Oracle NoSQL Database Cloud Service überwachen
Mit Oracle Cloud Infrastructure Monitoring können Sie Ihre Cloud-Ressourcen mit den Features "Metriken" und "Alarme" aktiv und passiv überwachen. Der Monitoring-Service verwendet Metriken, um Ressourcen und Alarme zu überwachen, um Sie zu benachrichtigen, wenn diese Metriken alarmspezifizierte Trigger erfüllen.
Eine Metrik ist eine Messung, die sich auf den Zustand, die Kapazität oder die Performance einer bestimmten Ressource bezieht. Ein Alarm ist eine Triggerregel und Abfrage. Alarme überwachen Ihre Cloud-Ressourcen passiv mittels Metriken. Sie können Benachrichtigungseinstellungen beim Erstellen eines Alarms konfigurieren.
Metriken werden an den Monitoring-Service als Raw-Datenpunkte (ein Zeitstempel/Wert-Paar für eine angegebene Metrik) und Dimensionen (eine in der Metrikdefinition angegebene Ressourcen-ID) und Metadaten ausgegeben. Der Monitoring-Service veröffentlicht Alarmmeldungen für konfigurierte Ziele, die vom Notifications-Service verwaltet werden.
Wenn Sie eine Metrik abfragen, gibt der Monitoring-Service aggregierte Daten entsprechend den angegebenen Parametern zurück. Sie können einen Bereich (z.B. die letzten 24 Stunden), eine Statistik und ein Intervall angeben. Eine Statistik ist die Aggregationsfunktion, die auf die Rohdatenpunkte angewendet wird. Die SUM-Aggregationsfunktion ist ein Beispiel für eine Statistik. Das Zeitfenster, in dem eine angegebene Gruppe von Rohdatenpunkten konvertiert wird, ist ein Intervall. Beispiel: 5 Minuten.
In der Konsole wird ein Monitoringdiagramm pro Metrik für ausgewählte Ressourcen angezeigt. Die aggregierten Daten in jedem Diagramm entsprechen der ausgewählten Statistik und dem ausgewählten Intervall. API-Anforderungen können optional nach Dimension filtern und eine Auflösung angeben. API-Antworten umfassen den Metriknamen zusammen mit seinem Quell-Compartment und Metrik-Namespace (gibt die Ressource, den Service oder die Anwendung an, die eine Metrik ausgibt). Der Namespace wird in der Metrikdefinition angegeben. Beispiel: Die von Oracle Cloud ausgegebene CpuUtilization-Metrikdefinition listet den Metrik-Namespace oci_computeagent als Quelle der Metrikauf.
Metrik- und Alarmdaten sind über die Konsole, die CLI und die API zugänglich. Weitere Informationen zu OCI-Monitoring-Servicekonzepten finden Sie unter Monitoringkonzepte.
Dieser Artikel enthält die folgenden Themen:
Oracle NoSQL Database Cloud-Servicemetriken
Oracle NoSQL Database Cloud Service gibt Metriken mit dem Metrik-Namespace oci_nosql aus.
Metriken für Oracle NoSQL Database Cloud Service umfassen die folgenden Dimensionen:
RESOURCEIDDie OCID der NoSQL-Tabelle in Oracle NoSQL Database Cloud Service.
Hinweis: Die OCID ist eine von Oracle zugewiesene eindeutige ID, die sowohl in die Konsole als auch in die API im Rahmen der Ressourceninformationen enthalten ist.
-
TABLENAMEDer Name der NoSQL-Tabelle in Oracle NoSQL Database Cloud Service.
-
REPLICADer Name des Bereichs, der die Tabellenaktualisierung von einer anderen Region empfängt.
Oracle NoSQL Database Cloud Service sendet Metriken an den Oracle Cloud Infrastructure Monitoring-Service. Sie können Alarme für diese Metriken mit den SDKs oder CLI der Oracle Cloud Infrastructure-Konsole anzeigen oder erstellen.
Tabelle - Oracle NoSQL Database Cloud Service-Metriken
| Metrik | Metrikanzeigename | Einheit | Beschreibung | Dimensionen |
|---|---|---|---|---|
ReadUnits |
Leseeinheiten | Units | Die Anzahl der in diesem Zeitraum konsumierten Leseeinheiten. | resourceId tableName |
WriteUnits |
Schreibeinheiten | Units | Die Anzahl der in diesem Zeitraum konsumierten Schreibeinheiten. | resourceId tableName |
StorageGB |
Speichergröße | GB | Die maximale von der Tabelle belegte Speichermenge. Da diese Informationen stündlich generiert werden, werden zwischen den Aktualisierungspunkten möglicherweise Werte angezeigt, die veraltet sind. | resourceId tableName |
ReadThrottleCount |
Lese-Throttle | Anzahl | Die Anzahl der Throttle-Ausnahmen beim Lesen für diese Tabelle in diesem Zeitraum. | resourceId tableName |
WriteThrottleCount |
Schreib-Throttle | Anzahl | Die Anzahl der Throttle-Ausnahmen beim Schreiben für diese Tabelle in diesem Zeitraum. | resourceId tableName |
StorageThrottleCount |
Speicher-Throttle | Anzahl | Die Anzahl der Throttle-Ausnahmen beim Speichern für diese Tabelle in diesem Zeitraum. | resourceId tableName |
MaxShardSizeUsagePercent |
Maximale Shard-Größennutzung | Prozentsatz | Das Verhältnis des im Shard belegten Speicherplatzes zu dem Gesamtplatz, der dem Shard zugewiesen ist. Dies ist spezifisch für eine Tabelle und der höchste Wert für alle Shards. | resourceId tableName |
Replica Lag |
Replikatverzögerung | Millisekunde | Eine Zeitverzögerung beim Replizieren der Datenänderungen einer globalen aktiven Tabelle von einer Absenderregion in eine Empfängerregion. | |
Darüber hinaus können Sie benutzerdefinierte Metriken gemäß Ihren Anforderungen veröffentlichen. Beispiel: Sie können Metriken einrichten, um die Anwendungstransaktionslatenz (Zeitaufwand pro abgeschlossener Transaktion) zu erfassen und diese Daten dann im Monitoring-Service zu buchen.
Erläuterungen zu NDCS-Metriken
Oracle NoSQL Database Cloud Service sendet Metriken an den Oracle Cloud Infrastructure Monitoring-Service.
Leseeinheiten:
Die Anzahl der in diesem Zeitraum konsumierten Leseeinheiten. Dies ist der Durchsatz von bis zu 1 KB Daten pro Sekunde für einen Lesevorgang mit Eventual Consistency. Wenn Ihre Daten größer als 1 KB sind, werden mehrere Leseeinheiten benötigt, um sie zu lesen. Das Metrikdiagramm "Leseeinheit" für eine Tabelle wird unten angezeigt. Die Metrik wird jede Minute verwendet, und die Metrikdiagramme werden standardmäßig für ein Intervall von 5 Minuten dargestellt.
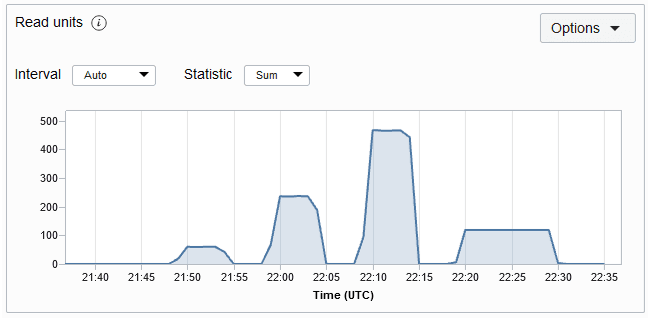
Beschreibung der Abbildung readmetric.png
Schreibeinheiten:
Die Anzahl der in diesem Zeitraum konsumierten Schreibeinheiten. Dies ist der Durchsatz für bis zu 1 KB Daten pro Sekunde für einen Schreibvorgang. Schreibvorgänge werden bei Einfüge-, Aktualisierungs- und Löschvorgängen ausgelöst. Wenn Ihre Daten größer als 1 KB sind, müssen mehrere Leseeinheiten geschrieben werden. Das Metrikdiagramm "Schreibeinheit" für eine Tabelle wird unten angezeigt. Die Metrik wird jede Minute verwendet, und die Metrikdiagramme werden standardmäßig für ein Intervall von 5 Minuten dargestellt.
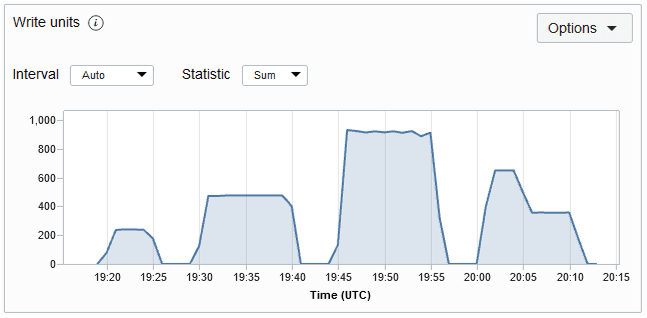
Beschreibung der Abbildung writemetric.png
SpeicherGB:
Die maximale von der Tabelle belegte Speichermenge. Das Metrikdiagramm "Speicher" für eine Tabelle wird unten angezeigt. Die Metrik wird jede Minute verwendet, und die Metrikdiagramme werden standardmäßig für ein Intervall von 5 Minuten dargestellt.
Hinweis: Nach der Tabellenerstellung dauert es eine Stunde, bis der Beginn der Verfolgung der Speichergröße vordefiniert ist. Nach der ersten Stunde werden die Speicherstatistiken alle 5 Minuten aktualisiert.
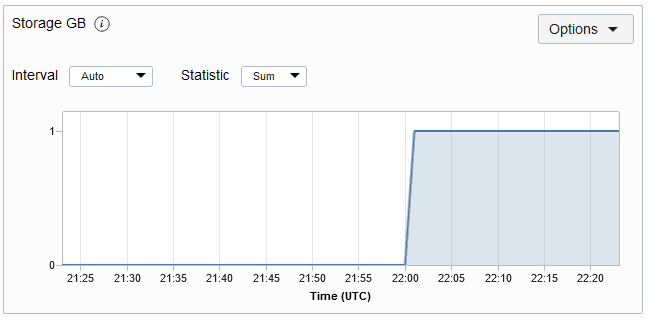
Beschreibung der Abbildung storagemetric.png
Hinweis: Die Speicher-GB-Metrik wird abgeschnitten. Daher wird die Speicherauslastung von weniger als 1 GB als 0 angezeigt. Das Diagramm zeigt den Speicher an, wenn die Nutzung größer als 1 GB ist.
ReadThrottleCount:
Dadurch wird die Anzahl der Lese-Throttling-Ausnahmen für die angegebene Tabelle im Zeitraum gezählt. Eine Throttling-Ausnahme gibt in der Regel an, dass der bereitgestellte Lesedurchsatz überschritten wurde. Wenn Sie diese häufig erhalten, sollten Sie erwägen, die Leseeinheiten auf Ihrem Tisch zu erhöhen. Das Metrikdiagramm "Lese-Throttle-Anzahl" für eine Tabelle wird unten angezeigt. Die Metrik wird jede Minute verwendet, und die Metrikdiagramme werden standardmäßig für ein Intervall von 5 Minuten dargestellt.
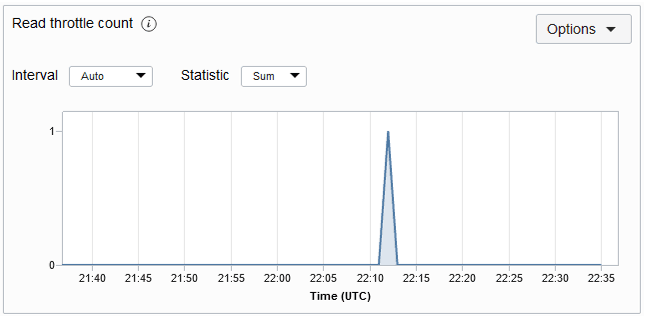
Beschreibung der Abbildung readthrottlemetric.png
WriteThrottleCount:
Dadurch wird die Anzahl der Schreib-Throttling-Ausnahmen für die angegebene Tabelle im Zeitraum gezählt. Eine Throttling-Ausnahme gibt in der Regel an, dass der bereitgestellte Schreibdurchsatz überschritten wurde. Wenn Sie diese häufig erhalten, sollten Sie erwägen, die Schreibeinheiten auf Ihrer Tabelle zu erhöhen. Das Metrikdiagramm "Schreib-Throttle-Anzahl" für eine Tabelle wird unten angezeigt. Die Metrik wird jede Minute verwendet, und die Metrikdiagramme werden standardmäßig für ein Intervall von 5 Minuten dargestellt.
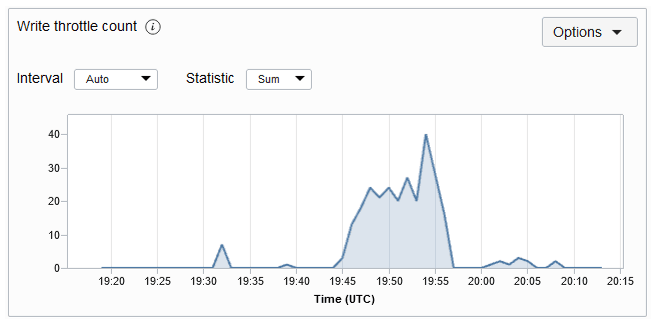
Beschreibung der Abbildung writethrottlemetric.png
StorageThrottleCount:
Dadurch wird die Anzahl der Speicher-Throttling-Ausnahmen für die angegebene Tabelle im Zeitraum gezählt. Eine Throttling-Ausnahme gibt in der Regel an, dass die bereitgestellte Speicherkapazität überschritten wurde. Wenn Sie diese häufig erhalten, sollten Sie erwägen, die Speicherkapazität Ihrer Tabelle zu erhöhen. Das Metrikdiagramm für die Speicher-Throttle-Anzahl für eine Tabelle wird unten angezeigt. Die Metrik wird jede Minute verwendet, und die Metrikdiagramme werden standardmäßig für ein Intervall von 5 Minuten dargestellt.
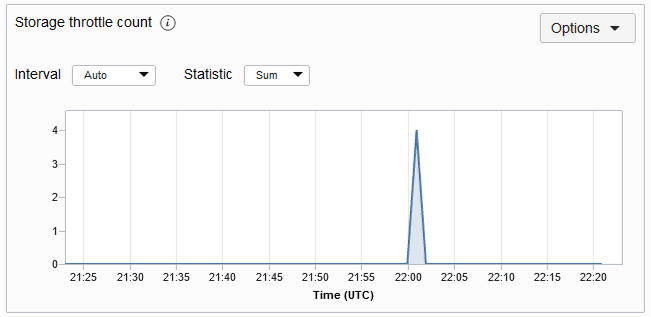
Beschreibung der Abbildung storagethrottlemetric.png
MaxShardSizeUsagePercent
Die höchste Speicherplatzbelegung in einem Shard für eine bestimmte Tabelle als Prozentsatz des Speicherplatzes, der in diesem Shard belegt wird.
Hinweis: Oracle NoSQL Database Cloud Service hasht Schlüssel in Shards, um die Verteilung über eine Sammlung von Speicherknoten bereitzustellen, die Speicher für die Tabellen bereitstellen. Oracle NoSQL Database Cloud Service-Tabellen werden zwar nicht direkt für Sie sichtbar, aber zwecks Verfügbarkeit und Performance in Shards aufgeteilt und repliziert. Ein Shard-Schlüssel entspricht entweder zu 100% dem Primärschlüssel oder ist eine Teilmenge des Primärschlüssels. Alle Datensätze, die einen Shard-Schlüssel gemeinsam verwenden, werden gemeinsam gespeichert, um die Datenlokalität zu erreichen.
Wenn maxShardSizeUsagepercent den Wert 100 erreicht, können Sie keinen Schreibvorgang mehr in der Tabelle ausführen. Sie müssen die Speicherkapazität erhöhen, um einen Schreibvorgang in die Tabelle durchzuführen. Mit dieser Metrik kann ermittelt werden, ob ein Speicher-Hotspot für die NoSQL-Tabelle vorhanden ist.
Dieses Szenario ist auf ein Ungleichgewicht bei der Speicherung der Tabellendaten über Shards zurückzuführen. Ein Ungleichgewicht kann auftreten, wenn ein Großteil der Tabellendaten in einer Teilmenge der Shards gespeichert wird. Der Speicher in einer NoSQL-Datenbank wird in Shards unterteilt, und der Shard-Schlüssel ist Teil der Tabellendefinition. In hierarchischen Tabellen verwenden die übergeordneten und untergeordneten Tabellen denselben Shard-Schlüssel. Wenn eine übergeordnete Tabelle mit untergeordneten Tabellen vorhanden ist, verwenden alle Datensätze denselben Shard-Schlüssel. Alle diese Daten werden zusammen gespeichert. Wenn eine übergeordnete Tabelle weniger untergeordnete Elemente aufweist, belegt sie weniger Speicherplatz in einem einzelnen Shard. Aufgrund dieses Ungleichgewichts können bestimmte Shards viel mehr Daten enthalten als andere Shards.
An einem bestimmten Punkt hat ein Shard die höchste Speicherplatzbelegung für eine bestimmte Tabelle, und der Prozentsatz, der in diesem Shard verwendet wird, ist der MaxShardSizeUsagePercent. Das Metrikdiagramm maxShardSizeUsagepercent für eine Tabelle wird unten angezeigt. Die Metrik wird jede Minute verwendet, und die Metrikdiagramme werden standardmäßig für ein Intervall von 5 Minuten dargestellt.
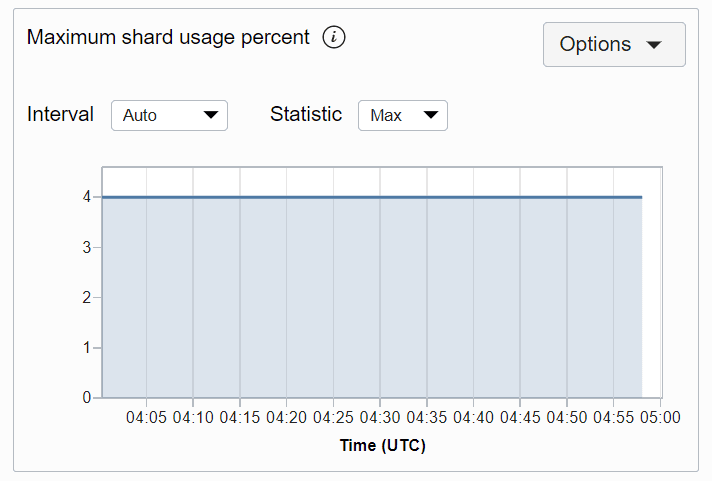
Beschreibung der Abbildung maxshardusageprct.png
Neben der Anzeige des Diagramms für eine Metrik stehen Ihnen folgende Optionen zur Verfügung.
Beschreibung der Abbildung Metric-options.png
Sie können die Tabellenansicht aufrufen, um den Wert einer Metrik zu einem bestimmten Zeitpunkt zu prüfen.
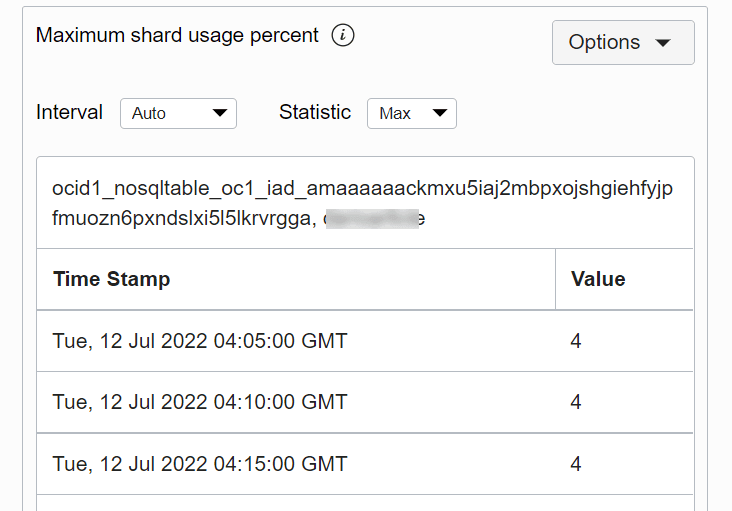
Beschreibung der Abbildung tableview.png
MaxShardSizeUsagePercent-Metrik überwachen
Sie müssen dieses Diagramm regelmäßig überwachen, um zu wissen, ob maxShardSizeUsagepercent erreicht ist. Proaktiv können Sie einen Alarm für diese Metrik erstellen.
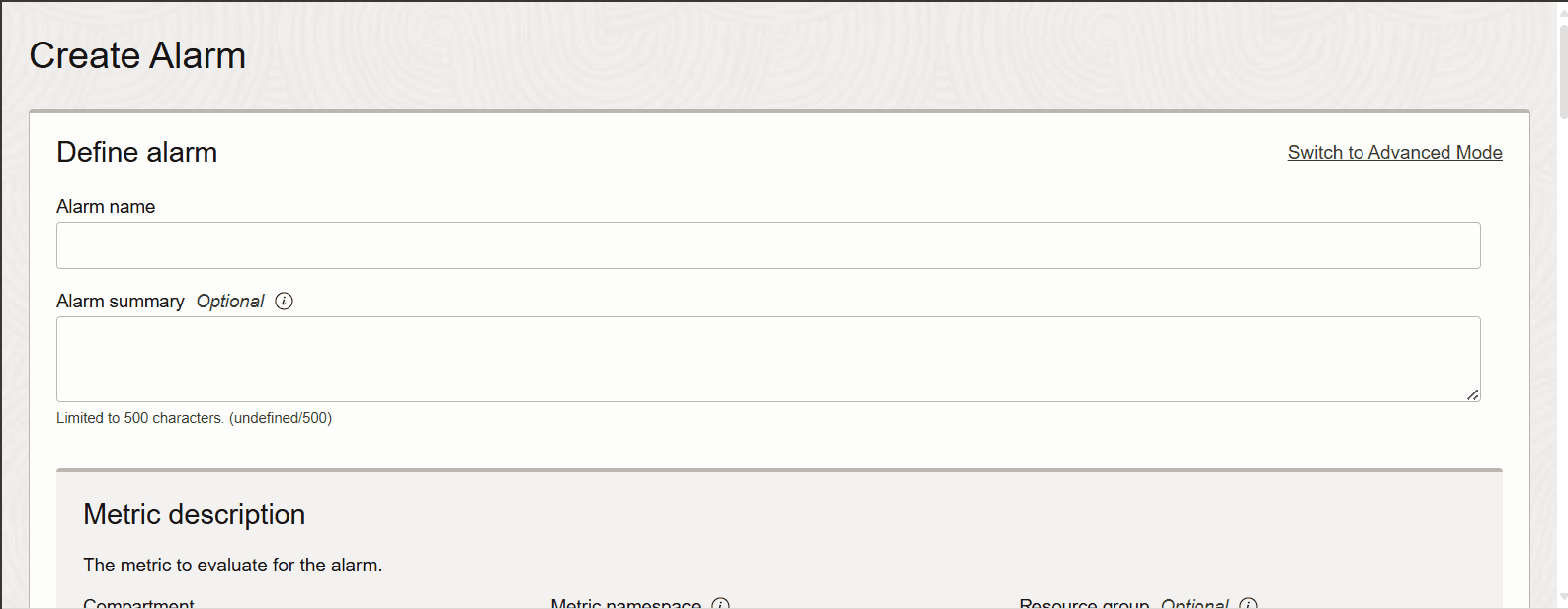
Beschreibung der Abbildung new-alarm-crt-1.png
Das heißt, Sie sollten einen Alarm auslösen, wenn die Metrik einen bestimmten Wert erreicht, z. B. 90 Prozent.
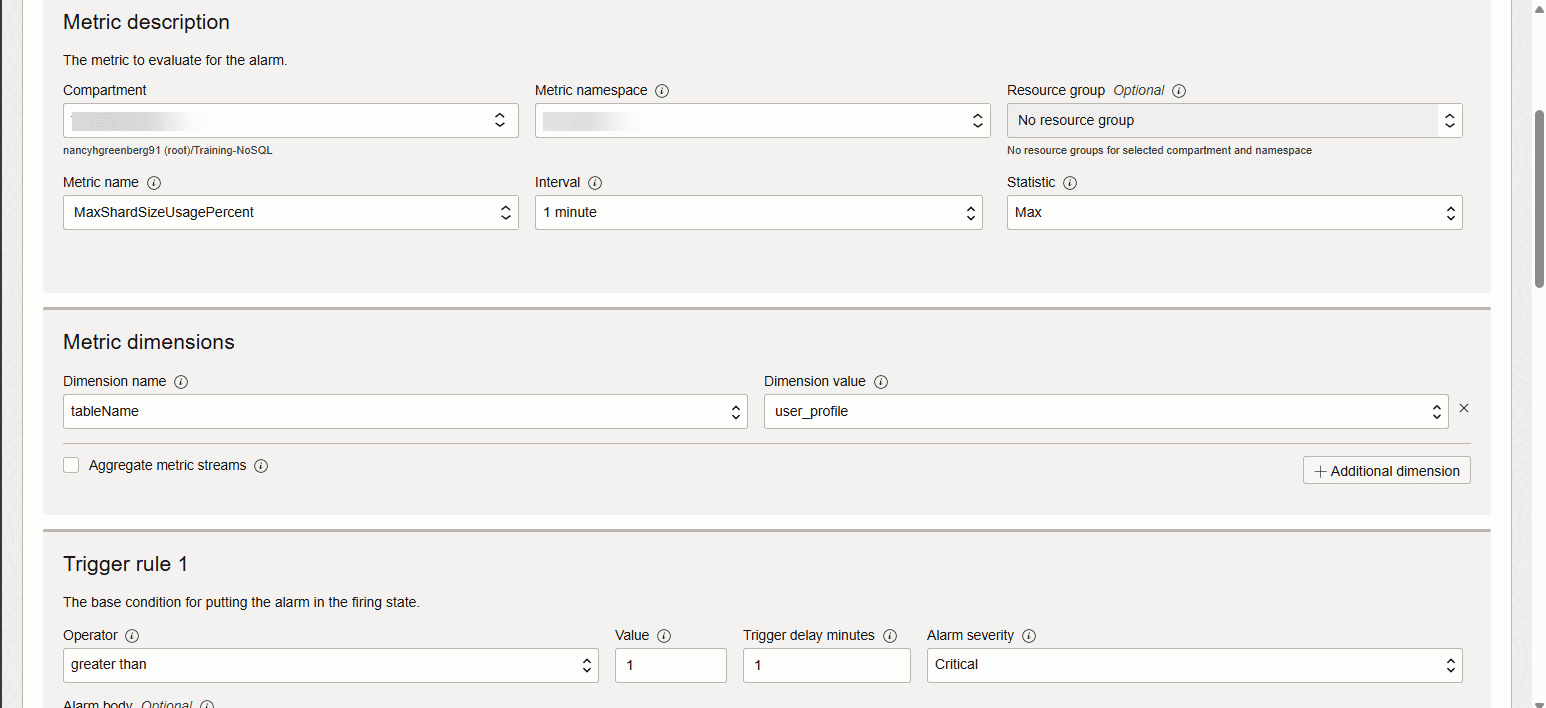
Beschreibung der Abbildung new-alarm-crt-2.png
OCI-Alarm verwendet den OCI-Benachrichtigungsservice zum Senden von Benachrichtigungen. Normalerweise wird der Alarm so konfiguriert, dass Benachrichtigungen über konfigurierte E-Mails gesendet werden. Wenn maxShardSizeUsagepercent 90 Prozent erreicht, wird eine E-Mail-Benachrichtigung gesendet.
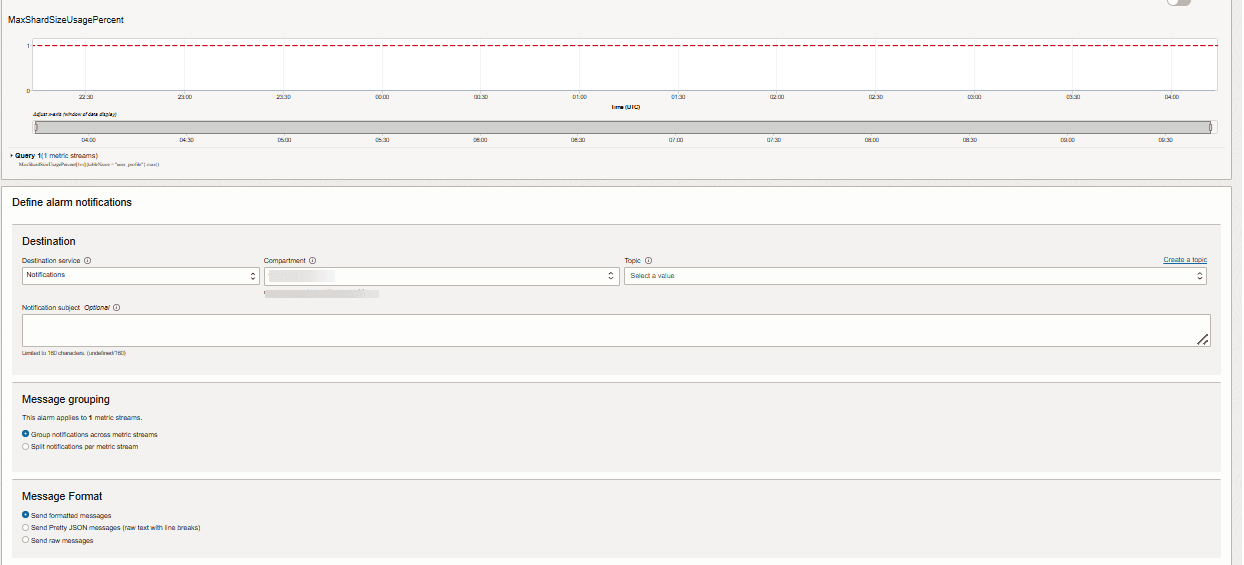
Beschreibung der Abbildung new-alarm-crt-3.png
Weitere Informationen finden Sie unter Alarme und Benachrichtigungen verwalten.
Wenn es ein Ungleichgewicht bei der Verteilung der Tabellendaten auf Shards gibt, können Sie die Ihrer Tabelle zugewiesene Speicherkapazität nicht maximal nutzen. In diesem Szenario erreicht maxShardSizeUsagepercent den Wert 100, auch ohne den gesamten Speicher zu nutzen, der der Tabelle zugewiesen ist. Sie müssen jetzt mehr Speicher hinzufügen, um mit dem Schreiben auf Ihre Tabelle fortzufahren. Dieses Szenario kann vermieden werden, indem beim Entwerfen der Tabelle einige Richtlinien befolgt werden.
-
Entscheiden Sie sich für den richtigen Shard-Schlüssel für Ihren Tisch. Die Attribute mit hoher Kardinalität sind eine gute Wahl für Shard-Schlüssel.
-
Begrenzen Sie die Anzahl der untergeordneten Tabellen, um ein potenzielles Shard-Speicherungungleichgewicht zu vermeiden.
Replikatverzögerung
Eine Zeitverzögerung beim Replizieren der Datenänderungen (INSERT/UPDATE oder DELETE) einer globalen aktiven Tabelle von einer Absenderregion in eine Empfängerregion. Der Schreibvorgang, der im Absenderbereich einer globalen aktiven Tabelle ausgeführt wurde, wird nach einer Zeitverzögerung im Empfängerbereich angezeigt. Die Informationen zur Zeitverzögerung werden als Metrik namens Replica Lag ausgedrückt. Replica Lag ist ein Maß dafür, wie aktuell die Tabellendaten in der Empfängerreplikationsregion sind, relativ zu den Daten in der Tabelle der Absenderregion. Die Replikatverzögerung gibt an, dass die Tabelle in der Empfängerregion noch keine Aktualisierungen aus der Absenderregion erhalten hat, die während der Nachlaufzeit stattgefunden hat. Wenn keine Anwendungsschreibvorgänge für die Tabelle im Absenderbereich stattgefunden haben, verwendet der Service die Ping-Mechanismen, um eine Annäherung der Verzögerung zu berechnen, und die Lag-Statistik ist weiterhin im Empfängerbereich verfügbar.
Informationen zum Replica Lag abrufen:
Klicken Sie im Teilsektor {\b Empfänger} auf die Tabelle {\b Global Active}, und zeigen Sie die Tabelleninformationen an. Klicken Sie unter Ressourcen auf Metriken. Die Metrik Replica lag (Replikationsverzögerung) zeigt die Replikationsverzögerung in Millisekunden an. Im folgenden Beispieldiagramm sehen Sie, dass die Replica Lag-Metrik in der Region "Canada Southeast (Toronto)" verwendet wird, der Empfängerregion. Diese Tabelle Global Active enthält zwei regionale Tabellenreplikate jeweils in den Regionen Canada Southeast (Montreal) und US East (Ashburn). Sie sehen, dass das Diagramm jeweils zwei Linien für diese regionalen Tabellenreplikate in Montreal und Ashburn hat.
Im folgenden Diagramm gibt das Intervall das Zeitfenster an, in dem das Diagramm dargestellt wird. Verschiedene Intervalloptionen sind verfügbar: 1 Minute, 5 Minuten, 1 Stunde und 1 Tag. Standardmäßig wird die Replikatverzögerung alle 1 Minute überwacht, und das Diagramm wird alle 5 Minuten dargestellt. Sie können verschiedene Statistiken für die Replica Lag-Metrik auswählen.
Beispiel 1: Replica Lag mit Canada Southeast (Toronto) als Empfängerregion und Canada Southeast (Montreal) und US East (Ashburn) als Absenderregionen.
Das folgende Diagramm wird für die mittlere Statistik für ein 5-Minuten-Intervall dargestellt.
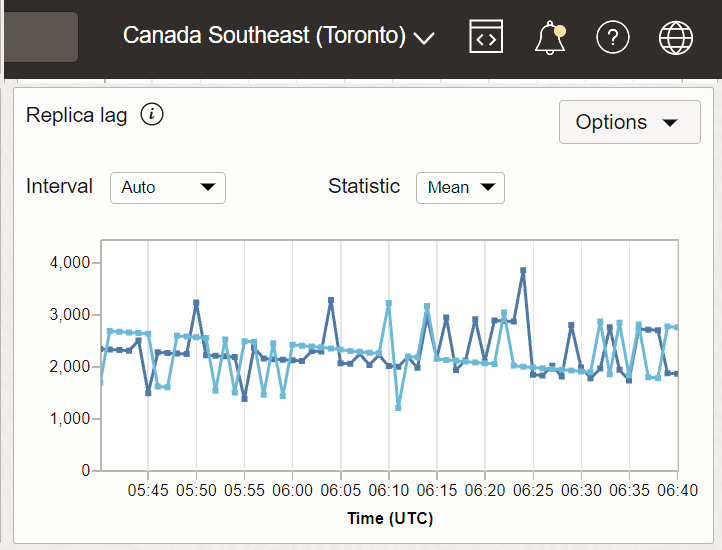
Beschreibung der Abbildung Metric_replica2.png
In diesem Beispiel sind Montreal und Ashburn zwei Absenderregionen, und Toronto ist die Empfängerregion, in der die Metrik erfasst wird. Betrachten Sie den Wert von Replica Lag um 12:25 UTC für Montreal. Es sind 2020 Millisekunden. Das bedeutet, dass die Empfängerregion Canada Southeast (Toronto) in den letzten 2020 Millisekunden keine Aktualisierungen erhalten hat, die in der Absenderregion Canada Southeast (Montreal) stattgefunden haben. Beachten Sie auch den Wert der Replikatverzögerung bei 12:25 UTC für Ashburn. Es sind 2954 Millisekunden. Das bedeutet, dass die Empfängerregion Canada Southeast (Toronto) in den letzten 2954 Millisekunden keine Aktualisierungen erhalten hat, die in der Absenderregion US East (Ashburn) stattgefunden haben.
Beispiel 2: Replica Lag mit US East (Ashburn) als Empfängerregion und Canada Southeast (Montreal) und Canada Southeast Toronto als Absenderregionen.
In diesem Beispiel sind Montreal und Toronto zwei Absenderregionen, und Ashburn ist die Empfängerregion, in der die Metrik erfasst wird.
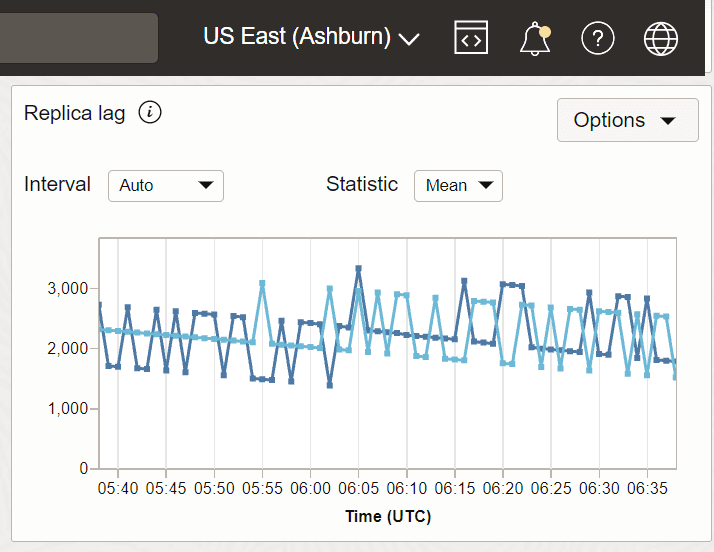
Beschreibung der Abbildung Metric_replica3.png
Beispiel 3: Replica Lag mit Canada Southeast (Montreal) als Empfängerregion und US East (Ashburn) und Canada Southeast Toronto als Absenderregionen.
In diesem Beispiel sind Ashburn und Toronto zwei Absenderregionen, und Montreal ist die Empfängerregion, in der die Metrik erfasst wird.
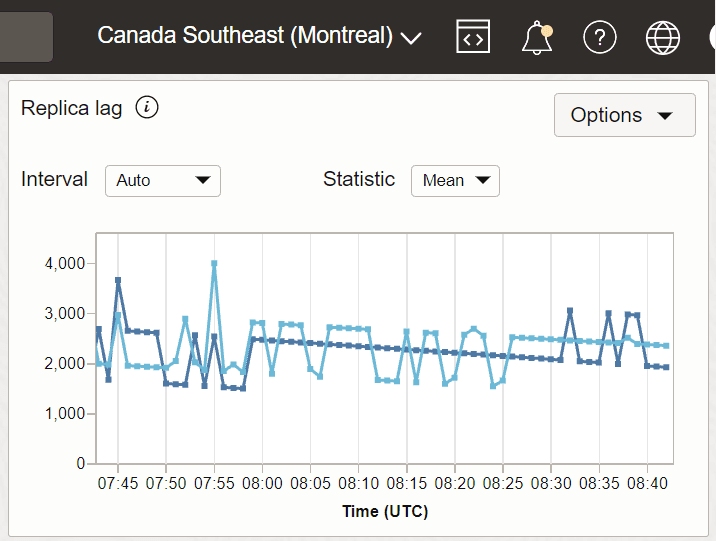
Beschreibung der Abbildung Metric_replica1.png
Neben der Anzeige des Diagramms für die Replikatverzögerung stehen Ihnen folgende Optionen zur Verfügung.
Beschreibung der Abbildung Metric_options.png
Sie können die Tabellenansicht abrufen, um den Wert der Replikatverzögerung zu einem bestimmten Zeitpunkt zu prüfen.
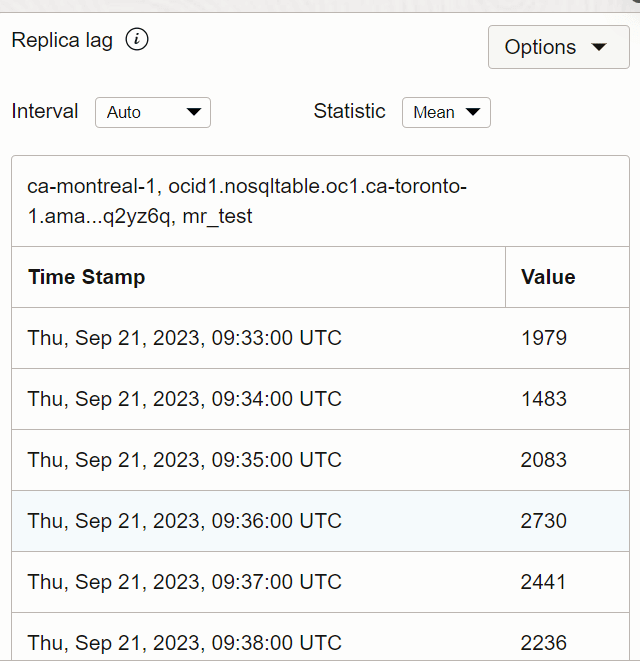
Beschreibung der Abbildung tabview_toronto.png
Oracle NoSQL Database Cloud Service-Metriken anzeigen oder auflisten
Sie können die Metriken anzeigen, die für Oracle NoSQL Database Cloud Service in der Konsole verfügbar sind. Darüber hinaus können Sie die Liste der Metriken abrufen, die für Oracle NoSQL Database Cloud Service mit OCI-CLI-Befehlen verfügbar sind.
-
öffnen Sie das Navigationsmenü, und klicken Sie auf Observability and Management. Klicken Sie unter Monitoring auf Servicemetriken.
-
Wählen Sie Compartment und Metrik-Namespace (oci_nosql) aus.
Führen Sie in der Cloud Shell den folgenden Befehl aus. Gibt Metrikdefinitionen zurück, die den in der Anforderung angegebenen Kriterien entsprechen. Compartment-OCID erforderlich. Weitere Informationen zu den OPTIONS, die mit dem Listenbefehl verfügbar sind, finden Sie unter List Metrics.
oci monitoring metric list --compartment-id <Compartment_OCID> --namespace oci_nosql
Beispiel:
oci monitoring metric list --compartment-id ocid1.compartment.oc1..aaaaaaaawrmvqjzoegxbsixp5k3b5554vlv2kxukobw3drjho3f7nf5ca3ya --namespace oci_nosqlBeispielantwort:
{
"data": [
{
"compartment-id": "ocid1.compartment.oc1..aaaaaaaawrmvqjzoegxbsixp5k3b5554vlv2kxukobw3drjho3f7nf5ca3ya",
"dimensions": {
"resourceId": "ocid1_nosqltable_oc1_phx_amaaaaaau7x7rfyasvdkoclhgryulgzox3nvlxb2bqtlxxsrvrc4zxr6lo4a",
"tableName": "demo"
},
"name": "ReadThrottleCount",
"namespace": "oci_nosql",
"resource-group": null
},
{
"compartment-id": "ocid1.compartment.oc1..aaaaaaaawrmvqjzoegxbsixp5k3b5554vlv2kxukobw3drjho3f7nf5ca3ya",
"dimensions": {
"resourceId": "ocid1_nosqltable_oc1_phx_amaaaaaau7x7rfyasvdkoclhgryulgzox3nvlxb2bqtlxxsrvrc4zxr6lo4a",
"tableName": "demo"
},
"name": "ReadUnits",
"namespace": "oci_nosql",
"resource-group": null
},
{
"compartment-id": "ocid1.compartment.oc1..aaaaaaaawrmvqjzoegxbsixp5k3b5554vlv2kxukobw3drjho3f7nf5ca3ya",
"dimensions": {
"resourceId": "ocid1_nosqltable_oc1_phx_amaaaaaau7x7rfyasvdkoclhgryulgzox3nvlxb2bqtlxxsrvrc4zxr6lo4a",
"tableName": "demo"
},
"name": "StorageGB",
"namespace": "oci_nosql",
"resource-group": null
},
{
"compartment-id": "ocid1.compartment.oc1..aaaaaaaawrmvqjzoegxbsixp5k3b5554vlv2kxukobw3drjho3f7nf5ca3ya",
"dimensions": {
"resourceId": "ocid1_nosqltable_oc1_phx_amaaaaaau7x7rfyasvdkoclhgryulgzox3nvlxb2bqtlxxsrvrc4zxr6lo4a",
"tableName": "demo"
},
"name": "StorageThrottleCount",
"namespace": "oci_nosql",
"resource-group": null
},
{
"compartment-id": "ocid1.compartment.oc1..aaaaaaaawrmvqjzoegxbsixp5k3b5554vlv2kxukobw3drjho3f7nf5ca3ya",
"dimensions": {
"resourceId": "ocid1_nosqltable_oc1_phx_amaaaaaau7x7rfyasvdkoclhgryulgzox3nvlxb2bqtlxxsrvrc4zxr6lo4a",
"tableName": "demo"
},
"name": "WriteThrottleCount",
"namespace": "oci_nosql",
"resource-group": null
},
{
"compartment-id": "ocid1.compartment.oc1..aaaaaaaawrmvqjzoegxbsixp5k3b5554vlv2kxukobw3drjho3f7nf5ca3ya",
"dimensions": {
"resourceId": "ocid1_nosqltable_oc1_phx_amaaaaaau7x7rfyasvdkoclhgryulgzox3nvlxb2bqtlxxsrvrc4zxr6lo4a",
"tableName": "demo"
},
"name": "WriteUnits",
"namespace": "oci_nosql",
"resource-group": null
}
]
}Wie werden Oracle NoSQL Database Cloud Service-Metriken erfasst?
Sie können Metrikabfragen erstellen, um bestimmte Metrikgruppen (aggregierte Daten) zu erfassen. Eine Metrikabfrage enthält den Monitoring Query Language-(MQL-)Ausdruck, der für die Rückgabe aggregierter Daten ausgewertet werden soll. Die Abfrage muss eine Metrik, eine Statistik und ein Intervall angeben.
Sie können Metrikabfragen verwenden, um Ihre Cloud-Ressourcen aktiv und passiv zu überwachen. Überwachen Sie die Überwachung aktiv mit Metrikabfragen, die Sie spontan generieren, nach Bedarf. Aktualisieren Sie in der Konsole ein Diagramm, um Daten aus mehreren Abfragen anzuzeigen. Speichern Sie die Abfragen, die Sie wiederverwenden möchten. Passiv mit Alarmen überwachen, die eine Bedingung oder Triggerregel zu einer Metrikabfrage hinzufügen.
Metrikabfragesyntax:
metric[interval] {dimensionname=dimensionvalue}.groupingfunction.statisticSyntax für Schwellenwertalarmabfrage:
metric[interval]{dimensionname=dimensionvalue}.groupingfunction.statistic alarmoperator alarmvalueInformationen zu unterstützten Parameterwerten finden Sie unter Monitoring Query Language-(MQL-)Referenz.
Beispielabfragen Einfache Metrikabfrage
Die Summe der Anzahl der Speicher-Throttles für alle Tabellen in einem Compartment in einem Intervall von einer Minute.
Die Anzahl der im Metrikdiagramm (Konsole) angezeigten Linien: 1 pro Tabelle.
StorageThrottleCount[1m].sum()Gefilterte Metrikabfrage
Die Summe der Anzahl von Speicherdrosseln in einem Compartment in einem Intervall von einer Minute, gefiltert nach einer einzelnen Tabelle.
Die Anzahl der im Metrikdiagramm (Konsole) angezeigten Linien: 1 pro Tabelle.
StorageThrottleCount[1m]{tableName = "demoKeyVal"}.sum()Aggregierte Metrikabfrage
Aggregierter Durchschnitt des Lesevorgangs in einem Intervall von sechzig Minuten, gefiltert in ein Compartment, aggregiert für den Durchschnitt.
Die Anzahl der im Metrikdiagramm (Konsole) angezeigten Linien: 1 pro Tabelle.
ReadUnits[60m]{compartmentId="ocid1.compartment.oc1.phx..exampleuniqueID"}.grouping().mean()Gruppierte aggregierte Metrikabfrage
Aggregierter Durchschnitt der Anzahl Lese-Throttles nach Leseeinheit in einem Intervall von sechzig Minuten, gefiltert nach einer einzelnen Tabelle in einem Compartment.
Die Anzahl der im Metrikdiagramm (Konsole) angezeigten Linien: 1 pro Leseeinheit.
ReadThrottleCount[60m]{tableName = "demoKeyVal"}.groupBy(ReadUnits).mean()Metrikabfrage erstellen
Es gibt zwei Möglichkeiten, eine Metrikabfrage zu erstellen. Sie können eine Abfrage entweder mit der Konsole oder mit dem OCI-CLI-Befehl erstellen.
-
öffnen Sie das Navigationsmenü, und klicken Sie auf Observability and Management. Klicken Sie unter Monitoring auf Metrik-Explorer.
Auf der Seite Metrik-Explorer wird ein leeres Diagramm mit Feldern zum Erstellen einer Abfrage angezeigt.
-
Füllen Sie die Felder aus, um eine neue Abfrage zu erstellen.
-
Compartment: Das Compartment mit den Oracle NoSQL Database Cloud Service-Tabellen, die Sie überwachen möchten. Standardmäßig ist das erste zugängliche Compartment ausgewählt.
-
Metrik-Namespace: Oracle NoSQL Database Cloud Service gibt Metriken für die Tabellen aus, die Sie überwachen möchten. Beispiel: oci_nosql.
-
Ressourcengruppe (optional): Die Gruppe, zu der die Metrik gehört. Eine Ressourcengruppe ist eine benutzerdefinierte Zeichenfolge, die mit einer benutzerdefinierten Metrik angegeben wird. Gilt nicht für Servicemetriken.
-
Metrikname: Der Name der Metrik. Nur eine Metrik kann angegeben werden. Die Metrikauswahl hängt von dem ausgewählten Compartment und dem Metrik-Namespace ab. Beispiel: ReadUnits
-
Intervall: Das Aggregationsfenster.
-
Statistik: Die Aggregationsfunktion.
-
Metrikdimensionen: Optionale Filter, um die ausgewerteten Metrikdaten einzugrenzen.
- Dimensionsfelder: Für Oracle NoSQL Database Cloud Service-Metriken können Sie entweder resourceId oder tableName als Dimensionsname und Dimensionswertpaar auswählen.
-
Aggregierte Metrikstreams: Stellt den kombinierten Wert aller Metrikstreams für die ausgewählte Statistik im Metrikdiagramm durch eine Linie dar.
-
-
Klicken Sie auf Diagramm aktualisieren.
Im Diagramm werden die Ergebnisse der neuen Abfrage angezeigt. Sehr kleine oder große Werte werden in den SI-Einheiten (Internationales Einheitensystem) angegeben, wie z.B. M für Mega (10 bis sechste Macht). Einheiten entsprechen der ausgewählten Metrik und werden nicht nach Statistik geändert.
-
Um die Abfrage als MQL-Ausdruck (Monitoring Query Language) anzuzeigen, wählen Sie den Erweiterten Modus.
-
Der Modus "Erweiterter Modus" befindet sich rechts unter dem Diagramm.
Verwenden Sie den erweiterten Modi, um die Abfrage mit der MQL-Syntax zu bearbeiten und die Ergebnisse nach Gruppe aggregieren. Die MQL-Syntax unterstützt auch zusätzliche Parameterwerte. Weitere Informationen zu Abfrageparametern im Basismodus und im erweiterten Modus finden Sie unter Monitoring Query Language-(MQL-)Referenz.
-
Führen Sie in der Cloud Shell den folgenden Befehl aus. Es gibt aggregierte Daten zurück, die den in der Anforderung angegebenen Kriterien entsprechen. Compartment-OCID erforderlich.
oci monitoring metric-data summarize-metrics-data --compartment-id<Compartment_OCID> --namespace oci_nosql --query-text [text]
--query-text ist der Monitoring Query Language-(MQL-)Ausdruck, der bei der Suche nach zu aggregierenden Metrikdatenpunkten verwendet werden soll. Die Abfrage muss eine Metrik, eine Statistik und ein Intervall angeben. Unterstützte Werte für Intervall: 1m-60m (auch 1h). Sie können optional Dimensionen und Gruppierungsfunktionen angeben. Unterstützte Gruppierungsfunktionen: grouping(), groupBy(). Weitere Informationen zu den OPTIONS, die mit dem Befehl "aggregize-metrics-data" verfügbar sind, finden Sie unter Summarize Metrics Data. Im folgenden Beispiel wird eine gefilterte Metrikabfrage erstellt, um die Summe der Leseeinheiten in einem Compartment in einem Ein-Minuten-Intervall abzurufen, das in eine einzelne Tabelle gefiltert wird.
Beispiel:
oci monitoring metric-data summarize-metrics-data --compartment-id ocid1.compartment.oc1..aaaaaaaawrmvqjzoegxbsixp5k3b5554vlv2kxukobw3drjho3f7nf5ca3ya
--namespace oci_nosql --query-text 'ReadUnits[1m]{tableName="articles"}.sum()'Beispielantwort:
{
"data": [
{
"aggregated-datapoints": [
{
"timestamp": "2022-02-17T11:03:00+00:00",
"value": 0.0
},
{
"timestamp": "2022-02-17T11:04:00+00:00",
"value": 0.0
},
{
"timestamp": "2022-02-17T11:05:00+00:00",
"value": 0.0
},
...
...
...
{
"timestamp": "2022-02-17T13:59:00+00:00",
"value": 0.0
},
{
"timestamp": "2022-02-17T14:00:00+00:00",
"value": 0.0
},
{
"timestamp": "2022-02-17T14:01:00+00:00",
"value": 0.0
}
],
"compartment-id": "ocid1.compartment.oc1..aaaaaaaawrmvqjzoegxbsixp5k3b5554vlv2kxukobw3drjho3f7nf5ca3ya",
"dimensions": {
"resourceId": "ocid1_nosqltable_oc1_phx_amaaaaaau7x7rfyav7f67yuj3t2q6rk7lp2a2obfdxa6hg2ho2ea7qabin4q",
"tableName": "demo"
},
"metadata": {},
"name": "ReadUnits",
"namespace": "oci_nosql",
"resolution": null,
"resource-group": null
}
]
}Alarme werden erstellt
Sie können einen Alarm erstellen, der die Alarmabfrage auswertet und eine Benachrichtigung sendet, wenn sich der Alarm im Auslösestatus befindet, zusammen mit anderen Alarmeigenschaften. Wenn ein Alarm ausgelöst wird, sendet er eine Alarmnachricht an das konfigurierte Thema (in Benachrichtigungen), das dann die Nachricht an alle Abonnements des Themas sendet. Slack, E-Mail, SMS und PagerDuty sind einige Beispiele für konfigurierte Themen in Benachrichtigungen.
Sofern dies konfiguriert wurde, werden Sie im festgelegten Intervall durch Wiederholungsbenachrichtigungen über einen fortlaufenden Auslösestatus informiert. Sie werden auch benachrichtigt, wenn ein Alarm wieder in den Status "OK" wechselt oder wenn ein Alarm zurückgesetzt wird.
Eine Alarmabfrage enthält den Monitoring Query Language-(MQL-)Ausdruck, der für die Rückgabe aggregierter Daten ausgewertet werden soll. Die Abfrage muss eine Metrik, eine Statistik und ein Intervall angeben.
Es gibt zwei Möglichkeiten, einen Alarm zu erzeugen. Sie können eine Abfrage entweder mit der Konsole oder der OCI-CLI erstellen.
-
öffnen Sie das Navigationsmenü, und klicken Sie auf Observability and Management. Klicken Sie unter Monitoring auf Alarmdefinitionen.
-
Klicken Sie auf Alarm erstellen.
Hinweis: Sie können einen Alarm auch von einer vordefinierten Abfrage auf der Seite "Servicemetriken" erstellen. Blenden Sie Optionen ein, und klicken Sie auf "Alarm für diese Abfrage erstellen". Weitere Informationen zu Servicemetriken finden Sie unter Oracle NoSQL Database Cloud Service-Metriken anzeigen oder auflisten.
-
Füllen Sie auf der Seite Alarm erstellen unter Alarm definieren die Alarmeinstellungen ein, oder aktualisieren Sie sie. Klicken Sie zum Umschalten zwischen Basismodus und erweitertem Modi auf In den erweiterten Modus wechseln oder In den Basismodus wechseln (rechts neben "Alarm definieren").
-
Alarmname: Benutzerfreundlicher Name für den neuen Alarm. Dieser Name wird als Titel für Benachrichtigungen zu diesem Alarm gesendet. Geben Sie dabei keine vertraulichen Informationen ein.
-
Alarmübersicht: Geben Sie eine benutzerfreundliche Übersicht für den neuen Alarm ein. Dies ist ein fakultatives Feld.
-
Tags (optional): Wenn Sie über Berechtigungen zum Erstellen von Ressourcen verfügen, können Sie auf die Ressource auch Freiformtags anwenden. Um ein definiertes Tag anzuwenden, benötigen Sie die Berechtigung zum Verwenden des Tag-Namespace. Weitere Informationen zum Tagging finden Sie unter Ressourcentags. Wenn Sie nicht sicher sind, ob Sie Tags anwenden sollten, überspringen Sie diese Option, oder fragen Sie Ihren Administrator. Sie können die Tags auch später noch anwenden.
Hinweis: Klicken Sie unten auf der Seite auf Erweiterte Optionen anzeigen, um auf die Tags-Optionen zuzugreifen.
-
Metrikbeschreibung: Die Metrik, die für die Alarmbedingung ausgewertet werden muss.
-
Compartment: Das Compartment mit den Oracle NoSQL Database Cloud Service-Tabellen, die Sie überwachen möchten. Standardmäßig ist das erste zugängliche Compartment ausgewählt.
-
Metrik-Namespace: Oracle NoSQL Database Cloud Service gibt Metriken für die Tabellen aus, die Sie überwachen möchten. Beispiel: oci_nosql.
-
Ressourcengruppe (optional): Die Gruppe, zu der die Metrik gehört. Eine Ressourcengruppe ist eine benutzerdefinierte Zeichenfolge, die mit einer benutzerdefinierten Metrik angegeben wird. Gilt nicht für Servicemetriken.
-
Metrikname: Der Name der Metrik. Nur eine Metrik kann angegeben werden. Die Metrikauswahl hängt von dem ausgewählten Compartment und dem Metrik-Namespace ab. Beispiel: ReadUnits
-
Intervall: Das Aggregationsfenster.
-
Statistik: Die Aggregationsfunktion.
-
Metrikdimensionen: Optionale Filter zum Eingrenzen der ausgewerteten Metrikdaten.
- Dimensionsfelder: Für Oracle NoSQL Database Cloud Service-Metriken können Sie entweder resourceId oder tableName als Dimensionsname und Dimensionswertpaar auswählen.
-
-
Aggregierte Metrikstreams: Stellt eine einzelne Zeile im Metrikdiagramm dar, um den kombinierten Wert aller Metrikstreams für die ausgewählte Statistik dar.
-
Triggerregel: Die Bedingung, die erfüllt werden muss, damit der Alarm den Auslösestatus aufweist. Die Bedingung kann als Schwellenwert angegeben werden, wie beispielsweise 90% für StorageGB.
-
Operator: Der Operator, der im Bedingungsschwellenwert verwendet wird.
-
Wert: Der Wert, der für den Bedingungsschwellenwert verwendet wird.
-
Triggerverzögerung in Minuten: Die Anzahl der Minuten, die der Zustand aufrechterhalten werden muss, bevor der Alarm den Auslösestatus aufweist.
-
Alarmschweregrad: Der wahrgenommene Antworttyp, der erforderlich ist, wenn der Alarm ausgelöst wird.
-
Alarmtext: Der menschenlesbare Inhalt der übermittelten Benachrichtigung. Oracle empfiehlt, Anweisungen für Benutzer zum Beheben der Alarmbedingung anzugeben. Beispiel: "High Read Throttle Count".
-
-
-
Um die Ansicht der Abfrageergebnisse zu ändern, klicken Sie auf die entsprechende Option über den Ergebnissen auf der rechten Seite:
-
Datentabelle anzeigen: Führt Datenpunkte auf, die jeweils einen Zeitstempel und Byte angeben.
-
Diagramm anzeigen (Standard): Stellt Datenpunkte in einem Diagramm dar.
-
-
Benachrichtigungen einrichten: Füllen Sie die Felder unter "Benachrichtigungen" aus.
-
Ziele: Das Thema, das für Benachrichtigungen verwendet werden soll.
-
Wiederholungsbenachrichtigung?: Während der Alarm den Auslösestatus aufweist, sendet der Alarm im angegebenen Intervall erneut Benachrichtigungen.
-
Benachrichtigungshäufigkeit: Die Wartezeit bis zum erneuten Senden der Benachrichtigung.
-
Benachrichtigungen unterdrücken: Richten Sie ein Unterdrückungszeitfenster ein, in dem Auswertungen und Benachrichtigungen ausgesetzt werden sollen, Dies ist hilfreich, um Alarmbenachrichtigungen während Systemwartungszeiträumen zu vermeiden.
-
-
Wenn Sie den neuen Alarm deaktivieren möchten, deaktivieren Sie Diesen Alert aktivieren?.
-
Klicken Sie auf Alarm speichern.
Führen Sie in der Cloud Shell den folgenden Befehl aus, um einen neuen Alarm im angegebenen Compartment zu erstellen. Compartment-OCID erforderlich.
oci monitoring alarm create --compartment-id <Compartment_OCID> --namespace oci_nosql --query-text [text] --destinations [complex type] --display-name [text] --is-enabled [boolean] --metric-compartment-id [text] --severity [text]
--query-text ist der Monitoring Query Language-(MQL-)Ausdruck, der bei der Suche nach zu aggregierenden Metrikdatenpunkten verwendet werden soll. Die Abfrage muss eine Metrik, eine Statistik und ein Intervall angeben. Unterstützte Werte für Intervall: 1m-60m (auch 1h). Sie können optional Dimensionen und Gruppierungsfunktionen angeben. Unterstützte Gruppierungsfunktionen: grouping(), groupBy(). Weitere Informationen zu den OPTIONS, die mit dem Befehl "Alarm erstellen" verfügbar sind, finden Sie unter Erstellen - Alarm. Im folgenden Beispiel wird ein Alarm mit einer Alarmabfrage erstellt, wenn 90 das Perzentil von StorageGB in einem Compartment in einem Intervall von einer Minute größer als 85 ist, gefiltert nach einer einzelnen Tabelle.
Beispiel für Schwellenwertalarm:
oci monitoring alarm create --compartment-id ocid1.compartment.oc1..aaaaaaaawrmvqjzoegxbsixp5k3b5554vlv2kxukobw3drjho3f7nf5ca3ya
--namespace oci_nosql --query-text 'StorageGB[1m]{tableName="demo"}.groupBy(WriteUnits).percentile(0.9) > 85'
--display-name HighStorageConsumption --metric-compartment-id demonosql --severity Critical --is-enabled trueAlarme verwenden
Sie können diese Richtlinien befolgen, wie Sie Ihre Alarme verwalten.
-
Erstellen Sie ein Alarmset für jede Metrik. Erstellen Sie für jede von der Oracle NoSQL Database Cloud Service-Tabelle ausgegebene Metrik Alarme, die das folgende Ressourcenverhalten definieren:
-
In Gefahr - Der Oracle NoSQL Database Cloud Service ist dem Risiko ausgesetzt, nicht mehr funktionsfähig zu sein, wie durch Metrikwerte angegeben. Beispiel: Die Speichergröße für eine Tabelle gefährdet eine hohe Auslastung.
-
Nicht optimal - Der Oracle NoSQL Database Cloud Service wird auf nicht optimalen Ebenen ausgeführt, wie mit Metrikwerten angegeben. Beispiel: ReadUnits oder Write Units weisen eine hohe Latenz auf.
-
Ressource ist hoch- oder heruntergefahren - Oracle NoSQL Database Cloud Service ist entweder nicht erreichbar oder funktioniert nicht. Beispiel: Hohe Zahl für ReadThrottleCount oder WriteThrottleCount.
-
-
Richten Sie einen Prozess für die Reaktion auf Alarme ein. Je nach Schweregrad des Alarms können Sie auf folgende Arten auf die Alarme reagieren:
-
Bei Critical to At-Risk-Alarmen können Sie das Operations-Team sofort benachrichtigen, da eine Reparatur erforderlich ist, um die Instanzen wieder auf optimale Betriebsebenen zu bringen. Sie konfigurieren Alarmbenachrichtigungen für das verantwortliche Team sowohl über PagerDuty als auch über E-Mails, um eine Untersuchung und entsprechende Behebungsmaßnahmen anzufordern, bevor die Instanzen in einen nicht betriebsbereiten Status wechseln. Sie legen minütliche Wiederholungsbenachrichtigungen fest. Wenn jemand auf die Alarmbenachrichtigungen antwortet, stoppen Sie vorübergehend Benachrichtigungen, indem Sie den Alarm unterdrücken. Sobald die Metriken wieder optimale Werte aufweisen, entfernen Sie die Unterdrückung.
-
Bei Warnungs- oder nicht optimalen Alarmen können Sie die entsprechende Person oder das entsprechende Team benachrichtigen, dass die Oracle NoSQL Database Cloud Service-Tabelle mehr Speichergröße verbraucht als üblich. Sie konfigurieren einen Schwellenwertalarm zur Benachrichtigung der entsprechenden Kontakte, da keine unmittelbaren Maßnahmen zur Untersuchung und Reduzierung der Speichergröße erforderlich sind. Sie legen die Benachrichtigung auf "Nur E-Mail" an den entsprechenden Entwickler oder das Team fest. Das Wiederholungsintervall setzen Sie auf 24 Stunden, um die Anzahl der E-Mail-Benachrichtigung zu reduzieren.
-