Oracle NoSQL Database Cloud Service - Referenz
Erfahren Sie mehr über unterstützte Datentypen, DDL-Anweisungen, Oracle NoSQL Database Cloud Service-Parameter und -Metriken.
Dieser Artikel enthält die folgenden Themen:
Unterstützte Datentypen
Oracle NoSQL Database Cloud Service unterstützt viele gängige Datentypen.
| Datentyp | Beschreibung |
|---|---|
BINARY |
Eine Folge von null oder mehr Byte. Die Speichergröße ist die Anzahl der Byte plus eine Codierung der Größe des Bytearrays, das je nach Größe des Arrays eine Variable ist. |
FIXED_BINARY |
Ein Bytearray mit fester Größe. Für diesen Datentyp gibt es keinen zusätzlichen Codierungs-Overhead. |
BOOLEAN |
Ein Datentyp mit einem von zwei möglichen Werten: TRUE oder FALSE. Die Speichergröße des booleschen Wertes beträgt 1 Byte. |
DOUBLE |
Eine lange Gleitkommazahl, die mit 8 Byte Speicher für Indexschlüssel codiert wird. Wenn es sich um einen Primärschlüssel handelt, verwendet er 10 Byte Speicher. |
FLOAT |
Eine lange Gleitkommazahl, die mit 4 Byte Speicher für Indexschlüssel codiert wird. Wenn es sich um einen Primärschlüssel handelt, verwendet er 5 Byte Speicher. |
LONG |
Eine lange Ganzzahl hat eine Codierung mit variabler Länge, die je nach Wert 1-8 Byte Speicher verwendet. Wenn es sich um einen Primärschlüssel handelt, verwendet er 10 Byte Speicher. |
INTEGER |
Eine lange Ganzzahl hat eine Codierung mit variabler Länge, die je nach Wert 1-4 Byte Speicher verwendet. Wenn es sich um einen Primärschlüssel handelt, verwendet er 5 Byte Speicher. |
STRING |
Eine Folge von null oder mehr Unicode-Zeichen. Der Stringtyp wird als UTF-8 codiert und in dieser Codierung gespeichert. Die Speichergröße entspricht der Anzahl der UTF-8 Byte plus der Länge, die je nach Anzahl der Bytes in der Codierung 1-4 Byte betragen kann. Beim Speichern in einem Indexschlüssel entspricht die Speichergröße der Anzahl der UTF-8 Byte plus einem einzelnen Nullbeendigungsbyte. |
NUMBER |
Eine vorzeichenbehaftete Dezimalzahl mit beliebiger Genauigkeit. Sie wird in einem Bytearrayformat serialisiert, das für geordnete Vergleiche verwendet werden kann. Das Format besteht aus 2 Teilen: 1. Das Zeichen und der Exponent plus eine einzelne Ziffer. Dies dauert 1-6 Byte, ist aber normalerweise 2, es sei denn, der Exponent ist ziemlich groß 2. Die Mantisse des Werts, der etwa ein Byte pro 2-stellig ist Beispiele: 12.345678 serialisiert in 6 Byte 1.234E+102 serialisiert in 5 Byte Hinweis: Wenn Sie numerische Werte in Ihrem Schema verwenden müssen, wird diese Es wird empfohlen, sich für die Datentypen in der unten angegebenen Reihenfolge zu entscheiden: INTEGER, LONG, FLOAT, DOUBLE, NUMBER Vermeiden Sie NUMBER, es sei denn, Sie benötigen es wirklich für Ihren Anwendungsfall, da NUMBER sowohl in Bezug auf die Speicher- als auch in Bezug auf die Verarbeitungsleistung teuer ist. |
TIMESTAMP |
Ein Zeitpunkt mit einer Gesamtstellenzahl. Die Gesamtstellenzahl wirkt sich auf die Speichergröße und -nutzung aus. TIMESTAMP-Daten werden in UTC (Koordinierte Weltzeit) gespeichert und verwaltet. Der Datentyp "Zeitstempel" erfordert je nach verwendeter Genauigkeit zwischen 3 und 9 Byte. Die folgende Aufschlüsselung veranschaulicht den von diesem Datentyp verwendeten Speicher: - Bit[0~13] Jahr - 14 Bit - Bit[14~17] Monat - 4 Bit - Bit[18~22] Tag - 5 Bit - Bit[23~27] Stunde - 5 Bit [optional] - Bit[28~33] Minute - 6 Bit [optional] - Bit[34~39] Sekunde - 6 Bit [optional] - Bit[40~71] Bruchteilsekunde [optional mit variabler Länge] |
UUID |
Hinweis: Der UUID-Datentyp wird als Subtyp des STRING-Datentyps betrachtet. Die Speichergröße beträgt 16 Byte als Indexschlüssel. Bei Verwendung als Primärschlüssel beträgt die Speichergröße 19 Byte. |
ENUM |
Eine Enumeration wird als Array von Zeichenfolgen dargestellt. ENUM-Werte sind symbolische IDs (Token). Sie werden als kleiner ganzzahliger Wert gespeichert, der eine geordnete Position in der Enumerationsreihenfolge darstellt. |
ARRAY |
Eine sortierte Collection mit null oder mehr typisierten Elementen. Arrays, die nicht als JSON definiert sind, können keine NULL-Werte enthalten. Als JSON deklarierte Arrays können ein beliebiges gültiges JSON-Format enthalten, einschließlich des speziellen Werts NULL, der für die JSON relevant ist. |
MAP |
Eine nicht sortierte Collection mit null oder mehr Schlüssel/Element-Paaren, wobei alle Schlüssel Zeichenfolgen sind und alle Elemente denselben Typ aufweisen. Alle Schlüssel müssen eindeutig sein. Die Schlüssel/Element-Paare werden als Felder bezeichnet, wobei die Schlüssel Feldnamen und die zugeordneten Elemente Feldwerte sind. Feldwerte können unterschiedliche Typen aufweisen, Zuordnungen dürfen jedoch keine NULL-Feldwerte enthalten. |
RECORD |
Eine feste Collection aus Schlüssel/Element-Paaren, wobei alle Schlüssel Zeichenfolgen sind. Alle Schlüssel in einem Datensatz müssen eindeutig sein. |
JSON |
Beliebige gültige JSON-Daten. |
Tabellenstatus und -lebenszyklen
Machen Sie sich mit den verschiedenen Tabellenstatus und deren Bedeutung vertraut (Tabellenlebenszyklusprozess).
Jede Tabelle durchläuft eine Reihe von unterschiedlichen Status von ihrer Erstellung bis zum Löschen. Beispiel: Eine Tabelle im Status DROPPING kann nicht in den Status ACTIVE versetzt werden. Eine Tabelle im Status ACTIVE hingegen kann in den Status UPDATING versetzt werden. Sie können die verschiedenen Tabellenstatus verfolgen, indem Sie den Tabellenlebenszyklus überwachen. In diesem Abschnitt werden die einzelnen Tabellenstatus beschrieben.
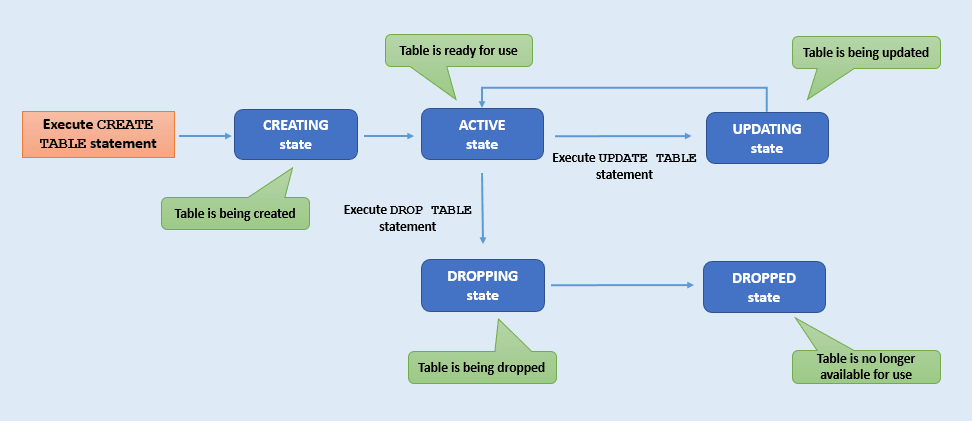
Beschreibung der Abbildung table-state.png
| Tabellenstatus | Beschreibung |
|---|---|
CREATING |
Die Tabelle wird gerade erstellt. Es ist nicht bereit zur Verwendung. |
UPDATING |
Die Tabelle wird gerade aktualisiert. Weitere Tabellenänderungen sind nicht möglich, während sich die Tabelle in diesem Status befindet. Eine Tabelle befindet sich im Status UPDATING, wenn:- Die Tabellenlimits geändert werden - Das Tabellenschema entwickelt sich - Tabellenindex hinzufügen oder löschen |
ACTIVE |
Die Tabelle kann im aktuellen Status verwendet werden. Die Tabelle wurde möglicherweise vor Kurzem erstellt oder geändert, ihr Status ist jetzt jedoch stabil. |
DROPPING |
Die Tabelle wird gerade gelöscht und kann nicht aufgerufen werden (egal, zu welchem Zweck). |
DROPPED |
Die Tabelle wurde gelöscht und ist für Lese-, Schreib- oder Abfrageaktivitäten nicht mehr vorhanden. Hinweis: Nach dem Löschen kann eine Tabelle mit demselben Namen erneut erstellt werden. |
Fehler bei SQL-Anweisungen in der OCI-Konsole debuggen
Wenn Sie mit der OCI-Konsole eine Tabelle mit einer DDL-Anweisung oder mit einer DML-Anweisung zum Einfügen oder Aktualisieren von Daten oder zum Abrufen von Daten mit einer SELECT-Abfrage erstellen, wird in einem der folgenden allgemeinen Szenarios möglicherweise ein Fehler angezeigt, dass Ihre Anweisung Unvollständig oder fehlerhaft ist:
- Wenn am Ende der SQL-Anweisung ein Semikolon angezeigt wird.
- Wenn in Ihrer SQL-Anweisung ein Syntaxfehler auftritt, wie die falsche Verwendung von Kommas, die Verwendung unnötiger Zeichen in der Anweisung usw.
- Wenn die SQL-Anweisung in einem der SQL-Schlüsselwörter oder in der Datentypdefinition einen Rechtschreibfehler enthält.
- Wenn Sie die Spalte als NOT NULL definiert haben, ihr jedoch keinen DEFAULT-Wert zugewiesen haben.
- Wenn Sie die Spalte als NOT NULL definiert haben, ihr jedoch keinen DEFAULT-Wert zugewiesen haben.
Wie Sie einige unvollständige oder fehlerhafte Fehler behandeln, wenn Sie Daten mit der OCI-Konsole erstellen oder verwalten:
- Entfernen Sie das Semikolon (falls vorhanden) am Ende der SQL-Anweisung.
- Prüfen Sie, ob in Ihrer SQL-Anweisung ein unerwünschtes Zeichen oder eine falsche Zeichensetzung vorhanden ist.
- Prüfen Sie auf Rechtschreibfehler in Ihrer SQL-Anweisung.
- Prüfen Sie, ob alle Spaltendefinitionen vollständig und korrekt sind.
- Prüfen Sie, ob Sie einen Primärschlüssel für die Tabelle definiert haben.
Wenn Sie immer noch einen Fehler erhalten, nachdem Sie einige der oben beschriebenen möglichen Situationen beseitigt haben, können Sie die Abfrage mit Cloud Shell ausführen und den genauen Fehler erfassen, wie im folgenden Beispiel gezeigt.
Beispiel: Fehlermeldung für eine SELECT-Anweisung aus der cloud shell abrufen
Der Befehl summarize prüft die Syntax und gibt eine kurze Zusammenfassung einer SQL-Anweisung zurück.
-
Öffnen Sie in der OCI-Konsole die Cloud Shell aus dem Menü oben rechts.
-
Kopieren Sie die SQL SELECT-Anweisung (z.B.
query1.sql) in eine Variable (SQL_SELECTSTMT).Beispiel:
SQL_SELECTSTMT=$(cat ~/query1.sql | tr '\n' ' ') -
Rufen Sie den folgenden Befehl "oci" auf, um die Syntax Ihrer SQL SELECT-Anweisung zu prüfen.
Hinweis: Sie müssen die
compartment_idfür diese SELECT-Anweisung angeben.oci raw-request --http-method GET --target-uri https://nosql.${OCI_REGION}.oci.oraclecloud.com/20190828/query/summarize?compartmentId=$NOSQL_COMPID\ &statement="$SQL_SELECTSTMT" | jq '.data'
Dadurch erhalten Sie den genauen Fehler in der SQL-Anweisung.
Referenz zur Data Definition Language
Erfahren Sie, wie Sie DDL in Oracle NoSQL Database Cloud Service verwenden.
Mit Oracle NoSQL Database Cloud Service-DDL können Sie Tabellen und Indizes erstellen, ändern und löschen.
Informationen zur Syntax der DDL-Sprache finden Sie in der DDL-Dokumentation für Tabellen. In dieser Dokumentation wird die von den On-Premise-Oracle NoSQL Database-Produkten unterstützte DDL-Sprache erläutert. Oracle NoSQL Database Cloud Service unterstützt einen Teil dieser Funktionalität. Die Unterschiede werden im Abschnitt DDL-Unterschiede in der Cloud dokumentiert.
Außerdem bietet jeder NoSQL-Sprachtreiber eine API zum Ausführen einer DDL-Anweisung. Informationen zum Schreiben Ihrer Anwendung finden Sie unter Tabellen und Indizes in Oracle NoSQL Database Cloud Service mit APIs erstellen.
Typische DDL-Anweisungen
Beispiele für häufig verwendete DDL-Anweisungen:
Tabelle erstellen
CREATE TABLE [IF NOT EXISTS] (
field-definition, field-definition-2 ...,
PRIMARY KEY (field-name, field-name-2...),
) [USING TTL ttl]Beispiel:
CREATE TABLE IF NOT EXISTS audience_info (
cookie_id LONG,
ipaddr STRING,
audience_segment JSON,
PRIMARY KEY(cookie_id))Tabelle ändern
ALTER TABLE table-name (ADD field-definition)
ALTER TABLE table-name (DROP field-name)
ALTER TABLE table-name USING TTL ttlBeispiel:
ALTER TABLE audience_info USING TTL 7 daysIndex erstellen
CREATE INDEX [IF NOT EXISTS] index-name ON table-name (path_list)Beispiel:
CREATE INDEX segmentIdx ON audience_info
(audience_segment.sports_lover AS STRING)Tabelle löschen
DROP TABLE [IF EXISTS] table-nameBeispiel:
DROP TABLE audience_infoEine vollständige Liste finden Sie im Referenzhandbuch:
DDL-Unterschiede in der Cloud
Die DDL-Sprache des Cloud-Service unterscheidet sich wie folgt von der Beschreibung in der Referenzdokumentation:
Tabellennamen
- Sind auf 256 Zeichen begrenzt und dürfen nur alphanumerische Zeichen und Unterstriche enthalten
- Muss mit einem Buchstaben beginnen
- Dürfen keine Sonderzeichen enthalten
- Untergeordnete Tabellen werden nicht unterstützt
Nicht unterstützte Konzepte
DESCRIBE- undSHOW TABLE-Anweisungen- Volltextindizes
- Benutzer- und Rollenmanagement
- On-Premise-Regionen
Abfragesprache - Referenz
Erfahren Sie, wie Sie mit SQL-Anweisungen Daten in Oracle NoSQL Database Cloud Service aktualisieren und abfragen.
Oracle NoSQL Database verwendet die SQL-Abfragesprache, um Daten in NoSQL-Tabellen zu aktualisieren und abzufragen. Weitere Informationen zur Syntax der Abfragesprache finden Sie unter SQL-Referenz für Oracle NoSQL Database.
Typische Abfragen
SELECT <expression>
FROM <table name>
[WHERE <expression>]
[GROUP BY <expression>]
[ORDER BY <expression> [<sort order>]]
[LIMIT <number>]
[OFFSET <number>];Beispiel:
SELECT * FROM Users;
SELECT id, firstname, lastname FROM Users WHERE firstname = "Taylor";UPDATE <table_name> [AS <table_alias>]
<update_clause>[, <update_clause>]*
WHERE <expr>[<returning_clause>];Beispiel:
UPDATE JSONPersons $j
SET TTL 1 DAYS
WHERE id = 6
RETURNING remaining_days($j) AS Expires;Unterschiede hinsichtlich der Abfragesprache in der Cloud
Die Abfrageunterstützung für den Cloud-Service unterscheidet sich von der Angabe in der Referenzdokumentation zur Abfragesprachen wie folgt:
Einschränkungen für in der SELECT-Klausel verwendete Ausdrücke
Oracle NoSQL Database Cloud Service unterstützt das Gruppieren von Ausdrücken oder arithmetischen Ausdrücken in Aggregatfunktionen. In der SELECT-Klausel sind keine anderen Arten von Ausdrücken zulässig. Beispiel: CASE-Ausdrücke sind in der SELECT-Klausel nicht zulässig.
Jeder NoSQL-Datenbanktreiber stellt eine API zum Ausführen einer Abfrageanweisung bereit.
Abfrageplanreferenz
Ein Abfrageausführungsplan ist die Abfolge der Vorgänge, die Oracle NoSQL Database zur Ausführung einer Abfrage ausführt.
Ein Abfrageausführungsplan ist ein Baum aus Planiteratoren. Jede Art von Iterator wertet eine andere Art von Ausdruck aus, die in einer Abfrage angezeigt werden kann. Im Allgemeinen kann sich die Wahl des Index und der Art der zugehörigen Indexprädikate drastisch auf die Abfrageperformance auswirken. Infolgedessen möchten Sie als Benutzer oft sehen, welcher Index von einer Abfrage verwendet wird und welche Prädikate an ihn weitergegeben wurden. Auf der Grundlage dieser Informationen können Sie die Verwendung eines anderen Index über Indexhinweise erzwingen. Diese Informationen sind im Ausführungsplan der Abfrage enthalten. . Alle Oracle NoSQL-Treiber stellen APIs zur Anzeige des Ausführungsplans einer Abfrage bereit.
Einige der häufigsten und wichtigsten Iteratoren, die in Abfragen verwendet werden:
TABLE-Iterator: Ein Tabellen-Iterator ist verantwortlich für:
- Der von der Abfrage verwendete Index (der primäre Index) wird durchsucht.
- An den Index übergebene Filterprädikate anwenden
- Rufen Sie bei Bedarf die Zeilen ab, auf die durch die qualifizierenden Indexeinträge verwiesen wird. Wenn der Index abdeckt, ist die Ergebnismenge des TABLE-Iterators eine Gruppe von Indexeinträgen. Andernfalls handelt es sich um eine Gruppe von Tabellenzeilen.
Hinweis: Ein Index wird als Deckungsindex für eine Abfrage bezeichnet, wenn die Abfrage nur mit den Einträgen dieses Index ausgewertet werden kann, d.h. ohne dass die zugehörigen Zeilen abgerufen werden müssen.
SELECT-Iterator: Er ist für die Ausführung des SELECT-Ausdrucks verantwortlich.
Jede Abfrage enthält eine SELECT-Klausel. Daher hat jeder Abfrageplan einen SELECT-Iterator. Ein SELECT-Iterator hat die folgende Struktur:
"iterator kind" : "SELECT",
"FROM" :
{
},
"FROM variable" : "...",
"SELECT expressions" :
[
{
}
]Der SELECT-Iterator enthält Felder wie "FROM", "WHERE", "FROM-Variable" und "SELECT-Ausdrücke". "FROM" und "FROM-Variable" stellen die FROM-Klausel des SELECT-Ausdrucks dar, WHERE die Filterklausel und "SELECT-Ausdruck" die SELECT-Klausel.
RECEIVE-Iterator: Es handelt sich um ein spezielles internes Iterator, das den Abfrageplan in 2 Teile unterteilt:
-
Der RECEIVE-Iterator selbst und alle Iteratoren, die sich darüber im Iteratorbaum befinden, werden am Treiber ausgeführt.
-
Alle Iteratoren unter dem RECEIVE-Iterator werden auf den Replikationsknoten (RNs) ausgeführt. Diese Iteratoren bilden einen Unterbaum, der auf dem eindeutigen untergeordneten Element des RECEIVE-Iterators verwurzelt ist.
Im Allgemeinen fungiert der RECEIVE-Iterator als Abfragekoordinator. Er sendet seinen Unterplan an die entsprechenden RNs zur Ausführung und sammelt die Ergebnisse. Es kann zusätzliche Operationen wie die Sortierung und doppelte Eliminierung ausführen und die Ergebnisse zur weiteren Verarbeitung an seine Vorgänger-Iteratoren (sofern vorhanden) weitergeben.
Verteilungsarten:
Eine Verteilungsart gibt an, wie die Abfrage zur Ausführung auf die RNs verteilt wird, die an einer Oracle NoSQL-Datenbank (einem Speicher) teilnehmen. Die Verteilungsart ist eine Eigenschaft des RECEIVE-Iterators.
Verschiedene Optionen für die Verteilung sind:
- SINGLE_PARTITION: Eine SINGLE_PARTITION-Abfrage gibt einen vollständigen Shard-Schlüssel in der WHERE-Klausel an. Infolgedessen ist die gesamte Ergebnismenge in einer einzelnen Partition enthalten, und der RECEIVE-Iterator sendet seinen Unterplan an eine einzelne RN, die diese Partition speichert. Eine SINGLE_PARTITION-Abfrage kann entweder den Primärschlüsselindex oder einen Sekundärindex verwenden.
- ALL_PARTITIONS: Abfragen verwenden hier den Primärschlüsselindex, und sie geben keinen vollständigen Shard-Schlüssel an. Wenn der Speicher also M-Partitionen hat, sendet der RECEIVE-Iterator M-Kopien seines Unterplans, die über jeweils eine der M-Partitionen ausgeführt werden.
- ALL_SHARDS: Abfragen verwenden hier einen sekundären Index, und sie geben keinen vollständigen Shard-Schlüssel an. Wenn der Speicher also über N-Shards verfügt, sendet der RECEIVE-Iterator N-Kopien seines Unterplans, die über jeweils einen der N-Shards ausgeführt werden.
Anatomie eines Abfrageausführungsplans:
Die Abfrageausführung erfolgt in Batches. Wenn ein Abfrageunterplan zur Ausführung an eine Partition oder ein Shard gesendet wird, wird er dort ausgeführt, bis ein Batchlimit erreicht ist. Das Batchlimit ist eine Anzahl von Leseeinheiten, die lokal von der Abfrage verbraucht werden. Der Standardwert ist 2000 Leseeinheiten (ca. 2 MB Daten) und kann nur über eine Option auf Abfrageebene verringert werden.
Wenn das Batch-Limit erreicht ist, werden alle erzeugten lokalen Ergebnisse zur weiteren Verarbeitung an den RECEIVE-Iterator zurückgesendet, zusammen mit einem booleschen Flag, das angibt, ob weitere lokale Ergebnisse verfügbar sein können. Bei 'Wahr' enthält die Antwort Informationen zum Lebenslauf. Wenn der RECEIVE-Iterator beschließt, die Abfrage erneut an dieselbe Partition/ denselben Shard zu senden, enthält er diese Lebenslaufinformationen in seine Anforderung, sodass die Abfrageausführung an dem Punkt neu gestartet wird, an dem sie während des vorherigen Batches gestoppt wurde. Dies liegt daran, dass nach Beendigung eines Batches kein Abfragestatus in der RN verwaltet wird. Der nächste Batch für dieselbe Partition/dieses Shard kann an derselben RN wie der vorherige Batch oder an einer anderen RN erfolgen, die auch dieselbe Partition/dieses Shard speichert.