Developing Data Flow Applications
Learn about the Library , including reusable Spark application templates and application security. Also learn how to create and view applications, edit applications, delete applications, and apply arguments or parameters.
- When Creating Applications using the Console
- Under Advanced Options, specify the duration in Max run duration minutes.
- When Creating Applications using the CLI
- Pass command line option of
--max-duration-in-minutes <number> - When Creating Applications using the SDK
- Provide optional argument
max_duration_in_minutes - When Creating Applications using the API
- Set the optional argument
maxDurationInMinutes
Reusable Spark Application Templates
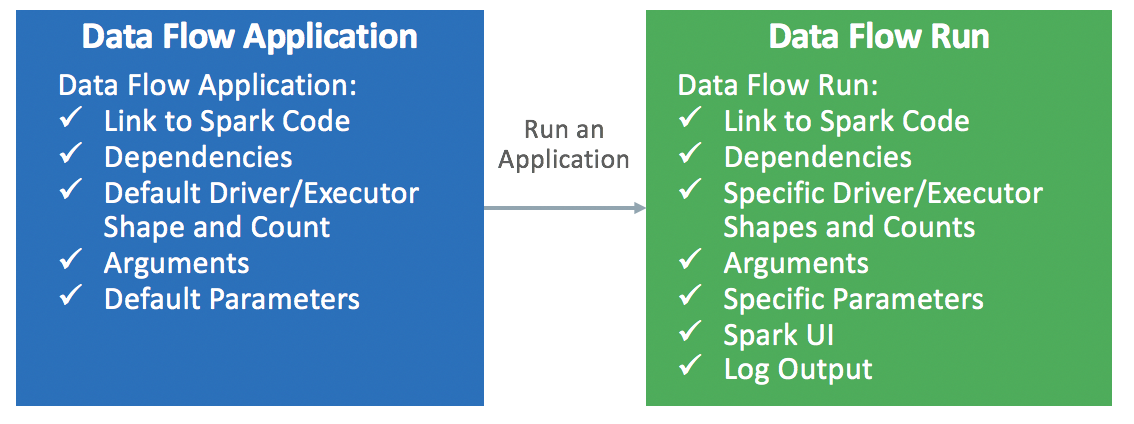
An Application is an infinitely reusable Spark application template.
Data Flow Applications consist of a Spark application, its
dependencies, default parameters, and a default runtime resource specification. After a
Spark developer creates a Data Flow Application, anyone
can use it without worrying about the complexities of deploying it, setting it up, or
running it. You can use it through Spark analytics in custom dashboards, reports,
scripts, or REST API calls. 
Every time you invoke the Data Flow Application, you create a
Run . It fills in the details of the
application template and starts it on a specific set of IaaS resources.