In Spark, Object Storage connectivity is used for performing queries on database hosted in Object Storage using spark-sql, spark-shell, spark-submit, and so on.
Prerequisites:
- The Hadoop user in the cluster must be part of the Spark group.
On Linux:
id bdsuser
uid=54330(bdsuser) gid=54339(superbdsgroup) groups=54339(superbdsgroup,985(hadoop),984(hdfs),980(hive),977(spark)
In Ranger:

In Ranger, access the Users tab and verify in the Groups column that the user is part of the Spark group.
- Spark and Hadoop user must be added to the following policies in Ranger.
tag.download.auth.userspolicies.download.auth.users
To verify, in the Ranger UI, select Access Manager > Resource Based Policies, and then select edit button for the Spark instance. The Config Properties window is displayed.
Example:
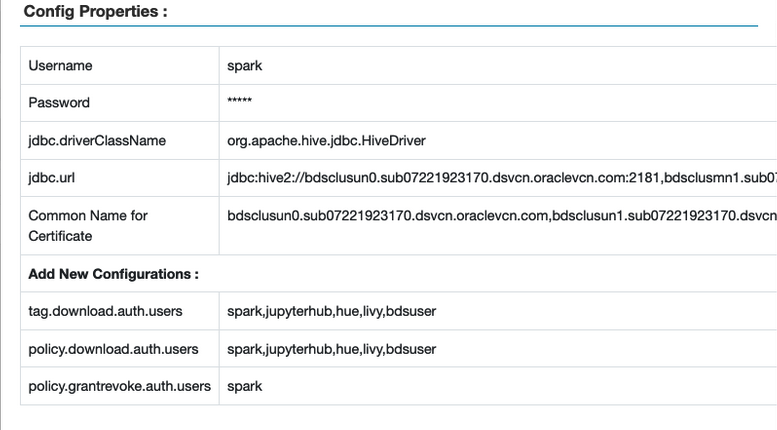
- Be sure the Hadoop user is added to
all - database, table, column policy to provide SELECT privilege on database, table, columns. To verify:
- In the Ranger UI select Access Manager > Resource Based Policies, and then select the SPARK3 repo.
- Select the policies created for the user.
- Select all - database, table, column, and then select Edit.
- Under Allow conditions section, verify the Hadoop user is listed, if not, add the user.
Note
You can use Big Data Service cluster nodes for service configuration and running examples. To use an Edge node, you must create and sign in to the Edge node.
- (Optional)
To use an Edge node for setting up Object Storage, first create an Edge node, and then sign in to the node. Then, copy the API key from the un0 node to the Edge node.
sudo dcli rsync -a <un0-hostname>:/opt/oracle/bds/.oci_oos/ /opt/oracle/bds/.oci_oos/
-
Create a user with sufficient permissions and a JCEKS file with the required passphrase value. If you're creating a local JCEKS file, copy the file to all nodes and change user permissions.
sudo dcli -f <location_of_jceks_file> -d <location_of_jceks_file>
sudo dcli chown <user>:<group> <location_of_jceks_file>
-
Add either of the following
HADOOP_OPTS combinations to the user bash profile.
Option 1:
export HADOOP_OPTS="$HADOOP_OPTS -DOCI_SECRET_API_KEY_ALIAS=<api_key_alias>
-DBDS_OSS_CLIENT_REGION=<api_key_region> -DOCI_SECRET_API_KEY_PASSPHRASE=<jceks_file_provider>"
Option 2:
export HADOOP_OPTS="$HADOOP_OPTS -DBDS_OSS_CLIENT_AUTH_FINGERPRINT=<api_key_fingerprint>
-DBDS_OSS_CLIENT_AUTH_PASSPHRASE=<jceks_file_provider> -DBDS_OSS_CLIENT_AUTH_PEMFILEPATH=<api_key_pem_file_path>
-DBDS_OSS_CLIENT_AUTH_TENANTID=<api_key_tenant_id> -DBDS_OSS_CLIENT_AUTH_USERID=<api_key_user_id> -DBDS_OSS_CLIENT_REGION=<api_key_region>"
-
In Ambari, add the Hadoop options to the hive-env template for Object Storage access.
-
Access Apache Ambari.
-
From the side toolbar, under Services select Hive.
-
Select Configs.
-
Selectg Advanced.
-
In the Performance section, go to Advanced hive-env.
-
Go to hive-env template, and then add one of the following options under the line
if [ "$SERVICE" = "metastore" ]; then.
Option 1:
export HADOOP_OPTS="$HADOOP_OPTS -DOCI_SECRET_API_KEY_ALIAS=<api_key_alias>
-DBDS_OSS_CLIENT_REGION=<api_key_region>
-DOCI_SECRET_API_KEY_PASSPHRASE=<jceks_file_provider>"
Option 2:
export HADOOP_OPTS="$HADOOP_OPTS -DBDS_OSS_CLIENT_AUTH_FINGERPRINT=<api_key_fingerprint>
-DBDS_OSS_CLIENT_AUTH_PASSPHRASE=<jceks_file_provider> -DBDS_OSS_CLIENT_AUTH_PEMFILEPATH=<api_key_pem_file_path>
-DBDS_OSS_CLIENT_AUTH_TENANTID=<api_key_tenant_id> -DBDS_OSS_CLIENT_AUTH_USERID=<api_key_user_id>
-DBDS_OSS_CLIENT_REGION=<api_key_region>"
-
Restart all required services through Ambari.
-
Run one of the following example commands to launch the spark SQL shell:
Example 1:
spark-sql --conf spark.driver.extraJavaOptions="${HADOOP_OPTS}" --conf spark.executor.extraJavaOptions="${HADOOP_OPTS}"
Example 2: Using the API key alias and passphrase.
spark-sql --conf spark.hadoop.OCI_SECRET_API_KEY_PASSPHRASE=<api_key_passphrase>
--conf spark.hadoop.OCI_SECRET_API_KEY_ALIAS=<api_key_alias>
--conf spark.hadoop.BDS_OSS_CLIENT_REGION=<api_key_region>
Example 3: Using IAM Service API Key parameters.
spark-sql --conf spark.hadoop.BDS_OSS_CLIENT_AUTH_USERID=<api_key_user_id>
--conf spark.hadoop.BDS_OSS_CLIENT_AUTH_TENANTID=<api_key_tenant_id>
--conf spark.hadoop.BDS_OSS_CLIENT_AUTH_FINGERPRINT=<api_key_fingerprint>
--conf spark.hadoop.BDS_OSS_CLIENT_AUTH_PEMFILEPATH=<api_key_pem_file_path>>
--conf spark.hadoop.BDS_OSS_CLIENT_REGION=<api_key_region> --conf spark.hadoop.BDS_OSS_CLIENT_AUTH_PASSPHRASE=<api_key_passphrase>
Note If there's any issue with Java heap space, pass the driver and executor memory as part of Spark SQL. For example.
--driver-memory 2g –executor-memory 4g. Example spark-sql statement:
spark-sql --conf spark.driver.extraJavaOptions="${HADOOP_OPTS}"
--conf spark.executor.extraJavaOptions="${HADOOP_OPTS}"
--driver-memory 2g --executor-memory 4g
-
Verify Object Storage connectivity:
Example for Managed Table:
CREATE DATABASE IF NOT EXISTS <database_name> LOCATION 'oci://<bucket-name>@<namespace>/';
USE <database_name>;
CREATE TABLE IF NOT EXISTS <table_name> (id int, name string) partitioned by (part int, part2 int) STORED AS parquet;
INSERT INTO <table_name> partition(part=1, part2=1) values (333, 'Object Storage Testing with Spark SQL Managed Table');
SELECT * from <table_name>;
Example for External Table:
CREATE DATABASE IF NOT EXISTS <database_name> LOCATION 'oci://<bucket-name>@<namespace>/';
USE <database_name>;
CREATE EXTERNAL TABLE IF NOT EXISTS <table_name> (id int, name string) partitioned by (part int, part2 int) STORED AS parquet LOCATION 'oci://<bucket-name>@<namespace>/';
INSERT INTO <table_name> partition(part=1, part2=1) values (999, 'Object Storage Testing with Spark SQL External Table');
SELECT * from <table_name>;
- (Optional)
Use
pyspark with spark-submit with Object Storage.
Note
Create the database and table before performing these steps.
-
Run the following:
from pyspark.sql import SparkSession
import datetime
import random
import string
spark=SparkSession.builder.appName("object-storage-testing-spark-submit").config("spark.hadoop.OCI_SECRET_API_KEY_PASSPHRASE","<jceks-provider>").config("spark.hadoop.OCI_SECRET_API_KEY_ALIAS",
"<api_key_alias>").enableHiveSupport().getOrCreate()
execution_time = datetime.datetime.now().strftime("%m/%d/%Y, %H:%M:%S")
param1 = 12345
param2 = ''.join(random.choices(string.ascii_uppercase + string.digits, k = 8))
ins_query = "INSERT INTO <database_name>.<table_name> partition(part=1, part2=1) values ({},'{}')".format(param1,param2)
print("##################### Starting execution ##################" + execution_time)
print("query = " + ins_query)
spark.sql(ins_query).show()
spark.sql("select * from <database_name>.<table_name>").show()
print("##################### Execution finished #################")
-
Run the following command from
/usr/lib/spark/bin:
./spark-submit --conf spark.driver.extraJavaOptions="${HADOOP_OPTS}" --conf spark.executor.extraJavaOptions="${HADOOP_OPTS}" <location_of_python_file>