Mit Notizbüchern eine Verbindung zu Data Flow herstellen
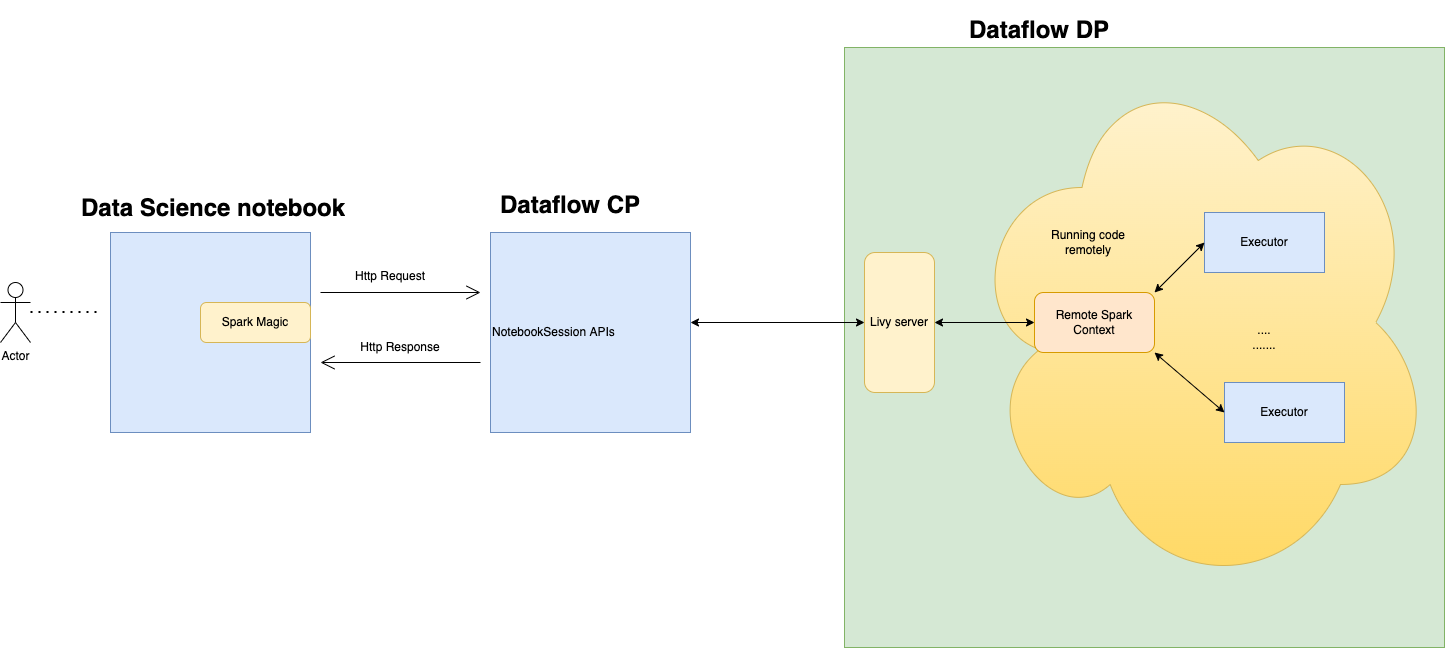
Sie können eine Verbindung zu Data Flow herstellen und eine Apache Spark-Anwendung über eine Data Science-Notizbuchsession ausführen. Mit diesen Sessions können Sie interaktive Spark-Workloads in einem langlebigen Data Flow-Cluster über eine Apache Livy-Integration ausführen.
Data Flow verwendet vollständig verwaltete Jupyter-Notebooks, damit Data Scientists und Data Engineers Data-Engineering- und Data Science-Anwendungen erstellen, visualisieren und debuggen sowie zusammen daran arbeiten können. Sie können diese Anwendungen in Python, Scala und PySpark schreiben. Sie können auch eine Data Science-Notebook-Session zur Ausführung von Anwendungen mit Data Flow verbinden. Die Datenflusskernels und -anwendungen, die auf Oracle Cloud Infrastructure Data Flow ausgeführt werden. Data Flow ist ein vollständig verwalteter Apache Spark-Service, der Verarbeitungsaufgaben für extrem große Datasets ausführt, ohne die Infrastruktur bereitstellen oder verwalten zu müssen. Weitere Informationen finden Sie in der Data Flow-Dokumentation.
Apache Spark ist ein verteiltes Compute-System für die skalierbare Datenverarbeitung. Es unterstützt umfangreiche SQL-, Batch- und Streamverarbeitungs- und ML-Aufgaben. Spark SQL bietet datenbankähnliche Unterstützung. Um strukturierte Daten abzufragen, verwenden Sie Spark SQL. Es handelt sich um eine ANSI-Standard-SQL-Implementierung.
Data Flow ist ein vollständig verwalteter Apache Spark-Service, der Verarbeitungsaufgaben für extrem große Datasets ausführt, ohne dass eine Infrastruktur bereitgestellt oder verwaltet werden muss. Mit Spark Streaming können Sie Cloud-ETL für Ihre kontinuierlich erstellten Streamingdaten ausführen. Es ermöglicht eine schnelle Anwendungsbereitstellung, da Sie sich auf die Anwendungsentwicklung und nicht auf das Infrastrukturmanagement konzentrieren können.
Apache Livy ist eine REST-Schnittstelle zu Spark. Leiten Sie fehlertolerante Spark-Jobs aus dem Notizbuch mit synchronen und asynchronen Methoden weiter, um die Ausgabe abzurufen.
SparkMagic ermöglicht die interaktive Kommunikation mit Spark über Livy. Dazu wird die Magic-Anweisung "%%spark" in einer JupyterLab-Codezelle verwendet. Die SparkMagic- Befehle sind für Spark 3.2.1 und die Conda-Umgebung von Data Flow verfügbar.
Data Flow-Sessions unterstützen das Autoskalieren von Data Flow-Clusterfunktionen. Weitere Informationen finden Sie in der Data Flow-Dokumentation unter Autoscaling. Data Flow-Sessions unterstützen die Verwendung von Conda-Umgebungen als anpassbare Spark-Laufzeitumgebungen.
- Einschränkungen
-
-
Data Flow-Sessions dauern bis zu 7 Tage oder 10.080 Minuten (maxDurationInMinutes).
- Data Flow-Sessions haben einen standardmäßigen inaktiven Timeout von 480 Minuten (8 Stunden) (idleTimeoutInMinutes). Sie können einen anderen Wert konfigurieren.
- Die Data Flow-Session ist nur über eine Data Science-Notebooksession verfügbar.
- Es wird nur die Spark Version 3.2.1 unterstützt.
-
Sehen Sie sich das Tutorialvideo zur Verwendung von Data Science mit Data Flow an. Weitere Informationen zur Integration von Data Science und Data Flow finden Sie in der Dokumentation zum Oracle Accelerated Data Science-SDK.