Data Flow-Anwendungen entwickeln
Erfahren Sie mehr über die Bibliothek , einschließlich wiederverwendbarer Spark-Anwendungsvorlagen und Anwendungssicherheit. Außerdem erfahren Sie, wie Anwendungen erstellt, angezeigt, bearbeitet und gelöscht werden und wie Sie Argumente oder Parameter anwenden.
- Beim Erstellen von Anwendungen mit der Konsole
- Geben Sie unter Erweiterte Optionen die Dauer in Max. Ausführungsdauer in Minuten an.
- Beim Erstellen von Anwendungen mit der CLI
- Befehlszeilenoption
--max-duration-in-minutes <number>übergeben - Beim Erstellen von Anwendungen mit dem SDK
- Geben Sie das optionale Argument
max_duration_in_minutesan. - Beim Erstellen von Anwendungen mit der API
- Legen Sie das optionale Argument
maxDurationInMinutesfest.
Wiederverwendbare Spark-Anwendungsvorlagen
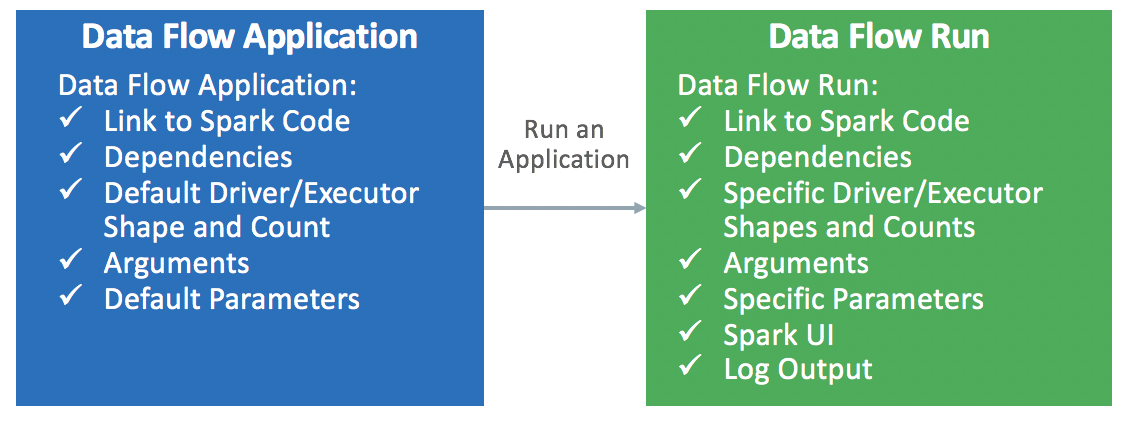
Eine Anwendung ist eine unendlich wiederverwendbare Spark-Anwendungsvorlage.
Datenflussanwendungen enthalten eine Spark-Anwendung, ihre Abhängigkeiten, Standardparameter und eine Spezifikation von Standardlaufzeitressourcen. Nachdem ein Spark-Entwickler eine Datenflussanwendung erstellt hat, kann sie von beliebigen Benutzern verwendet werden, ohne dass diese die Komplexität des Bereitstellens, Einrichtens oder Ausführens berücksichtigen müssen. Sie können sie über Spark-Analysen in benutzerdefinierten Dashboards, Berichten, Skripten oder REST-API-Aufrufen verwenden. 
Wenn Sie die Datenflussanwendung aufrufen, erstellen Sie eine Ausführung . Es füllt die Details der Anwendungsvorlage aus und startet sie mit einer bestimmten Gruppe von IaaS-Ressourcen.