How JD Edwards EnterpriseOne Uses Subsystems
Some JD Edwards EnterpriseOne applications are designed to use subsystems to complete needed work. For example, you can instruct Sales Order Processing to print pick slips through a JD Edwards EnterpriseOne subsystem. You activate a subsystem through the processing options of a batch application. Then you create a specific version of the batch application, using that processing option to run the application in subsystem mode.
You must manually start subsystems to minimize the consumption of system resources. When started, JD Edwards EnterpriseOne subsystems run continuously, looking for and processing requests from JD Edwards EnterpriseOne applications. Subsystems run until you terminate them. Subsystems can have much higher throughput than regular batch jobs (for shorter running jobs) because they initialize their user environment and sessions only once. Also, they need to get report specifications from the metadata kernel only once for the duration of their execution.
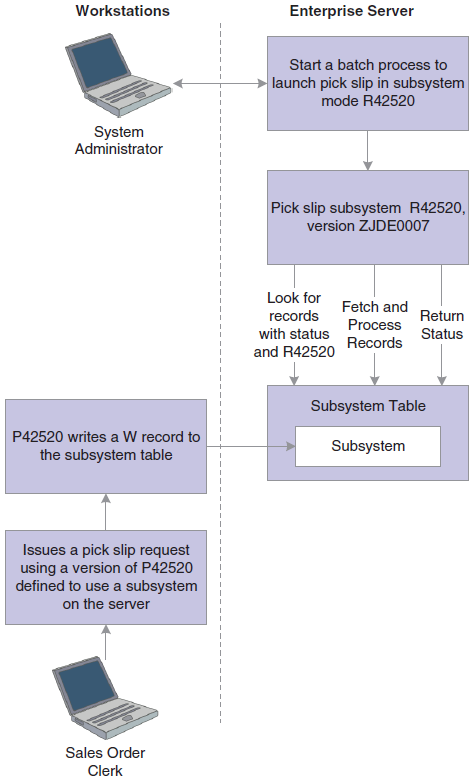
Typically, you use subsystem jobs running on the enterprise server to off load processor resources from the workstation. Instead of queuing requests and running them in batches at specified times of the day, you can direct the requests to a subsystem, where they are processed in real-time. For example, you might be running the Sales Order Entry application on a workstation and want to print pick slips. If you are using a version of pick slips that has the Subsystem Job function enabled, the request is executed by a subsystem job. The pick slip request is routed to and processed by the subsystem job on the defined enterprise server. As a result, no additional processing resources are required from the workstation machine to actually print the pick slip.
When an application issues a request for a job to run in a subsystem, it places a record in the Subsystem Job Master table (F986113). These records are identified by subsystem job name and contain status and operational indicators. Embedded in the record is key information that allows the subsystem to process the record without additional interaction with the requesting application. The continuously running subsystem monitors the records in this table. If the subsystem finds a record with its process ID and appropriate status indicators, it processes the record and updates the status accordingly.
This illustration displays the logical sequence of events associated with subsystems: