Bevor Sie beginnen
In diesem Tutorial wird gezeigt, wie Sie mit einer Resource Manager-Vorlage Oracle Cloud Infrastructure Data Science-Ressourcen in Oracle Cloud Infrastructure einrichten. Der Data Science-Service ist für das Autoscaling-Feature von PeopleSoft Cloud Manager erforderlich. Dieses Tutorial dauert etwa 30 Minuten.
Informationen hierzu finden Sie in der Oracle Cloud Infrastructure-Dokumentation unter Mandanten für Data Science mit Oracle Resource Manager konfigurieren.
Hintergrund
Dies ist das achtzehnte Tutorial in der Install PeopleSoft Cloud Manager-Serie. Lesen Sie die Tutorials in der aufgeführten Reihenfolge. Die optionalen Tutorials bieten alternative Methoden für das Setup.
- Installation von PeopleSoft Cloud Manager vorbereiten
- Oracle Cloud-Accountinformationen für PeopleSoft Cloud Manager prüfen
- Virtuelles Cloud-Netzwerk für PeopleSoft Cloud Manager planen (optional)
- Virtuelles Cloud-Netzwerk für PeopleSoft Cloud Manager in der Oracle Cloud Infrastructure-Konsole erstellen (optional)
- Benutzerdefinierte oder private Netzwerkressourcen mit PeopleSoft Cloud Manager verwenden (optional)
- Benutzerdefiniertes Linux-Image für PeopleSoft Cloud Manager erstellen (optional)
- Benutzerdefiniertes Windows-Image für PeopleSoft Cloud Manager in Oracle Cloud Infrastructure erstellen (optional)
- Vault-Ressourcen für die Kennwortverwaltung für PeopleSoft Cloud Manager erstellen
- API-Signaturschlüssel für PeopleSoft Cloud Manager generieren
- Cloud Manager-Stack PeopleSoft mit Resource Manager installieren
- Bei Cloud Manager-Instanz anmelden
- Cloud Manager-Einstellungen angeben
- File Storage Service für PeopleSoft Cloud Manager-Repository verwenden
- Cloud Manager-Benutzer, -Rollen und -Berechtigungslisten verwalten
- Webproxy für PeopleSoft Cloud Manager konfigurieren (optional)
- Load Balancer in Oracle Cloud Infrastructure für PeopleSoft Cloud Manager-Umgebungen erstellen (optional)
- Definierte Tags in Oracle Cloud Infrastructure für PeopleSoft Cloud Manager erstellen (optional)
- Data Science-Ressourcen für Autoscaling in PeopleSoft Cloud Manager erstellen (optional)
Schritt 1: Bereitstellen vorbereiten
Wählen Sie ein Compartment aus, um den Data Science-Stack zu installieren. Die Ressourcen, einschließlich IAM-Policys, die vom Stack erstellt werden, sind für das ausgewählte Compartment spezifisch. Sie müssen dasselbe Compartment verwenden, um den Data Science-Stack und die nachfolgenden Data Science-Vorgänge zu installieren.
Stellen Sie sicher, dass der Benutzer, der den Resource Manager-Stack für Data Science bereitstellt, Administratorberechtigungen im Mandanten hat.
Schritt 2: Resource Manager-Stack für Data Science bereitstellen
Tipp:
In diesem Tutorial erfahren Sie, wie Sie eine Vorlage für den Data Science-Stack über die Oracle Cloud Infrastructure-Konsole abrufen. Alternativ können Sie eine ZIP-Datei herunterladen, die den Resource Manager-Stack für Data Science enthält, von der Website GitHub (https://github.com/oracle-quickstart/oci-ods-orm). Verwenden Sie in diesem Fall die Konfigurationsoption "Meine" auf der Seite "Stack erstellen".So rufen Sie den Resource Manager-Stack für Data Science ab:
- Klicken Sie auf der Homepage der Oracle Cloud Infrastructure-Konsole auf das Menüsymbol (
 ), und wählen Sie Entwicklerservices, Stacks unter "Resource Manager" aus.
), und wählen Sie Entwicklerservices, Stacks unter "Resource Manager" aus. - Klicken Sie auf Stack erstellen.
- Wählen Sie die Option Vorlage aus.
- Klicken Sie unter "Stackkonfiguration" auf Vorlage auswählen.
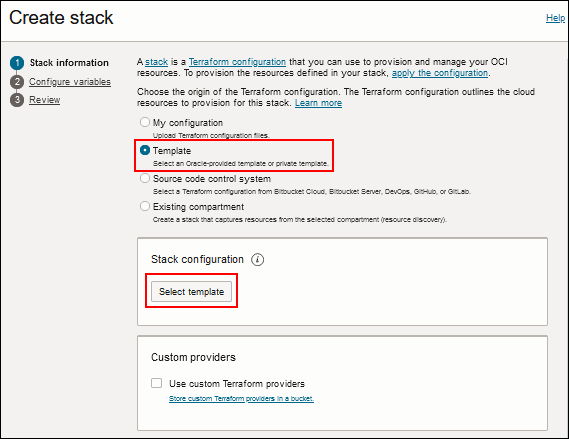
Beschreibung dieser Abbildung (datasci_stack_info_select_template.png) - Wählen Sie auf der Seite "Vorlagen durchsuchen" die Option "Service".
- Aktivieren Sie das Kontrollkästchen für Data Science, und klicken Sie auf Vorlage auswählen.
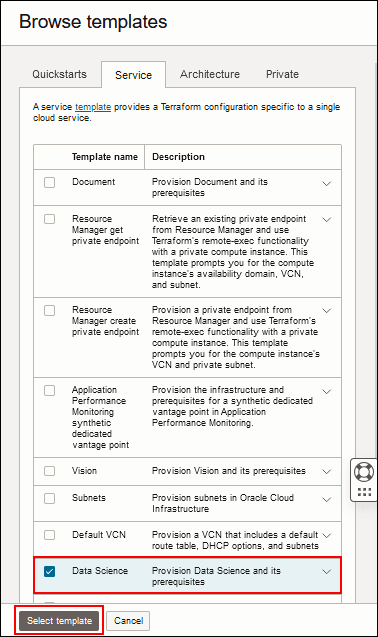
Beschreibung dieser Abbildung (browse_templates_select_datasci.png) - Geben Sie einen Namen und eine Beschreibung für den Stack ein, oder übernehmen Sie die Standardwerte.
- Wählen Sie ein Compartment aus, um den Data Science-Stack zu erstellen.
- Geben Sie bei Bedarf Tags ein.
- Klicken Sie auf Weiter
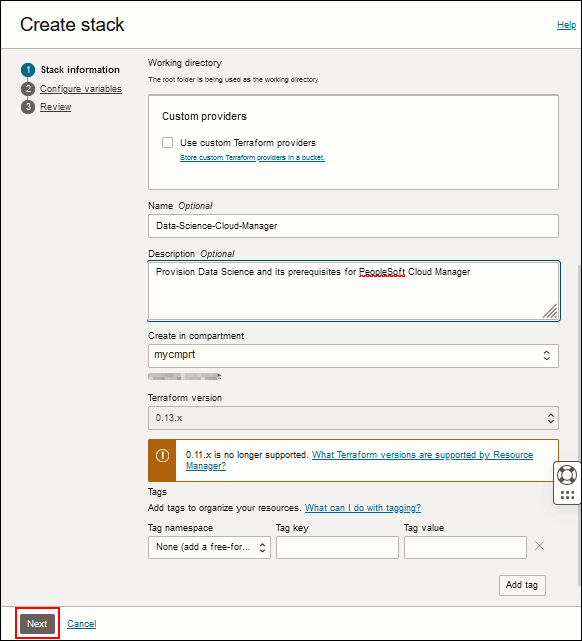
Beschreibung dieser Abbildung (datasci_stack_info_page_next.png)
Schritt 3: Data Science-Stack konfigurieren
- Übernehmen Sie die Standardnamen für die IAM-Gruppen- und Policy-Konfigurationsvariablen, oder geben Sie neue Namen ein. Verwenden Sie keine Leerzeichen.
Die Werte werden automatisch aus der Vorlage übernommen.
- Gruppenname für Sicherheits-Policys
- Name der dynamischen Gruppe für Data Science-Ressourcen
- Policy-Name (Compartment-Level)
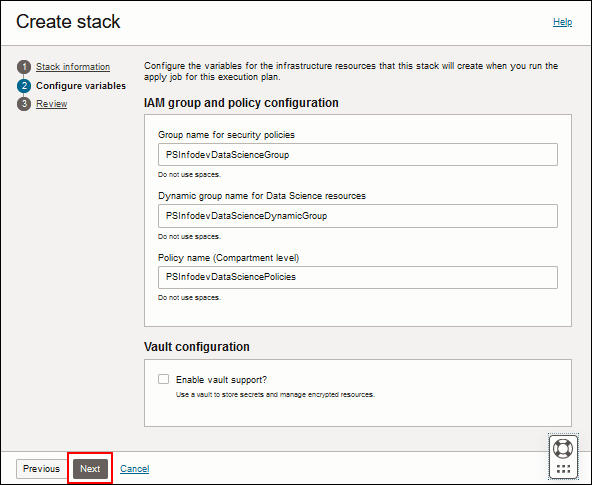
Beschreibung dieser Abbildung (datasci_stack_conf_vars.png) - Klicken Sie anschließend auf Weiter.
- Prüfen Sie die Details, und deaktivieren Sie die Option Apply ausführen.
- Klicken Sie auf Erstellen. Sie gelangen zur Seite mit den Stackdetails.
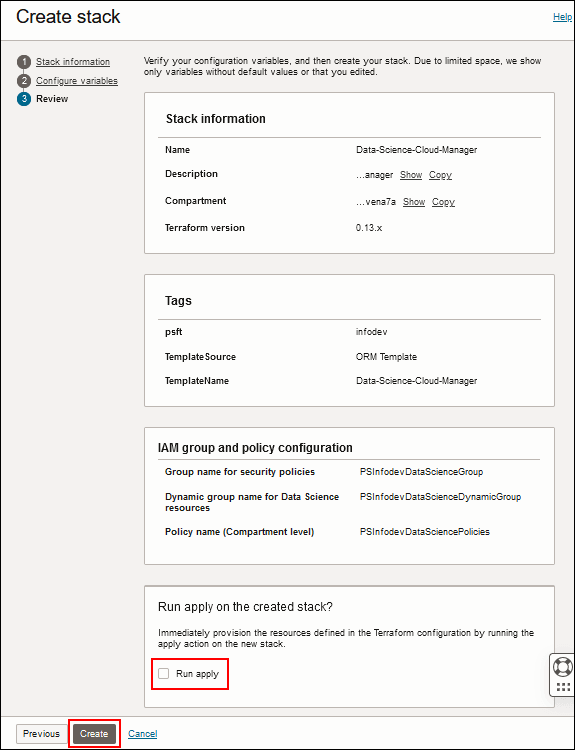
Beschreibung dieser Abbildung (datasci_stack_review.png)
Schritt 4: Resource Manager-Plan ausführen und Jobs für den Stack anwenden
Führen Sie den Job "Ressourcenmanagerplan" aus, um die Ressourcen zu prüfen, die vom Stack erstellt werden, und führen Sie dann den Job "Anwenden" aus.
- Klicken Sie auf der Seite mit den Stackdetails auf Planen.
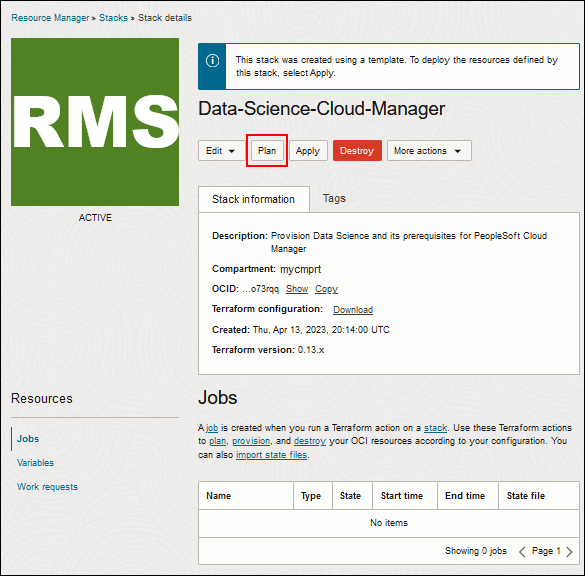
Beschreibung dieser Abbildung (run_plan_job.png) - Übernehmen Sie den Standardnamen für den Plan, und klicken Sie auf Planen.
- Wenn der Status in "Erfolgreich" geändert wird, werden die Joblogs angezeigt. Prüfen Sie die Logs für den Apply-Job, in denen die Ressourcen aufgeführt werden, einschließlich Gruppen, Benutzer und Policys, die erstellt werden.
Weitere Informationen finden Sie in diesem Tutorial im Abschnitt Ressourcen, die vom Resource Manager-Stack für Data Science erstellt wurden.
- Wählen Sie oben auf der Seite in der Navigation die Option {\b Stack Details}. Klicken Sie auf der Seite mit den Stackdetails auf Anwenden.
- Übernehmen Sie den Standardnamen und die Option "Automatisch genehmigen". Klicken Sie auf Apply.

Beschreibung dieser Abbildung (run_apply_job.png) -
Die Seite mit den Jobdetails für den Job "Anwenden" wird angezeigt. Warten Sie, bis der Auftrag abgeschlossen wurde.
Schritt 5: Benutzer zu Gruppe hinzufügen
Der Benutzer, der der Gruppe hinzugefügt wird, die vom Data Science-Stack erstellt wurde, muss über die im Tutorial "Cloud Manager-Benutzer, -Rollen und -Berechtigungslisten verwalten" aufgeführten Berechtigungen verfügen.
- Wählen Sie auf der Seite mit den Jobdetails für den Apply-Job aus den Links auf der linken Seite die Option Jobressourcen aus.
- Wählen Sie das Aktionsmenü für die Data Science-Gruppe, in diesem Beispiel PSInfodevDataScienceGroup, und wählen Sie Ressource anzeigen aus.
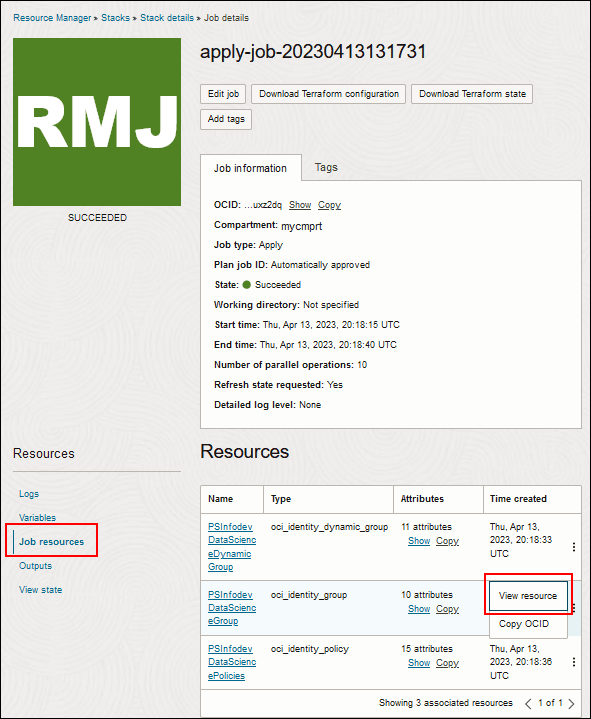
Beschreibung dieser Abbildung (job_resources_view_res.png) - Klicken Sie auf die Seite "Gruppendetails" auf Benutzer zu Gruppe hinzufügen.
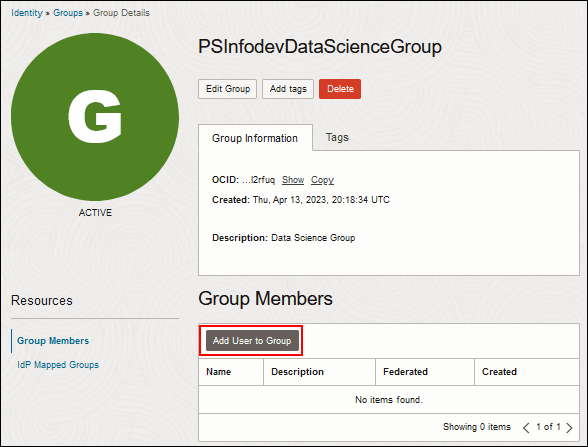
Beschreibung dieser Abbildung (grp_details_add_user.png) - Wählen Sie den Cloud Manager-Benutzer mit den entsprechenden Berechtigungen aus, und klicken Sie auf Hinzufügen.
Beschreibung dieser Abbildung (add_user_to_group.png)
Schritt 6: Objektspeicher-Bucket hinzufügen
Für das Autoscaling-Feature von Cloud Manager ist ein Objektspeicher-Bucket für den Datenupload und das Modelltraining erforderlich.
- Klicken Sie auf der Homepage der Oracle Cloud Infrastructure-Konsole auf das Menüsymbol, und wählen Sie unter "Object Storage" und "Archivspeicher" die Option Speicher und dann Buckets aus.
- Wählen Sie das Compartment aus, in dem Sie den Data Science-Stack bereitgestellt haben, und klicken Sie auf Bucket erstellen.
- Geben Sie einen Namen ein, z.B. TRAINING_DATA. Notieren Sie sich den Namen für die Verwendung in Cloud Manager.
- Übernehmen Sie die Standardoptionen, und klicken Sie auf Erstellen.

Beschreibung dieser Abbildung (create_bucket_page.png)
Schritt 7: Data Science-Einstellungen in Cloud Manager konfigurieren
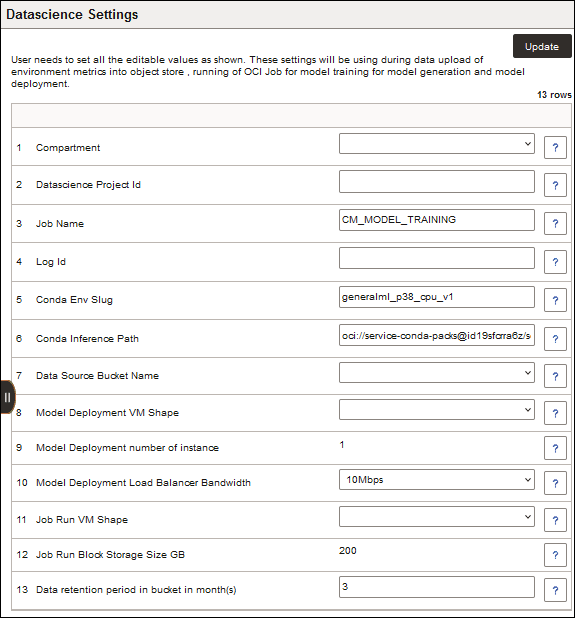
Melden Sie sich bei Cloud Manager an, um die Seite "Datascience-Einstellungen" zu konfigurieren.
Siehe Abschnitt "Data Science-Einstellungen" in PeopleSoft Cloud Manager. Wählen Sie die Seite PeopleSoft Cloud Manager im Oracle Help Center aus.
Ressourcen, die vom Resource Manager-Stack für Data Science erstellt wurden
| Typ | Beschreibung |
|---|---|
| oci_identity_group | IAM-Gruppe für Benutzer (d.h. Cloud Manager-Benutzer) |
| oci_identity_policy | IAM-Policy-Regeln zum Erteilen von Berechtigungen für DataScienceGroup und DataScienceDynamicGroup |
| oci_identity_policy | IAM-Policy-Regeln auf Mandantenebene |
| oci_identity_dynamic_group | Dynamische IAM-Gruppe für Data Science-Service-Principals |
Weitere Informationen
- PeopleSoft Cloud Manager-Homepage, My Oracle Support, Dokument-ID 2231255.2
- Tool für den Überblick über kumulative Features (Klicken Sie auf "Generate a CFO report", und wählen Sie oben PeopleSoft Cloud Manager aus.)
- Oracle Cloud-Dokumentation im Oracle Help Center
Data Science-Ressourcen für Autoscaling in PeopleSoft Cloud Manager erstellen (optional)
G41721-01
August 2025
Copyright © 2025, Oracle und/oder verbundene Unternehmen.
Verwenden Sie den Resource Manager-Stack, um Data Science-Ressourcen für Autoscaling in PeopleSoft Cloud Manager zu erstellen.
Diese Software und zugehörige Dokumentation werden im Rahmen eines Lizenzvertrages zur Verfügung gestellt, der Einschränkungen hinsichtlich Nutzung und Offenlegung enthält und durch Gesetze zum Schutz geistigen Eigentums geschützt ist. Das Verwenden, Kopieren, Vervielfältigen, Übersetzen, Übertragen, Ändern, Lizenzieren, Übermitteln, Verteilen, Ausstellen, Ausführen, Veröffentlichen oder Anzeigen dieser Software oder von Teilen daraus ist ausschließlich zu den in Ihrer Lizenzvereinbarung bzw. per Gesetz ausdrücklich erlaubten Zwecken zugelassen. Reverse Engineering, Disassemblierung oder Dekompilierung der Software ist verboten, es sei denn, dies ist erforderlich, um die gesetzlich vorgesehene Interoperabilität mit anderer Software zu ermöglichen.
Handelt es sich hier um Software oder zugehörige Dokumentation, die an die Regierung der Vereinigten Staaten von Amerika oder an einen in ihrem Auftrag handelnden Lizenznehmer geliefert wird, dann gilt der folgende Hinweis:
U.S. GOVERNMENT END USERS: Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs) and Oracle computer documentation or other Oracle data delivered to or accessed by U.S. Government end users are "commercial computer software" or "commercial computer software documentation" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, the use, reproduction, duplication, release, display, disclosure, modification, preparation of derivative works, and/or adaptation of i) Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs), ii) Oracle computer documentation and/or iii) other Oracle data, is subject to the rights and limitations specified in the license contained in the applicable contract. The terms governing the U.S. Government's use of Oracle cloud services are defined by the applicable contract for such services. No other rights are granted to the U.S. Government.
Diese Software oder Hardware ist für die allgemeine Nutzung in diversen Informationsmanagementanwendungen entwickelt worden. Sie ist nicht für den Einsatz in schon an sich gefährlichen Anwendungen entwickelt oder intendiert, einschließlich von Anwendungen, die möglicherweise ein Risiko von Personenschäden mit sich bringen. Falls die Software oder Hardware für solche Zwecke verwendet wird, verpflichtet sich der Lizenznehmer, sämtliche erforderlichen Maßnahmen wie Fail Safe, Backups und Redundancy zu ergreifen, um den sicheren Einsatz zu gewährleisten. Die Oracle Corporation und ihre verbundenen Unternehmen schließen jegliche Haftung für Schäden aus, die durch den Einsatz dieser Software oder Hardware in gefährlichen Anwendungen verursacht werden.
Oracle und Java sind eingetragene Marken der Oracle Corporation und/oder ihrer verbundenen Unternehmen. Andere Namen und Bezeichnungen können Marken ihrer jeweiligen Inhaber sein.
Intel und Intel Inside sind Marken oder eingetragene Marken der Intel Corporation. Alle SPARC-Marken werden in Lizenz verwendet und sind Marken oder eingetragene Marken der SPARC International, Inc. AMD, Epyc und das AMD-Logo sind Marken oder eingetragene Marken von Advanced Micro Devices. UNIX ist eine eingetragene Marke von The Open Group.
Diese Software oder Hardware und die Dokumentation können Zugriffsmöglichkeiten auf oder Informationen über Inhalte, Produkte und Serviceleistungen von Dritten enthalten. . Sofern nicht anderweitig in einem einschlägigen Vertrag zwischen Ihnen und Oracle vereinbart, übernehmen die Oracle Corporation und ihre verbundenen Unternehmen keine Verantwortung für Inhalte, Produkte und Serviceleistungen von Dritten und lehnen ausdrücklich jegliche Art von Gewährleistung diesbezüglich ab. Sofern nicht anderweitig in einem einschlägigen Vertrag zwischen Ihnen und Oracle vereinbart, übernehmen die Oracle Corporation und ihre verbundenen Unternehmen keine Verantwortung für Verluste, Kosten oder Schäden, die aufgrund des Zugriffs auf oder der Verwendung von Inhalten, Produkten und Serviceleistungen von Dritten entstehen.