추가 데이터 임포트
중요: 이 항목은 최신 버전의 Connect 사용자를 위한 것입니다. 계정에서 여전히 고전 Connect를 사용하는 경우, 고전 Connect 사용자 안내서를 다운로드합니다.
Connect를 사용하여 Oracle Responsys의 추가 데이터 테이블로 레코드를 임포트할 수 있습니다.
임포트 작업이 실행된 후 업로드 파일이 서버에 보관됩니다. 작업이 성공하면 업로드 파일이 삭제됩니다. 작업이 실패하면 다음과 같은 경우에만 업로드 파일이 삭제됩니다.
- 파일이 비어 있는 경우
- 파일에 부적합한 데이터 형식과 같은 데이터 문제가 있는 경우
- 업로드 파일과 개수 파일에 포함된 레코드 수가 서로 다른 경우
추가 데이터 임포트 작업을 생성하려면 다음을 수행합니다.
- 사이드 탐색 표시줄에서
 데이터를 누르고 Connect를 선택합니다.
데이터를 누르고 Connect를 선택합니다. - Connect 관리 페이지에서 작업 생성을 누릅니다.
- 드롭다운 목록에서 추가 데이터 임포트를 선택하고 임포트 작업의 이름과 설명을 입력합니다.
작업 이름은 100자를 넘을 수 없으며 A-Z a-z 0-9 공백 ! - = @ _ [ ] { } 문자만 포함할 수 있습니다.
- 완료를 누릅니다.
Connect 마법사가 열립니다. 원하는 순서로 단계를 완료할 수 있으며, 변경사항을 저장한 후 나중에 계속할 수 있습니다.
- 다음 단계를 완료합니다.
- 모든 단계를 구성한 후 저장을 누릅니다. 작업을 저장하고 활성화하려면 활성화를 누릅니다.
중요: 작업을 저장하거나 활성화하려면, 먼저 만료 일자를 설정하거나 작업을 만료되지 않음으로 설정해야 합니다. 만료 일자를 설정하려면 만료 일자 옆에 있는 편집  을 누릅니다. 만료된 작업은 삭제되며 복구할 수 없습니다. 만료 일자 관리에 대해 자세히 알아보십시오.
을 누릅니다. 만료된 작업은 삭제되며 복구할 수 없습니다. 만료 일자 관리에 대해 자세히 알아보십시오.
완료한 후에:
- 작업을 저장한 후 Connect 관리 페이지를 사용하여 작업을 관리할 수 있습니다. 작업 관리에 대해 자세히 알아보십시오.
- 작업을 저장할 때 Connect에서 오류가 반환될 수 있습니다. 오류를 검토하고 수정해야 하는 페이지로 바로 이동하려면 오류 표시를 누릅니다. 모든 오류를 해결해야 작업을 활성화할 수 있습니다.
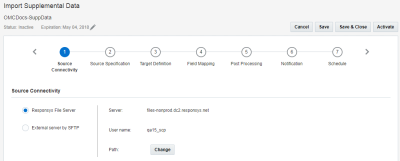
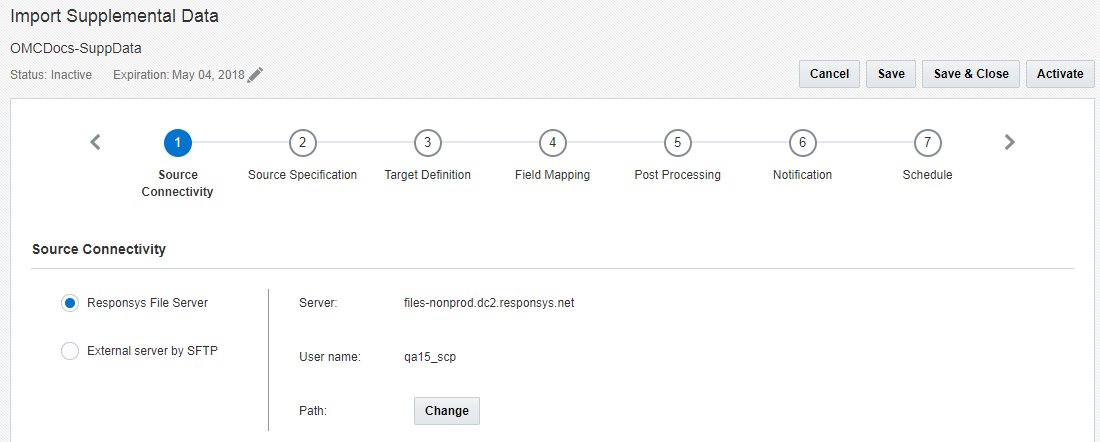
1단계: 출처 연결
이 단계에서는 출처 파일을 검색하기 위한 파일 서버 사양을 제공합니다.
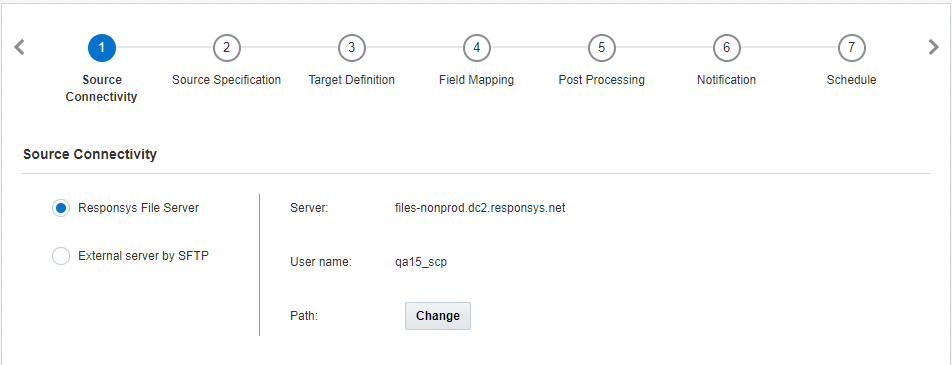
다음 옵션 중에서 하나를 선택합니다.
- Responsys 파일 서버: Connect 작업은 Responsys SCP(Secure Copy Protocol) 계정 파일 서버를 통해 데이터를 임포트할 수 있습니다. 이 계정에는 업로드, 다운로드 및 보관을 위한 세 개의 디렉토리가 포함됩니다.
중요: 아직 설정되지 않은 경우 Oracle Responsys 지원 센터와 소속 IT 팀이 함께 작업하여 SSH-2 공개/개인 키 쌍을 생성해야 합니다. 이렇게 하면 SSH/SCP 클라이언트를 통해 SCP 계정에 안전하게 접근할 수 있습니다. SSH(Secure Shell) 클라이언트를 사용하여 자체 디렉토리를 생성할 수도 있습니다.
- 이 옵션을 선택한 경우 변경을 눌러 파일이 있는 디렉토리를 지정합니다.
- SFTP를 통한 외부 서버: 이 옵션을 선택한 경우 다음 정보를 제공합니다.
- 호스트 이름 – 드롭다운 목록에서 호스트 이름을 선택합니다.
- 디렉토리 경로 – 연관된 디렉토리의 경로 이름을 입력합니다.
- 사용자이름: SFTP 연결에 접근하기 위한 사용자이름을 입력합니다.
- 인증: 서버가 설정된 방식에 따라 비밀번호 또는 키를 선택합니다.
키 인증을 사용하는 첫번째 작업인 경우 키 정보 접근 또는 생성을 누른 다음, SFTP 계정에 키를 추가하기 위한 공개 키와 지침을 받을 전자메일 주소를 입력합니다. 공개 키를 설치한 후 연결 테스트를 눌러 SFTP 연결 구성이 적합한지 확인합니다.
팁: 키 인증에 대한 자세한 내용은 공개 키 선택, 임포트 또는 생성을 참조하십시오.
2단계: 출처 사양
이 단계에서는 임포트할 파일에 대한 정보를 제공합니다.
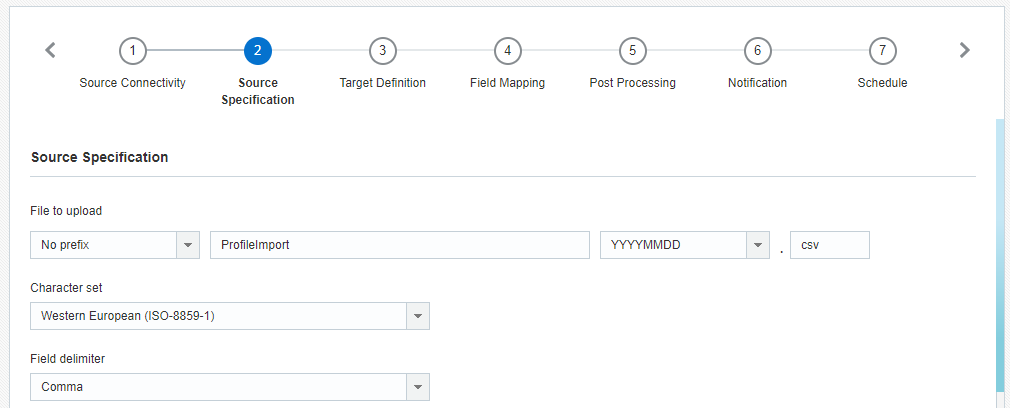
- 업로드할 파일: 임포트할 파일의 전체 이름 및 파일 확장자입니다. 파일 생성 일자를 접두어 또는 접미어로 추가할 수 있습니다.
- 문자 집합: 파일의 문자 집합입니다. 파일에 이모지가 포함되어 있는 경우, 문자 집합으로 유니코드(UTF-8)를 선택해야 합니다.
- 필드 구분 기호: 파일에서 필드(열)를 구분하는 구분 기호입니다.
- 필드 묶기: 텍스트 열 및 값을 작은따옴표 또는 큰따옴표로 묶을지를 지정합니다.
- 일자 형식: 임포트 파일의 일자 형식을 선택합니다. 지원되는 일자 형식에 대한 자세한 내용은 Connect에서 지원되는 일자 형식을 참조하십시오.
- 첫번째 라인에 열 이름 포함: 파일의 첫번째 라인에 필드 이름을 포함하려면 이 확인란을 선택합니다.
- 파일이 PGP/GPG 키로 암호화됩니다. – 파일이 키를 사용하여 암호화되어 있고 업로드하기 전에 파일의 암호를 해독해야 하는 경우 이 확인란을 선택합니다.
- 파일이 PGP/GPG 키로 서명됩니다. – 파일이 키를 사용하여 서명되어 있는 경우 이 확인란을 선택합니다.
- 필요한 레코드 수를 확인할 파일: 선택적으로, 이 확인란을 선택하고 레코드 수를 임포트한 레코드 수와 비교하는 데 사용할 파일을 지정합니다. 예를 들어 이 파일에 필요한 레코드 수가 300개인데 임포트한 파일에 100개 레코드만 있으면 전송 오류가 기록되고 업로드 프로세스가 중단됩니다.
3단계: 목표 정의
이 단계에서는 데이터를 임포트할 추가 데이터 테이블을 선택합니다.
참고: 4단계에서 필드를 매핑하는 동안 목표 테이블도 선택해야 합니다.
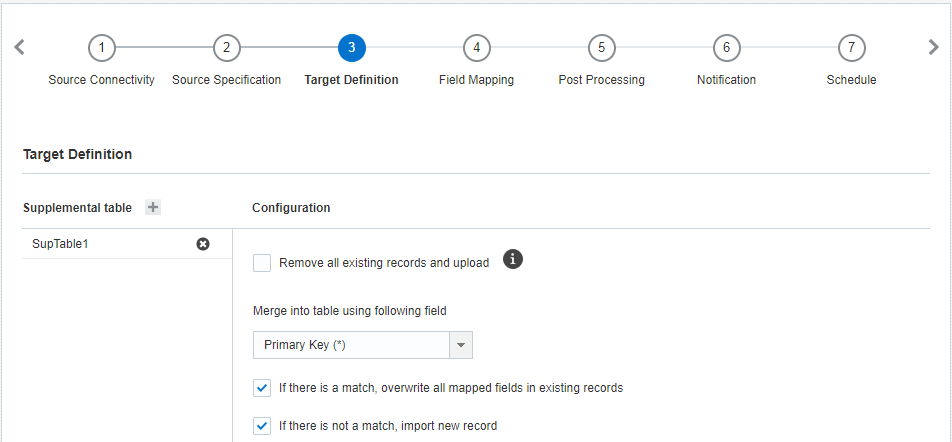
목표 정의를 추가하려면 다음을 수행합니다.
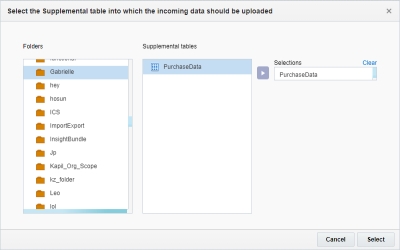
- 목표 정의 단계에서 추가 +를 누르고 데이터를 임포트할 추가 데이터 테이블을 선택합니다.
- 구성 섹션에서 다음 옵션을 지정합니다.
- 기존 레코드 모두 제거 및 업로드: 기존 레코드를 새로 업로드한 레코드로 바꾸려면 이 확인란을 선택합니다.
- 다음 필드를 사용하여 테이블에 병합: 기존 레코드를 모두 제거하지 않는 경우 새 레코드를 기존 레코드에 병합하는 데 사용할 필드를 선택합니다.
- 일치 항목이 있는 경우 기존 레코드에서 매핑된 필드 모두 덮어쓰기: 레코드가 일치할 경우 기존 레코드를 새 데이터로 바꾸려면 이 확인란을 선택합니다. 이 확인란을 선택하지 않으면 수신 레코드가 무시됩니다.
- 일치 항목이 없는 경우 새 레코드 임포트: 일치 항목이 없는 경우 레코드를 임포트하려면 이 확인란을 선택합니다. 이 확인란을 선택하지 않으면 수신 레코드가 무시됩니다.
4단계: 필드 매핑
이 단계에서는 출처 파일의 열을 목표 테이블의 필드에 매핑합니다. 필드 매핑은 각 목표 필드에 해당하는 출처 필드를 지정합니다.
수동으로 필드를 매핑하거나, 업로드 파일을 매핑에 사용하거나, 자동으로 필드 매핑을 생성할 수 있습니다.
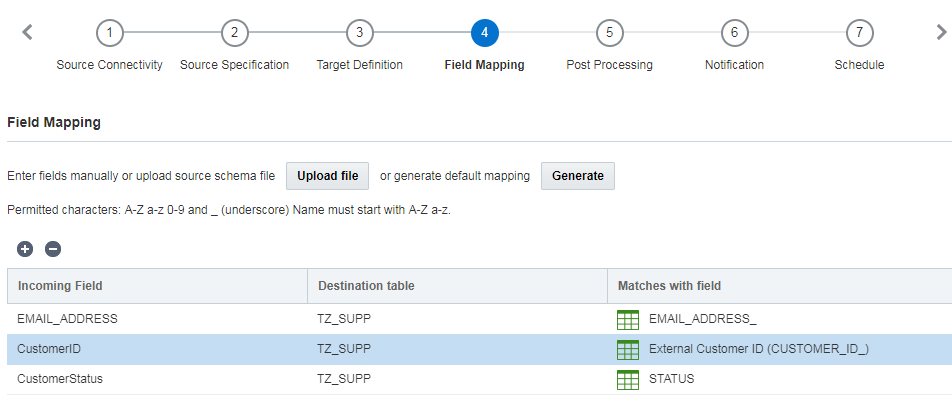
다음 사항에 유의하십시오.
- 긴 필드 이름은 30자로 잘립니다.
- 필드 이름은 문자 또는 숫자로 시작해야 하며 문자, 숫자 및 _(밑줄)만 사용할 수 있습니다.
- 필드가 생성될 때 필드 이름은 대/소문자를 구분하지 않지만 나중에 모두 대문자로 변환됩니다.
- 변경으로 인해 필드 이름이 중복되면 해당 필드 이름을 수동으로 변경해야 합니다.
- Oracle Responsys에서 정의되고 예약된 모든 시스템 필드 이름은 밑줄 문자로 끝납니다(예: EMAIL_ADDRESS_). 모범 사례에 따라 업로드된 필드 이름은 밑줄 문자로 끝나면 안 됩니다. 이러한 이름은 시스템 필드로 예약되어 있습니다.
- 가능하면 비슷한 이름이 지정된 수신 필드를 기존 필드와 일치시킵니다(예: CUST_ID를 CUSTOMER_ID_에 일치시킴).
데이터 유형 및 필드 이름 요구 사항에 대한 자세한 내용은 데이터 유형 및 필드 이름을 참조하십시오.
매핑 파일을 업로드하려면 다음을 수행합니다.
- 필드 매핑 단계에서 파일 업로드를 누릅니다.
- 매핑 파일을 선택하고 세부사항을 완료합니다.
- 필드 구분 기호: 파일에서 열을 구분하는 구분 기호(일반적으로 탭 또는 쉼표)를 선택합니다.
- 필드 묶기 기호: 텍스트 열 및 값을 작은따옴표 또는 큰따옴표로 묶을지를 지정합니다.
- 첫번째 라인에 열 이름 포함: 첫번째 라인에 필드 이름을 포함하려면 확인란을 선택합니다.
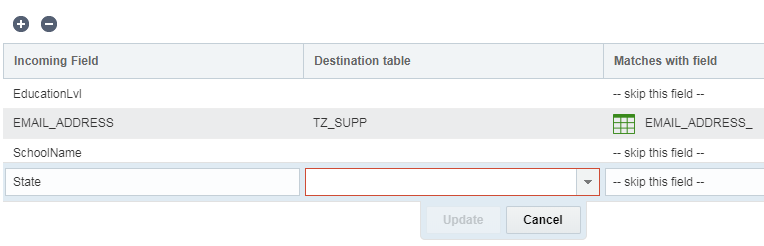
필드를 매핑하려면 다음을 수행합니다.
- 필드 매핑 단계에서 추가 +를 누릅니다.
- 해당 필드의 목표 테이블도 선택합니다.
- 수신 필드 및 일치하는 필드를 지정합니다. 필드를 일치하지 않으려면 이 필드 건너뛰기를 선택합니다.
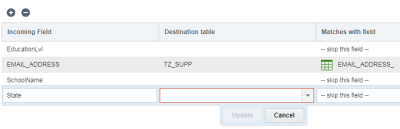
- 업데이트를 누릅니다.
5단계: 사후 처리
이 단계에서는 작업 실행을 성공한 후에 캠페인을 실행할 수 있습니다. 캠페인을 40개까지 선택할 수 있습니다.
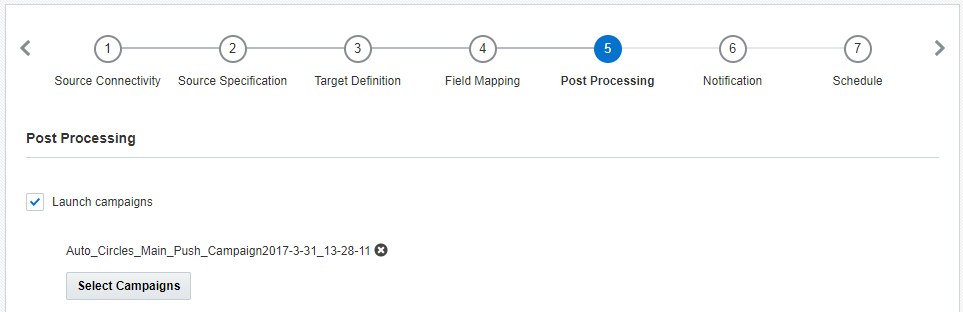
캠페인 실행 진행률 통지를 받으려면 각 캠페인 설정에서 진행률 통지를 수신할 전자메일 주소를 하나 이상 지정해야 합니다.
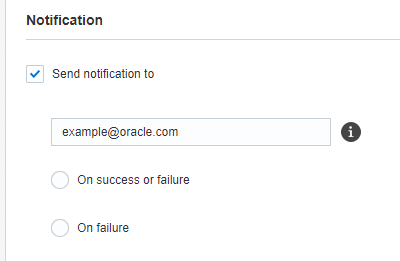
6단계: 통지
이 단계에서는 작업에 대한 전자메일 통지를 설정합니다. 작업을 성공 또는 실패한 후에 통지를 전송하도록 선택할 수 있습니다.
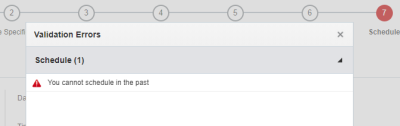
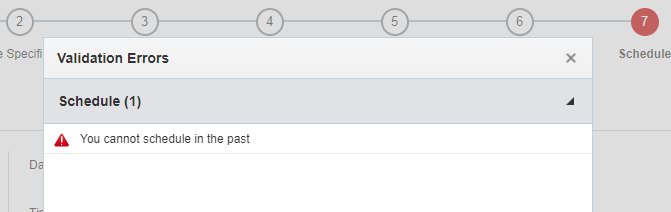
7단계: 스케줄
이 단계에서는 작업을 스케줄링합니다. 지정된 일자 및 시간에 작업을 한 번 실행하거나, 반복 스케줄에 따라 실행할 수 있습니다. 요청 시 작업을 실행하려면 스케줄링 안함 옵션을 사용합니다.
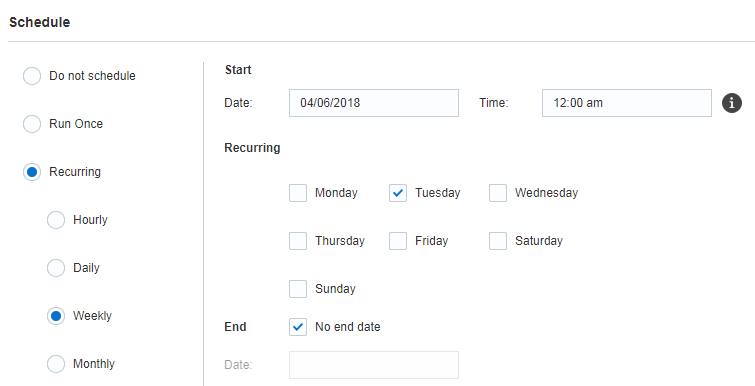
중요: 31일이 있는 윤년과 윤달로 문제가 발생하지 않도록 월의 29일, 30일 또는 31일에는 매달 반복하는 실행을 스케줄링할 수 없습니다. 월의 마지막 요일(예: 월의 마지막 금요일)에 실행되도록 작업을 스케줄링할 수 있습니다.
작업의 시작 시간을 설정할 때는 1시간 내의 시간대(0-14분, 15-29분, 30-44분, 45-59분) 중 하나를 선택합니다. 시스템은 스케줄링된 각 작업에 대해 임의 시간(분)을 선택합니다(예: 0-14분 구간 중 12분). 이를 통해 작업 시작 시간을 더 균등하게 분배합니다.
작업은 선택한 시간대 내의 임의 시간에 시작됩니다. 현재 시간과 겹치는 시간대에 새 작업을 설정하려고 하면, 선택한 시간이 과거 일자라는 내용의 오류 메시지가 발생할 수 있습니다. 따라서 모범 사례에 따라 현재 시간대 이후의 시간대를 선택합니다.