Understanding Scheduler Resilience
The scheduler is used to run notifications and orchestrations at designated intervals defined by the schedule attached to each. The scheduler runs as a process on one or more AIS Servers. As notifications and orchestrations are incorporated into critical business processes, the scheduling and execution of those notifications and orchestrations becomes equally critical. The scheduler must be able to tolerate failures, restart with minimum human intervention, and load balance in that if one scheduler instance begins to fall behind, another can pick up the overflow.
Starting a notification or orchestration on a scheduler to run at some interval creates a scheduled job with a set of properties. To make the scheduler resilient, you can store the scheduled job properties for notifications and orchestrations centrally in the database. This means that if you are running a single instance of the scheduler, the scheduler can restart from a failure and continue processing from the queue of scheduled jobs without an administrator having to resubmit all jobs manually. Or if you are running multiple instances of the scheduler, the schedulers can each take scheduled jobs from the queue. If any single instance of a scheduler fails, the other schedulers can proceed independently for continuous operations.
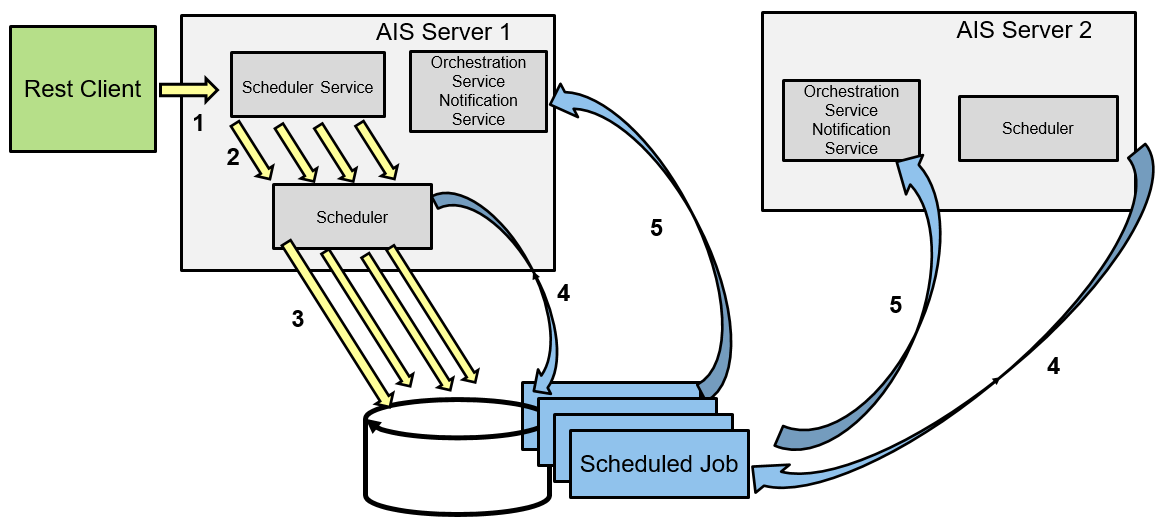
In this graphic, the following steps occur:
The user requests notifications and/or orchestrations to run on their schedule using the scheduler service.
The scheduler service creates a job for each of the notifications and/or orchestrations.
The job definitions are stored in a database.
The scheduler on one of the AIS Servers finds a job to run when that job's scheduled interval is reached.
The job calls a notification or orchestration service.