General
Q1: How do I know when new features are added to APM?
Answer: All major new features are announced in the APM Release Notes
Q2: Is it possible to switch an APM Domain from Free tier to Paid?
Answer: No. You need to create a new paid domain and reconfigure agents/tracer/browser agent settings.
Q3: How can I limit the ingestion, so it will not go over a set number of billing units?
Answer: Limiting ingestion can be done in multiple ways:
- Exclude unwanted or not useful spans. e.g. use the servlet probe configuration to exclude high volume - low value service request.
- Use sampling to reduce the number of traces being reported. Note that the decision to sample a trace is done in the first component of a trace flow.
- Reduce the abridge limit (default value is 100)
Q4: How can I be alerted on potential increase in service usage cost due to changes in application usage?
Answer: Yes, the metric SpanIngestions in the oci_apm namespace reports the number of span ingested to a domain in 15 minutes intervals. You can set an alert for this metric. For billing proposes the span count is hourly: either aggregating to 1h units ( SpanIngestions[1h].sum() ) or using ¼ of the desired threshold value. Note that 100,000 spans equal one billing unit.
Q5: Is APM reporting of username compliant with GDPR?
Answer: By default, no user identifiable information is captured. When username reporting functionality is enabled, special care needs to be taken to align usage with GDPR standards.
Monitoring
Q1: How are multiple browser tabs for a web application handled in monitoring?
Answer: By default, multiple tabs will be treated as a single session with the same session-id.
Q2: OCI Application Performance Monitoring provides only a Java agent for download and deployment. Does that mean that APM cannot monitor .NET or any other environments?
Answer: Not at all. APM analyzes data from a variety of sources, not just from Agents deployed in an environment. Among others, APM supports OpenTracing. Specifically, APM supports the JSON-encoded Zipkin v2 format. Using Jaeger, Zipkin or other tracers, APM can monitor most common languages.
Q3: The “Complete" and “Success” status of a trace seem very similar. What is the difference?
Answer: The “Complete” status indicates that the trace root span is complete. A “Success” status indicates that the root span is complete and that it has an http-status dimension, the value of which represents a successful request (0 < httpStatusCode < 400).
Q4: What's the difference between APM Java agent and APM Java Tracer?
Answer: The APM Java agent does byte code instrumentation (BCI) when added to an application server. It uses the open tracing format to send data to the APM end point. If you don’t have a way to generate tracing in the application server, you can use APM agent and its BCI to get traces. If your application server supports creating traces (for example Helidon or Spring Boot) you can use the APM Java tracer to send traces to APM. For more information, see Configure Application Performance Monitoring Data Sources.
Q5: I deployed the APM Browser Agent in my Single Page App (SPA) UI, but all/most of the traces start with a server side span. Where are the RUM spans?
Answer: In many SPA deployments, the HTML page is loaded from one domain, while the AJAX calls connect to a different domain for the dynamic data (using the REST/API server domain). By default, the Browser Agent does not instrument calls to external domains. This is done to avoid the instrumentation of calls by external systems that may not handle the instrumentation as expected. You can fix this issue by specifying the required external domain as allowed to be instrumented. For details, see: Configure Ajax Calls Instrumentation.
Time Reporting
Q1: What is the difference between end time and report period?
Answer: The best way to think of report period is just to assume it's the end time for the span. This provides a consistent view of all received metrics for reporting and alerting. The main benefit of report period over an end time concept, is that the end time would be based on agent timestamp (start time + duration), and clock skew would make the resulting reporting less useful.
Q2: What is the impact of clock skew on reporting?
Answer: Clock skew refers to the fact that the clock at different agents is not synchronized. The result of clock skew is that the start time of different spans and the related duration does not match up when it's diagnosed in detail. This impacts metrics like trace duration (which is based on minimum start time of any span in the trace, vs maximum start-time + duration of any span in the trace).
Q3: What time can I use?
Answer: Common concepts can be used to identify which of the two timings to use:
- When diagnosing details of a trace, it is often easiest to follow the tree by looking at the span start times, and reason from there, what triggered what
- When trying to identify a trace that relates to data seen in a logfile captured at the same system the agent is running, using the span start time is the best aproach, since these are stemming from the same clock as the logfile.
- When aggregating data to see load and performance metrics over time, it is best to use the
reportPeriod, since this metric is most stable, especially when the agent is capturing long running processes. - When reporting a dashboard that reflects current state, it is best to use
reportPeriod, since the current state of affairs is more complete. - When creating alerts, it is important to use the
reportPeriod, to ensure client clock skew (especially from browsers) is not hiding any impact on issues.
Errors and Codes
Q1: Why are errors of type 'Script Error' reported without further details?
Answer: In some cases the CORS implementation in the browser is preventing access to details of javascript that caused a particular failure. It is suggested to move the apmrum javascript to the monitored application domain to improve visibility. In some cases adding the 'Timing-Allowed' header can be used to increase visibility in reporting.
Q2: What does http status code 0 indicate?
Answer: http status 0 indicates that there was no response from the server to derive the status code from, indicating either a timeout or restrictions in the browser that prevent access to this data (e.g. due to CORS).
Q3: Why do I see the message “The spans cannot be shown as a call tree because some of the spans have duplicate IDs”, and how can I fix it?
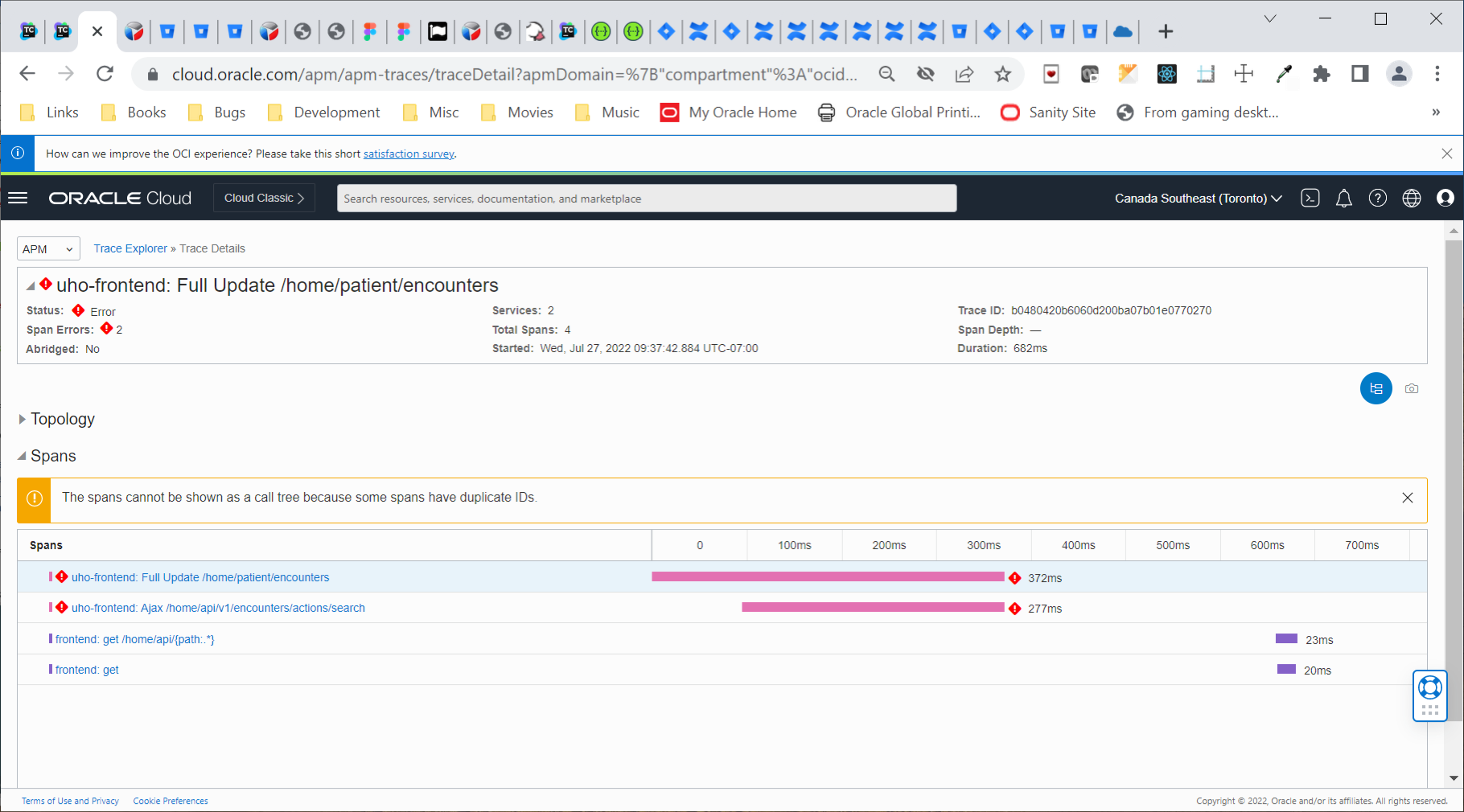
Answer: Every span in a trace should have a unique span ID. Duplicate IDs suggest misconfiguration or a problem with a tracer. A common case that causes a misconfiguration is the use of the supportsJoin capability available in Zipkin tracer. If this is your case, this capability can be disabled via the application configuration or through environment variables.
Example: Add supportsJoin : false to the Zipkin tracer configuration in the application.yaml file.
OCI Application Performance Monitoring FAQ
F45093-04
October, 2022
Copyright © 2022, Oracle and/or its affiliates.
Oracle Cloud Infrastructure Application Performance Monitoring Frequently Asked Questions Section
This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited.
If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable:
U.S. GOVERNMENT END USERS: Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs) and Oracle computer documentation or other Oracle data delivered to or accessed by U.S. Government end users are "commercial computer software" or "commercial computer software documentation" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, the use, reproduction, duplication, release, display, disclosure, modification, preparation of derivative works, and/or adaptation of i) Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs), ii) Oracle computer documentation and/or iii) other Oracle data, is subject to the rights and limitations specified in the license contained in the applicable contract. The terms governing the U.S. Government's use of Oracle cloud services are defined by the applicable contract for such services. No other rights are granted to the U.S. Government.
This software or hardware is developed for general use in a variety of information management applications. It is not developed or intended for use in any inherently dangerous applications, including applications that may create a risk of personal injury. If you use this software or hardware in dangerous applications, then you shall be responsible to take all appropriate fail-safe, backup, redundancy, and other measures to ensure its safe use. Oracle Corporation and its affiliates disclaim any liability for any damages caused by use of this software or hardware in dangerous applications.
Oracle and Java are registered trademarks of Oracle and/or its affiliates. Other names may be trademarks of their respective owners.
Intel and Intel Inside are trademarks or registered trademarks of Intel Corporation. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. AMD, Epyc, and the AMD logo are trademarks or registered trademarks of Advanced Micro Devices. UNIX is a registered trademark of The Open Group.
This software or hardware and documentation may provide access to or information about content, products, and services from third parties. Oracle Corporation and its affiliates are not responsible for and expressly disclaim all warranties of any kind with respect to third-party content, products, and services unless otherwise set forth in an applicable agreement between you and Oracle. Oracle Corporation and its affiliates will not be responsible for any loss, costs, or damages incurred due to your access to or use of third-party content, products, or services, except as set forth in an applicable agreement between you and Oracle.