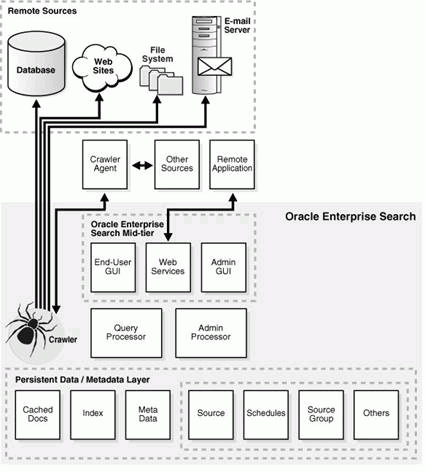
Configuring SES for Text Search
Component |
Description |
|---|---|
Crawler |
The SES Crawler is a Java process activated by your Oracle server according to a set schedule. When activated, the crawler spawns a configurable number of processor threads that fetch documents from various data sources. The crawler maps link relationships and analyzes them to avoid going in circles and taking wrong turns. Whenever the crawler encounters embedded, non-HTML documents during the crawling it uses filters to automatically detect the document type and to filter and index the document. |
Database |
An Oracle11g database contains the SES-repository, which stores information about the repositories indexed by SES and the search engine index (information collected by the crawler, filtered and indexed by Oracle11g Text). |
Search UI & API |
SES provides an out-of-the-box user interface to the Server. It also provides a web services API for building custom applications for querying indexed data, and contains interfaces for Basic Search Form, Advanced Search Form, Query Result Display, URL registration, authentication and authorization, and so on. |
Administration Tool and Interface |
The SES administration tool is a browser-based application that you use to configure and schedule the crawler, configure the server, run several reporting features, and other similar tasks. |
Federator |
Via the Suggested Content feature, SES also provides the ability to federate queries to other engines that implement their own search mail servers, Internet search engines, and specific applications. Additionally, SES provides the ability to federate queries to other SES instances. These results can be combined and displayed together along with those results served off the internal index of SES Server. |