Understanding Subsystem Jobs
Within Oracle's JD Edwards EnterpriseOne, subsystem jobs are batch processes that continually run independent of, but asynchronously with, JD Edwards EnterpriseOne applications. These subsystem jobs function with the system's logical process or queue defined for the server platform. You can configure JD Edwards EnterpriseOne to use one or more subsystems.
Use subsystem jobs to:
Off-load processor resources.
Protect server processes.
Perform repetitive and frequent processes to maximize output throughput.
Examples of applications that are suited for subsystem processing include:
Logistics Warehousing
Inventory
Sales Order Processing
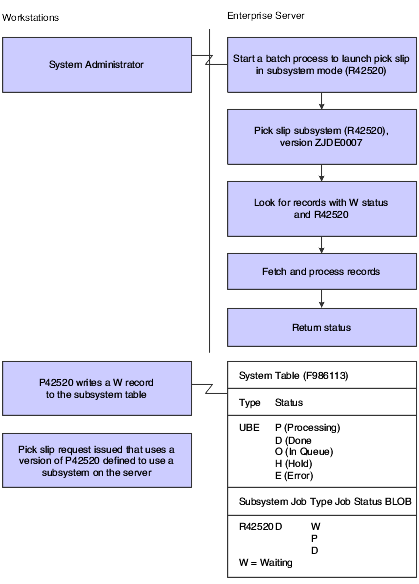
For example, you can execute the Sales Order Entry application on a workstation and automatically print pick slips when all orders are entered. If you are using a version of pick slips that has the subsystem job function enabled, the pick slip request is routed to and processed by the subsystem job on the defined enterprise server. As a result, no additional processing resources are required of the workstation.
When a JD Edwards EnterpriseOne application issues a request for a job to run as a subsystem job, it places a record in the Subsystem Job Master (F986113) table. This record is identified by a subsystem job name and version, and contains status and operational indicators. Embedded in the record is key information that enables the subsystem to process the record without additional interaction with the requesting application. Key information includes the values for the processing options and the values for the report interconnect data structure. The continuously running subsystem monitors this table for records. If the subsystem finds a record with the appropriate status indicators for the specific report and version being run, it processes the record and updates the status accordingly.
This diagram illustrates how the system processes a subsystem job: