Externe Daten mit Data Catalog abfragen
Oracle Cloud Infrastructure Data Catalog ist der Metadatenverwaltungsservice für Oracle Cloud, mit dem Sie Daten ermitteln und Data Governance unterstützen können. Es bietet eine Bestandsaufnahme von Assets, ein Geschäftsglossar und einen gemeinsamen Metastore für Data Lakes.
Autonomous AI Database kann diese Metadaten nutzen, um das Management für den Zugriff auf den Objektspeicher Ihres Data Lakes erheblich zu vereinfachen. Anstatt externe Tabellen für den Zugriff auf den Data Lake manuell zu definieren, verwenden Sie die externen Tabellen, die automatisch definiert und verwaltet werden. Diese Tabellen werden in geschützten Schemas der autonomen KI-Datenbank gefunden, die mit Änderungen im Datenkatalog auf dem neuesten Stand gehalten werden.
Informationen zum Abfragen mit Data Catalog
Durch die Synchronisierung mit Data Catalog-Metadaten erstellt Autonomous AI Database automatisch externe Tabellen für jede logische Entity, die von Data Catalog erfasst wird. Diese externen Tabellen werden in Datenbankschemas definiert, die vollständig vom Metadatensynchronisierungsprozess verwaltet werden. Benutzer können Daten sofort abfragen, ohne das Schema (Spalten und Datentypen) für externe Datenquellen manuell ableiten und externe Tabellen manuell erstellen zu müssen.
Die Synchronisierung ist dynamisch und hält die autonome KI-Datenbank in Bezug auf Änderungen an den zugrunde liegenden Daten auf dem neuesten Stand. Dadurch werden die Administrationskosten gesenkt, da sie automatisch Hunderte bis Tausende von Tabellen verwaltet. Darüber hinaus können mehrere autonome KI-Datenbankinstanzen denselben Datenkatalog verwenden, wodurch die Verwaltungskosten weiter gesenkt und ein gemeinsames Set von Geschäftsdefinitionen bereitgestellt werden.
Die Data Catalog-Ordner/-Buckets sind Container, die mit Autonomous Database-Schemas synchronisiert werden. Logische Entitys innerhalb dieser Ordner/Buckets werden externen Autonomous Database-Tabellen zugeordnet. Diese Schemas und externen Tabellen werden automatisch über den Synchronisierungsprozess generiert und verwaltet:
-
Ordner/Buckets werden Datenbankschemas zugeordnet, die nur zu organisatorischen Zwecken dienen.
-
Die Organisation soll mit dem Data Lake konsistent sein und Verwirrung beim Zugriff auf Daten über verschiedene Pfade minimieren.
-
Data Catalog ist die Quelle der Wahrheit für die Tabellen, die in Schemas enthalten sind. Im Data Catalog vorgenommene Änderungen aktualisieren die Tabellen des Schemas bei einer nachfolgenden Synchronisierung.
Um diese Funktion zu verwenden, initiiert ein Database Data Catalog-Administrator eine Verbindung zu einer Data Catalog-Instanz, wählt aus, welche Datenassets und logischen Entitys synchronisiert werden sollen, und führt die Synchronisierung aus. Der Synchronisierungsprozess erstellt Schemas und externe Tabellen basierend auf den ausgewählten Datenassets und logischen Entitys für das Harvesting in Data Catalog. Sobald die externen Tabellen erstellt sind, können Data Analysts mit der Abfrage ihrer Daten beginnen, ohne das Schema für externe Datenquellen manuell ableiten und externe Tabellen erstellen zu müssen.
Hinweis: Das DBMS_DCAT-Package ist für die Ausführung der Aufgaben verfügbar, die zum Abfragen von Datenassets für den Data Catalog-Objektspeicher erforderlich sind. Siehe DBMS_DCAT-Package.
Konzepte für die Abfrage mit Data Catalog
Die folgenden Konzepte sind für Abfragen mit Data Catalog erforderlich.
Datenkatalog: Data Catalog sammelt Datenassets, die auf die Objektspeicherdatenquellen verweisen, die Sie mit der autonomen KI-Datenbank abfragen möchten. In Data Catalog können Sie angeben, wie die Daten beim Harvesting organisiert werden, wobei verschiedene Dateiorganisationsmuster unterstützt werden. Im Rahmen des Data Catalog-Harvesting-Prozesses können Sie die Buckets und Dateien auswählen, die Sie im Asset verwalten möchten. Weitere Informationen finden Sie unter Data Catalog - Überblick.
Objektspeicher: Objektspeicher haben Buckets, die eine Vielzahl von Objekten enthalten. Einige gängige Objekttypen in diesen Buckets sind: CSV-, Parkett-, Avro-, Json- und ORC-Dateien. Buckets haben in der Regel eine Struktur oder ein Entwurfsmuster für die darin enthaltenen Objekte. Es gibt viele verschiedene Möglichkeiten, Daten zu strukturieren, und viele verschiedene Möglichkeiten, diese Muster zu interpretieren.
Beispiel: Ein typisches Entwurfsmuster verwendet Ordner der obersten Ebene, die Tabellen darstellen. Dateien in einem bestimmten Ordner verwenden dasselbe Schema und enthalten Daten für diese Tabelle. Unterordner werden häufig zur Darstellung von Tabellenpartitionen verwendet (z.B. ein Unterordner für jeden Tag). Data Catalog bezieht sich auf jeden Ordner der obersten Ebene als logische Entity, und diese logische Entity wird einer externen Tabelle der autonomen KI-Datenbank zugeordnet.
Verbindung: Eine Verbindung ist eine autonome AI-Datenbankverbindung zu einer Data Catalog-Instanz. Für jede autonome AI-Datenbankinstanz können Verbindungen zu mehreren Data Catalog-Instanzen vorhanden sein. Die Zugangsdaten der autonomen KI-Datenbank müssen über Berechtigungen für den Zugriff auf Datenkatalogassets verfügen, für die ein Harvesting aus dem Objektspeicher ausgeführt wurde.
Harvesting: Ein Data Catalog-Prozess, der den Objektspeicher scannt und die logischen Entitys aus Ihren Datasets generiert.
Datenasset: Ein Datenasset in Data Catalog stellt eine Datenquelle dar, die Datenbanken, Oracle Object Storage, Kafka und mehr umfasst. Autonomous AI Database nutzt Oracle Object Storage-Assets für die Metadatensynchronisierung.
Datenentity: Eine Datenentity in Data Catalog ist eine Sammlung von Daten, wie eine Datenbanktabe oder -View oder eine einzelne Datei. Sie enthält normalerweise viele Attribute, die ihre Daten beschreiben.
Logische Entity: In Data Lakes umfassen zahlreiche Dateien in der Regel eine einzelne logische Entity. Beispiel: Sie haben tägliche Clickstream-Dateien, und diese Dateien verwenden dasselbe Schema und denselben Dateityp.
Eine logische Data Catalog-Entity ist eine Gruppe von Object Storage-Dateien, die beim Harvesting abgeleitet werden, indem Dateinamensmuster angewendet werden, die erstellt und einem Datenasset zugewiesen wurden.
Datenobjekt: Ein Datenobjekt im Datenkatalog bezieht sich auf Datenassets oder Datenentitys.
Dateinamensmuster: In einem Data Lake können Daten auf unterschiedliche Weise organisiert werden. Normalerweise erfassen Ordner Dateien mit demselben Schema und Typ. Sie müssen sich beim Data Catalog registrieren, wie Ihre Daten organisiert sind. Dateinamensmuster werden verwendet, um zu identifizieren, wie Ihre Daten organisiert sind. In Data Catalog können Sie Dateinamensmuster mit regulären Ausdrücken definieren. Wenn Data Catalog ein Datenasset mit einem zugewiesenen Dateinamensmuster erstellt, werden logische Entitys basierend auf dem Dateinamensmuster erstellt. Durch das Definieren und Zuweisen dieser Muster zu Datenassets können mehrere Dateien als logische Entitys basierend auf dem Dateinamensmuster gruppiert werden.
Synchronisieren (Synchronisieren): Die autonome KI-Datenbank führt Synchronisierungen mit Data Catalog aus, um ihre Datenbank automatisch in Bezug auf Änderungen an den zugrunde liegenden Daten auf dem neuesten Stand zu halten. Die Synchronisierung kann manuell oder nach einem Zeitplan ausgeführt werden.
Der Synchronisierungsprozess erstellt Schemas und externe Tabellen basierend auf den Data Catalog-Datenassets und logischen Entitys. Diese Schemas sind geschützt, d.h. ihre Metadaten werden von Data Catalog verwaltet. Wenn Sie die Metadaten ändern möchten, müssen Sie die Änderungen in Data Catalog vornehmen. Die Schemas der autonomen KI-Datenbank berücksichtigen alle Änderungen, nachdem die nächste Synchronisierung ausgeführt wurde. Weitere Details finden Sie unter Synchronisierungsmapping.
Synchronisierungszuordnung
Der Synchronisierungsprozess erstellt und aktualisiert Schemas und externe Tabellen der autonomen KI-Datenbank basierend auf Data Catalog-Datenassets, Ordnern, logischen Entitys, Attributen und relevanten benutzerdefinierten Overrides.
| Data Catalog | Autonome KI-Datenbank | Mappingbeschreibung |
|---|---|---|
| Datenasset und Ordner (Objektspeicher-Bucket) | Schemaname | Standardwerte: Standardmäßig hat der generierte Schemaname in der autonomen KI-Datenbank das folgende Format:
Anpassungen: Die Standardnamendata-asset-name und folder-name können angepasst werden, indem benutzerdefinierte Eigenschaften, Geschäftsnamen und Anzeigenamen definiert werden, um diese Standardnamen außer Kraft zu setzen.
Beispiele:
|
| Logische Entity | Externe Tabelle | Logische Entitys werden externen Tabellen zugeordnet. Wenn die logische Entity über ein partitioniertes Attribut verfügt, wird sie einer partitionierten externen Tabelle zugeordnet. Der Name der externen Tabelle wird vom Anzeigenamen oder Geschäftsnamen der entsprechenden logischen Entity abgeleitet. Wenn Beispiel: Wenn |
| Attribute der logischen Entity | Spalten für externe Tabelle | Spaltennamen: Die Spaltennamen der externen Tabelle werden aus den Attributanzeigenamen oder Geschäftsnamen der entsprechenden logischen Entity abgeleitet. Bei logischen Entitys, die aus Parquet-, Avro- und ORC-Dateien abgeleitet werden, ist der Spaltenname immer der Anzeigename des Attributs, da er den aus den Quelldateien abgeleiteten Feldnamen darstellt. Bei Attributen, die einer logischen Entity entsprechen, die aus CSV-Dateien abgeleitet wird, werden die folgenden Attributfelder in der Prioritätsreihenfolge zum Generieren des Spaltennamens verwendet:
Spaltentyp: Die benutzerdefinierte Eigenschaft Für Attribute, die einer logischen Entity entsprechen, die aus Avro-Dateien mit den Datentypen Spaltenlänge: Die benutzerdefinierte Eigenschaft Spaltengenauigkeit: Die benutzerdefinierte Eigenschaft Für Attribute, die einer logischen Entity entsprechen, die aus Avro-Dateien mit den Datentypen Spaltenmaßstab: Die benutzerdefinierte Eigenschaft |
Typischer Workflow mit Data Catalog
Es gibt einen typischen Workflow von Aktionen, die von Benutzern ausgeführt werden, die mit Data Catalog abfragen möchten.
Der Datenbankdatenkatalogadministrator erstellt eine Verbindung zwischen der autonomen KI-Datenbankinstanz und einer Datenkataloginstanz. Anschließend konfiguriert und führt er eine Synchronisierung (Synchronisierung) zwischen dem Datenkatalog und der autonomen KI-Datenbank aus. Die Synchronisierung erstellt externe Tabellen und Schemas in der Instanz der autonomen KI-Datenbank basierend auf dem synchronisierten Datenkataloginhalt.
Der Administrator der Datenbankdatenkatalogabfrage oder der Datenbankadministrator erteilt READ-Zugriff auf die generierten externen Tabellen, sodass Datenanalysten und andere Datenbankbenutzer die externen Tabellen durchsuchen und abfragen können.
In der folgenden Tabelle werden die einzelnen Aktionen ausführlich beschrieben. Eine Beschreibung der verschiedenen Benutzertypen in dieser Tabelle finden Sie unter Data Catalog-Benutzer und -Rollen.
Hinweis: Das DBMS_DCAT-Package ist für die Ausführung der Aufgaben verfügbar, die zum Abfragen von Datenassets für den Data Catalog-Objektspeicher erforderlich sind. Siehe DBMS_DCAT-Package.
| Aktion | Wer ist der Benutzer | Beschreibung |
|---|---|---|
| Policys erstellen | Datenbank-Data Catalog-Administrator | Die Zugangsdaten für den autonomen AI-Datenbankbenutzer müssen über die entsprechenden Berechtigungen zum Verwalten des Datenkatalogs und zum Lesen aus dem Objektspeicher verfügen. Weitere Informationen: Erforderliche Zugangsdaten und IAM-Policys. |
| Zugangsdaten erstellen | Datenbank-Data Catalog-Administrator | Stellen Sie sicher, dass Datenbankzugangsdaten für den Zugriff auf Data Catalog und für die Abfrage des Objektspeichers vorhanden sind. Der Benutzer ruft Weitere Informationen: Prozedur DBMS_CLOUD CREATE_CREDENTIAL. |
| Verbindungen zu Data Catalog erstellen | Datenbank-Data Catalog-Administrator | Um eine Verbindung zwischen einer autonomen KI-Datenbankinstanz und einer Data Catalog-Instanz zu initiieren, ruft der Benutzer Die Verbindung zur Data Catalog-Instanz muss Benutzerzugangsdaten mit ausreichenden Oracle Cloud Infrastructure-(OCI-)Berechtigungen verwenden. Nachdem die Verbindung hergestellt wurde, wird die Data Catalog-Instanz mit dem Namespace Weitere Informationen: Prozedur SET_DATA_CATALOG_CONN, Prozedur UNSET_DATA_CATALOG_CONN. |
| Selektive Synchronisierung erstellen | Datenbank-Data Catalog-Administrator | Erstellen Sie einen Synchronisierungsjob, indem Sie die zu synchronisierenden Data Catalog-Objekte auswählen. Der Benutzer kann:
Weitere Informationen: Siehe Prozedur CREATE_SYNC_JOB, Prozedur DROP_SYNC_JOB, Synchronisierungszuordnung |
| Mit Datenkatalog synchronisieren | Datenbank-Data Catalog-Administrator | Der Benutzer initiiert einen Synchronisierungsvorgang. Die Synchronisierung wird manuell über den Prozeduraufruf Der Synchronisierungsvorgang erstellt, ändert und löscht externe Tabellen und Schemas entsprechend dem Data Catalog-Inhalt und der Synchronisierungsauswahl. Die manuelle Konfiguration wird mit benutzerdefinierten Data Catalog-Eigenschaften angewendet. Weitere Informationen: Siehe Prozedur DBMS_DCAT RUN_SYNC, Prozedur CREATE_SYNC_JOB, Synchronisierungszuordnung |
| Synchronisierungs- und Anzeigeprotokolle überwachen | Datenbank-Data Catalog-Administrator | Der Benutzer kann den Synchronisierungsstatus anzeigen, indem er die Ansicht USER_LOAD_OPERATIONS abfragt. Nachdem der Synchronisierungsprozess abgeschlossen ist, kann der Benutzer ein Log der Synchronisierungsergebnisse anzeigen, einschließlich Details zu den Zuordnungen logischer Entitys zu externen Tabellen. |
| Berechtigungen erteilen | Database Data Catalog-Abfrageadministrator, Datenbankadministrator | Der Data Catalog-Abfrageadministrator oder Datenbankadministrator der Datenbank muss Benutzern von Datenanalysten READ für generierte externe Tabellen erteilen. Dadurch können die Datenanalysten die generierten externen Tabellen abfragen. |
| Externe Tabellen durchsuchen und abfragen | Datenanalyst | Datenanalysten können die externen Tabellen über jedes Tool oder jede Anwendung abfragen, die Oracle SQL unterstützt. Datenanalysten können die synchronisierten Schemas und Tabellen in den DCAT$\*-Schemas prüfen und die Tabellen mit Oracle SQL abfragen. Weitere Informationen: Synchronisierungszuordnung |
| Verbindungen zu Data Catalog beenden | Datenbank-Data Catalog-Administrator | Um eine vorhandene Data Catalog-Verknüpfung zu entfernen, ruft der Benutzer die Prozedur Diese Aktion wird nur ausgeführt, wenn Sie die Verwendung von Data Catalog und den externen Tabellen, die aus dem Katalog abgeleitet werden, nicht mehr planen. Mit dieser Aktion werden Datenkatalogmetadaten gelöscht und synchronisierte externe Tabellen aus der Instanz der autonomen KI-Datenbank gelöscht. Die benutzerdefinierten Eigenschaften in Data Catalog- und OCI-Policys sind nicht betroffen. Weitere Informationen: Prozedur UNSET_DATA_CATALOG_CONN |
Beispiel: MovieStream-Szenario
In diesem Szenario erfasst Moviestream Daten in einer Landing Zone im Objektspeicher. Ein Großteil dieser Daten, aber nicht unbedingt alle, wird dann für die Bereitstellung einer autonomen KI-Datenbank verwendet. Vor dem Zuführen der autonomen KI-Datenbank werden die Daten transformiert, bereinigt und anschließend im Bereich "Gold" gespeichert.
Data Catalog wird für das Harvesting dieser Quellen verwendet und stellt dann einen Geschäftskontext für die Daten bereit. Datenkatalogmetadaten werden mit der autonomen KI-Datenbank gemeinsam verwendet, sodass Benutzer der autonomen KI-Datenbank diese Datenquellen mit Oracle SQL abfragen können. Diese Daten können in die autonome KI-Datenbank geladen oder mithilfe externer Tabellen dynamisch abgefragt werden.
Weitere Informationen zur Verwendung von Data Catalog finden Sie in der Data Catalog-Dokumentation.
-
Objektspeicher - Buckets, Ordner und Dateien prüfen
-
Prüfen Sie die Buckets im Objektspeicher.
Beispiel: Im Folgenden werden die Landing-Buckets (
moviestream_landing) und die Goldzone-Buckets (moviestream_gold) im Objektspeicher aufgeführt: -
Prüfen Sie die Ordner und Dateien in den Objektspeicher-Buckets.
Beispiel: Im Folgenden werden die Ordner im Landing Bucket (
moviestream_landing) im Objektspeicher aufgeführt:
-
-
Data Catalog - Dateinamensmuster erstellen
-
Informieren Sie Data Catalog anhand von Dateinamensmustern, wie Ihre Daten organisiert sind. Dies sind reguläre Ausdrücke, mit denen Dateien kategorisiert werden. Die Dateinamensmuster werden vom Data Catalog-Harvester verwendet, um logische Entitys abzuleiten. Die folgenden beiden Dateinamensmuster werden für das Harvesting der Buckets im MovieStream-Beispiel verwendet. Weitere Informationen zum Erstellen von Dateinamensmustern finden Sie unter Harvesting von Object Storage-Dateien als logische Datenentitys ausführen.
Hive-Stil Ordnerart {bucketName:.*}/{logicalEntity:[^/]+}.db/{logicalEntity:[^/]+}/.*{bucketName:[\w]+}/{logicalEntity:[^/]+}(?<!.db)/.*$- Erstellt logische Entitys für Quellen, die ".db" als ersten Teil des Objektnamens enthalten.
- Um die Eindeutigkeit im Bucket sicherzustellen, lautet der resultierende Name (db-name).(Ordnername)
- Erstellt eine logische Entity basierend auf dem Ordnernamen außerhalb der Root
- Um eine Duplizierung mit Hive zu verhindern, werden Objektnamen übersprungen, die ".db" enthalten.
-
Um Dateinamensmuster zu erstellen, gehen Sie zur Registerkarte Dateinamensmuster für Ihren Datenkatalog, und klicken Sie auf Dateinamensmuster erstellen. Beispiel: Die Registerkarte Dateinamensmuster erstellen für den Datenkatalog
moviestreamlautet:
-
-
Datenkatalog - Datenasseterstellung
-
Erstellen Sie ein Datenasset, das für das Harvesting von Daten aus dem Objektspeicher verwendet wird.
Beispiel: Ein Datenasset mit dem Namen
phoenixObjStorewird im Datenkatalogmoviestreamerstellt: -
Fügen Sie eine Verbindung für das Datenasset hinzu.
In diesem Beispiel stellt das Datenasset eine Verbindung zum Compartment für die Objektspeicherressource
moviestreamher. -
Verknüpfen Sie jetzt Ihre Dateinamensmuster mit Ihrem Datenasset. Wählen Sie Dateinamensmuster zuweisen aus, prüfen Sie die gewünschten Muster, und klicken Sie auf Zuweisen.
Beispiel: Hier sind die dem Datenasset
phoenixObjStorezugewiesenen Muster: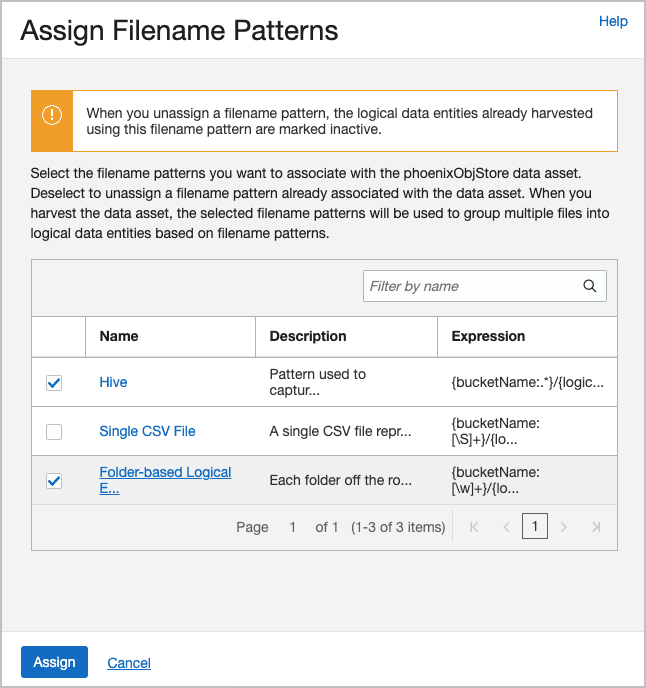
-
Datenkatalog - Harvesting für Daten aus Objektspeicher ausführen
a. Harvesting für das Datenasset des Datenkatalogs ausführen. Wählen Sie die Objektspeicher-Buckets mit den Quelldaten aus.
In diesem Beispiel sind die Buckets
moviestream_goldund `filmstream_landing` aus dem Objektspeicher für die Harvesting ausgewählt.b. Nachdem Sie den Job ausgeführt haben, werden die logischen Entitys angezeigt. Mit Datenassets durchsuchen können Sie sie prüfen.
In diesem Beispiel wird die logische Entity
customer-extensionund ihre Attribute betrachtet.Wenn Sie über ein Glossar verfügen, empfiehlt Data Catalog Kategorien und Begriffe, die mit der Entity und ihren Attributen verknüpft werden sollen. Dadurch wird ein Geschäftskontext für die Artikel bereitgestellt. Schemas, Tabellen und Spalten sind oft nicht selbsterklärend.
In unserem Beispiel möchten wir zwischen den verschiedenen Arten von Buckets und der Bedeutung ihres Inhalts unterscheiden:
-
Was ist eine Landezone?
-
Wie genau sind die Daten?
-
Wann wurde es zuletzt aktualisiert?
-
Definition einer logischen Entity oder ihres Attributs
-
-
Autonome KI-Datenbank - Mit Datenkatalog verbinden
Autonome KI-Datenbank mit Datenkatalog verbinden. Sie müssen sicherstellen, dass die für diese Verbindung verwendeten Zugangsdaten einen OCI-Principal verwenden, der für den Zugriff auf das Data Catalog-Asset autorisiert ist. Weitere Informationen finden Sie unter Data Catalog-Policys.
a. Bei Datenkatalog anmelden
BEGIN DBMS_CLOUD.CREATE_CREDENTIAL ( credential_name => 'OCI_NATIVE_CRED', user_ocid => 'ocid1.user.oc1..aaaaaaaatfn77fe3fxux3o5lego7glqjejrzjsqsrs64f4jsjrhbsk5qzndq', tenancy_ocid => 'ocid1.tenancy.oc1..aaaaaaaapwkfqz3upqklvmelbm3j77nn3y7uqmlsod75rea5zmtmbl574ve6a', private_key => 'MIIEogIBAAKCAQEA...t9SH7Zx7a5iV7QZJS5WeFLMUEv+YbYAjnXK+dOnPQtkhOblQwCEY3Hsblj7Xz7o=', fingerprint => '4f:0c:d6:b7:f2:43:3c:08:df:62:e3:b2:27:2e:3c:7a'); END; -- Variables are used to simplify usage later define oci_credential = 'OCI_NATIVE_CRED' define dcat_ocid = 'ocid1.datacatalog.oc1.iad.aaaaaaaardp66bg....twiq' define dcat_region='us-ashburn-1' define uri_root = 'https://objectstorage.us-ashburn-1.oraclecloud.com/n/mytenancy/b/landing/o' define uri_private = 'https://objectstorage.us-ashburn-1.oraclecloud.com/n/mytenancy/b/private_data/o' -- Query a private bucket to test the privileges. select * from dbms_cloud.list_objects('&oci_credential', '&uri_private/'); -------- -- Set the credentials to use for object store and data catalog -- Connect to Data Catalog -- Review connection --------- -- Set credentials exec dbms_dcat.set_data_catalog_credential(credential_name => '&oci_credential'); exec dbms_dcat.set_object_store_credential(credential_name => '&oci_credential'); -- Connect to Data Catalog begin dbms_dcat.set_data_catalog_conn ( region => '&dcat_region', catalog_id => '&dcat_ocid'); end; / -- Review the connection select * from all_dcat_connections;b. Datenkatalog mit autonomer KI-Datenbank synchronisieren. Hier werden alle Objektspeicherassets synchronisiert:
-- Sync Data Catalog with Autonomous Database ---- Let's sync all of the assets. begin dbms_dcat.run_sync('{"asset_list":["*"]}'); end; / -- View log select type, start_time, status, logfile_table from user_load_operations; -- Logfile_Table will have the name of the table containing the full log. select * from dbms_dcat$1_log; -- View the new external tables select * from dcat_entities; select * from dcat_attributes;c. Autonome KI-Datenbank - Starten Sie jetzt Abfragen für den Objektspeicher.
-- Query the Data ! select *from dcat$phoenixobjstore_moviestream_gold.genre; -
Schemas für Objekte ändern
Die Standardschemanamen sind ziemlich kompliziert. Vereinfachen wir sie, indem wir sowohl das Asset als auch das benutzerdefinierte Attribut
Oracle-Db-Schemades Ordners in Data Catalog angeben. Ändern Sie das Datenasset inPHX, und die Ordner inlandingbzw.gold. Das Schema ist eine Verkettung der beiden.a. Navigieren Sie in Data Catalog zum Bucket
moviestream_landing, und ändern Sie das Asset inlandingbzw.gold.Vor der Änderung:
Nach der Änderung:
b. Eine weitere Synchronisierung ausführen.
-
Beispiel: Partitioniertes Datenszenario
Dieses Szenario veranschaulicht, wie externe Tabellen in einer autonomen KI-Datenbank erstellt werden, die auf logischen Data Catalog-Entitys basieren, die aus partitionierten Daten im Objektspeicher gewonnen wurden.
Das folgende Beispiel basiert auf Beispiel: MovieStream-Szenario und wurde angepasst, um die Integration mit partitionierten Daten zu demonstrieren. Data Catalog wird für das Harvesting dieser Quellen verwendet und stellt dann einen Geschäftskontext für die Daten bereit. Weitere Einzelheiten zu diesem Beispiel finden Sie unter Beispiel: MovieStream-Szenario.
Weitere Informationen zur Verwendung von Data Catalog finden Sie in der Data Catalog-Dokumentation.
-
Objektspeicher - Buckets, Ordner und Dateien prüfen
-
Prüfen Sie die Buckets im Objektspeicher.
Beispiel: Im Folgenden werden die Landing-(
moviestream_landing-) und Goldzone-(moviestream_gold-)Buckets im Objektspeicher aufgeführt: -
Prüfen Sie die Ordner und Dateien in den Objektspeicher-Buckets.
Beispiel: Im Folgenden werden die Ordner im Landing Bucket (
moviestream_landing) im Objektspeicher aufgeführt:
-
-
Data Catalog - Dateinamensmuster erstellen
-
Informieren Sie Data Catalog anhand von Dateinamensmustern, wie Ihre Daten organisiert sind. Hierbei handelt es sich um Ordnerpräfixe oder reguläre Ausdrücke, mit denen Dateien kategorisiert werden. Die Dateinamensmuster werden vom Data Catalog-Harvester verwendet, um logische Entitys abzuleiten. Wenn ein Ordnerpräfix angegeben wird, generiert der Data Catalog automatisch logische Entitys aus dem angegebenen Ordnerpräfix im Objektspeicher. Das folgende Dateinamensmuster wird für das Harvesting der Buckets im MovieStream-Beispiel verwendet. Weitere Informationen zum Erstellen von Dateinamensmustern finden Sie unter Harvesting von Object Storage-Dateien als logische Datenentitys ausführen.
Ordnerpräfix Beschreibung workshop.db/Erstellt logische Entitys für Quellen, die den Pfad "workshop.db" im Objektspeicher enthalten. -
Um Dateinamensmuster zu erstellen, gehen Sie zur Registerkarte Dateinamensmuster für Ihren Datenkatalog, und klicken Sie auf Dateinamensmuster erstellen. Beispiel: Die Registerkarte Dateinamensmuster erstellen für den Datenkatalog
moviestreamlautet:
-
-
Datenkatalog - Datenasseterstellung
-
Erstellen Sie ein Datenasset, das für das Harvesting von Daten aus dem Objektspeicher verwendet wird.
Beispiel: Ein Datenasset mit dem Namen
amsterdamObjStorewird im Datenkatalogmoviestreamerstellt: -
Fügen Sie eine Verbindung für das Datenasset hinzu.
In diesem Beispiel stellt das Datenasset eine Verbindung zum Compartment für die Objektspeicherressource
moviestreamher. -
Verknüpfen Sie jetzt Ihre Dateinamensmuster mit Ihrem Datenasset. Wählen Sie Dateinamensmuster zuweisen aus, prüfen Sie die gewünschten Muster, und klicken Sie auf Zuweisen.
Beispiel: Hier sind die dem Datenasset
amsterdamObjStorezugewiesenen Muster:
-
-
Datenkatalog - Harvesting für Daten aus Objektspeicher ausführen
-
Harvesting für das Datenasset des Datenkatalogs ausführen. Wählen Sie die Objektspeicher-Buckets mit den Quelldaten aus.
In diesem Beispiel sind die Buckets
moviestream_goldund `filmstream_landing` aus dem Objektspeicher für die Harvesting ausgewählt. -
Nachdem Sie den Job ausgeführt haben, werden die logischen Entitys angezeigt. Mit Datenassets durchsuchen können Sie sie prüfen.
In diesem Beispiel wird die logische Entity
sales_sample_parquetund ihre Attribute betrachtet. Beachten Sie, dass Data Catalog das Attributmonthals partitioniert identifiziert hat.
-
-
Autonome KI-Datenbank - Mit Datenkatalog verbinden
Autonome KI-Datenbank mit Datenkatalog verbinden. Sie müssen sicherstellen, dass die für diese Verbindung verwendeten Zugangsdaten einen OCI-Principal verwenden, der für den Zugriff auf das Data Catalog-Asset autorisiert ist. Weitere Informationen finden Sie unter Data Catalog-Policys.
-
Bei Datenkatalog anmelden
BEGIN DBMS_CLOUD.CREATE_CREDENTIAL ( credential_name => 'OCI_NATIVE_CRED', user_ocid => 'ocid1.user.oc1..aaaaaaaatfn77fe3fxux3o5lego7glqjejrzjsqsrs64f4jsjrhbsk5qzndq', tenancy_ocid => 'ocid1.tenancy.oc1..aaaaaaaapwkfqz3upqklvmelbm3j77nn3y7uqmlsod75rea5zmtmbl574ve6a', private_key => 'MIIEogIBAAKCAQEA...t9SH7Zx7a5iV7QZJS5WeFLMUEv+YbYAjnXK+dOnPQtkhOblQwCEY3Hsblj7Xz7o=', fingerprint => '4f:0c:d6:b7:f2:43:3c:08:df:62:e3:b2:27:2e:3c:7a'); END; -- Variables are used to simplify usage later define oci_credential = 'OCI_NATIVE_CRED' define dcat_ocid = 'ocid1.datacatalog.oc1.eu-amsterdam-1....leguurn3dmqa' define dcat_region='eu-amsterdam-1' define uri_root = 'https://objectstorage.us-ashburn-1.oraclecloud.com/n/mytenancy/b/landing/o' define uri_private = 'https://objectstorage.us-ashburn-1.oraclecloud.com/n/mytenancy/b/private_data/o' -- Query a private bucket to test the privileges. select * from dbms_cloud.list_objects('&oci_credential', '&uri_private/'); -------- -- Set the credentials to use for object store and data catalog -- Connect to Data Catalog -- Review connection --------- -- Set credentials exec dbms_dcat.set_data_catalog_credential(credential_name => '&oci_credential'); exec dbms_dcat.set_object_store_credential(credential_name => '&oci_credential'); -- Connect to Data Catalog begin dbms_dcat.set_data_catalog_conn ( region => '&dcat_region', catalog_id => '&dcat_ocid'); end; / -- Review the connection select * from all_dcat_connections; -
Datenkatalog mit autonomer KI-Datenbank synchronisieren. Hier werden alle Objektspeicherassets synchronisiert:
-- Sync Data Catalog with Autonomous Database ---- Let's sync all of the assets. begin dbms_dcat.run_sync('{"asset_list":["*"]}'); end; / -- View log select type, start_time, status, logfile_table from user_load_operations; -- Logfile_Table will have the name of the table containing the full log. select * from dbms_dcat$1_log; -- View the new external tables select * from dcat_entities; select * from dcat_attributes; -
Autonome KI-Datenbank - Starten Sie jetzt Abfragen für den Objektspeicher.
-- Query the Data ! select count(*) from DCAT$AMSTERDAMOBJSTORE_MOVIESTREAM_LANDING.SALES_SAMPLE_PARQUET; -- Examine the generated partitioned table select dbms_metadata.get_ddl('TABLE','SALES_SAMPLE_PARQUET','DCAT$AMSTERDAMOBJSTORE_MOVIESTREAM_LANDING') from dual; CREATE TABLE "DCAT$AMSTERDAMOBJSTORE_MOVIESTREAM_LANDING"."SALES_SAMPLE_PARQUET" ( "MONTH" VARCHAR2(4000) COLLATE "USING_NLS_COMP", "DAY_ID" TIMESTAMP (6), "GENRE_ID" NUMBER(20,0), "MOVIE_ID" NUMBER(20,0), "CUST_ID" NUMBER(20,0), ... ) DEFAULT COLLATION "USING_NLS_COMP" ORGANIZATION EXTERNAL ( TYPE ORACLE_BIGDATA ACCESS PARAMETERS ( com.oracle.bigdata.fileformat=parquet com.oracle.bigdata.filename.columns=["MONTH"] com.oracle.bigdata.file_uri_list="https://swiftobjectstorage.eu-amsterdam-1.oraclecloud.com/v1/tenancy/moviestream_landing/workshop.db/sales_sample_parquet/*" ... ) ) REJECT LIMIT 0 PARTITION BY LIST ("MONTH") (PARTITION "P1" VALUES (('2019-01')) LOCATION ( 'https://swiftobjectstorage.eu-amsterdam-1.oraclecloud.com/v1/tenancy/moviestream_landing/workshop.db/sales_sample_parquet/month=2019-01/*'), PARTITION "P2" VALUES (('2019-02')) LOCATION ( 'https://swiftobjectstorage.eu-amsterdam-1.oraclecloud.com/v1/tenancy/moviestream_landing/workshop.db/sales_sample_parquet/month=2019-02/*'), ...PARTITION "P24" VALUES (('2020-12')) LOCATION ( 'https://swiftobjectstorage.eu-amsterdam-1.oraclecloud.com/v1/tenancy/moviestream_landing/workshop.db/sales_sample_parquet/month=2020-12/*')) PARALLEL
-
-
Schemas für Objekte ändern
Die Standardschemanamen sind ziemlich kompliziert. Vereinfachen wir sie, indem wir sowohl das Asset als auch das benutzerdefinierte Attribut
Oracle-Db-Schemades Ordners in Data Catalog angeben. Ändern Sie das Datenasset inPHX, und die Ordner inlandingbzw.gold. Das Schema ist eine Verkettung der beiden.-
Navigieren Sie in Data Catalog zum Bucket
moviestream_landing, und ändern Sie das Asset inlandingbzw.gold.Vor der Änderung:
Nach der Änderung:
-
Eine weitere Synchronisierung ausführen.
-