3 Developing a Cassandra Message Store Architecture
This chapter provides information about how to design your Oracle Communications Messaging Server Cassandra message store architecture, and information about how Messaging Server components are distributed across hardware and software resources. For more information about general concepts, see the "Developing a Messaging Server Architecture" chapter in Messaging Server Installation and Configuration Guide.
Understanding the Cassandra Message Store Architecture
In general, you never deploy the Cassandra message store on a single node. Instead, you deploy the Cassandra message store on multiple nodes in a data center. In Cassandra, the term data center is a grouping of nodes, configured together for replication purposes. (A cluster contains one or more data centers, which can span physical locations.)
A Cassandra node can be installed on a Docker container, a virtual machine (VM), or a physical host. Using containers provides more flexibility with your deployment than using physical hosts. For example, if a physical host contains extra bandwidth, you can increase throughput by installing more Cassandra instances within containers.
In a Messaging Server deployment, containers are recommended for installing Cassandra. However, if a physical host can support only a single Cassandra instance, do not use a container.
Each node can read and write messages that are sent to the data center. One node is chosen to be coordinator for each read or write operation, and forwards the read or write operation to appropriate replicas for the operation's partition key. Cassandra uses token aware routing, so the coordinator for an operation usually holds one copy of the relevant data.
Cassandra uses replicas on multiple nodes to ensure data reliability and fault tolerance. A replication factor (on a per-keyspace basis) determines the number of replicas. A replication factor of 1 means that there is only one copy of each row on one node. A replication factor of 2 means two copies of each row, where each copy is on a different node. When you install the Cassandra message store, Messaging Server automatically sets the replication factor on the Cassandra keyspaces. You can control the replication factor through Messaging Server configuration options. For more information, see the replication factor options in Table 4-3, "Data Center and Replication Configuration Options".
Internode communications between nodes occurs through a peer-to-peer protocol called gossip. Through gossip, nodes periodically exchange state information about themselves and about other nodes they know about. To facilitate gossip communications and bootstrap nodes in a data center, you designate some nodes as seed nodes. The seed node acts as a point of contact for other nodes to find each other and learn the topology of the data center. In addition, it is recommended to configure snitches, which determine which data centers and racks the nodes belong to. It is recommended to configure the DataStax option GossipingPropertyFileSnitch as endpoint_snitch. Snitches inform Cassandra about the network topology so that requests are routed efficiently and enable Cassandra to distribute replicas by grouping machines into data centers and racks. You also use Message Server data center and replication factor options, to configure racks and data centers. For more information, see Table 4-3, "Data Center and Replication Configuration Options".
For more information about Cassandra architecture, see DataStax Enterprise Reference Architecture at:
http://www.datastax.com/wp-content/uploads/2014/01/WP-DataStax-Enterprise-Reference-Architecture.pdf
Overview of Cassandra Message Store Logical Architecture
In general terms, the message store holds and stores user mail. Sometimes it is referred to as a ”back end.” The message store also refers to the Message Access Components including the IMAP server and the POP server. Starting with Messaging Server 8.0.2, the Message Access Components have been separated out from the message store into their own logical layer, referred to as the message access layer.
The original Messaging Server message store is based on storing mailbox caches, mailbox indexes and messages in the file system, and use of Oracle Berkeley Database (BDB) for other metadata. The Cassandra message store, based on Cassandra database, changes the approach to how you architect the store components of your Messaging Server deployment. At a high-level, Figure 3-1 shows the Cassandra message store logical architecture.
Figure 3-1 Cassandra Message Store Logical Architecture
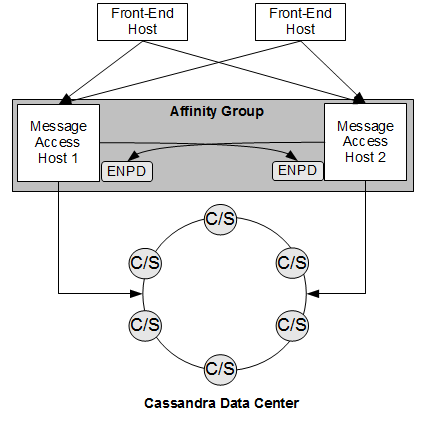
Description of ''Figure 3-1 Cassandra Message Store Logical Architecture''
The preceding figure shows the following components of the Cassandra message store logical architecture:
-
Front-end hosts: The front-end hosts, which can be Message Transfer Agent (MTA), Messaging Multiplexor (MMP), LMTP client, or Webmail (mshttpd) hosts, communicate with the message access hosts.
-
Message access hosts: The message access hosts run the imapd process and LMTP server. The message access hosts also run the Event Notification Service (ENS) enpd process for horizontal scalability in the form of a store affinity group. Store affinity groups enable routing to an alternate LMTP server in the list if the first one listed is unavailable. Store notifications relevant to the store affinity group are published to all ENPD servers in the store affinity group. Other connections to a store affinity group (POP, IMAP, LMTP server) can be handled by any host in the store affinity group.
Note:
Only two message access hosts are required in a store affinity group. This differs from classic store automatic failover, which requires three hosts in a store affinity group.The message access hosts also run the Indexed Search Converter (ISC) process, which pre-converts messages before delivery to the message store.
-
Cassandra data center: The data center is a collection of Cassandra and Solr hosts, which store and index the email data. The Solr core consists of the ms_index index/schema and Field Input Transformer (FIT), a plugin that generates dynamic Solr fields to index the message header and body contents.
Deploying the Cassandra Message Store on Data Centers
Figure 3-2 shows the logical architecture of a Cassandra message store on a single data center.
Figure 3-2 Message Store Deployed Upon a Single Cassandra Data Center
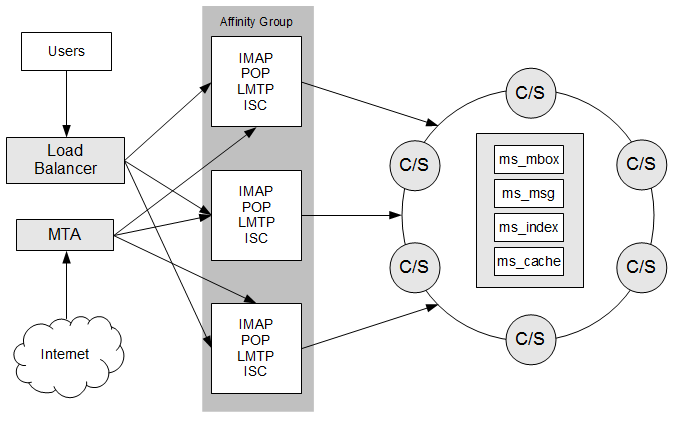
Description of ''Figure 3-2 Message Store Deployed Upon a Single Cassandra Data Center''
This figure shows a Messaging Server Cassandra message store deployment that consists of a load balancer; a Message Transfer Agent (MTA) host for incoming traffic; multiple Messaging Server message access hosts in a single affinity group; and a single Cassandra data center. Each Cassandra/Solr node (indicated by a "C/S" in the figure) in the data center contains the four keyspaces that make up the message store and indexing and search component: ms_mbox, ms_msg, ms_index, and ms_cache.
Note:
See Figure 3-1, "Cassandra Message Store Logical Architecture" for more details on the logical architecture of the message access tier and ENS, which is not depicted in this figure.When you perform the initial configuration of Messaging Server, or when the service startup of the stored process happens when in Cassandra message store mode, by default, it creates all four keyspaces on a Cassandra/Solr node on one data center called DC1.
In general, use a single data center for a proof of concept deployment, and not for production purposes. While you can use a single store affinity group deployment, the scale limits of a single-affinity deployment are unknown. In the event ENS notifications become a scale bottleneck, the recommendation is to add a new store affinity group. When there is more than one store affinity group, you must have an MMP between the load balancer and the IMAP/LMTP/ISC tier.
Figure 3-3 shows the logical architecture of a Cassandra message store on multiple data centers and clusters.
Figure 3-3 Message Store Deployed Upon Multiple Cassandra Clusters
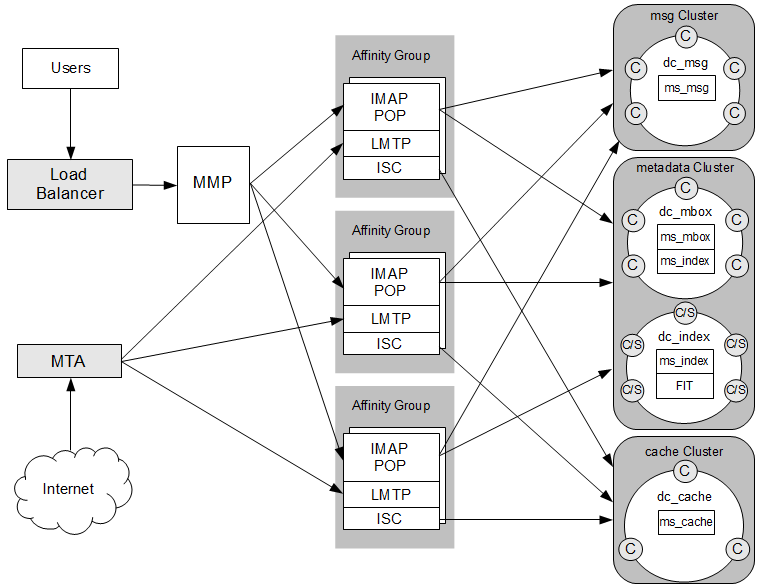
Description of ''Figure 3-3 Message Store Deployed Upon Multiple Cassandra Clusters''
This figure shows a Messaging Server Cassandra message store deployment that consists of a load balancer; a Message Transfer Agent (MTA) host for incoming traffic; a Messaging Multiplexor (MMP) host to act as the connection point to the multiple back-end message stores; multiple Messaging Server front-end hosts, configured as three store affinity groups (and running ENS), for message access and delivery handling; and three Cassandra clusters. The clusters contain at least one Cassandra data center, indicated by "dc_name." Each Cassandra node is indicated by "C" in the figure, and each Cassandra/Solr node is indicated by "C/S." The dc_msg data center contains the ms_msg keyspace. The dc_mbox data center contains the ms_mbox and ms_index keyspaces. The dc_index data center contains the ms_index keyspace and Solr components. The dc_cache data center contains the ms_cache keyspace. Because the cache data can be regenerated, only a single ms_cache keyspace is needed; disaster recovery is unnecessary. Also, the ms_cache keyspace is only needed by the Indexed Search Converter (ISC). The Cassandra replication factor ensures there are N copies of data distributed across the nodes in the data center.
Note:
See Figure 3-1, "Cassandra Message Store Logical Architecture" for more details on the logical architecture of the message access tier and ENS, which is not depicted in this figure.Planning for a Highly Available Cassandra Message Store Deployment
Unlike previous versions of Messaging Server, where you need to install and manage clustering software to obtain a highly available message store, the Cassandra message store is itself designed to provide continuous uptime. Cassandra relies the concept of installing multiple nodes with no single point of failure. Because of its peer-to-peer distributed system, where data is handled by all nodes in a cluster, Cassandra is able to address the problem of failures. Thus, the need to use additional clustering software is rendered unnecessary (nor is it supported).
At a high-level, Cassandra operates in the following way to ensure data consistency across all nodes in a cluster:
-
Uses a peer-to-peer protocol called gossip for nodes to exchange state information.
-
Ensures data durability through use of a a sequentially written commit log on each node.
-
Indexes and writes data to an in-memory structure, called a memtable, which is similar to a write-back cache.
-
When the in-memory structure becomes full, Cassandra writes the data to disk. Cassandra automatically partitions and replicates the writes throughout the cluster.
For more information on Cassandra architecture, see the DataStax documentation at:
http://docs.datastax.com/en/cassandra/3.0/cassandra/architecture/archTOC.html
High availability is achieved on the Messaging Server front-end tier (Message Transfer Agent (MTA), Messaging Multiplexor (MMP), and mshttpd daemon) through the use of load balancers, or MX records (MTA-submit). High availability is achieved on the message access tier (IMAP, POP, LMTP server, ENPD, and ISC) with store affinity groups. High availability on the back-end tier (Cassandra/DSE, FIT and ISC) is achieved through Cassandra/DSE itself.
You must configure store affinity groups consistently on all front-end tier and message access tier hosts. Store affinity groups enable the MMP to switch to an alternate IMAP server that can perform read/write IMAP operations for the user if one of the message access tier hosts goes down. Classic message store only supports failover (with read-only on backup IMAP servers), while Cassandra store supports read/write for all IMAP servers in the affinity group.
Store notifications are broadcast to all enpd servers in the store affinity group (which then relays them to all subscribed IMAP servers in the affinity group). Without store affinity groups, all store notifications would have to be broadcast to all enpd servers in the deployment, which would eventually pose a scalability problem.
For more information on configuring store affinity groups, see "Installing and Configuring the Messaging Server Software".