Tabellenextraktion
Mit der Tabellenextraktion können Sie Tabellen in einem Dokument identifizieren und deren Inhalt extrahieren. Beispiel: Wenn eine PDF-Quittung eine Tabelle enthält, die Steuern und den Gesamtbetrag enthält, identifiziert Document Understanding die Tabelle und extrahiert die Tabellenstruktur.
Document Understanding stellt die Anzahl der Zeilen und Spalten für die Tabelle und den Inhalt in jeder Tabellenzelle bereit. Jede Zelle hat einen Konfidenzscore. Der Konfidenzscore ist eine Dezimalzahl. Punkte, die näher an 1 liegen, weisen auf eine höhere Sicherheit im extrahierten Text hin, während niedrigere Scores auf einen niedrigeren Vertrauenswert hinweisen. Der Bereich des Konfidenzscores für jedes Label liegt zwischen 0 und 1.
Folgende Features werden unterstützt:
- Tabellenextraktion für Tabellen mit und ohne Rahmen
- Grenzpolygone
- Sicherheitsscore
- Einzelne Anforderung
- Batchanforderung
- Nur in englischer Sprache
Beispiel für die Tabellenextraktion
Ein Beispiel für die Verwendung der Tabellenextraktion in Document Understanding.
- Eingabedokument
-
API-Anforderung für Tabellenextraktionseingabe
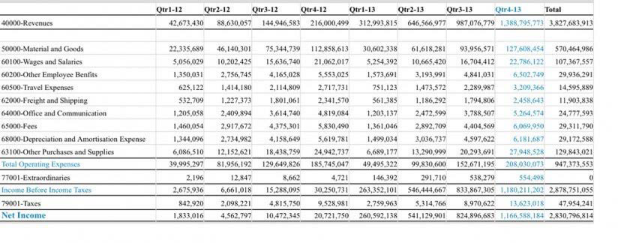 :
:{ "processorConfig": { "processorType": "GENERAL", "features": [ { "featureType": "TABLE_EXTRACTION" } ] }, "inputLocation": { "sourceType": "OBJECT_STORAGE_LOCATIONS", "objectLocations": [ { "source": "OBJECT_STORAGE", "namespaceName": "", "bucketName": "", "objectName": "" } ] }, "compartmentId": "", "outputLocation": { "namespaceName": "", "bucketName": "", "prefix": "" } } - Ausgabe:
-
API-Antwort für Tabellenextraktionsausgabe
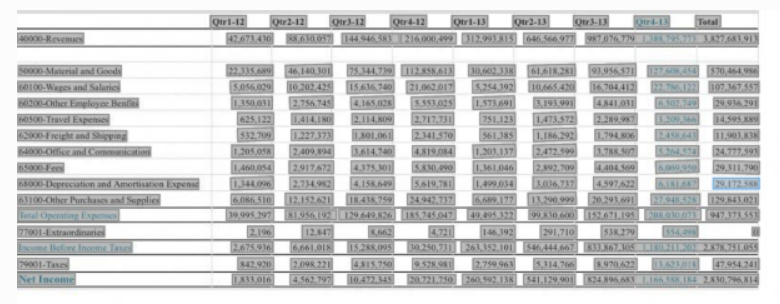 :
:{ "documentMetadata": { "pageCount": 1, "mimeType": "application/pdf" }, "pages": [ { "pageNumber": 1, "dimensions": { "width": 2575, "height": 1013, "unit": "PIXEL" }, ... "tables": [ { "rowCount": 15, "columnCount": 9, "bodyRows": [ { "cells": [ { "text": "Qtr1-12", "rowIndex": 0, "columnIndex": 1, "confidence": 0.92011595, "boundingPolygon": { "normalizedVertices": [ { "x": 0.2532038834951456, "y": 0.022704837117472853 }, { "x": 0.3005825242718447, "y": 0.022704837117472853 }, { "x": 0.3005825242718447, "y": 0.05330700888450148 }, { "x": 0.2532038834951456, "y": 0.05330700888450148 } ] }, "wordIndexes": [ 0 ] }, { "text": "Qtr2-12", "rowIndex": 0, "columnIndex": 2, "confidence": 0.919653, "boundingPolygon": { "normalizedVertices": [ { "x": 0.33048543689320387, "y": 0.022704837117472853 }, { "x": 0.3724271844660194, "y": 0.022704837117472853 }, { "x": 0.3724271844660194, "y": 0.05330700888450148 }, { "x": 0.33048543689320387, "y": 0.05330700888450148 } ] }, "wordIndexes": [ 1 ] }, ...