Data Flow
This page describes the standard data flow for Oracle Utilities Analytics Warehouse (OUAW).
On this page:
Product Overview
Oracle Utilities Analytics Warehouse extracts data from the utilities application source database into the replication layer. After data extraction, it transforms raw data in the staging area, and then loads this transformed data into the target star schemas for business users to consume.
The following image is a high-level diagram of OUAW's data flow.

Data Extraction (Replication Layer)
The replication layer is the landing zone of OUAW. During the integration of the source database instance with OUAW, there is one replication schema generated for each one of the source instances. These schemas serve to store the extracted data (that is, both existing historical and ongoing change data) from the source. The key benefits of this layer are:
- It can be configured to retain history.
- It facilitates debugging.
- It allows to have multiple parallel loads.
- It is possible to reset and to reload entities.
- It simplifies the loading process by creating replication views and loading target facts and dimensions from them.
- It is possible to configure it to replicate additional tables from source database for user customization purposes.
Note the following details about the replication schema for a source instance in OUAW:
- It contains all the tables that were selected for replication.
Note: There are different types of tables in the replication schema (for example, Overwritten Type, History Type, and so on). The replication table patterns are explained below in this section. See Replication Table Patterns.
- The table and column names in the replication layer will be the same as in the source.
- Additional columns (for example, JRN_*) will be generated, as they are required for the ETL process.
Note: The replication layer table structure is explained below in this section. See Replication Table Structure.
- Tables in the replication layer do not contain any referential integrity, and not null constraints for faster data replication.
- Each table in this schema contains a primary key and an index on a column called JRN_SLICING_TS for faster data processing.
- Some functional indexes are created in the replication schema tables to speed up data processing.
Replication Views
Replication views are metadata-driven views for a specific source instance to simplify the loading of dimensions and facts into the target data warehouse. These views are created during the integration of the source with OUAW. The replication view of a specific target dimension or fact table populates data from one or more dependent replicated tables. It contains all simple and direct transformations in order to simplify the loading of that target entity.
However, for target columns that require complex transformations such as grouping, aggregation, conditional grouping, and so on, it is necessary to make a separate mapping to transform the data into an intermediate staging table and then load it into the target.
Replication Table Patterns
The following table patterns are used when replicating tables from the source. The use of these patterns should be based on how the tables are being used in the source system and on the target entities to be loaded from them.
|
Pattern |
Details |
|---|---|
|
Overwrite (OVRD) |
Description: Historical changes for these types of replicated tables are not tracked in the replication layer. These are typically the transactional or the master data used to populate the slowly changing dimension of type 1 dimension or an accumulation fact. Approach:
Note: OUAW does not remove that record completely from the replication table. |
|
Effective-Dated (EFDT) |
Description: The source maintains history by using an effective date column, however the end date is not defined and needs to be calculated for better responsiveness of the data load processes. Approach:
|
|
Key Tables (KEY) |
Description: Oracle Utilities Application Framework products store the keys for the primary tables of an MO into this type of table. This data is not deleted when data from the base tables is archived or purged. This is required to differentiate between a deletion on the source system and an archival on the source system. Approach: The table consists of key columns only and is replicated as is with the timestamp and the source system change number. |
|
History (HIST) |
Description: Change history is not maintained in the source product, but historical changes for these types of replicated tables are tracked in the replication layer. These tables are mostly required for populating slowly changing dimension of type 2 and periodic snapshot fact. Approach:
|
|
History Type 2 (SCD2) |
Description: This type of table can only be seen in the replication schema for the Network Management System source. Source system maintains history by keeping BIRTH and DEATH for every record in this type of table. Approach: In the Oracle Utilities Network Management System source system, some of the tables follow the SCD2 behavior, using birth and death columns to store the effective start and effective end dates. |
Replication Table Structure
A replicated table has all columns of the source table and additional attributes depending on the categorization. The column order of the replicated table matches the column order of the source table. The additional columns will be added to the right end of the table.
The following table shows the columns that are going to be generated for each replication pattern.
|
Column |
Overwrite (OVRD) |
Effective Dated (EFDT) |
Key (KEY) |
History (HIST) |
History Type2 (SCD2) |
|---|---|---|---|---|---|
|
All Source Columns |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Slicing Timestamp (JRN_SLICING_TS) |
Yes |
Yes |
Yes |
Yes |
Yes |
|
System Change Number (JRN_SCN) |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Operation Indicator (JRN_FLAG) |
Yes |
Yes |
No |
Yes |
Yes |
|
Cleansed Indicator (JRN_CLEANED_FLAG) |
Yes |
Yes |
No |
Yes |
Yes |
|
Last Change Timestamp (JRN_UPDATE_DTTM) |
Yes |
Yes |
No |
No |
Yes |
|
Effective Start Timestamp (JRN_EFF_START_DTTM) |
No |
No |
No |
Yes |
No |
|
Effective End Timestamp (JRN_EFF_END_DTTM) |
No |
No |
No |
Yes |
No |
|
Current Indicator (JRN_CURRENT_FLAG) |
No |
Yes |
No |
Yes |
Yes |
Note: Installation of OUAW is usually done after the transactional systems have been operational for a few years. Therefore, the source system may have accumulated a large amount of historical data over the years. Apart from existing historical data, ongoing change data is required to be extracted from the source. OUAW has two different approaches to bring the initial and incremental data into the target replication schema: initial and incremental.
Initial Data Replication Approach
This section explains the methods used to load the initial data in OUAW through the Oracle Database feature DBMS_DATAPUMP to bring existing historical data from the source database to the replication schema. There are three different modes to synchronize the initial source data with the target:
- Export and Import:In this mode, data is first exported from the source into the database directory (B1_DATA_DUMP_DIR) in source. Then the dump file needs to be transferred from the source into target manually. Once dump files are moved into the database directory (B1_DATA_DUMP_DIR) in target, then data is imported into the replication schema. Export and import logs are written into the source and target database directory, respectively.
- Export and Import Using Shared Network Storage : This mode is similar to the previous one, but this mode requires shared network storage. Both source and target should be able to access the database directory (B1_DATA_DUMP_DIR) in this shared network storage. In this method file transfer is not required and this is the best mode to load a large volume of initial data into the target.
- Database Link: In this mode data will be imported directly from the source into the target using the database link, which is created during the integration of the source with OUAW.
Notes:
- Tables in the replication schema contain a few additional columns called journal columns for ETL purposes. Transformation logic needs to be applied to populate these additional columns into the replication schema.
- Data transformation at the time of extraction from source over network will impact performance. Therefore, raw source data is first imported into a temporary schema called import schema and then it is transformed and loaded into the target replication schema from the import schema. Import schema is dropped by the initial data synchronization job at the end of initial data load.
- No data filtering is applied at the time of initial data synchronization. Therefore, initial synchronization job synchronizes complete data from the source for all tables configured to be replicated.

Incremental Data Replication Approach
OUAW uses Oracle GoldenGate Classic Architecture to replicate change data into the target replication schema. The change data synchronization process is set by the Oracle Data Integrator process during the integration of the source system with OUAW. The GoldenGate primary extract process in the source is meant to capture change data from the redo or archive logs and write that data into trail files in the trail location. GoldenGate secondary extract process, also called pump process, send those trails over the network and into the target trail location. Finally, GoldenGate replicat process applies those transactions in trail files into the target replication schema. Oracle Utilities Analytics Warehouse uses integrated extract and classic replicat process to synchronize change data from the source into the target database.
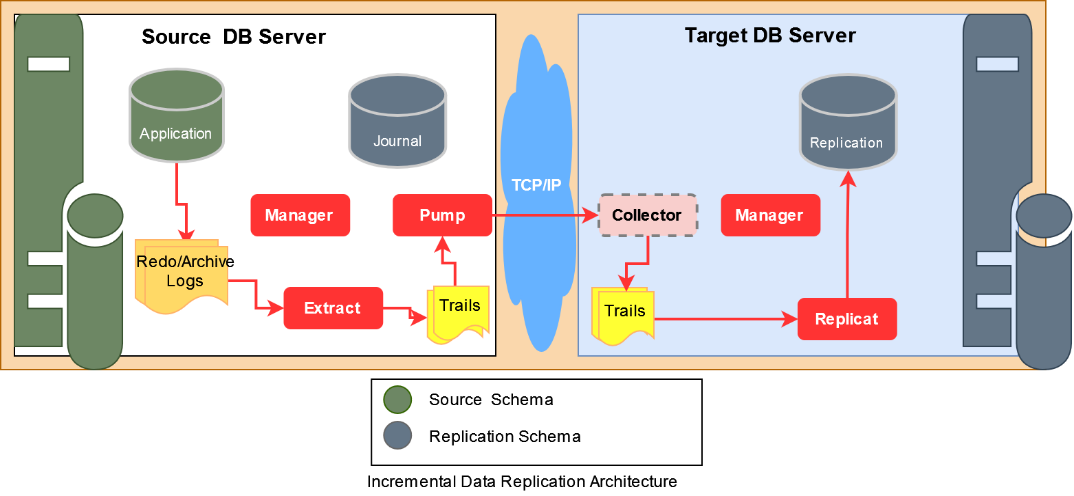
DDL Capture Support
Any product can undergo data structure changes in from one release to other. When a source application is upgraded to the current release, it is quite possible that tables used by OUAW undergo structural changes in source. Those structural or DDL changes need to be replicated into the replication schema in target. Oracle GoldenGate supports all DDL replication, but OUAW has implemented some restrictions for the successful execution of the ETL jobs.
The following table explains which DDL changes are supported and which are not.
|
Structural Change |
Expected Behavior |
|---|---|
|
Existing replicated table renamed in source |
OUAW does not rename the table in the target replication schema. This is not supported because it would impact all the ETL jobs that use this table. Oracle Data Integrator mappings need to be modified to refer to the renamed table. GoldenGate extract and replicat parameter files also need to be modified to support this change. Therefore, impact analysis is required before applying this type of change into target replication schema. |
|
Existing replicated table dropped from source |
OUAW does not drop the table from the target replication schema. This is not supported because it would impact all the ETL jobs that use this table. Therefore, impact analysis is required. If no ETL mapping is referring to the table dropped from source, then it can be dropped manually from the target replication schema. |
|
Existing replicated table altered from source:
|
OUAW supports all these operations and applies these changes into the target replication schema. |
Data Transformation (Staging Layer)
After the source data is replicated into the replication layer, the raw data need to be cleansed, confirmed, and transformed before loading into the target star schema. You must perform the following operations in the staging area to transform the raw data into summary data in accordance with the business requirements:
- Eliminate unwanted data.
- Find and remove duplicates.
- Convert the data.
- Aggregate the data.
- Look up the dimension key.
- Reprocess the missing dimension key.
- Validate the data in accordance with the target constraints.
Notes:
- Some transformations are more complex and need to be performed in multiple stages. Partially transformed data needs to be stored into intermediate tables to simplify the loading process. Different types of intermediate tables are created as part of the ETL process. Types of intermediate tables and their uses are mentioned below. Not every ETL job or process will create all these types of intermediate tables. These tables will be created based on their complexity and the type of the target entity.
- Except for the primary error table, all other types of tables are created dynamically. The names of these type of tables follow the pattern "resource name of the target data store". For every fact table, primary error tables are created in the staging area when their respective ETL job is executed for the first time. Primary error tables are never dropped from the staging layer.
Key Table
When an ETL process starts, it first applies the slice start and end date ranges and identifies the data sets that need to be processed to populate the current sliced data into the target. Then it tries to identify the list of natural keys (in accordance with the target entity's natural key) present within the data set and store those keys into the key table. The key table is created automatically by the ETL process. Its name is the resource name of the target data stored in the Oracle Data Integrator mapping used to load the key table. Resource name for the key table is usually given as KEY_#GLOBAL.B1_JOB_ID, where KEY_ resource name prefix and #GLOBAL.B1_JOB_ID is an Oracle Data Integrator global variable that stores the job execution ID. So, if the ID of an ETL job is 123456, then the key table name would be KEY_123456. Apart from the natural keys, the key table might contain additional attributes.
Temporary Table
The temporary table is created automatically and used to store partially transformed data for the ETL processes, which may require zero or more temporary tables for the complete transformation of data.
The name of the temporary table is the resource name of the target data stored in the Oracle Data Integrator mapping used to load the temporary table. The resource name for the temporary table is usually given as TMP_#GLOBAL.B1_JOB_ID, where TMP_ resource name prefix and #GLOBAL.B1_JOB_ID is an Oracle Data Integrator global variable that stores the job execution ID. So, if the job execution ID of an ETL job is 123456, then the temporary table name would be 'TMP_123456'. ETL process might require storing intermediate data into multiple temporary tables. Therefore, you might see prefixes like TMP01_, TMP02_, AGG_, AGG01_, AGG02_, and so on.
Staging Table
The staging table is the last intermediate table in the staging layer where all transformed data is merged. For every dimension and fact in the target data warehouse one staging table is created for each job run. This table contains final transformed data in it before loading into their respective dimension or fact. Target dimension and facts are loaded from the staging table. Name of the staging table is STG_ followed by the job execution ID. If the job execution ID of an ETL job is 123456, then the staging table name would be STG_123456.
Primary Error Table
In a data warehouse, it is possible that a transactional record referring to a dimension arrives to the target before an entry is made for the dimension in the corresponding dimension table. These types of dimensions are called late arriving dimensions, and there are many ways to handle them. The above scenario is handled in OUAW in the following manner:
- A reference dimension key is populated into the fact staging table with a missing key value (-99).
- The transaction is marked as an error, and a copy of it is kept in an error table in the staging area. This error table is called the primary error table.
- Transactions with missing dimension reference are loaded into the target fact along with other valid transactions.
- After their respective dimension is arrived into the target, those missing dimension reference transactions in the error table are reprocessed and then merged into their respective fact table.
- After the reprocess, if there is a missing dimension reference found for a transaction, the transaction is removed from the error table to a temporary error table.
Therefore, every fact contains a primary error table. In general, the name of the primary error table is ERR_ followed by the name of the target fact. For example, if the fact name is CF_FT, then their primary error table name would be ERR_CF_FT.
Temporary Error Table
The temporary error table is created to reprocess only those rows from the primary error table for which missing dimensions are found. The naming convention for the table is ERR_#GLOBAL.B1_JOB_ID, where #GLOBAL.B1_JOB_ID is the job execution ID of the running slice of the fact table. For example, if the global job execution ID of the ETL job is 123456, then the name of the temporary error table name would be ERR_123456.
Note: A primary error table might contain thousands of rows with missing dimension references, which could be due to only 10 missing dimensions. It is not necessary that all missing dimensions arrive at a time before the next job execution, because it is costly to reprocess rows disregarding if their missing dimensions arrived or not.
Cleanup of Staging Layer
The staging layer is used for the data transformation purpose. It creates temporary intermediate objects to store partially transformed data. The size of this layer grows over a period of time if those temporary objects are not removed from the staging layer. OUAW manages this layer automatically. It removes all temporary intermediate objects from the staging layer after the retention period is over. By default, the retention period for the cleanup of the staging layer is 7 days, but this can be increased or decreased depending on the size of the storage allocated for this layer. How to configure the staging retention period and the information about the cleanup job is explained later.
As objects and data in this layer are not persistent, no reporting should be done from this layer, and business users should not have access to this layer. This layer can only be accessed for debugging ETL jobs or analyzing the issue with the ETL process.
Data Loading (Target Layer)
The target layer is the presentation layer that contains dimensions, facts, summary tables, and stores final transformed data. This layer is dimensionally modeled, and business users can have access to it in order to run report queries. All pre-built analytics populate data from this layer.
The OUAW target layer is the single database schema where all star schema objects (that is, the centralized fact and dependent dimensions) are present. Star schemas are associated with the source product, and those will be populated only if their corresponding source is configured. Few dimension entities such as Account, Address, Person, Premise, Service Agreement, Message, Crew, and Fiscal Period dimensions are conformed dimensions. These dimensions are populated from more than one source product. Every target entity (dimension, fact, or materialized view) contain a source indicator column (DATA_SOURCE_ID) to know the actual source of a transaction. Different types of entities present in the target layer of Oracle Utilities Analytics Warehouse (OUAW) are explained in this section.
Dimensions
Dimensions are business entities that contain descriptive attributes based on the measures described in the fact. OUAW's target layer contains the following types of dimensions:
- Static Dimension: Static dimensions are loaded only once. Data in this type of dimension are never modified after being loaded. These types of dimensions contain different bucket ranges. Each bucket contains values for start and end ranges. Target fact refers to the appropriate bucket by populating their respective dimension key based on measures or expression that falls within the start and end range. To reconfigure a bucket start and end range, it is required to reset all its dependent facts and the bucket dimension and reload after new bucket ranges are configured.
- Slowly Changing Dimension Type I: This type of dimension does not track history. Whenever a newer version of an existing dimension record arrives, it overwrites the existing row with the newer version.
- Slowly Changing Dimension Type II: This type of dimension tracks history. Whenever a newer version of an existing dimension record arrives, it expires the previously existing record by setting the effective end to the current date and inserts a new record with the effective start time to current time.
Facts
Facts contain measurements and dimensions reference based on the measurements described. OUAW's target layer contains the following types of facts:
- Accumulating Fact: Some business transactions are not discrete. They pass through a fixed set of states and those states are analyzed as a whole. A row in an accumulating fact table summarizes the measurement events occurring at predictable steps between the beginning and the end of a process. Therefore, in an accumulation fact, only one record will be present for a natural key.
- Periodic Snapshot Fact: A row in a periodic snapshot fact table summarizes many measurement events occurring over a standard period such as a hour, day, a week, or a month.
- Derived Fact: These types of facts are either accumulating or periodic snapshot facts, but they are not loaded directly from the raw source data in the replication layer. These facts are loaded from data from the detailed facts in the target layer and contain summary data.