11 OSM Pre-Production Testing and Tuning
This chapter describes how to run performance tests and tune Oracle Communications Order and Service Management (OSM) before going into production.
OSM Performance Testing and Tuning Overview
Performance testing and tuning is an iterative process with cycles of testing, tuning, analyzing, and retesting. Although many factors impact OSM performance, you can classify them into the following categories:
-
Hardware: OSM performance is bounded by the limitations of the hardware on which it runs such as when maximum CPU, memory, or other resources are reached. For example, through the performance testing process, you may discover that you need more hardware for another database instance or for additional WebLogic Server managed servers.
-
Software: Achieving optimal OSM performance depends on proper configuration and tuning of these OSM components and technologies included in the OSM architecture:
-
The operating systems
-
The Oracle GRID infrastructure and associated disk groups and disks
-
The Oracle Real Application Cluster (Oracle RAC) database
-
The Oracle WebLogic Server cluster
-
Java
-
The Java message service
-
Oracle Coherence
-
Shared storage
-
Oracle Communications Design Studio
-
-
Solution: OSM cartridges provide the metadata instructions that the OSM server needs to fulfill orders according to business requirements. The level of complexity defined in OSM cartridges impacts order processing performance. For example, the number of tasks in a process or the number of order line items in an incoming order, and the complexity of the incoming order can affect order throughput. To improve solution-related performance, you may need to redesign the solution in Design Studio and redeploy it.
The main goal of performance testing is to determine how many automation threads and how large an order cache are required in a managed server to handle a peak order rate that is sustainable. Although CPU can sometimes cause performance issues, memory is typically the first resource to reach its maximum capacity. You can determine this peak sustainable order rate by monitoring the memory usage of the WebLogic Server during a performance test.
The process for determining this sustainable peak order rate includes the following steps:
-
Install and configure the performance test environment. This includes the hardware, software, and the OSM solution components.
-
Prepare the WebLogic Server connection pool, maximum constraints for work managers, and the JBoss and Coherence cache size and timeout values by setting these values to very high settings. Setting these values high enables you to find the point at which the memory of the managed server begins to be overloaded.
-
Find the sustainable peak order rate by monitoring the WebLogic Server's Java heap using JConsole. The sustainable peak order rate is determined by ensuring that the live data size (LDS) remains stable at 50% of the old generation tenured heap.
-
When you have determined the sustainable peak order rate, you can review the WebLogic Server log files to determine the number of automation threads that had been in use, the number of orders in the JBoss and Coherence cache, and the average duration these orders required before completing.
-
Configure the WebLogic Server connection pool, maximum constraints for work managers, and the JBoss and Coherence cache size and timeouts values by setting these values to the those you determined during performance testing. Performing this step ensures that WebLogic Server managed servers in your WebLogic Server cluster do not run out of memory.
-
Use the sustainable peak order rate to determine how many managed servers you require in your WebLogic Server cluster.
Guidelines for the Performance Test Environments
You determined the initial sizing of your production environment hardware when you planned the physical architecture of your system, as described in "Planning the Physical Architecture". In this chapter, you will run performance tests to determine if your initial sizing is adequate.
Ideally, the hardware sizing for the performance test environment should be comparable to that of the production environment. For example, if the test environment is less than half of the capacity of the production environment, then you cannot adequately test the performance capability of the solution. In addition, the technology stack and the solution architecture should resemble the production environment as closely as possible. For example, the Oracle Grid infrastructure, the Oracle RAC setup, the WebLogic Server setup, and the shared storage used should be similar to that used in the production environment.
When the performance test environment is smaller than the production environment, a conservative approach must be taken to extrapolate the results, considering that the results in production may be substantially different than what is being observed in the test environment. For example, you can test a smaller number of managed servers in the test cluster environment as long as the managed servers have the same resources as an equivalent production managed server (for example, memory, CPU). If you plan to deploy multiple managed servers per machine in production, a you should use a similar deployment for testing (for example, smaller number of machines but comparable deployment and resource usage for each machine).
You should not assume a simple, linear extrapolation based on hardware. Often, usage and data contention bottlenecks do not manifest themselves until the system is large enough. Conversely, an undersized system may magnify issues that otherwise would not exist: for instance, when using an Oracle RAC database with a slow interconnect or slow storage retrieval. For example, you must know the number of managed servers you have in your cluster to properly size the coherence invocation service threads. If your coherence threads are not properly sized for your environment, you may experience costly issues in a fully sized production environment. For more information about configuring coherence threads, see "Configuring and Monitoring Coherence Threads".
The performance test environment may also serve as a preproduction environment for tasks such as validating upgrade plans or new cartridges. Oracle recommends that you keep the performance test environment available both prior to the initial deployment and throughout the lifespan of the OSM solution, so that performance testing can be conducted on any new enhancements, fixes, and workarounds, and any other changes introduced to the implementation.
When you are planning the performance test environment, create a test plan that includes the following high-level information:
-
Versions of the following software: OSM, WebLogic Server, Coherence, JDK, Oracle Database, Design Studio, and the OSM Design Studio plug-ins
-
The patches applied
-
Operating system, version, and configuration
-
Solution and deployment architecture
-
Latest cartridges
-
WebLogic Server configuration files (all files in the domain_home/config directory), JVM heap size, the osm-coherence-cache-config.xml file, and the OSM oms-config.xml file
-
Cluster size
-
OSM database configuration: memory size, tablespaces and redo log sizes, layout, and so on. Also, for example, whether you plan to use Oracle RAC and partitioning and, if so, the number of orders per partition.
About Configuring the Environment for Performance Testing
The performance testing process involves determining the sustainable order rate that each managed server in the OSM WebLogic cluster can handle. The sustainable order rate is typically 80% of the maximum order rate that each managed server can handle beyond which the managed server becomes overloaded. This creates a buffer that ensures that large spikes in customer orders do not create problems.
This chapter provides instructions for configuring and tuning work managers, work manager constraints, and JBoss and Coherence caches such that in the initial environment setup, the constraints and caches are set very high. Having these settings high enables you to overload the managed server's cpu and memory so that you can determine the sustainable order rate for each managed server. After determining the sustainable order rate, you can then configure the work manager constraints and caches to ensure that the managed server in the cluster can never process more orders than it can handle.
About Work Managers, Work Manager Constraints, and the JDBC Connection Pool
OSM uses work managers to prioritize and control work. You can tune work managers using work manager constraints, which is an effective way to prevent overloading the managed servers in the OSM WebLogic Server cluster. The work manager constraints limit the number of threads available to OSM work managers.
The OSM installer creates only one maximum thread constraint shared by all OSM work managers. While this performs well in a development environment, this configuration is not the best approach in a production environment. For example, in a production environment under high load, this configuration can cause all available threads to alternate between the automation work manager (osmAutomationWorkManager) and the JMS web service work manager (osmWsJmsWorkManager), impacting core order processing capabilities.
To better control the flow of orders, Oracle recommends that you set the following values for thread constraints:
-
osmJmsApiMaxThreadConstraint for the osmWsJmsWorkManager work manager. The osmJmsApiMaxThreadConstraint should be 12.5% of the total number of threads when you initially begin the tuning process.
-
osmHttpApiMaxThreadConstraint for the osmWsHttpWorkManager and osmXmlWorkManager work manager. The osmHttpApiMaxThreadConstraint should be 12.5% of the total number of threads when you initially begin the tuning process.
-
osmGuiMaxThreadConstraint for the osmTaskClientWorkManager, osmOmClientWorkManager work managers. The osmGuiMaxThreadConstraint should be 25% of the total number of threads when you initially begin the tuning process.
-
osmAutomationMaxThreadConstraint for the osmAutomationWorkManager work manager. The osmAutomationMaxThreadConstraint should be 50% of the total number of threads when you initially begin the tuning process.
After you have completed the tuning process, you will set these constraints to values that enable maximum performance while ensuring that the server does not get overloaded or encounter alternating thread issues.
You must also ensure that every OSM thread always has access to a database connection. Oracle recommends that you set the maximum number of work manager threads to 80% of the database connection pool. One approach to this configuration is to first determine the total number of threads needed by adding all the maximum work manager constraints together, and then set the database connection pool to 125% of this number.
About the JBoss and Coherence Order Cache
OSM uses JBoss and Coherence order caches that determine how many orders can stay in active memory and for how long before being removed from the cache. Tuning the JBoss and Coherence order caches also prevents the managed servers in the OSM WebLogic Server cluster from being overloaded.
Synchronizing Time Across Servers
It is important that you synchronize the date and time across all machines that are involved in testing, including client test drivers. In production environments, Oracle recommends that you do this using Network Time Protocol (NTP) rather than manual synchronization. Synchronization is important in capturing accurate run-time statistics.
Determining Database Size
The size of the database (amount of memory, number of CPUs, and storage capacity) has an impact on performance. Oracle recommends that you run tests using the same size database that is planned for the production environment. You can do this by seeding the database with data, migrating data, or running a representative set of sample orders. Initial testing against an empty database only highlight the most serious problems. With an empty schema, database performance problems that relate to gathering optimizer statistics that are inaccurate will not become apparent until after the OSM system enters production.
This chapter provides instructions for populating the database with orders, warming up the system, and running database optimizer statistics so that the performance test generates accurate results.
Note:
Oracle recommends that you back up the OSM schema before running performance testing. After testing, you can restore the schema so that you do not need to purge orders that were generated during the testing. Keep in mind that exporting and importing the OSM schema can be time-consuming.Alternatively, you can drop the all partitions and rebuild the seed data. This method can be faster than backing up and restoring the schema.
Setting Up Emulators
If the entire system is not available for testing, you can set up emulators to simulate external requests and responses. For example, if you need to test OSM performance before the billing or inventory system is ready, you can use emulators.
If you are using the Order-to-Activate cartridges, OSM provides an Oracle Application Integration Architecture (Oracle AIA) Emulator, which you can use to emulate order responses. If possible, run emulators on separate hardware from the OSM server so they do not consume OSM resources during performance testing. For more information about setting up and using Oracle AIA emulators, see OSM Cartridge Guide for Oracle Application Integration Architecture.
Setting Up a Test Client for Load Generation
You can use a test client to submit the orders for performance testing. The test client can be a custom application or any third-party tool, such as JMeter, LoadUI, or SoapUI. The examples used in this chapter are from a SoapUI project.
Keep the following in mind when setting up a test client:
-
Ensure the test client does not impact OSM hardware resources. It is best to run test clients on different hardware from the hardware where OSM is deployed.
-
Ensure the number of test client threads is configurable and supported in the test client machine. This is essential for load and scalability testing because the number of concurrent users that the system can support is based on the number of test client threads. If high loading is required, you might need to use multiple test client machines to generate a sufficiently high load.
-
Ensure the test client can provide vital statistics on performance data, such as average, maximum, standard deviation, and 90th percentile performance numbers.
-
Ensure the test client can complete long running tests with a steady load.
Example Managed Server Configuration
This section describes an example managed server configuration to illustrate how to run a performance test on an OSM instance as described in "Example Performance Tests on OSM Managed Servers".
The example is based on the following:
-
Each machine has 64 threads and processors.
-
Each machine has 128 GB of physical memory.
-
Each machine runs two managed servers.
-
Each managed server is configured with 32 GB of memory.
To configure the managed servers, do the following:
-
For each managed server, set 24 hardware threads for garbage collection by using the -XX:ParallelGCThreads managed server startup argument.
See "Configuring Managed Server Startup Parameters" for more information about setting startup parameters.
Note:
Even though you could allocate half of the 64 hardware threads for garbage collection, this would create too many tenured heap partitions which increases the risk of fragmentation. -
For each managed server, configure the database connection pool with four times the number of available hardware threads. This very large connection pool removes any limitations on the number of threads that managed server can use during the performance test. This enables the performance test to determine the actual overload point for the managed servers.
In the sample environment, given that there are two managed servers on one machine that has 64 threads, the connection pool for each managed server could start at 4 x 64 threads / 2 managed servers = 128 connections for each managed server.
Note:
Ideally, each managed server would have its own dedicated machine. In which case, there would be 4 x 64 threads / 1 managed server = 256 connections for the managed server.To set the maximum capacity of the connection pool, do the following:
-
Log in to the WebLogic Server Administration Console.
-
In Domain Structure, expand Services, and then select Data Sources.
The Summary of JDBC Data Sources screen is displayed.
-
For each entry in the table with a name in the format:
osm_pool_sid_group_y
where sid is the system identifier (SID) of the Oracle RAC database instance and y is the group letter for the managed server, do the following:
Select the data source. The Settings for pool_name window is displayed.
Under the Configuration tab, select the Connection Pools subtab.
In the Maximum Capacity field, verify that the value is set to 128. If it is not, click Lock & Edit, change the value, and click Save.
-
Click Activate Changes if you changed any values.
-
-
Verify the maximum thread constraints and that the thread constraints are to a large value for initial performance testing. These maximum constraints are calculated based on 80% of the database connection pool, which is 128 x 0.80 = 102:
-
osmJmsApiMaxThreadConstraint for the osmWsJmsWorkManager work manager. In this example, the constraint should be 102 x 0.125 = 12.75
-
osmHttpApiMaxThreadConstraint for the osmWsHttpWorkManager and osmXmlWorkManager work managers. In this example, the constraint should be 102 x 0.125 = 12.75
-
osmGuiMaxThreadConstraint for the osmTaskClientWorkManager and osmOmClientWorkManager work managers. In this example, the constraint should be 102 x 0.25 = 25.
-
osmAutomationMaxThreadConstraint for the osmAutomationWorkManager work manager. In this example, the constraint should be 102 x 0.5 = 51.
To validate these constraints, do the following:
-
In the Administration Console, in Domain Structure, expand Environment, and then select Work Managers.
The Summary of Work Managers screen is displayed.
-
For each of the constraints listed above:
Click the name of the constraint. The Settings for constraint_name window is displayed.
Verify that the value of the Count field is the value expected from your calculations. If it is not, click Lock & Edit, change the value, and click Save.
-
Click Activate Changes if you changed any values.
-
-
Verify the size of the osmGuiMinThreadConstraint constraint, which is used for the following OSM client work managers:
-
osmOmClientWorkManager
-
osmTaskClientWorkManager
To validate the minimum thread constraint for the OSM clients, do the following:
-
In the Administration Console, in Domain Structure, expand Environment, and then select Work Managers.
The Summary of Work Managers screen is displayed.
-
Click osmGuiMinThreadConstraint.
The Settings for constraint_name window is displayed.
-
Verify that the value of the Count field is 4. If it is not, click Lock & Edit, change the value, and click Save.
-
Click Activate Changes if you changed the value.
-
-
Restart all the managed servers in the cluster.
Guidelines for Performance Testing and Tuning
This section provides general guidelines and example procedures for conducting performance tests on OSM. The sample procedures use SoapUI and JConsole. The method involves testing and tuning the OSM system until you determine the sustainable order rate for each managed server in the OSM WebLogic Server cluster and for the Oracle RAC database instances.
Your performance goals, including the expected results for each test run, are typically based on business objectives.
In working toward achieving the optimum performance for your OSM system, keep the following high-level goals in mind:
-
Maximizing the rate by which orders are processed by the system (order throughput)
-
Minimizing the time it takes for each order to complete
The performance testing and tuning examples provided in this section illustrate how you can find the correct balance between these considerations, which often affect one another. For example, when you achieve maximum throughput, orders might not have the fastest completion time. Sometimes you must configure OSM to respond faster but at the expense of order throughput.
The example performance test also addresses the technical safety boundaries for the system, such as a hardware resource utility (for example, heap size), and the ability to process a certain number of orders and manual users at the same time. The example performance test also addresses secondary technical goals that ensure the system can continue running under stress, such as handling a large burst of orders, outages of other systems, or failover and recovery of OSM hardware.
Note:
Even if you cannot define specific performance requirements, it is valuable to conduct performance testing in order to get benchmark numbers that you can compare with future releases of the solution.General Guidelines for Running Tests and Analyzing Test Performance
To analyze the results of the test runs, do the following during testing:
-
Gather operating system information for OSM application machines.
-
Gather Automatic Workload Repository (AWR) snapshots for Oracle RAC, ADDM, and (Active Session History) ASH reports from the database for the exact duration of the test.
-
Monitor information for WebLogic Server CPU, heap, and threads using tools like VisualVM or JConsole.
-
Gather garbage collection logs and server logs.
-
Gather multiple thread dumps regularly, especially during issues.
-
Gather heap dumps, if necessary.
-
Monitor WebLogic server activities, such as JMS queues, JDBC connections, execute thread pool, and so on, using WLST.
-
Monitor network and storage for less latency and consistent throughput based on the documented service times for the hardware.
Example Performance Tests on OSM Managed Servers
When you have created a production ready OSM solution and have deployed it in a test environment as described in "Guidelines for the Performance Test Environments", you can run the performance tests described in this section. The performance testing process includes the following steps:
-
Determine how long your orders last and set the order volatility level on the OSM schema.
-
Begin a performance test to warm up the production system to achieve the following:
-
Enable the OSM server to compile all Java classes involved in processing orders.
-
Enable incremental statistics gathering on low, medium, and high volatility order and gather statistics at appropriate times.
-
Determine the appropriate size of the JBoss and Coherence order cache and the order cache inactivity timeouts.
-
-
Run the performance test.
-
Gather data.
-
Analyze data.
-
Tune the work manager constraints and the maximum connection pool capacity.
-
Tune the JBoss and Coherence maximum order cache.
-
Tune the redo log file size.
In addition to the steps described in this chapter, you must also tune other components such as the database, the operating system, the network, the storage, and so on.
Setting the Order Volatility Level
Before you warm up your system, you can specify whether you have low, medium, or high volatility orders for a specific group of database tables. Order with high volatility last for only a few second. Orders with low volatility can last for hours or even days. Orders that are a mix of high or low volatility can be classified as medium volatility. You must specify the order volatility level for these tables because the volatility level is dependent on the solution. For more information about statistics, see OSM System Administrator's Guide.
Log in to the OSM core schema and run the following commands to set the order volatility level:
execute om_db_stats_pkg.set_table_volatility('OM_ORDER_FLOW',om_const_pkg.v_volatility_volatility_level); execute om_db_stats_pkg.set_table_volatility('OM_AUTOMATION_CTX',om_const_pkg.v_volatility_volatility_level); execute om_db_stats_pkg.set_table_volatility('OM_AUTOMATION_CORRELATION',om_const_pkg.v_volatility_volatility_level); execute om_db_stats_pkg.set_table_volatility('OM_ORDER_POS_INPUT',om_const_pkg.v_volatility_volatility_level); execute om_db_stats_pkg.set_table_volatility('OM_UNDO_BRANCH_ROOT',om_const_pkg.v_volatility_volatility_level); execute om_db_stats_pkg.set_table_volatility('OM_ORCH_DEPENDENCY_PENDING',om_const_pkg.v_volatility_volatility_level);
where volatility_level is low, medium, or high.
Warming Up the OSM System
Before an OSM performance test, you must start and run the WebLogic servers and the database so that all Java classes compile and the cache of the database populates with data. Typically, running the system for 5 to 10 minutes at 30 percent of its maximum order intake is enough, at which point the WebLogic server CPU usage and database input/output have stabilized.
After the initial warm-up period, you must run orders again at a higher rate to gather database statistics about low, medium, and high volatility tables. Do not gather statistics unless you have properly warmed up the system or the statistics will not be representative.
While you are running the orders, you must also set various JBoss and Coherence order cache values in preparation for the performance test.
For example, to run a warm up session with SoapUI, do the following:
-
Download and install SoapUI.
-
Create a SoapUI project.
-
Within the project, create a test suite.
-
Create a test step for CreateOrderBySpecification using a single order.
-
Open the order.
-
Click on the address bar and select Add new endpoint.
The Add new endpoint screen is displayed.
-
Enter the following:
http://hostname:port/OrderManagement/wsapi
where hostname is the managed server host name or IP address and port is the port number of the managed server.
-
Submit the order to verify connectivity with the OSM managed server.
-
Create a load test with the representative set of orders.
-
Open the load test.
-
In the Limit field enter a number. For example 600. This value in seconds causes the load test to run for 10 minutes which is enough of the initial warm up time to enable the Java classes to compile.
-
In the Threads field, enter 4.
-
In the Delay field, enter a number. For example 15000. This value represents a 15000 millisecond delay interval (2.5 seconds) in which SoapUI submits the orders. The higher the value, the longer the delay, and the fewer orders are submitted. The lower the value, the shorter the delay, and more orders are submitted.
-
Open a terminal and run the following command:
ps -ef | grep managed_server
where managed_server is the name of the managed server you are tuning. The output specifies the current user name running the managed server and the first set of numbers specifies the process ID (PID) number of the managed server.
-
Run Java_home/bin/jconsole (where Java_home is the JDK root directory) to run the JConsole application for monitoring
The New Connection screen is displayed.
-
Select the PID that corresponds to the one from the results in step 14.
-
Click Connect.
-
Click Insecure.
-
Click the Memory tab.
-
From the Chart list, select Memory Pool "PS Old Gen".
-
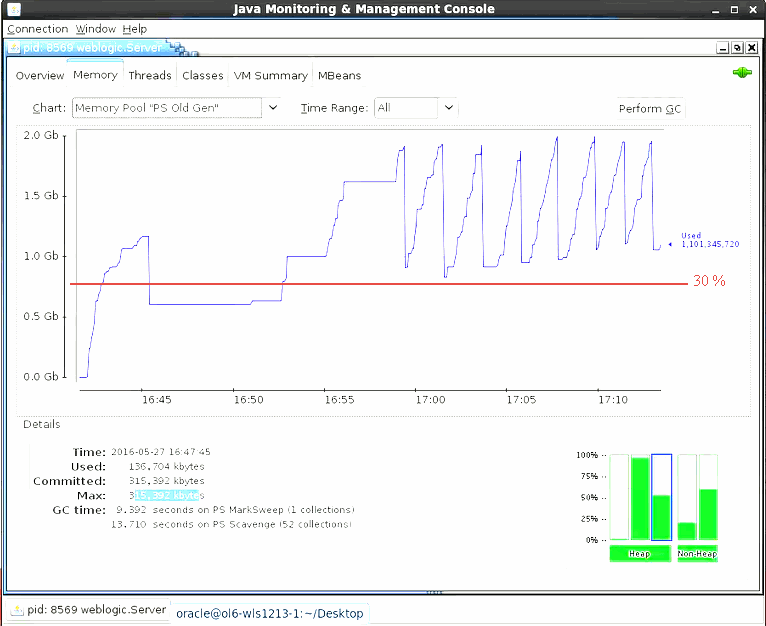
Monitor the life data size (LDS) which is the number of live objects that remain after a garbage collection. Ensure that the LDS is no more than 30% of the maximum old generation during the warm up process. If the order rate causes the LDS to increase above 30%, then the managed server is processing too many orders. Increase the Delay field amount on the SoapUI Load Test screen until you see the live objects after garbage collection return to 30%.
For example, Figure 11-1 shows a small 2.5 GB managed server running with more than 30% live objects after garbage collection.
-
After the initial performance test to compile the Java classes completes, set the Limit value to a higher number. For example 1800 for a 30 minute performance test for gathering database statistics.
Note:
The duration you set depends on the OSM system being tested. Some systems may require longer than 30 minutes. -
Start the performance test for gathering low volatility statistics and determining order cache eviction time.
-
Log in to the order management schema.
-
Enable incremental statistics on low volatility orders.
execute om_db_stats_pkg.set_table_prefs_incremental(a_incremental => true,a_volatility => om_const_pkg.v_volatility_low);
-
After the performance test has completed, gather statistics on the low volatility orders. Because the database is no longer processing orders, you can use all available threads (default behavior) to gather statistics.
execute om_db_stats_pkg.gather_order_stats(a_force => true,a_volatility => om_const_pkg.v_volatility_low);
-
Use the OSM Task web client and verify the average time it takes for orders to complete.
To verify the average time it take for order to complete, do the following:
-
Log in to the OSM Task web client.
-
Click Reporting.
-
Click Completed Order Statistics.
-
In the From field, enter the starting time and date for the current performance test.
-
In the To field, enter the current time and date for the performance test.
-
Click Find.
-
Compare the average time it take for orders to complete from the Avg Time column with the longest time it take for orders to complete from the Highest Time column. You can use these values to determine how long orders should stay in the cache before being evicted. For example, if orders, on average, take three minutes to complete and it took five minutes for the longest, then a four minute cache eviction timeout for inactivity would be reasonable. Or, if most orders take 30 minutes to complete and the longest took 50 minutes to complete, then a forty minute timeout for inactivity would be enough. The inactivity timeout should capture 80% of your order volume.
-
-
Using a text editor, open the domain_home/oms-config.xml file.
-
Add the following text to the bottom of the file before the final </oms-configuration> tag to configure the JBoss cache:
<oms-parameter> <oms-parameter-name>ClosedOrderCacheMaxEntries</oms-parameter-name> <oms-parameter-value>60</oms-parameter-value> </oms-parameter> <oms-parameter> <oms-parameter-name>ClosedOrderCacheTimeout</oms-parameter-name> <oms-parameter-value>60</oms-parameter-value> </oms-parameter> <oms-parameter> <oms-parameter-name>OrderCacheMaxEntries</oms-parameter-name> <oms-parameter-value>order_max</oms-parameter-value> </oms-parameter> <oms-parameter> <oms-parameter-name>OrderCacheInactivityTimeout</oms-parameter-name> <oms-parameter-value>inactivity_timeout</oms-parameter-value> </oms-parameter>
where
-
order_max is the maximum number of orders that can be in the managed server's JBoss cache. Set this value to a high number, such as 2000 for the purposes of performance tuning procedure. You will change this number to a lower setting after completing the performance tuning procedure.
-
inactivity_timeout is the value you determined in step 27 in seconds. This timeout evicts an order from the JBoss cache.
-
-
Save and close the file.
-
Using a text editor, open the osm-coherence-cache-config.xml file. See "Configuring and Monitoring Coherence Threads" for more information about locating and externalizing the osm-coherence-cache-config.xml file.
-
Search on osm-local-large-object-expiry:
<scheme-name>osm-local-large-object-expiry</scheme-name> <eviction-policy>LRU</eviction-policy> <high-units>order_max</high-units> <low-units>0</low-units> <unit-calculator>FIXED</unit-calculator> <expiry-delay>inactivity_timeout</expiry-delay> <flush-delay>1000ms</flush-delay> </local-scheme>
where
-
order_max is the maximum number of orders that can be in the managed server's Coherence cache. Set this value to a high number, such as 2000 for the purposes of performance tuning procedure. You will change this number to a lower setting after completing the performance tuning procedure.
-
inactivity_timeout is the value you determined in step 27 in seconds. This timeout evicts an order from the Coherence cache.
-
-
Save and close the file.
-
Restart all servers.
-
In the SoapUI load test screen, change the Delay field to a smaller number, such as 12000 which is two seconds, and run a second 30 minute load test.
-
Start the performance test for gathering medium and high volatility statistics.
-
Monitor the life LDS and ensure that the LDS is no more than 50% of the maximum old generation. If the order rate causes the LDS to increase above 50%, increase the Delay field amount on the SoapUI Load Test screen.
-
Log in to the order management schema.
-
Enable incremental statistics on medium and high volatility orders.
execute om_db_stats_pkg.set_table_prefs_incremental(a_incremental => true,a_volatility => om_const_pkg.v_volatility_medium); execute om_db_stats_pkg.set_table_prefs_incremental(a_incremental => true,a_volatility => om_const_pkg.v_volatility_high);
-
During the performance test, gather statistics on the medium and high volatility orders. The following statements also reduce the number of threads used for gathering statistics to two so that order processing does not suffer a performance impact.
execute DBMS_STATS.SET_SCHEMA_PREFS(user, 'DEGREE', 2); execute om_db_stats_pkg.gather_order_stats(a_force => true,a_volatility => om_const_pkg.v_volatility_high); execute DBMS_STATS.SET_SCHEMA_PREFS(user, 'DEGREE', 'DBMS_STATS.AUTO_DEGREE'); execute DBMS_STATS.SET_SCHEMA_PREFS(user, 'DEGREE', 2); execute om_db_stats_pkg.gather_order_stats(a_force => true,a_volatility => om_const_pkg.v_volatility_medium); execute DBMS_STATS.SET_SCHEMA_PREFS(user, 'DEGREE', 'DBMS_STATS.AUTO_DEGREE');
Note:
If this is the first time you run this performance test with optimizer statistics gathered, some SQL execution plans may not be optimal. The database compares execution plans during the overnight maintenance window and accepts the better plans at that time. You may want to repeat the test the following day to see if there is a performance improvement. In addition, you may want your DBA to review which execution plans the database selected during the maintenance window because they may not always be the most optimal.Determining the Sustainable Order Rate for a Managed Server
The following procedure should be done after completing warm up procedures.
-
Log on to the Oracle database as sys or the equivalent (traditional database or the pluggable database) and create an Oracle database automatic workload repository (AWR) snapshot.
-
Open the SoapUI load test.
-
In the Limit field enter a number. For example 3600. This value is in seconds and causes the load test to run for 60 minutes, which is enough for the performance test although in some cases a longer period is required.
-
In the Threads field, enter 4.
-
In the Delay field, enter a number. For example 15000. This value represents a 15000 millisecond delay interval (2.5 seconds) between order submissions. The higher the value, the longer delay, and the less orders are submitted. The lower the value, the shorter the delay, and more orders are submitted.
-
Start the performance test.
-
As you are running the performance test, run JConsole.
-
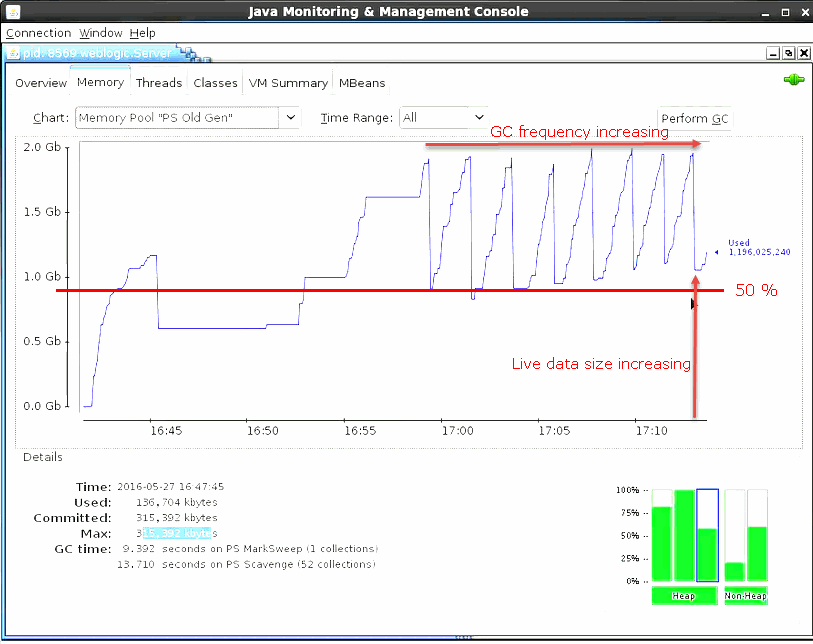
Monitor the LDS and ensure that the level is stable at around 50% of the maximum old generation. If the order injection rate causes the LDS to increase above 50% for an extended time and if the LDS continues to increase so that garbage collection becomes more and more frequent, then decrease the number of orders you submit by increasing the Delay field amount on the SoapUI Load Test screen. For example, you might move from a 2.5 second delay to a 3 second delay.
Figure 11-2 shows garbage collection with a steadily increasing frequency and LDS size. If the order injection rate were to remain at the current level, the managed server would eventually crash.
The inverse scenario is also possible where the LDS size is lower than 50% and the frequency of garbage collection is much longer. In this case, you must increase the order injection rate by decreasing the Delay field amount on the SoapUI Load Test screen.
Note:
The frequency of garbage collection and the size of the LDS for a 32 GB managed server is much larger than is depicted in Figure 11-2. The maximum old generation in a 32 GB managed server is 17 GB and the target LDS is 50% of the old generation which is 8.5 GB. Depending on the size and complexity of your orders, garbage collection make take a long time to occur. For example, garbage collection may only occur once every half hour. If very long garbage collection intervals are occurring, then increase the length of the performance test to two or even three hours to get an accurate garbage collection sampling. See step 3 to increase the length of the performance test. -
When the LDS level has stabilized during the performance test, verify the number of automation threads being used to support the current number of orders that the managed server is processing. This value will be used to set the work manager maximum thread constraint for automations.
To verify the number of automation threads in use and set the automation work manager maximum constraint, do the following:
-
Log in to the WebLogic Server Administration Console.
The WebLogic Administration Console is displayed.
-
In Domain Structure, expand Environment and then select Servers.
The Summary of Servers page is displayed.
-
Click the name of the WebLogic server that you are tuning.
The configuration parameters for the server are displayed on a tabbed page.
-
Click the Monitoring tab.
-
Click the Threads subtab.
-
Above the Self-Tuning Thread Pool Threads table, click Customize this table.
-
In the Filter by Column list, select Work Manager.
-
In the Criteria field, enter osmAutomationWorkManager.
-
Click Apply.
-
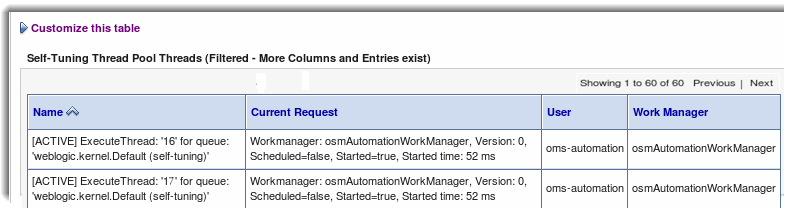
Refresh the screen every minute over 30 minutes to determine the highest number of active osmAutomationWorkManager threads you see after a refresh during that time.
Figure 11-3 shows the beginning of a table that lists 60 active automation threads.
Note:
It is possible that there may be no active threads after refreshing. This does not indicate a problem unless the result occurs consistently.
-
-
Determine the maximum number of orders that can be in the JBoss and Coherence cache:
-
Open a terminal on the machine running the manager server that you are tuning.
-
In a text editor, open domain_home/servers/managed_server/logs/managed_server.out (where managed server is the name of the managed server you are tuning).
-
Search the log file for cache information using the # Orders Information text. Search through all instances and find the highest instance of the Orchestration Cache or the Order Cache value (whichever is greater of the two, although they are typically identical).
This example, after searching through 30 cache information instances, the following cache information instance shows the highest set of cache values:
Cache % Full # Orders Information ---------------------- ------ -------- ----------- Closed Order Cache 12% 6/50 Historical Order Cache 8% 80/1000 Orchestration Cache 40% 400/1000 Order Cache 40% 401/1000 Redo Order Cache 0% 0/1000
You would select the Order Cache number in this example because it is higher than the Orchestration Cache number.
-
-
After you finish the test, log on to the Oracle database again and create a second AWR snapshot.
-
Generate a report using both AWR snapshots.
-
Ask a database administrator (DBA) to analyze the AWR report to determine whether the database is performing as expected. DBAs are trained to detect database performance issues such as an undersized database or suboptimal SQL statement execution plans.
Tuning Work Manager Constraints and the Maximum Connection Pool Capacity
To set work manager constraints and the maximum connection pool capacity for OSM JDBC data sources, do the following:
-
Log in to the WebLogic Server Administration Console.
-
In Domain Structure, expand Environment, and then select Work Managers.
The Summary of Work Managers page is displayed.
-
Click Lock & Edit.
-
Select the osmAutomationMaxThreadConstraint.
The Configuration tab appears.
-
In the Count field, enter the number of automation threads you observed in step 9 of the "Determining the Sustainable Order Rate for a Managed Server" procedure.
The example in Figure 11-3 of step 9 showed 60 automations active.
-
Click Save.
-
In Domain Structure, expand Environment, and then select Work Managers.
The Summary of Work Managers page is displayed.
-
Select the osmGuiMaxThreadConstraint.
The Configuration tab appears.
-
In the Count field, enter a number. This value is typically half of the osmAutomationMaxThreadConstraint count although if you have a solution that makes extensive use of manual tasks, you may need to raise this value.
For example, if the osmAutomationMaxThreadConstraint was 60 then the osmGuiMaxThreadConstraint would be 30. However, if the OSM client users begin to experience long delays before they can gain access to an OSM client session, then you may want to raise this value. You should include OSM client users in you performance test to ensure that the ratio of threads allocated to osmGuiMaxThreadConstraint and osmAutomationMaxThreadConstraint is properly balanced.
-
Click Save.
-
In Domain Structure, expand Environment, and then select Work Managers.
The Summary of Work Managers page is displayed.
-
Select the osmJmsApiMaxThreadConstraint.
The Configuration tab appears.
-
In the Count field, enter a number. A typical starting value is between 4 to 6 which is enough in most cases. If the overall heath of the managed server and the database are good, but the web service JMS queue is accumulating messages, then this value could be increased. Increase the value incrementally, and run additional performance tests to ensure that the overall health of the managed server and database continues to be good.
-
Click Save.
-
In Domain Structure, expand Environment, and then select Work Managers.
The Summary of Work Managers page is displayed.
-
Select the osmHttpApiMaxThreadConstraint.
The Configuration tab appears.
-
In the Count field, enter a number. A typical starting value is between 4 to 6 which is enough in most cases. If the overall heath of the managed server and the database are good then this value could be increased. Increase the value incrementally, and run additional performance tests to ensure that the overall health of the managed server and database continues to be good.
-
Click Save.
-
Add the all the maximum constraints you have configured and divide the total by 0.80 (80%) to determine the maximum connection pool size. For example, if you had the following constraint values:
-
osmAutomationMaxThreadConstraint = 60
-
osmGuiMaxThreadConstraint = 30
-
osmJmsApiMaxThreadConstraint = 5
-
osmHttpApiMaxThreadConstraint = 5
which results in 100 / 0.80 which equals = 125 maximum connection pool size.
-
-
Log in to the WebLogic Server Administration Console.
The WebLogic Administration Console is displayed.
-
In Domain Structure, expand Services, and then select Data Sources.
The Summary of JDBC Data Sources screen is displayed.
-
Select an OSM JDBC data source. The OSM JDBC data source are as follows:
osm_pool_sid_group_y
where sid is the Oracle RAC database instance system identifier and y is the group letter.
The Configuration tab is displayed
-
Click the Connection Pools tab.
-
In the Maximum Capacity field, enter the value you calculated in step 19.
-
Click Save.
-
Click Activate Changes.
Tuning the JBoss and Coherence Maximum Order Cache
To set the maximum number of orders in the JBoss and Coherence cache for managed servers, do the following:
-
Using a text editor, open the domain_home/oms-config.xml file.
-
Change the JBoss OrderCacheMaxEntries value:
<oms-parameter> <oms-parameter-name>OrderCacheMaxEntries</oms-parameter-name> <oms-parameter-value>order_max</oms-parameter-value> </oms-parameter>
where order_max is the maximum number of orders that can be in the managed server's JBoss cache. Set this value to the number orders in the cache that you observed in step 10 of the "Determining the Sustainable Order Rate for a Managed Server" procedure.
-
Save and close the file.
-
Using a text editor, open the osm-coherence-cache-config.xml file. See "Configuring and Monitoring Coherence Threads" for more information about locating and externalizing the osm-coherence-cache-config.xml file.
-
Search on osm-local-large-object-expiry:
<scheme-name>osm-local-large-object-expiry</scheme-name> <eviction-policy>LRU</eviction-policy> <high-units>order_max</high-units>
where order_max is the maximum number of orders that can be in the managed server's Coherence cache. Set this value to the number orders in the cache that you observed in step 10 of the "Determining the Sustainable Order Rate for a Managed Server" procedure.
-
Save and close the file.
Sizing the Redo Log Files
Using the AWR log files generated in the "Determining the Sustainable Order Rate for a Managed Server" section, check the log switches (derived) statistics. Log switching should occur at a frequency no less than 20 minutes apart. If the frequency of log switching is less than 20 minutes apart, then the redo log files are undersized. Increase the log file size, or number of redo groups, or both.
Checkpoint frequency is affected by several factors, including log file size and the FAST_START_MTTR_TARGET initialization parameter. If you set this parameter to limit the instance recovery time, Oracle Database automatically tries to checkpoint as frequently as necessary. The optimal size can be obtained by querying the OPTIMAL_LOGFILE_SIZE column from the V$INSTANCE_RECOVERY view. If FAST_START_MTTR_TARGET is not set, OPTIMAL_LOGFILE_SIZE is not set either.
For more information about sizing redo log files, see Oracle Database Performance Tuning Guide.
If the above change does not reduce checkpoint frequency, use the renice command to set the Log Writer Process (LGWR) to run at higher priority or run LGWR in the redo thread (RT) class by adding LGWR to the parameter: _high_priority_processes='VKTM|LGWR". Only change _high_priority_processes in consultation with database support. For example, more processes may need to be added, such as PMON. And if the database is an Oracle RAC database, LMS should be added to this parameter. Test this change thoroughly.
Finally, if all other methods fail to reduce checkpoint frequency, set the _log_parallelism_max hidden parameter after consultation with database support.
Additional Performance Testing Options
The following sections provide additional performance testing options.
Performance-Related Features for Large Orders
In some cases, you might want to model large orders for OSM. A large order typically contains a sizeable payload with more than a hundred order items, and where each order item may contain many data elements. OSM provides the following features that can help you manage these large orders:
-
Order automation concurrency control (OACC) is a policy driven OSM function that you can use to limit the number of concurrent automations plug-in instances that OSM can process at one time. For large orders, this ability can significantly reduce contention caused by an excessive number of automation plug-ins processing at the same time. High levels of automation plug-in contention can create performance issues because of the number of message retries and timeouts on the JMS queues. You can specify a policy using the AutomationConcurrencyModels parameter in the oms-config.xml file (see OSM System Administrator's Guide) or you can include an OACC policy in solution cartridge. See OSM Developer's Guide for information about creating OACC policies.
-
Use the oracle.communications.ordermanagement.table-layout.size and the oracle.communications.ordermanagement.table-layout.fetch-size oms-config.xml parameter to create a threshold that limit the number of order rows that OSM can retrieve at one time from the database when using Data tab in the Order Management web client. See OSM System Administrator's Guide for more information.
-
Use the oracle.communications.ordermanagement.table-layout.threshold oms-config.xml parameter to specify a threshold that automatically applies the style behavior table layout if a multi-instance node exceeds the threshold when using Data tab in the Order Management web client. See OSM System Administrator's Guide for more information.
-
Ensure that the show_all_data_history_logs_for_orderdetails is set to false to reduce the number of logs that OSM generates. See OSM System Administrator's Guide for more information.
Distribution of High-Activity Orders
High-activity orders have a large number of processes, sub-processes, and tasks that must be run concurrently. Because the workload for a high-activity order can be significantly higher than for a typical order, OSM may redistribute a high-activity order to another active server instance proportionate to the managed server weights within the cluster. This redistribution based on weight ensures that one managed server does not get an unfair share of high-activity orders because of round robin-load balancing and ensures that high-activity orders are properly distributed among members in the cluster.
Note:
A high-activity order is not exempt from order affinity: when OSM redistributes the order, it transfers the entire order and order ownership to another managed server. This redistribution does not mean that the order is being processed and owned by more than one managed server. See "About Order Affinity and Ownership in an OSM WebLogic Cluster" for more information.High activity order processing is enabled by default. To tune or disable the high-activity order routing mode in OSM, you must configure a set of related parameters in the oms-config.xml file. See OSM System Administrator's Guide for a detailed reference of available parameters.
Measuring Order Throughput
Based on the order complexity guidelines specified in "Overview of Planning Your OSM Production Installation", you can calculate order throughput per second (TPS) using the following formula:
(throughput in task transitions per second) / (average number of tasks per order)
Throughput can then be calculated hourly, by multiplying by 3600 seconds per hour; or daily, by multiplying by 3600 seconds per hour plus the number of operating hours per day.
To determine a TPS value:
-
Log onto a database.
-
Enter the following statements:
alter session set nls_date_format = 'dd-mon-yyyy hh24:mi:ss'; select count(*), min(timestamp_in), max(timestamp_in), 24*3600*(max(timestamp_in)-min(timestamp_in)) duration, to_char ((count(*)/(24*3600*(max(timestamp_in)-min(timestamp_in)))), '9999.999') tasks_per_sec from om_hist$order_header where hist_order_state_id = 4 and task_type in ('A','M','C') and timestamp_in between 'dd-mon-yyyy hh24:mi:ss' and 'dd-mon-yyyy hh24:mi:ss';
where
-
dd is the day.
-
mon is the first three letters of the month.
-
yyyy is the year.
-
hh24 is the number of hours in the 24 hour format.
-
mi is the number of minutes.
-
ss is the number of second.
-
Using the OM_ORDER_NODE_ANCESTRY Table
OM_ORDER_NODE_ANCESTRY is a table that stores the hierarchy of order group nodes. The table improves the efficiency and response time of worklist and order search queries, mainly for cartridges that have multi-instance subprocesses and a large number of flexible headers. For more information about parallel processes and multi-instance subprocesses, see the topic about understanding parallel process flows in OSM Concepts.
The downside of enabling the OM_ORDER_NODE_ANCESTRY table is increased CPU usage for order creation and updates, increased order creation response time, and most importantly increased disk usage. Specifically, OM_ORDER_NODE_ANCESTRY is one of the largest tables in OSM. It is often responsible for more than 20% of the space, depending on the depth of order templates, especially for large orders, such as O2A. Therefore, this table is disabled by default.
An Oracle database package called OM_ORDER_NODE_ANCESTRY_PKG contains the stored procedures that allow you enable and disable the OM_ORDER_NODE_ANCESTRY table.
Note:
If you deploy cartridges with multi-instance subprocesses and are considering running OSM with the OM_ORDER_NODE_ANCESTRY table disabled, you must evaluate factors such as the ancestry depth in the master order template and the number of flexible headers, which could impact performance in the UI worklist and search results.Table 11-1 shows the performance implications of running different cartridges in OSM with the OM_ORDER_NODE_ANCESTRY table enabled or disabled.
Table 11-1 Performance Implications of the OM_ORDER_NODE_ANCESTRY Table
| OSM Solution | OM_ORDER_NODE_ANCESTRY Table Status | Performance Implications |
|---|---|---|
|
Cartridges that do not require multi-instance subprocesses |
Disabled |
Positive impact:
|
|
Cartridges that require multi-instance subprocesses |
Enabled |
Positive impact:
Negative impact:
In this case, consider compressing the ancestry table. For more information about Oracle advanced compression, see Oracle Technology Network. Note that compression has the following negative impact:
|
|
Cartridges that require multi-instance subprocesses |
Disabled |
Positive impact:
Negative impact:
In this case, Oracle recommends:
|
Enabling the OM_ORDER_NODE_ANCESTRY Table
When the OM_ORDER_NODE_ANCESTRY table is enabled, OSM populates the OM_ORDER_NODE_ANCESTRY table with data and uses queries on this table to support UI worklist and order searches. Running OSM in this mode is effective for new order id blocks. A new block is allocated when the current partition where new orders are created (known as the active partition) is exhausted.
Order ids are stored in the OM_ORDER_ID_BLOCK table. In this table, a column called ANCESTRY_POPULATED_UP_TO indicates the last order id in the block of order ids that has data in the OM_ORDER_NODE_ANCESTRY table.
An active order id block can be split logically, as in the following example:
-
An order id block contains order ids from 0 to 100000. The order id block is NOT split yet and all order ids in this block contain ancestry data.
-
An order id block is split. Orders ids between order id 0 and 2000 have ancestry data. Orders between order id 2001 and 100000 do not have ancestry data.
A block of order ids is active if it is the latest block for the current database instance (DBINSTANCE). The previous blocks for the database instance are inactive blocks.
When users retrieve worklist tasks or search for orders, OSM uses the data in order id blocks to determine if queries are run against the OM_ORDER_NODE_ANCESTRY table (old queries) or the OM_ORDER_INSTANCE table (new queries).
Note:
Ancestry data is used only if the cartridge includes multi-instance tasks (pivot nodes).You might need to switch several times between running OSM with the OM_ORDER_NODE_ANCESTRY table enabled and disabled. The following example scenarios illustrate circumstances that might necessitate switching between the two modes.
Scenario 1: Introducing multi-instance subprocess entities (enable, disable, enable)
-
You have upgraded OSM to a later version that includes this functionality. OSM continues to run with the OM_ORDER_NODE_ANCESTRY table enabled.
-
Because of large volumes of orders, you determine that OSM cartridges do not use multi-instance subprocesses and decide to disable the OM_ORDER_NODE_ANCESTRY table.
-
Some time later, you introduce multi-instance sub-process entities (for example, OSM needs to run a sub-process for each of the multiple addresses a customer has) by redeploying existing, or deploying new, cartridges.
-
You then determine that the worklist demonstrates performance degradation and decide to re-enable the OM_ORDER_NODE_ANCESTRY table.
Scenario 2: Eliminating multi-instance subprocess entities (disable, enable, disable)
-
You install the latest release of OSM, which includes this functionality. The OM_ORDER_NODE_ANCESTRY table is disabled.
-
You deploy a cartridge that uses multi-instance subprocesses, and leave the table disabled because performance test results are satisfactory.
-
You then determine that the worklist demonstrates performance degradation and decide to enable the OM_ORDER_NODE_ANCESTRY table.
-
Some time later, you redeploy updated cartridges so that all multi-instance subprocesses are eliminated. You then disable the OM_ORDER_NODE_ANCESTRY table.
You can run this procedure when OSM is online or offline.
To enable the OM_ORDER_NODE_ANCESTRY table:
-
Log in to SQL*Plus as the OSM core schema user.
-
Run the following command:
begin om_order_node_ancestry_pkg.enable_ancestry_table; end;
Disabling the OM_ORDER_NODE_ANCESTRY Table
Running OSM with the OM_ORDER_NODE_ANCESTRY table disabled is suitable if you are deploying cartridges that do not include multi-instance subprocesses. When you run OSM with the table disabled, the OM_ORDER_NODE_ANCESTRY table is not populated and hierarchical queries (for cartridges with multi-instance subprocesses) that are run using UI worklist or search functionality return ancestry data from the OM_ORDER_INSTANCE table.
You must disable the OM_ORDER_NODE_ANCESTRY table when OSM is offline because the procedure uses the last order id to split the block of order ids into two parts: populated and non-populated. For example, if the current order id is 100 and the last order id in the active block is 10000:
-
[1...100...10000] is logically split into:
-
[1...100]: order ids with populated ancestry
-
[101...10000]: order ids with non-populated ancestry
-
To disable the OM_ORDER_NODE_ANCESTRY table:
-
Log in to SQL*Plus as the OSM core schema user.
-
Take the OSM server offline. For more information about stopping OSM, see OSM System Administrator's Guide.
-
Run the following command:
begin om_order_node_ancestry_pkg.disable_ancestry_table; end;Note:
You can run the disable OM_ORDER_NODE_ANCESTRY table procedure only once on a single block of ids because the current block of ids can be split only once.