Understanding Microservices
Overview
Microservices are the latest addition to the Unified Assurance Hyperscale Architecture. The central idea behind microservices is that some types of applications become easier to build and maintain when they are broken down into smaller, composable pieces which work together. Each component is continuously developed and separately maintained, and the application is then simply the sum of its constituent components. This is in contrast to traditional, monolithic or service oriented applications which are all developed all in one piece.
Applications built as a set of modular components are easier to understand, easier to test, and most importantly easier to maintain over the life of the application. It enables organizations to achieve much higher agility and be able to vastly improve the time it takes to get working improvements to production.
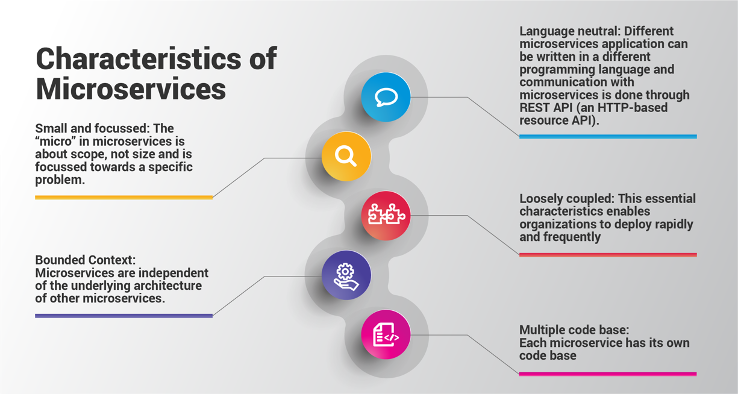
Description of illustration characteristics-of-microservices.png
Technology Components
Unified Assurance uses the best-of-breed components to implement microservices into its solution. Each of these components was carefully selected based on their industry adoption, flexibility of integration, and ease of use.
Docker
Docker provides an improved user experience for creating and sharing container images and as a result saw great adoption over other container implementations. Containers are a natural fit for microservices, matching the desire for lightweight and nimble components that can be easily managed and dynamically replaced. Unlike virtual machines, containers are designed to be pared down to the minimal viable pieces needed to run whatever the one thing the container is designed to do, rather than packing multiple functions into the same virtual or physical machine. The ease of development that Docker and similar tools provide help make possible rapid development and testing of services. The Docker daemon runs on all internal presentation servers and all servers installed with Cluster roles.
Docker Registry
The Docker Registry is a stateless, highly scalable web server that stores and distributes Docker images within each Unified Assurance instance. Docker Registry runs as a standalone Docker container on each Unified Assurance internal presentation server. The Registry runs behind the Unified Assurance web server which acts as a reverse proxy and secures the Registry with TLS client certificate authentication. Docker images are pushed into the Registry during the installation and update of specific Unified Assurance image packages. Images are pulled down from each Docker daemon on behalf of a Kubernetes cluster.
Kubernetes
Kubernetes is a portable, extensible, open-source platform for managing containerized workloads and services, that facilitates both declarative configuration and automation. It has a large, rapidly growing ecosystem. Kubernetes services, support, and tools are widely available. Kubernetes provides a framework to run distributed systems resiliently. It takes care of scaling and failover for your application, provides deployment patterns, and more.
Rancher Kubernetes Engine (RKE) is a CNCF-certified Kubernetes distribution that runs entirely within Docker containers. It works on bare-metal and virtualized servers. RKE solves the problem of installation complexity, a common issue in the Kubernetes community. With RKE, the installation and operation of Kubernetes is both simplified and easily automated, and it is entirely independent of the operating system and platform you are running.
Helm
Helm helps you manage Kubernetes applications. Helm is a package manager for Kubernetes that allows developers and operators to more easily package, configure, and deploy applications and services onto Kubernetes clusters. Helm Charts help you define, install, and upgrade even the most complex Kubernetes application.
ChartMuseum
ChartMuseum is a stateless, highly scalable web server that stores and distributes Helm charts within each Unified Assurance instance. ChartMuseum runs as a standalone Docker container on each Unified Assurance internal presentation server. This chart repository runs behind the Unified Assurance web server which acts as a reverse proxy and secures the repository with TLS client certificate authentication. Helm charts are pushed into the repository during the installation and update of specific Unified Assurance image packages. Charts are pulled down from each Helm client for deployment into a Kubernetes cluster.
Hyperscale Clusters
Unified Assurance runs stateless microservices for the new collection and processing application tiers in Kubernetes clusters. The existing Service Oriented Architecture (SOA) collection and processing application tiers will exist outside of these clusters. One or more clusters can exist per Unified Assurance instance, but all servers of each cluster must reside in the same data center or availability zone.
Cluster and Namespace Examples
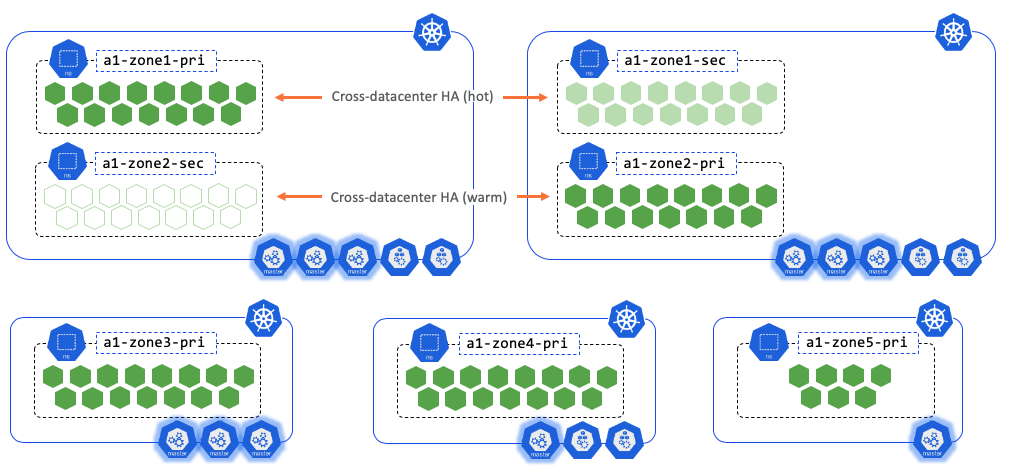
Description of illustration cluster-and-namespace-examples.png
Cluster Roles
Each cluster requires at least one primary server running the Kubernetes control plane and etcd stateful configuration stores. Production clusters should be setup with at least 3 primaries. The role known as Cluster.Master provides the definition to deploy the Kubernetes primary applications on desired servers.
The role known as Cluster.Worker provides the definition to run any additional Kubernetes workloads. The Cluster.Worker role can be defined on the same server as Cluster.Master if the server has plenty of resource capabilities.
Namespaces
Kubernetes supports multiple virtual clusters backed by the same physical cluster. These virtual clusters are called namespaces. Unified Assurance has an opinionated view of namespaces. Each cluster has a monitoring namespace to check the health of the cluster and containers, a messaging namespace to run the message bus for microservice pipelines, and one or more namespaces per device zone. The zoned namespaces isolate application discovery and polling to specific Unified Assurance device zones. Additionally, each zone is separated into a primary and secondary namespace to provide cross-cluster failover.
Monitoring
The health of the Kubernetes cluster components and the containers in each cluster are monitored from applications in the a1-monitoring namespace. Performance metrics are pulled and stored locally in each cluster. The metrics are moved to long term storage in the Unified Assurance Metric database. Metric KPIs collected not only provide analytics coupled with alerting thresholds, they can be used by the Kubernetes Horizontal Pod Autoscaler to increase the number of replicas of Pod deployments dynamically as needed.
Pulsar Message Bus
Apache Pulsar is a multi-tenant, high-performance solution for server-to-server messaging. It provides very low publish and end-to-end latency and guarantees message delivery with persistent message storage. Pulsar provides the backbone for Unified Assurance microservice pipelines and runs in the a1-messaging namespace.
Microservice Pipelines
Microservices are simple, single-purpose applications or system components that work in unison via a lightweight communication mechanism. That communication mechanism is very frequently a publish/subscribe messaging system, which has become a core enabling technology behind microservice architectures and a key reason for their rising popularity. A central principle of publish/subscribe systems is decoupled communications, wherein producers do not know who subscribes, and consumers do not know who publishes; this system makes it easy to add new listeners or new publishers without disrupting existing processes.
The first Unified Assurance pipeline available is the Event pipeline. The most basic setup of the pipeline connects event collectors to the FCOM processor for normalization and finally to the Event Sink for storage in the Event database.
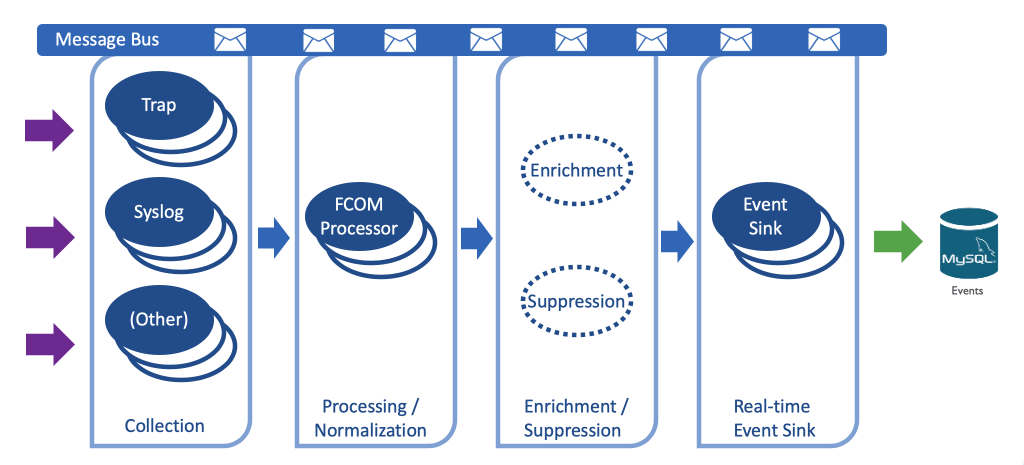
Description of illustration event-pipeline.png
Control Plane High Availability and Redundancy
Kubernetes High-Availability is about setting up Kubernetes, along with its supporting components in a way that there is no single point of failure. A single primary cluster can easily fail, while a multi-primary cluster uses multiple primary nodes, each of which has access to the same worker nodes. In a single primary cluster, the important components like the API server and controller manager lie only on the single primary node, and if it fails you cannot create more services, pods, etc. However, in the case of a Kubernetes HA environment, these important components are replicated on multiple primaries (usually three primaries) and if any of the primaries fail, the other primaries keep the cluster up and running.
Kubernetes nodes pool together their resources to form a more powerful machine. When you deploy programs onto the cluster, it intelligently handles distributing work to the individual nodes for you. If any nodes are added, removed, or failed, the cluster will shift around work as necessary.
Cross-Data Center Redundancy
Microservice redundancy is the concept of ensuring the high-availability, a core principle of microservice architecture, of microservice-based applications across multiple separately managed Kubernetes clusters. This high-availability protects services from otherwise critical events, such as hardware, platform, or network failure and, ultimately, ensures no loss in functionality for the end-user.
At the cluster-level, Kubernetes natively handles high-availability in the event of node failures very well by mitigating the migration of application pods from one node to another within the same cluster. However, in event of partial or entire datacenter failure, another worker node assigned to that cluster may no longer be available for pod migration, therefore the application is unable to run. To counter this problem, microservice redundancy provides a means for the workload of the application to be performed on an identical application running inside a pod on a completely different cluster. The secondary cluster, also known as the "redundant" cluster, can be running on physical or virtual machines that are positioned outside of the same network as the first (known as "primary") cluster, or even located in a different datacenter. This is achievable by utilising Submariner, a third-party open-source technology, to create a secure tunnel between the two clusters, allowing seamless communication between microservices and their redundant counterparts. By "joining" a cluster to the Submariner broker, a cluster can gain service discovery capabilities for any Kubernetes service exported to the broker from another joined cluster. This also creates a secure tunnel between the two clusters via which they can communicate.
In Unified Assurance, both the primary and secondary clusters are joined to the broker, which is deployed on the secondary cluster. A HTTP endpoint for each microservice running on the primary cluster can be exposed to its duplicate running on the secondary cluster. The secondary microservice can use the endpoint to perform a health check on the primary microservice. In the event of a catastrophic failure in the primary cluster, the health check will fail and, depending on user-defined thresholds, the microservice will "failover" to the secondary cluster where any ongoing and future work will now be performed indefinitely until the primary microservice is restored and the health check is successful once again. The microservice will now "fallback" to the primary cluster and the system regains status-quo.
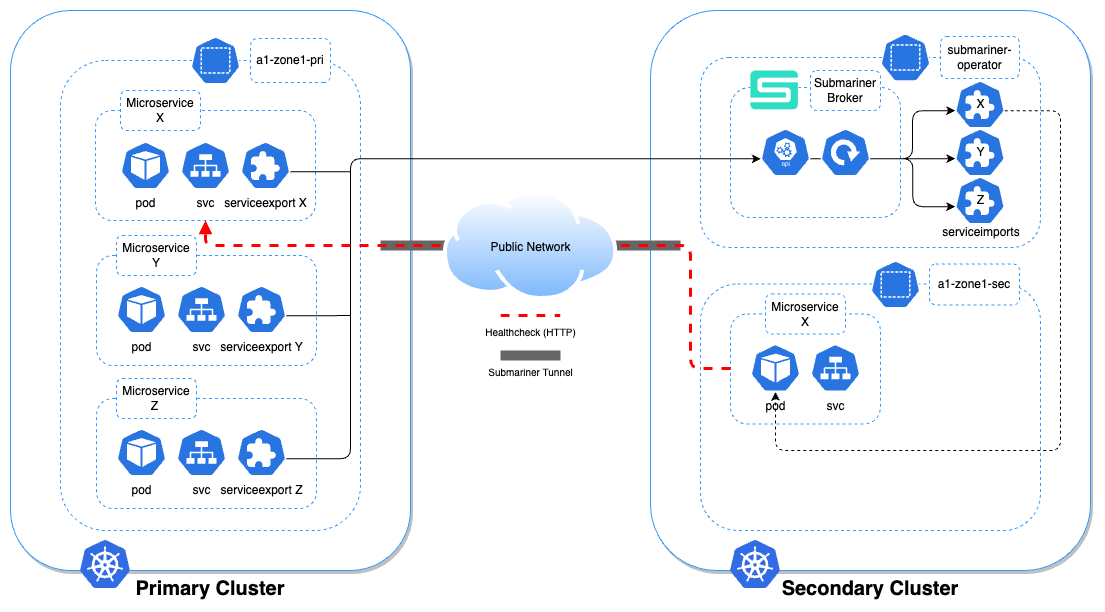
Description of illustration microservice-cross-data-center-redundancy.png
Submariner
Submariner is an open-source technology that provides service discovery and OSI Layer 3 communication across clusters using either encrypted or unencrypted connections. It facilitates geo-redundancy, scaling, and fault-isolation for applications that can span across multiple datacenters, regions, and networks.
Microservice Auto-scaling
Application auto-scaling is not a new concept and has been in the industry for quite a long time. A classical monolithic application would run on a host operating system, utilizing the physical machine's resources of its components and other applications, including the operating system. Scaling such an application frequently required redesign, splitting components manually, managing different physical machines and observing the system using monitoring tools, and making scaling decisions by a person or a team.
Microservices negate some of the cumbersome issues of monolithic applications. Physical machines become part of a resource pool controlled by Kubernetes. Each component is now a small composable unit of work which can be scaled seamlessly using industry standard technologies. Each work unit is designed to gather operational metrics that report on the unit's performance, efficiency, and resource use. Technologies like Prometheus have standardized the way microservices expose these metrics, how these metrics are collected, and how they are exposed to other technologies for reuse.
Technologies like KEDA simplify the layer between microservices and Kubernetes to make scaling decisions based on various aspects in the product's architecture, where using different types of metrics like web traffic, messaging queue throughput, network bandwidth, or something as basic as system resource use, KEDA will provide scaling decisions for Kubernetes. If the application has been found to be running slowly, become unresponsive, or not keep up within its nominal operation, Kubernetes will assign more work units as required to keep the application running optimally and then scale down when the additional work is no longer required to keep resource use optimal and efficient, in real-time.
By using auto-scaling matched with high availability and redundancy, users no longer need to worry about systems not responding, data being lost, or having service outages because at any single point of time, no part of the system is not available or not responsive.
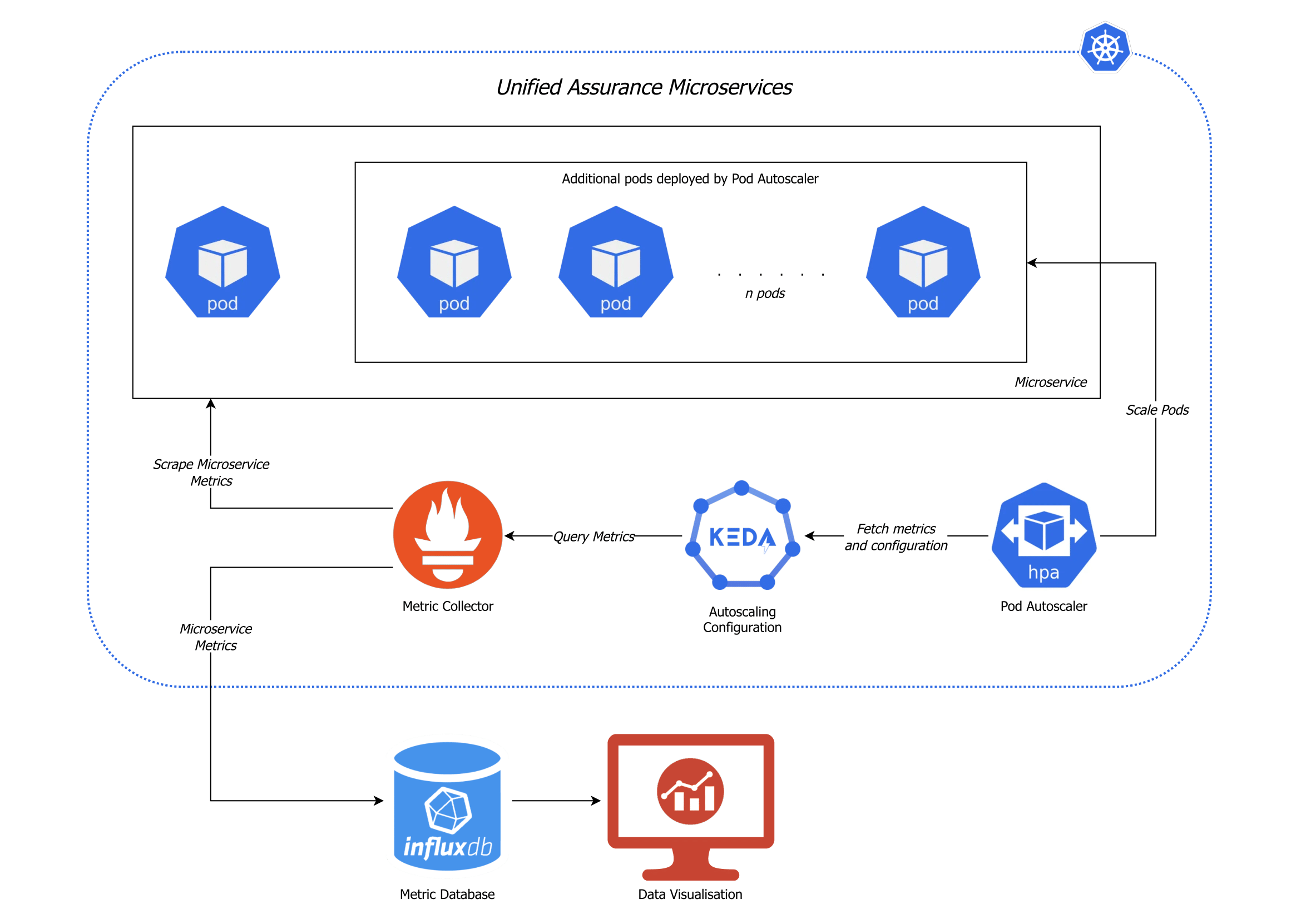
Description of illustration microservice-auto-scaling.png
KEDA
KEDA is a single-purpose and lightweight component that runs within each cluster. KEDA works alongside standard Kubernetes components and can extend functionality without overwriting or duplication. With KEDA you can explicitly map the apps you want to use event-driven scale, with other apps continuing to function. This makes KEDA a flexible and safe option to run alongside any number of any other Kubernetes applications or frameworks.
KEDA exposes rich event data like queue length or stream lag to the Horizontal Pod Autoscaler (HPA) to drive scale out. It defines the formulas and thresholds that can be customized to configure the scale of those deployment replicas.
Prometheus
Prometheus is an open-source systems monitoring and alerting toolkit. Prometheus joined the Cloud Native Computing Foundation in 2016 as the second hosted project, after Kubernetes. Prometheus scrapes metrics from instrumented jobs, either directly or via an intermediary push gateway for short-lived jobs. It exports all scraped samples to a metric database and can runs rules over this data to either aggregate and record new time series from existing data or generate alerts. Grafana or other API consumers can be used to visualize the collected data.
Deploying Microservices
A Kubernetes cluster must be setup on one or more servers before microservices can be deployed. Refer to Microservice Cluster Setup for instructions.