13 Configuring Oracle Traffic Director for High Availability
This chapter describes the high-availability capabilities of Oracle Traffic Director. It contains the following sections:
13.1 Overview of High-Availability Features
In the context of Oracle Traffic Director instances, high availability includes the following capabilities:
-
Receive and serve client requests without downtime caused by hardware failures, kernel crashes, and network issues.
-
You can set up a highly available traffic routing and load-balancing service for your enterprise applications and services by configuring two Oracle Traffic Director instances to provide active-active or active-passive failover. For more information, see Section 13.2, "Creating and Managing Failover Groups."
-
If an Oracle Traffic Director process crashes, it restarts automatically.
Oracle Traffic Director provides two levels of availability, application level and node level. Application level availability is the default feature and does not require any additional configuration. Application level availability ensures that the load balancing service is monitored through the Oracle Traffic Director Watchdog daemon and is available even during application level failures such as process crash. This feature ensures that Oracle Traffic Director as a software load balancer can continue to front-end requests to back-end applications even if there is a software issue within the load balancing service. The node level availability ensures that Oracle Traffic Director continues to front-end requests to back-end applications even if the system/vServer crashes because of issues such as CPU failure or memory corruption. For node level availability, Oracle Traffic Director must be installed on two compute notes or vServers, and a failover group must be configured between them.
To provide high availability to the Oracle Traffic Director instance itself, each load balancer server instance includes at least three processes, a watchdog process, a primordial process, and one or more load balancer processes. The watchdog process spawns the primordial, which then spawns the load balancer processes. The watchdog process and the primordial process provide a limited level of high availability within the server processes. If the load balancer process or primordial process terminates abnormally for any reason, then Oracle Traffic Director watchdog is responsible for restarting these services, to ensure that Oracle Traffic Director as a software load balancer service continues to be available. An Oracle Traffic Director instance will have exactly one watchdog process, one primordial process and one or more load balancer processes.
-
Most configuration changes to Oracle Traffic Director instances can be deployed dynamically, without restarting the instances and without affecting requests that are being processed. For configuration changes that do require instances to be restarted, the administration interfaces—CLI and Fusion Middleware Control—display a prompt to restart the instances.
-
-
Distribute client requests reliably to origin servers in the back end.
-
If a server in the back end is no longer available or is fully loaded, Oracle Traffic Director detects this situation automatically through periodic health checks and stops sending client requests to that server. When the failed server becomes available again, Oracle Traffic Director detects this automatically and resumes sending requests to the server. For more information, see Section 5.7, "Configuring Health-Check Settings for Origin-Server Pools."
-
In each origin-server pool, you can designate a few servers as backup servers. Oracle Traffic Director sends requests to the backup servers only when none of the primary servers in the pool is available. For more information, see Section 5.3, "Modifying an Origin-Server Pool."
-
You can reduce the possibility of requests being rejected by origin servers due to a connection overload, by specifying the maximum number of concurrent connections that each origin server can handle.
For each origin server, you can also specify the duration over which the rate of sending requests to the server is increased. This capability helps minimize the possibility of requests getting rejected when a server that was offline is in the process of restarting.
For more information, see Section 6.3, "Modifying an Origin Server."
-
13.2 Creating and Managing Failover Groups
You can ensure high availability of Oracle Traffic Director instances by combining two Oracle Traffic Director instances in a failover group represented by one or two virtual IP (VIP) addresses. Both the hosts in a failover group must run the same operating system version, use identical patches and service packs, and run Oracle Traffic Director instances of the same configuration.
Note:
-
You can create multiple failover groups for the same instance, but with a distinct VIP address for each failover group.
-
On Oracle SuperCluster and Exalogic (Solaris), Oracle Traffic Director can be configured for high availability only when installed on a global zone. In addition, all administration nodes must be running on the global zone.
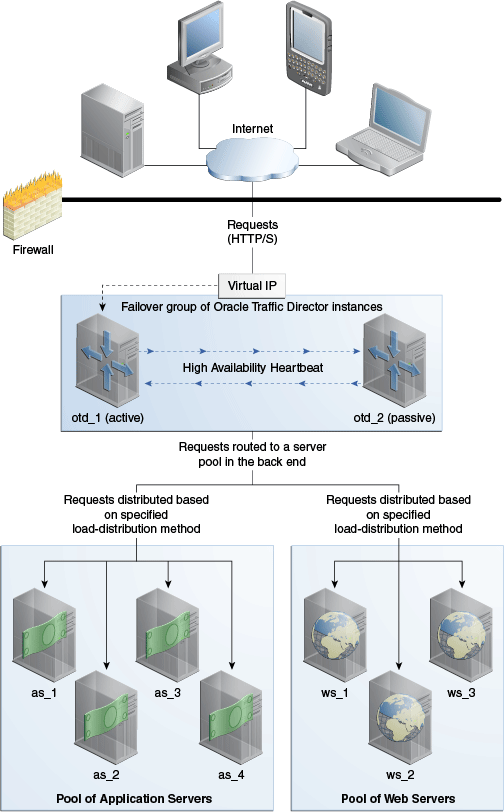
Figure 13-1 shows Oracle Traffic Director deployed for a high-availability use case in an active-passive failover mode.
Figure 13-1 Oracle Traffic Director Network Topology: Active-Passive Failover Mode
Description of ''Figure 13-1 Oracle Traffic Director Network Topology: Active-Passive Failover Mode''
The topology shown in Figure 13-1 consists of two Oracle Traffic Director instances—otd_1 and otd_2—forming an active-passive failover pair and providing a single virtual IP address for client requests. When the active instance (otd_1 in this example) receives a request, it determines the server pool to which the request should be sent and forwards the request to one of the servers in the pool based on the load distribution method defined for that pool.
Note that Figure 13-1 shows only two server pools in the back end, but you can configure Oracle Traffic Director to route requests to servers in multiple server pools.
In the active-passive setup described here, one node in the failover group is redundant at any point in time. To improve resource utilization, you can configure the two Oracle Traffic Director instances in active-active mode with two virtual IP addresses. Each instance caters to requests received on one virtual IP address and backs up the other instance.
This section contains the following topics:
13.2.1 How Failover Works
Oracle Traffic Director provides support for failover between the instances in a failover group by using an implementation of the Virtual Routing Redundancy Protocol (VRRP), such as keepalived for Linux and vrrpd (native) for Solaris.
Keepalived v1.2.12(minimum version required) is included in Oracle Linux; so you need not install or configure it. Keepalived is licensed under the GNU General Public License. Keepalived provides other features such as load balancing and health check for origin servers, but Oracle Traffic Director uses only the VRRP subsystem. For more information about Keepalived, go to http://www.keepalived.org.
VRRP specifies how routers can failover a VIP address from one node to another if the first node becomes unavailable for any reason. The IP failover is implemented by a router process running on each of the nodes. In a two-node failover group, the router process on the node to which the VIP is currently addressed is called the master. The master continuously advertises its presence to the router process on the second node.
Caution:
On a host that has an Oracle Traffic Director instance configured as a member of a failover group, Oracle Traffic Director should be the only consumer of Keepalived. Otherwise, when Oracle Traffic Director starts and stops thekeepalived daemon for effecting failovers during instance downtime, other services using keepalived on the same host can be disrupted.If the node on which the master router process is running fails, the router process on the second node waits for about three seconds before deciding that the master is down, and then assumes the role of the master by assigning the VIP to its node. When the first node is online again, the router process on that node takes over the master role. For more information about VRRP, see RFC 5798 at http://datatracker.ietf.org/doc/rfc5798.
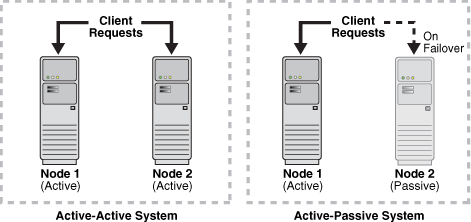
13.2.2 Failover Modes
You can configure the Oracle Traffic Director instances in a failover group to work in the following modes:
-
Active-passive: A single VIP address is used. One instance in the failover group is designated as the primary node. If the primary node fails, the requests are routed through the same VIP to the other instance.
-
Active-active: This mode requires two VIP addresses. Each instance in the failover group is designated as the primary instance for one VIP address and the backup for the other VIP address. Both instances receive requests concurrently.
The following figure illustrates the active-active and active-passive failover modes.
13.2.3 Creating Failover Groups
This section describes how to implement a highly available pair of Oracle Traffic Director instances by creating failover groups. For information about how failover works, see Section 13.2.1, "How Failover Works."
You can create a failover group by using either Fusion Middleware Control or the WLST.
Note:
For information about invoking WLST, see Section 1.7.1, "Accessing WebLogic Scripting Tool."-
Decide the unique VIP address that you want to assign to the failover group.
-
The VIP addresses should belong to the same subnet as that of the nodes in the failover group.
-
The VIP addresses must be accessible to clients.
Note:
To configure an active-active pair of Oracle Traffic Director instances, you would need to create two failover groups with the same instances, but with a distinct VIP address for each failover group, and with the primary and backup node roles reversed. -
-
Identify the network prefix of the interface on which the VIP should be managed. The network prefix is the subnet mask represented in the Classless Inter-Domain Routing (CIDR) format, as described in the following examples.
-
For an IPv4 VIP address in a subnet that contains 256 addresses (8 bits), the CIDR notation of the subnet mask
255.255.255.0would be24, which is derived by deducting the number of addresses in the given subnet (8 bits) from the maximum number of IPv4 addresses possible (32 bits). -
Similarly, for an IPv4 VIP address in a subnet that has 4096 addresses (12 bits), the CIDR notation of the subnet mask
255.255.240.0would be20(=32minus12). -
To calculate the CIDR notation of the subnet mask for an IPv6 subnet, you should deduct the bit-size of the subnet's address space from 128 bits, which is the maximum number of IPv6 addresses possible.
The default network-prefix-length is
24or64for an IPv4 VIP or IPv6 VIP, respectively. The default network-prefix-length is used, if not specified, for automatically choosing the NIC and for validating if the VIP is in the same subnet as the specified NIC.While actually plumbing the VIP it is preferred to use the hostmask, 32 for IPv4 and 128 for IPv6, so that any outgoing traffic originating from that node does not use the VIP as the source address.
-
-
Identify the Oracle Traffic Director administration nodes that you want to configure as primary and backup nodes in the failover group. The nodes should be in the same subnet.
Note that the administration nodes that you select should have Oracle Traffic Director instances present on them for the specified configuration.
-
Identify the network interface for each node.
For each network interface that is currently up on the host, the administration server compares the network part of the interface's IP address with the network part of the specified VIP. The first network interface that results in a match is used as the network interface for the VIP.
For this comparison, depending on whether the VIP specified for the failover group is an IPv4 or IPv6 address, the administration server considers only those network interfaces on the host that are configured with an IPv4 or IPv6 address, respectively.
-
You can bind to a VIP IP address within the HTTP listener by performing a system configuration that allows you to bind to a non-existing address, as a sort of forward binding. Perform one of the following system configurations:
echo 1 > /proc/sys/net/ipv4/ip_nonlocal_bindor,
sysctl net.ipv4.ip_nonlocal_bind=1(change in/etc/sysctl.confto keep after a reboot)Make sure that the IP addresses of the listeners in the configuration for which you want to create a failover group are either an asterisk (
*) or the same address as the VIP. Otherwise, requests sent to the VIP will not be routed to the virtual servers. -
Make sure that the router ID for each failover group is unique. For every subsequent failover group that you create, the default router ID is decremented by one: 254, 253, and so on.
Creating Failover Groups Using Fusion Middleware Control
To create a failover group by using the Fusion Middleware Control, do the following:
-
Log in to Fusion Middleware Control, as described in Section 1.7.2, "Displaying Fusion Middleware Control."
-
Click the WebLogic Domain button at the upper left corner of the page.
-
Select Administration > OTD Configurations.
A list of the available configurations is displayed.
-
Select the configuration for which you want to create a failover group.
-
Click the Traffic Director Configuration In the Common Tasks pane.
-
Select Administration > Failover Groups.
The Failover Groups page is displayed. It shows a list of the Failover Groups defined for the configuration.
-
Click Create.
The New Failover Group wizard is displayed.
-
Follow the on-screen prompts to complete creation of the failover group by using the details—virtual IP address, network interface, host names of administration nodes, and so on—that you decided earlier.
After the failover group is created, the Results screen of the New Failover Group wizard displays a message confirming successful creation of the failover group.
-
Click Close on the Results screen.
The details of the failover group that you just created are displayed on the Failover Groups page.
Note:
At this point, the two nodes form an active-passive pair. To convert them into an active-active pair, create another failover group with the same two nodes, but with a different VIP and with the primary and backup roles reversed.

Creating Failover Groups Using WLST
To create a failover group, run the otd_createFailoverGroup command.
For example, the following command creates a failover group with the following details:
-
Configuration:
ha -
Primary instance:
1.example.com -
Backup instance:
2.example.com -
Virtual IP address:
192.0.2.1
props = {}
props['configuration'] = 'ha'
props['virtual-ip'] = '192.0.2.1'
props['primary-instance'] = '1.example.com'
props['backup-instance'] = '2.example.com'
props['primary-nic'] = 'eth0'
props['backup-nic'] = 'eth0'
otd_createFailoverGroup(props)
Note:
When creating a failover group you must runotd_startFailover on those machines as a root user. This is to manually start the failover. If this command is not executed, failover will not start and there will be no high availability. For more information about otd_startFailover, see WebLogic Scripting Tool Command Reference for Oracle Traffic Director.To enable active-active failover, create another failover group with the same two nodes, but with the primary and backup roles reversed.
For more information about otd_createFailoverGroup, see WebLogic Scripting Tool Command Reference for Oracle Traffic Director.
13.2.4 Managing Failover Groups
To manage the failover groups, the failover daemon needs to run as a privileged user (typically root), otd_startFailover command should be executed as a privileged user on the machines on which the primary and backup instances of the failover group run. Similarly to stop the daemon, you should run the otd_stopFailover. The configuration parameters for the keepalived daemon are stored in a file named keepalived.conf in the config directory of each instance that is part of the failover group. For more information about otd_startFailover or otd_stopFailover, see the WebLogic Scripting Tool Command Reference for Oracle Traffic Director.
After creating failover groups, you can list them, view their settings, change the primary instance for a failover group, switch the primary and backup instances, and delete them. Note that to change the VIP or any property of a failover group, you should delete the failover group and create it afresh.
You can view, modify, and delete failover groups by using either Fusion Middleware Control or the WLST.
Note:
For information about invoking WLST, see Section 1.7.1, "Accessing WebLogic Scripting Tool."Managing Failover Groups Using Fusion Middleware Control
To view, modify, and delete failover groups by using the Fusion Middleware Control, do the following:
-
Log in to Fusion Middleware Control, as described in Section 1.7.2, "Displaying Fusion Middleware Control."
-
Click the WebLogic Domain button at the upper left corner of the page.
-
Select Administration > OTD Configurations.
A list of the available configurations is displayed.
-
Select the configuration for which you want to manage failover groups.
-
Click the Traffic Director Configuration In the Common Tasks pane.
-
Select Administration > Failover Groups.
-
The Failover Groups page is displayed. It shows a list of the Failover Groups defined for the configuration.
-
To view the properties of a failover group, click its virtual IP.
-
To switch the hosts for the primary and backup nodes, click the Toggle Primary button. In the resulting dialog box, click OK.
-
To delete a failover group, click the Delete button. In the resulting dialog box, click OK.
-
Note:
-
If you want to assign a different node as the primary or backup node in a failover group, you should create the failover group afresh.
-
There can be a maximum of 255 failover groups across configurations.
Managing Failover Groups Using WLST
To view, modify, and delete failover groups, see the following examples with the below details.
-
Configuration:
ha -
Primary instance:
1.example.com -
Backup instance:
2.example.com -
Virtual IP address: 10.128.67.44
For example, run the otd_listFailoverGroups command, for list a failover group:
props = {}
props['configuration'] = 'ha'
otd_listFailoverGroups(props)
For example, run the otd_toggleFailovergroupPrimary command, for toggle a failover group:
props = {}
props['configuration'] = 'ha'
props['virtual-ip'] = '10.128.67.44'
otd_toggleFailovergroupPrimary(props)
For example, run the otd_getFailoverGroupProperties command, for change properties of a failover group:
props = {}
props['configuration'] = 'ha'
props['primary-instance'] = '1.example.com'
otd_getFailoverGroupProperties(props)
For example, run the otd_deleteFailoverGroup command, for deleting a failover group:
props = {}
props['configuration'] = 'ha'
props['virtual-ip'] = '10.128.67.44'
otd_deleteFailoverGroup(props)
For more information, see WebLogic Scripting Tool Command Reference for Oracle Traffic Director.