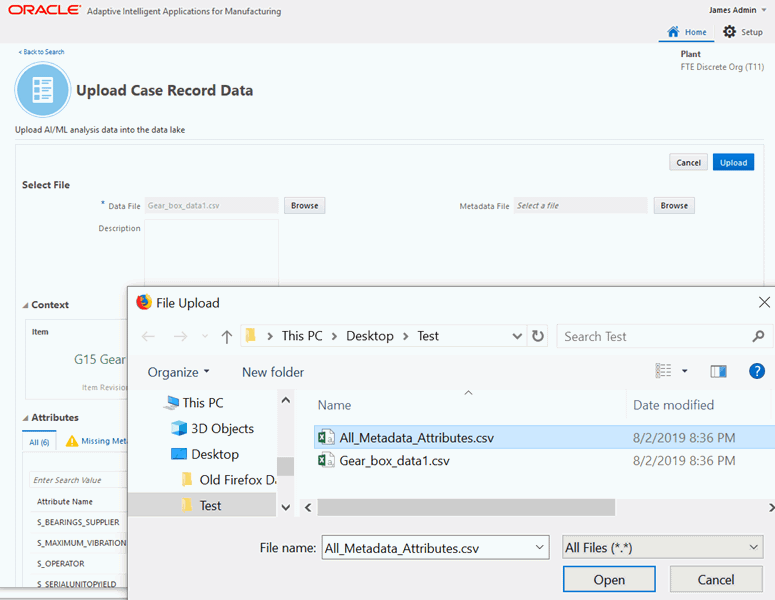
-
Click Upload.
Note: The Upload button is only enabled after the data file is uploaded and the metadata definition for all attributes is correct.
Once you click to upload the files, the Upload Case Record Data Status shows that file is under processing.
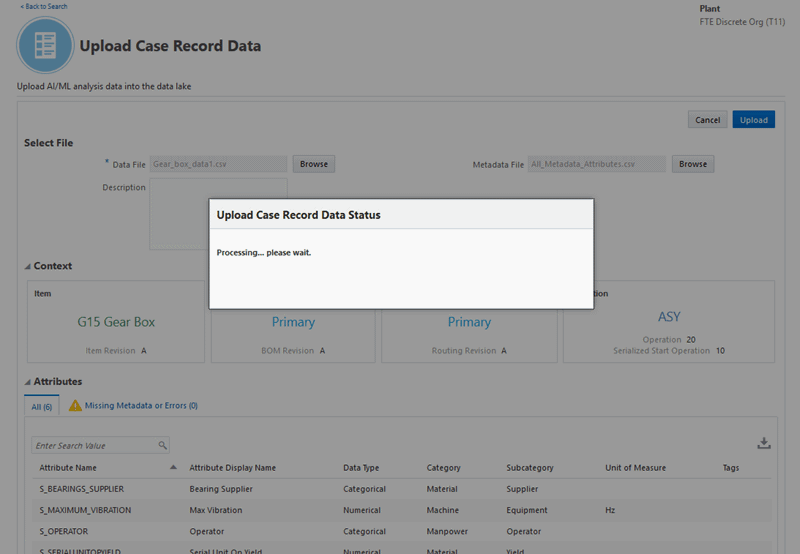
-
Once the case record data files are processed, you will be returned to the Case Record Data page where you can monitor the progress of data import.
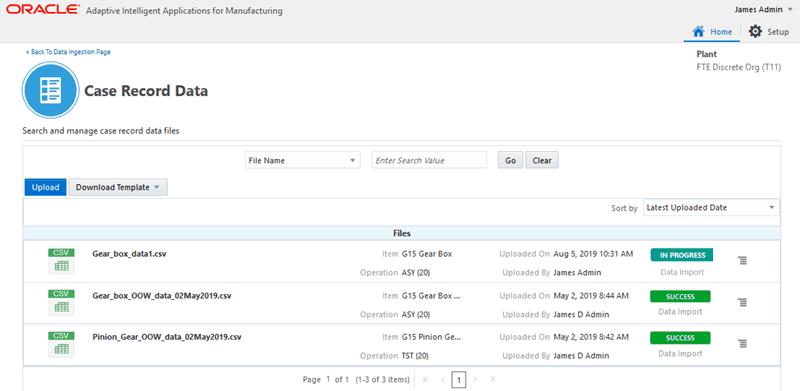
The file appears in the list of uploads in the Case Record Data page, along with the details of file, the status, and actions that can be performed.
The following information displays for the uploaded file:
-
File Name
-
Description
-
Data Context Information:
-
Item
-
Operation
-
-
Uploaded On
-
Uploaded By
-
Status of the Upload:
-
IN PROGRESS: This indicates that the file has been submitted and the background processing is in progress.
-
SUCCESS: This indicates that all case records data in the spreadsheet has been imported successfully.
-
ERROR: This indicates that the import of some or all of the case records data has failed due to errors.
-
-
Action link
To view the status of the background process, you can navigate to the Background Process page. See: Running Background Processes, Oracle Adaptive Intelligent Apps for Manufacturing User's Guide.
-
-
Click the Action link, next to the upload status that displays for an upload. Depending on the enabled actions available for you to perform, you can select from the following actions on the upload:
-
View Data Import Summary
-
Download Error Records
-
Download Data File
-
View File Details
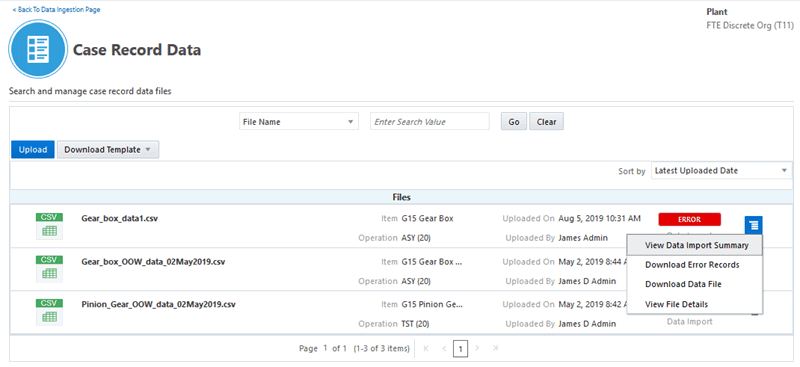
These actions are enabled or disabled, based on the status of the data import, as given in the following table:
Import Status View Data Import Summary Download Error Records Download Data file View File Details IN PROGRESS Disabled Disabled Disabled Enabled SUCCESS Enabled Disabled Enabled Enabled ERROR Enabled Enabled Enabled Enabled -
-
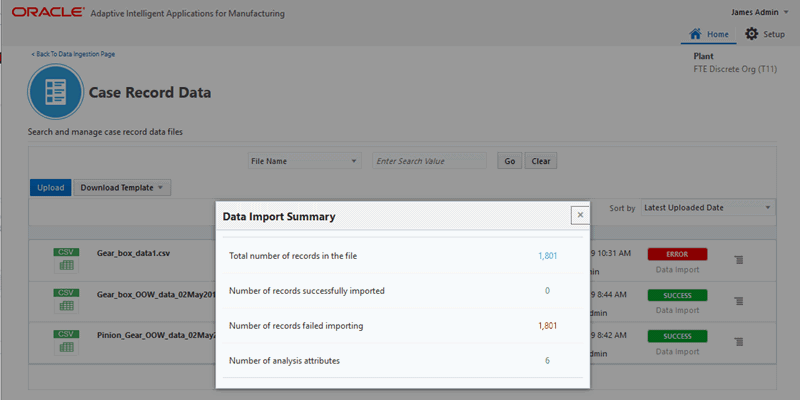
Click the View Data Import Summary action. You can view details like total number of records, successfully imported records, failed imports, and the number of analysis attributes.The Data Import Summary displays the following:
-
Total number of records in the file
-
Number of records successfully imported
-
Number of records failed importing
-
Number of analysis attributes
-
-
Click the Download Error Records action to download the CSV file containing all the errors records with error details to your local machine.
-
Click the Download Data file action to download the data file to your local machine.
-
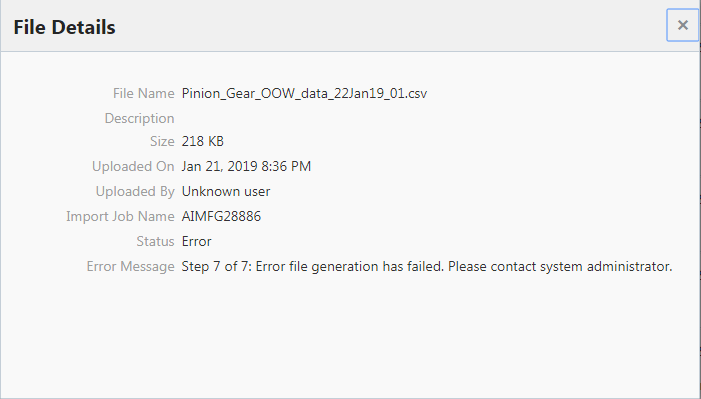
Click the View File Details action, to review the file name, description, size, upload details, import job name, and status for the upload.
Note that the file is processed in the following seven steps, sequentially:
-
Scanning of the file.
-
Creating context for the file.
-
Copying the file to Storage Cloud.
-
Launching the background job.
-
Reading data from the file.
-
Importing data to the target tables.
-
Generating the error file.
If there is an error during any of the seven file processing steps, the error message will specify at which step the file failed processing.
-
-
To prepare data you have uploaded for analysis, see Preparing Data, Oracle Adaptive Intelligent Apps for Manufacturing User's Guide.
Using Case Record Data Templates
AIAMFG provides data and metadata templates for process manufacturing and discrete manufacturing organizations to enter and then upload case record data for analysis.
Case Record Data Template
Use the data template to enter:
-
Context information: Provide context information in the first row. Note that the upload process will only pick the the first row for setting the context information and ignores any additional rows you may enter.
-
Case Record Identifier: Provide case record identifier as work orders for work order level analysis and work order/serial units combination for discrete serial level analysis.
-
Attributes: Provide input features and target attributes which can be selected as targets or features in a dataset.
Note that in the Case Record Data user interface, the data templates you can download are based on the organization type of the context organization. For example, the discrete manufacturing case record data template downloads when logged in as a discrete manufacturing user. Following are the details of the data templates for discrete manufacturing and process manufacturing organizations:
Discrete Manufacturing Data Template
| Field Name | Required | Data Type | Length (Max) | Description | Sample Data |
| ItemCategory | Char | 40 | Item Category, if not provided, defaults to Case Record Data. | Product | |
| ItemNumber | Y | Char | 40 | Item Number | G15 Pinion Gear |
| ItemDescription | Char | 240 | Item Description, if not provided, defaults to item number. | Pinion Gear Assembly | |
| BOMType | Char | 10 | BOM Type, if not provided, defaults to Primary. | Primary | |
| BOMRevision | Char | 3 | BOM Revision, if not provided, defaults to A. | A | |
| RoutingType | Char | 10 | Routing Type, if not provided, defaults to Primary. | Primary | |
| Routing Revision | Char | 3 | Routing Revision, if not provided, defaults to A. | A | |
| OperationSequenceNumber | Number | Operation Sequence Number, if not provided, defaults to 10. | 10 | ||
| SerializedStartOperation | Y (for production unit analysis) | Number | Required for production unit analysis and optional for work order level analysis. | 10 | |
| OperationCode | Y | Char | 3 | Operation Code | OP1 |
| WorkOrderNumber | Y | Char | 240 | Work Order Number | WO-PG-1001 |
| SerialNumber | Y (for production unit analysis) | Char | 30 | Required for production unit analysis and should be left null for work order level analysis | SN00000100 |
| Actual Start Date | Y | Date | 01/01/2015 10:00:00 | ||
| Actual End Date | Y (for completed work orders only) | Date | 01/02/2015 10:00:00 A blank AcutalEndDate field indicates the work order is in progress and will be used for predictions analysis. | ||
| Attribute1, Attribute2, Attribute3... | Character or Number | 240 | MainMtlSupplier MaterialGrade Column Name can be a max of 30 Characters. | John Smith High |
Note: The following maximum numbers of attributes are supported:
-
450 categorical data type attributes
-
450 numeric data types
Note: Ensure that the attribute names do not contain any special characters. Only underscores are allowed.
Process Manufacturing Data Template
| Field Name | Required | Data Type | Length (Max) | Description | Sample Data |
| ItemCategory | Char | 40 | Item Category, if not provided, defaults as Case Record Data | Product | |
| ItemNumber | Y | Char | 40 | Item Number | Strawberry Jam |
| ItemDescription | Char | 240 | Item Description, if not provided, defaults as the item number | Bulk Processed Strawberry Jam | |
| ItemRevision | Char | 3 | Item Revision, if not provided, defaults as A | A | |
| RecipeNumber | Y | Char | 32 | Recipe Number | Strawberry Jam |
| RecipeVersion | Number | Recipe Version, if not provided, defaults to 0 | 1 | ||
| StepNumber | Number | Step Number, if not provided, defaults to 10 | 10 | ||
| OperationCode | Y | Char | 16 | Operation Code | FILLING |
| WorkOrderNumber | Y | Char | 32 | Work Order Number | WO-PG-1001 |
| ActualStartDate | Y | Date | 01/01/2015 10:00:00 | ||
| ActualEndDate | Y ( for completed work orders only) | Date | 01/02/2015 10:00:00 A blank AcutalEndDate field indicates the work order is in progress and will be used for predictions analysis. | ||
| Attribute1, Attribute2, Attribute3... | Char or Number | 240 | MainMtlSupplier MaterialGrade Column Name can be a max of 30 Characters. | John Smith High |
Note: The following maximum numbers of attributes are supported:
-
450 categorical data type attributes
-
450 numeric data types
Note: Ensure that the attribute names do not contain any special characters. Only underscores are allowed.
Case Record Metadata Template
Following are the details of the case record metadata templates:
MetadataTemplate
| Field Name | Required | Data Type | Length (Max) | Description | Sample Data |
| AttributeName | Y | Char | 30 | Attribute Name | EM1_MAX |
| AttributeDisplayName | Char | 250 | Attribute Display Name defaults as the Attribute name if not provided. | EM1_MAX | |
| Data Type | Char | 12 | Data Type values can be a numerical or categorical, and if values are not provided, the data type will default from sample records in the data file.
Note: You cannot change the data type, if the data is already loaded for this attribute. | Numerical or Categorical | |
| Category | Y | Char | 10 | Category should be one of the 5 Ms: Manpower, Material, Management, Machine, Method | Machine
Note: The value can be any of the 5Ms. It defaults to Unspecified if no value is given. |
| Subcategory | Char | 30 | Subcategory will default to Unspecified if not provided | Sensor Summary | |
| UOM | Char | 3 | UOM | ||
| Tags | Char | 500 | Tags support key value pair format separated by :: | Department::Manufacturing::Operation::10 |
Validating Case Record Data
Case Record Data Validations:
The following are the validations for Case Record Data:
-
Storage Cloud requires file names to be unique across a folder. To satisfy this requirement, case record data file names must be unique.
-
Case record data in the template must match with the context organization. Context Organization is the organization that you select to access all AIMFG features and invoke the Data Ingestion user interfaces.
-
Ensure you enter one row for data context information. Only the first row is taken for validation for data context information and all additional rows provided are ignored.
-
For Date format fields, the time zone must be the same as the application server time zone and the data format must be MM/DD/YYYY HH24:MI:SS.
-
When multiple sets of data are imported for the same item or business context, the items are created the first time the import is submitted. Future import runs for the same item will reuse the existing item.
-
When users upload a new case record data set that reuses an existing item, the program:
-
Creates new transactions. If there are existing transaction records, they will be updated.
-
Creates new attributes or updates attribute data for existing transactions.
-
-
A case record data row can upload the following data elements:
-
Work order number.
-
Serial number (for serialized analysis).
-
Actual start date and actual end date.
-
Attributes that can be input features or target attributes.
-
-
Attributes
-
Attributes can be input features or target attributes.
-
The spreadsheet can support a maximum of 450 numerical and 450 categorical data type attributes.
-
Provide meaningful names for the attributes as this information will be provided as a default value in all related user interfaces.
-
Attribute names must be alphanumeric and supports underscore only.
-
-
For installations that use both Golden Gate synchronization and Case Record Data upload, it is required to create a new organization for case record data upload. The same organization cannot be used for both features. A separate organization must be created.
-
As each import runs on MERGE mode, the transactions are always updated if they exist and inserted if they do not exist. Note that you may have an existing dataset, and if you update the data, the existing dataset will not change or reflect the modified data.
-
When the upload program errors out due to setup or context data, the user must fix the data before submitting the case record upload again.
-
When the upload program errors out due to transactional data, the background processor will import transactions that were successfully validated and only error our incorrect transactions. You can download the file with the error transactions, fix the data, and upload the transactions in a new data file again.