Mit OKE die Datenlokalität für Cassandra- und Spark-Aktivitäten verbessern
Einführung
Apache Cassandra ist eine verteilte Masterless-Datenbank, in der jeder Knoten über Tokenbereiche verfügt. Apache Spark ist eine verteilte Compute-Engine, die den Spark-Cassandra-Connector zum Lesen aus Cassandra-Replikaten verwenden kann. In Kubernetes werden Pods geplant, ohne zu wissen, wo sich die Daten befinden, sodass die Datenlokalität nicht garantiert ist.
In diesem Tutorial wird gezeigt, wie OKE die Lokalität mit Kubernetes-Primitiven verbessern kann: StatefulSets (stabile Identität für Cassandra), Knotenlabels und Affinität/Anti-Affinität, um Spark-Executors mit Cassandra-Pods gemeinsam zu lokalisieren. Daher werden Lesevorgänge von demselben Knoten (ideal) oder im schlimmsten Fall von einem Hop zum Co-Location-Replikat verarbeitet.
Ziele
- Stellen Sie ein OKE-Cluster mit 3 Knoten und eine Bastion (ORM oder Terraform) bereit.
- Co-Location Cassandra und Spark auf zwei Knoten mit Labels + Affinität.
- Führen Sie einen Spark-Lesejob für Cassandra aus, und prüfen Sie ihn.
- Beobachten Sie knotenübergreifenden Traffic mit VCN-Flowlogs.
Voraussetzungen
- OCI-Mandant mit Berechtigungen für VCN, OKE, Compute, Logging (Flowlogs); optionales Monitoring.
- SSH-Schlüsselpaar für Bastionzugriff.
- Grundlegende Kubernetes-Kenntnisse (Knoten, Labels, Pods usw.).
Aufgabe 1: Umgebung mit OCI Resource Manager (ORM) bereitstellen (empfohlen).
-
Klicken Sie unten, um den Stack in der OCI-Konsole zu öffnen:

-
Folgen Sie dem geführten Ablauf:
-
Akzeptieren Sie die Nutzungsbedingungen.
-
Fügen Sie einen SSH-Schlüssel ein, und wählen Sie die Availability-Domain aus.
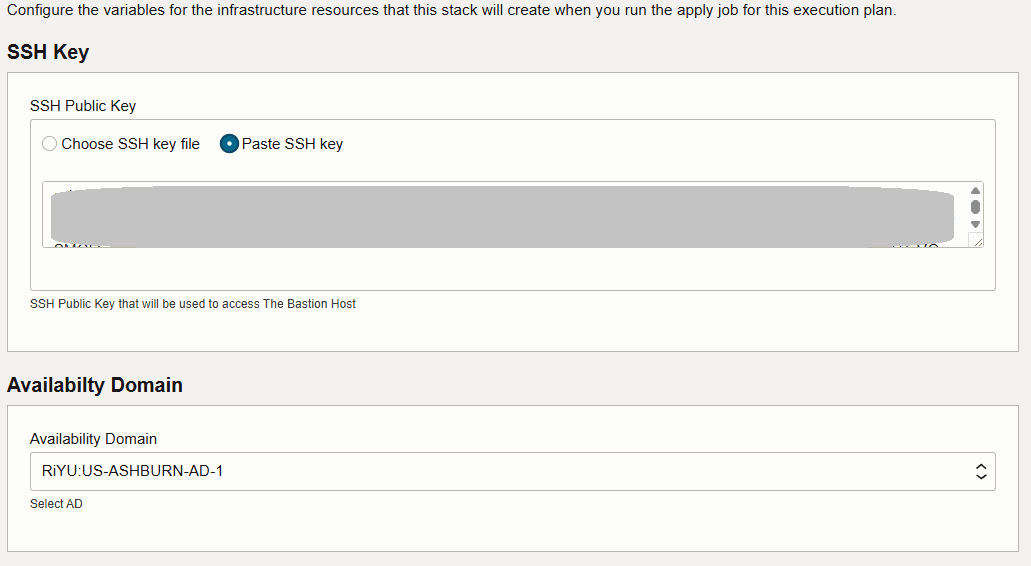
-
Sie können den Rest der Werte als Standard beibehalten, um ein VCN, ein OKE-Cluster und eine Bastion bereitzustellen.
-
Stack starten.
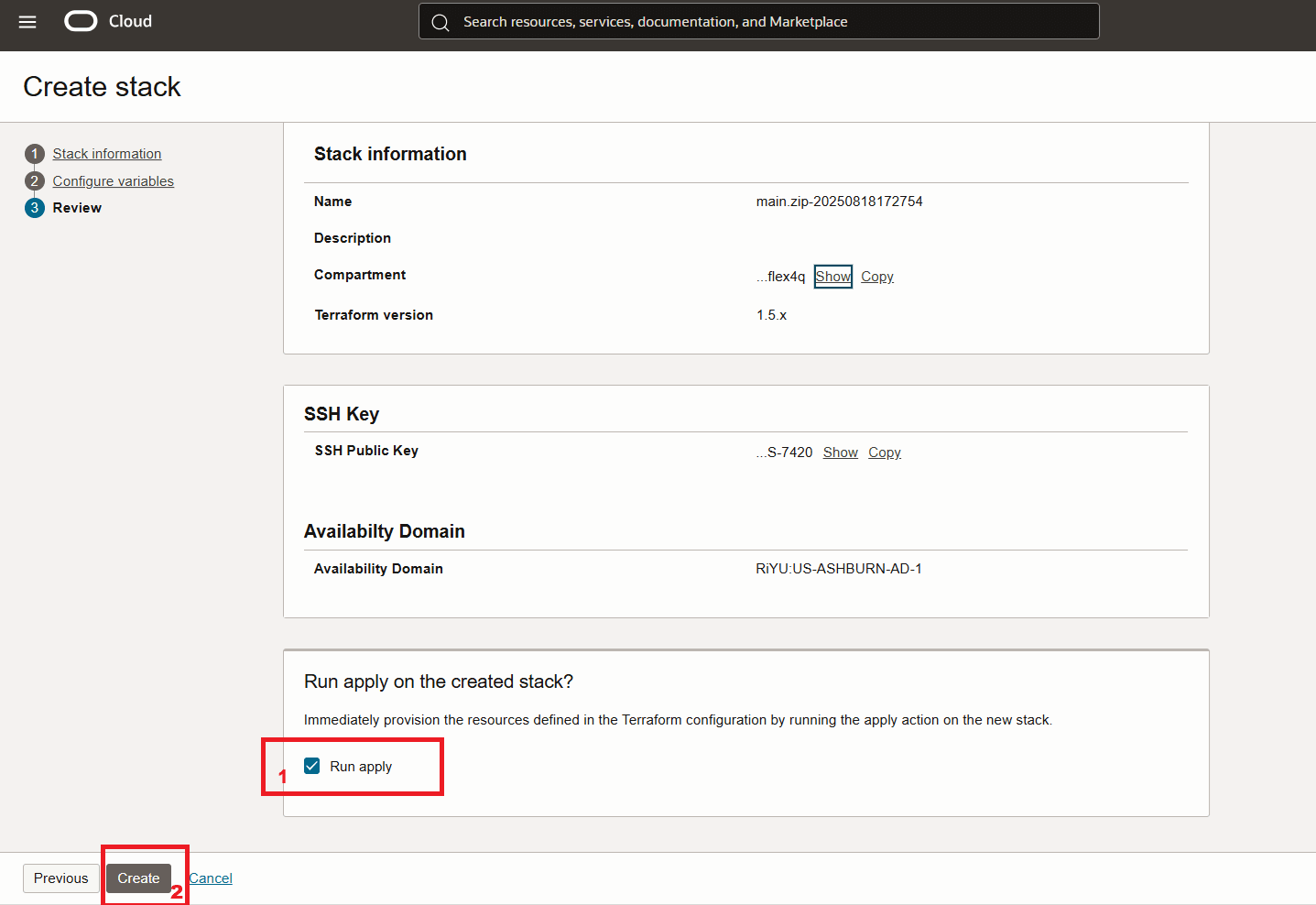
-
Nachdem der Stack abgeschlossen ist, erhalten Sie die IP der Bastion im Ausgabeabschnitt.
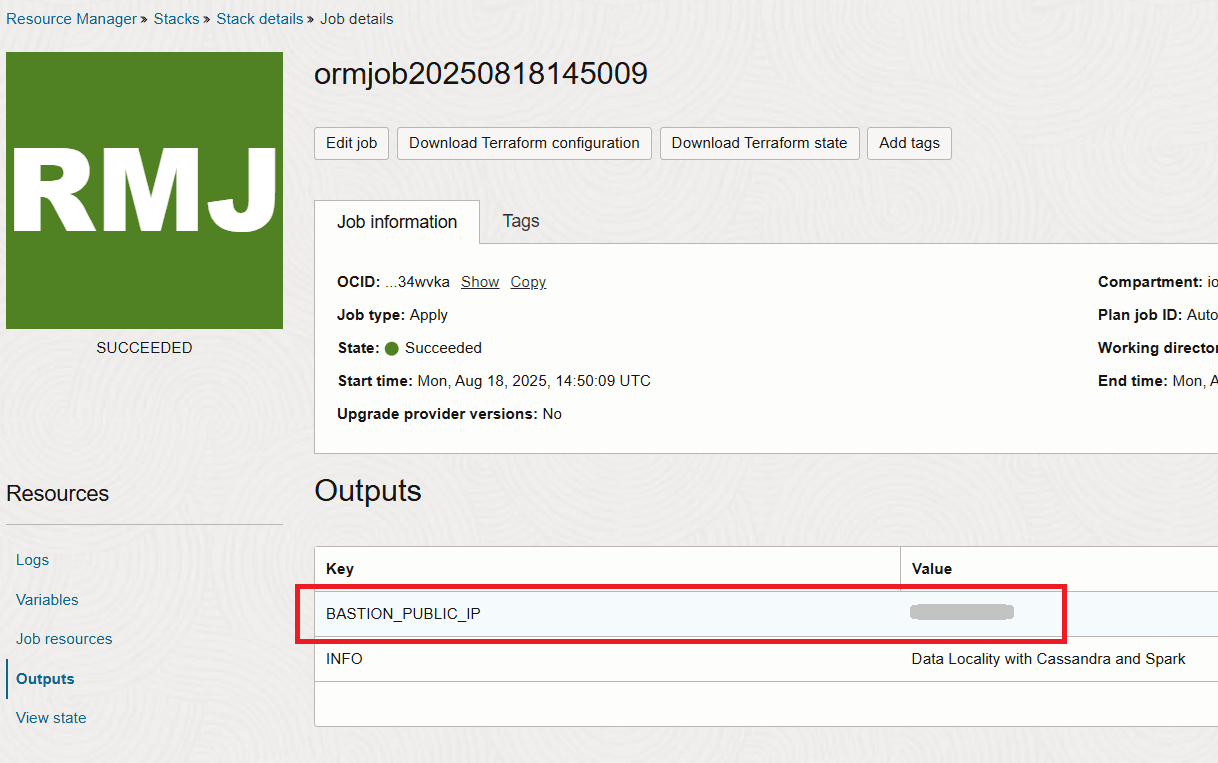
Aufgabe 2: Verbindung zur Bastion herstellen und Deployment prüfen
Das anfängliche Infrastruktur-Provisioning wird innerhalb von etwa 15 Minuten abgeschlossen. Das vollständige Setup (über Cloud-Init auf der Bastion) dauert jedoch etwa 20 Minuten, um Helm zu installieren, Cassandra und Spark bereitzustellen und den Lesejob auszuführen.
-
So überwachen Sie den Prozess mit SSH in die Bastion:
ssh -i <path-to-private-key> opc@<bastion_public_ip> -
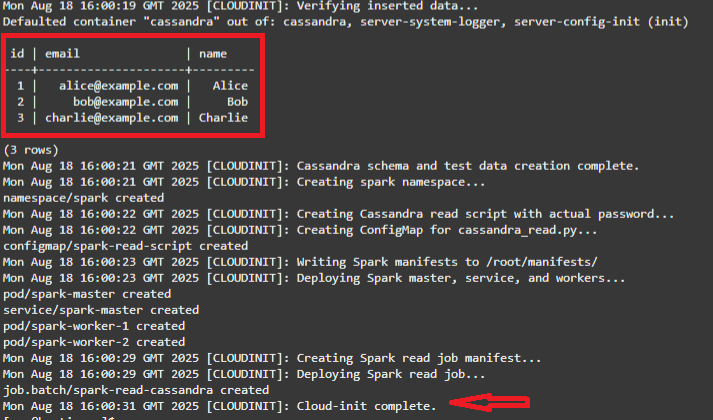
Führen Sie den folgenden Befehl aus, um den Fortschritt des cloudinit-Skripts zu überwachen.
tail -f /var/log/oke-automation.log -
Der Stack wird abgeschlossen, wenn die 3 vordefinierten Cassandra-Werte gelesen werden und die Meldung Cloud-Init abgeschlossen angezeigt wird.
Hinweis: Das cloudinit-Skript hat folgende Aktionen ausgeführt:
- Installieren Sie kubectl, Helm, OCI-CLI (Instanz-Principals), und rufen Sie kubeconfig ab.
- Auf Mitarbeiter warten
- Beschriften Sie die ersten beiden Knoten mit:
spark-locality=true, data-locality=enabled, and node-role=zone-a/zone-b - Installieren Sie cert-manager und k8ssandra-operator (CRDs)
- Anwenden von K8ssandraCluster
- Warten auf Cassandra
- Erstellen Sie testks.users, und fügen Sie 3 Zeilen ein
- Spark-Namespace erstellen. ConfigMap mit /scripts/cassandra_read.py erstellen (lesen Sie testks.users)
- Stellen Sie Spark Master, Service und zwei Worker bereit (nodeSelector spark-locality: "true", Anti-Affinität von Mitarbeitern)
- Job weiterleiten spark-read-cassandra
-
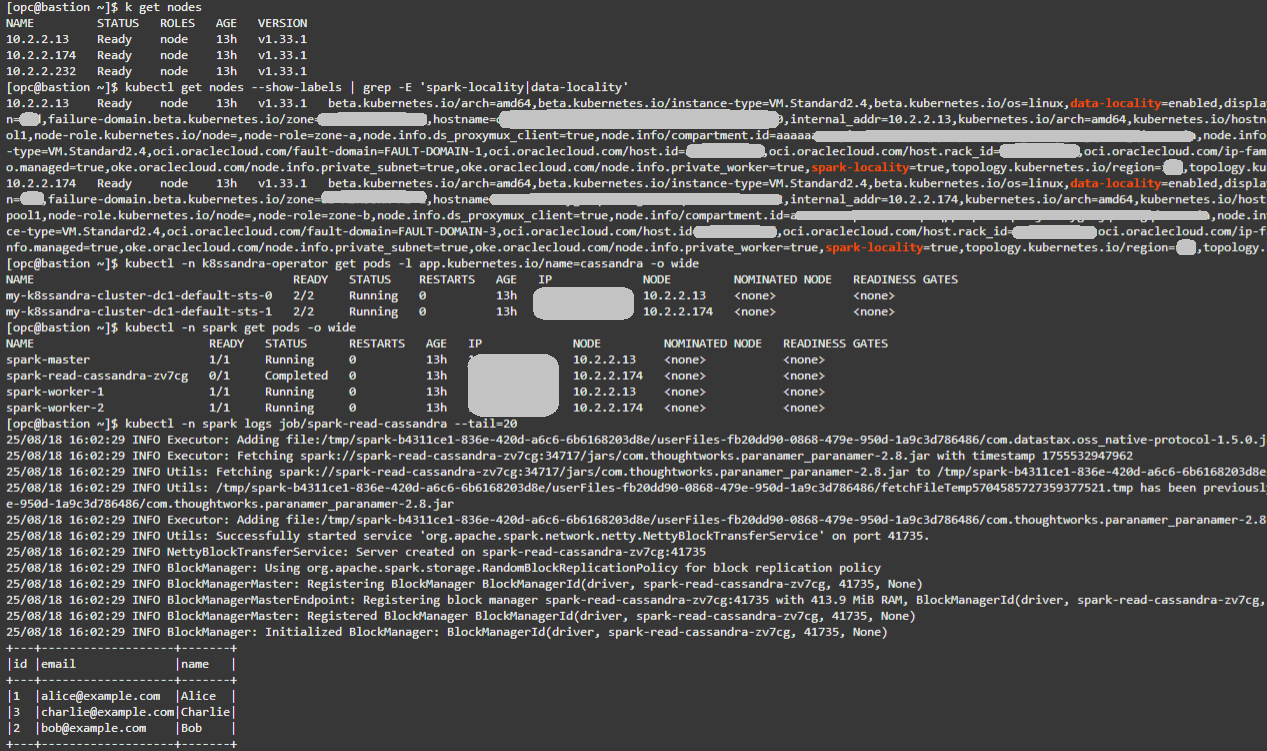
Bestätigen Sie über die Bastion-VM die vorhandenen Knoten:
kubectl get nodes -
Bestätigen Sie die Ortsbeschriftungen. Erwarten Sie zwei Knoten mit spark-locality=true und data-locality=enabled.
kubectl get nodes --show-labels | grep -E 'spark-locality|data-locality' -
Cassandra-Platzierung überprüfen:
kubectl -n k8ssandra-operator get pods -l app.kubernetes.io/name=cassandra -o wide -
Spark-Platzierung prüfen:
kubectl -n spark get pods -o wide -
Prüfen Sie die Spark-Lesejoblogs. Die 3 Datensätze aus testks.users und eine erfolgreiche Ausführung sollten angezeigt werden.
kubectl -n spark logs job/spark-read-cassandra --tail=20
Tipp: Der Abgleich von NODE-Werten in Cassandra- und Spark-Pods bestätigt den Co-Standort und die idealen Bedingungen für die Lokalität. Für aussagekräftigere Ablauflogergebnisse fügen Sie zusätzliche Zeilen mit cqlsh in testks.users ein. Größere Datensätze generieren mehr Leseverkehr, wodurch Lokalität vs. Nicht-Standort-Effekte einfacher zu beobachten sind.
Im Folgenden sehen Sie eine Beispielausgabe für die oben genannten Befehle:
Aufgabe 3: Netzwerkeffekte mit VCN-Flowlogs beobachten
Verwenden Sie VCN-Flowlogs, um zu verstehen, wo Cassandra-Traffic während Spark-Lesevorgängen fließt. Die aktuelle Automatisierung verwendet Flannel (VXLAN), was sich auf die Anzeige von Flowlogs auswirkt.
Was ändert sich mit dem CNI?
- Flanell (VXLAN, dieses Labor):
- Podtraffic mit gleichem Knoten bleibt auf der Hostbrücke → kein VCN-Flowlogeintrag.
- Podtraffic zwischen Knoten wird als UDP
(VXLAN) gekapselt. Standardmäßig verwendet Flannel Port 8472, aber wenn dieser Port nicht verfügbar ist, kann er einen anderen hohen UDP-Port auswählen. Der genaue Port kann je nach Deployment variieren.
- VCN-natives Podnetwork (NPN):
- Pods erhalten VCN-IPs, und Traffic wird ohne Overlay an L3 weitergeleitet.
- Flowlogs zeigen die realen Anwendungsports (für Cassandra: TCP 9042).
-
Aktivieren Sie Flowlogs im Worker-Subnetz.
Aktivieren Sie in der OCI-Konsole Flowlogs für das OKE-Workersubnetz. Führen Sie den Spark-Lesejob erneut aus (oder warten Sie darauf), um Traffic zu generieren.
-
Abfrageflusslogs (wählen Sie den Pfad aus, der mit Ihrem Cluster übereinstimmt)
Bei Verwendung dieser Automatisierung (Flannel/VXLAN): Verwenden Sie eine erweiterte Abfrage ähnlich der folgenden:
search "<your-flow-log-OCID>"
| where data.protocolName = 'UDP'
| where data.destinationPort = <vxlan-port>
Ersetzen Sie
- Pod-zu-Pod-Traffic wird in UDP
zwischen Worker-Knoten-IPs (anstelle des Cassandra-Ports 9042) gekapselt. - Lesevorgänge auf demselben Knoten: kein VCN-Flowlogeintrag (Traffic bleibt lokal).
- Knotenübergreifende Lesevorgänge: sichtbar, wenn UDP 14789 zwischen Worker-Knoten-IPs in der folgenden Abbildung fließt.
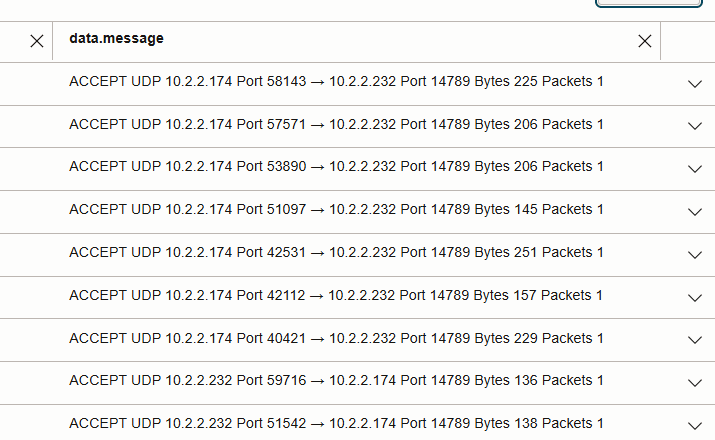
- Der Vergleich der Paketanzahl mit UDP 14789 hebt den Effekt der Datenlokalität im Vergleich zur Nichtlokalität hervor.
Wenn Ihr Cluster NPN verwendet:
- Filtern Sie direkt nach TCP dstPort = 9042 zwischen Pod-/Worker-IPs.
- Cassandra CQL liest/schreibt als 9042 Flows. (idealerweise sehr wenig)
Hinweis: Die Aufnahme neuer Einträge in Flowlogs kann einige Minuten dauern.
Wichtige Überlegungen
-
Cluster mit >3 Knoten:
Die Lokalität ist wichtiger, wenn die Clustergröße wächst. Ohne Platzierungsregeln können Spark Executors auf Knoten ohne lokale Replikate ausgeführt werden, was zu vielen Remote-Lesevorgängen führt. Durch Co-Location wird sichergestellt, dass Lesevorgänge entweder lokal oder im schlimmsten Fall ein einzelner Hop zu einem anderen Replikat sind.
- Leistungsgewinne durch Co-Location:
- Zero-Hop-Lesevorgänge → geringste Latenz.
- Weniger knotenübergreifende Lesevorgänge → geringere Bandbreitennutzung und geringere Zugriffskonflikte.
- Höherer Durchsatz für Spark-Jobs, die Cassandra parallel lesen.
- In dieser Automatisierung verwendete Mechanismen:
- StatefulSets → stabile Cassandra-Pod-Identitäten.
- Knotenlabels (
spark-locality,data-locality) → geben Knoten für Co-Location an. - Podaffinität/Antiaffinität → Spark Executors, die auf Cassandra-Knoten geplant sind und über sie verteilt sind.
- K8ssandra Operator → deklaratives Cassandra Deployment und Management.
- ConfigMap + Spark-Job → validiert Cassandra-Lesevorgänge und generiert Traffic.
- VCN-Flowlogs → beobachten und bestätigen Lokalitätseffekte.
- Nicht im Geltungsbereich von OKE (Faktoren auf Anwendungsebene):
- Spark-Aufgabenplanung und Partitionszuweisung.
- Cassandra-Replikationsfaktor und Konsistenzebene.
- Spark-Cassandra-Connector-Logik zur Auswahl von Replikaten.
Verwandte Links
Links zu weiteren Ressourcen bereitstellen. Dieser Abschnitt ist optional. Löschen, falls nicht erforderlich.
Bestätigungen
- Autoren - Adina Nicolescu (Principal Cloud Architect)
Weitere Lernressourcen
Sehen Sie sich weitere Übungen zu docs.oracle.com/learn an, oder greifen Sie auf weitere kostenlose Lerninhalte im Oracle Learning YouTube-Kanal zu. Besuchen Sie außerdem education.oracle.com/learning-explorer, um ein Oracle Learning Explorer zu werden.
Die Produktdokumentation finden Sie im Oracle Help Center.
Use OKE to Improve Data Locality for Cassandra and Spark Activity
G53296-01