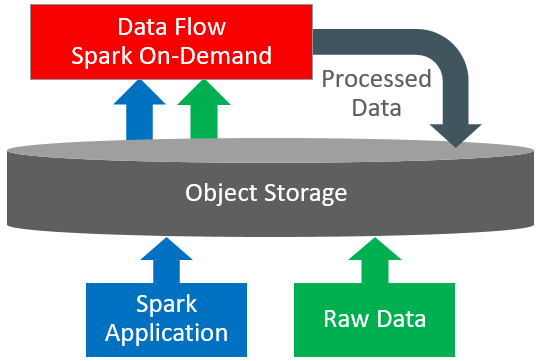
Data Flow Overview
Learn about Data Flow and how you can use it to easily create, share, run, and view the output of Apache Spark applications.
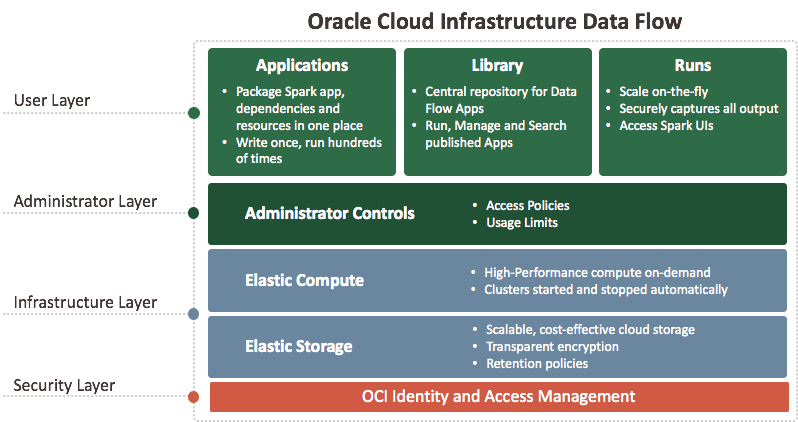
What is Oracle Cloud Infrastructure Data Flow
Data Flow is a cloud-based serverless platform with a rich user interface. It allows Spark developers and data scientists to create, edit, and run Spark jobs at any scale without the need for clusters, an operations team, or highly specialized Spark knowledge. Being serverless means there is no infrastructure for you to deploy or manage. It is entirely driven by REST APIs, giving you easy integration with applications or workflows. You can control Data Flow using this REST API. You can run Data Flow from the CLI as Data Flow commands are available as part of the Oracle Cloud Infrastructure Command Line Interface. You can:
-
Connect to Apache Spark data sources.
-
Create reusable Apache Spark applications.
-
Launch Apache Spark jobs quickly.
-
Create Apache Spark applications using SQL, Python, Java, Scala, or spark-submit.
-
Manage all Apache Spark applications from a single platform.
-
Process data in the Cloud or on-premises in your data center.
-
Create Big Data building blocks that you can easily assemble into advanced Big Data applications.