Oracle® Outside In Clean Content Developer's Guide
Release 8.5.4
F11001-01 |
Contents
Introduction
Definitions
Features
File Formats
SDK layout
Architecture
Java
C/C++
.NET
Using the API
Initialization
Basic Use
Request
Response
Document IO
Targets
Analysis and Scrubbing
Extraction
Embedding Recursion
Embedding Export
Embedding Replacement
PowerPoint Disassembly/Assembly
Threading
Timeouts
Exception Handling
Install and Coding Guidelines
Java
C/C++
.NET
Introduction
The Outside In Clean Content SDK provides all the components, documentation, samples, and other resources required by third-party developers to integrate Oracle's document analysis, scrubbing, extraction, and export technology into their applications.
Definitions
The following definitions are used in this documentation and the Clean Content API.
document
This term is used broadly and generically in the documentation and API to refer to any file such as a word processing document, a spreadsheet, a presentation, a PDF, etc.
target
Some feature or piece of information in a document that can be identified and in many cases removed (see scrub below). Most targets relate to a known security risk in popular file formats although some like identifying a document as being encrypted.
analyze
To determine if a given target exists in the document.
scrub
To remove a given target from a document.
extract
To provide the developer with text, structure and other information in the document.
export
To copy objects, images and other artifacts embedded in a document to standalone files.
disassembly
To take a document with multiple parts (slides in PowerPoint is the only current example) and split it into multiple standalone documents, one per part.
assembly
To take several documents and merge them into a single document.
Features
The Clean Content API exposes the following major features;
- Discovery (analysis) and removal (scrubbing) of over 40 unique pieces of information (targets) inside Microsoft Word, Excel, PowerPoint, and Adobe PDF documents
- Extraction of the text, structure and other information from Microsoft Office documents and Adobe PDF files.
- Export of embedded objects and images from Microsoft Office documents and Adobe PDFs
- Specialized scrubbing and modification of Fields in Microsoft Word documents
- Addition, modification, and removal of Properties in Microsoft Office documents and Adobe PDF files.
- Recursion into embedded objects for both scrubbing and extraction
- Replacement of embedded images in Microsoft Office documents
- Assembly/Disassembly of PowerPoint presentations
- High performance
- High stability
- APIs including Java, C, C++ and .NET
File formats
Clean Content supports the following primary file formats. Many other formats (such as Windows Metafile) commonly associated with these primary file formats are also supported. Note that hundreds of additional file formats are supported when using the optional integration with Outside In Search Export.
Adobe FDF
Support: Analyze, Extract, Export
Extensions:
fdf
Adobe PDF includes all versions
Support: Analyze, Extract (with hit highlighting support), Export
Extensions:
pdf
Microsoft Docfile includes formats such as Microsoft Visio, Microsoft Project, etc.
Support: Analyze (properties only), Scrub (properties only), Extract (properties only)
Microsoft Excel 2007 and above
Support: Analyze, Scrub, Extract, Export
Extensions:
xlsx, xlsb, xlsm, xltx, xltm, and xlam
Microsoft Excel 2007 Binary
Support: Analyze (limited), Scrub (properties and macros only), Extract
Extensions:
xlsb
Microsoft Excel 97 thru 2003
Support: Analyze, Scrub, Extract, Export
Extensions:
xls
Microsoft PowerPoint 2007 and above
Support: Analyze, Scrub, Extract, Export, Assembly, Disassembly
Extensions:
pptx, pptm, potx, potm, ppam, ppsx, and ppsm
Microsoft PowerPoint 97 thru 2003
Support: Analyze, Scrub, Extract, Export, Assembly, Disassembly
Extensions:
ppt, pps, pot, and ppa
Microsoft Word 2007 and above
Support: Analyze, Scrub, Extract, Export
Extensions:
docx, docm, dotx, and dotm
Microsoft Word 97 thru 2003
Support: Analyze, Scrub, Extract, Export
Extensions:
doc and dot
SDK Layout
The SDK's directory structure provides easy access to all the components, samples, documentation and other files needed to integrate the Clean Content SDK into your application.
CleanContentSDK
The root directory of the SDK
CleanContentSDKDemoWin32.exe
CleanContentSDKDemoWin64.exe
CleanContentSDKDemoLinux32.sh
CleanContentSDKDemoLinux64.sh
Operating system specific launchers for the Clean Content SDK demo application. This Java application is designed to demonstrate the full potential of the Clean Content API and allow developers to explore the analysis, scrubbing, extraction and export behavior of this SDK is a full-featured GUI environment.
CleanContentSDKDemoGeneric.sh
A generic launcher for the Clean Content SDK demo application on Unix style operating systems. It will use the JAVA_HOME environment variable followed by locate bin/java to find an appropriate Java Runtime Environment to use. That requires the bash shell.
index.html
The Clean Content Developer's Guide
app
Directory containing components and documentation for the CleanContentSDKDemo application
c
Directory containing libraries, include files, samples and other files required to use the Clean Content C/C++ API. For more information, see Clean Content C/C++ API.
include
Directory containing include files required to use the C/C++ API. Most importantly it contains secureapi.h which is the only file your code needs to include.
lib
Directory containing native code libraries needed to use the C/C++ API plus the test and sample app executables.
Windows
Directory containing DLLs and LIBs needed to use the C/C++ API on Microsoft Windows plus the test and sample application EXEs . This directory will include one or more sub-directories that correspond to the processor architecture for which Clean Content is available. Currently, x86 and x64 architectures are available.
Linux
Directory containing library archives and shared objects needed to use the C/C++ API on Linux plus the test and sample applications. This directory will include one or more sub-directories that correspond to the processor architecture for which Clean Content is available. Currently x86 and x64 architectures are available.
api
Directory containing the full source code to the C/C++ API.
apitest
Directory containing a cross-platform, pure C, test application designed to exercise the C API.
sanitytest
Directory containing a cross-platform, C++, test application that uses the files in CleanContentSDK/samplefiles/targets to verify that basic document analysis is working correctly.
csample
Directory containing a cross-platform, pure C, sample application.
cppsample
Directory containing a cross-platform, C++, sample application.
dumptext
Directory containing a cross-platform, C++ sample application that shows how to retrieve the text out of a document using an element handler.
docs
Directory containing documentation for the SDK
cdoc
Directory containing C/C++ API documentation
javadoc
Directory containing Java API documentation
dotnetdoc
Directory containing .NET API documentation
technotes
Directory containing technical notes
java
Directory containing components, samples and other files required to use the Clean Content C/C++ API. For more information, see Clean Content C/C++ API
lib
Directory containing CleanContent.jar that should be shipped with your application. See Install and Coding Guidelines.
sample
Directory containing Java API sample applications. Sample directories include batch files and shell scripts to build and run each application.
AnalyzeDirectorySample
Directory containing a command line sample application that analyzes all the documents in a given directory.
dotnet
Directory containing components, samples and other files required to use the Clean Content C/C++ API. For more information, see Clean Content C/C++ API
lib
Directory containing CleanContentNET.dll that should be shipped with your application plus the test app executables. Just shipping this dll is not enough, please see the .NET Install and Coding Guidelines.
apitest
Directory containing a .NET test application designed to exercise the basics of the .NET API.
sanitytest
Directory containing a .NET test application that uses the files in CleanContentSDK/samplefiles/targets to verify that basic document analysis is working correctly.
jres
Directory containing four Java Runtime Environments (Win32, Win64, Linux32 and Linux64) needed to run the CleanContentSDKDemo application and the Java sample applications on the supported operating systems. These JREs may also be distributed with the developer's application. Oracle chooses to ship these JREs along with its SDK instead of requiring developers to "install Java" before using the demo app.
oit
Directory structure used to provide platform specific OILInk executables for integration with Outside In Search Export. Executables for Win32, Win64, Linux32 and Linux64 are provided.
samplefiles
Directory containing documents that can be used to test Clean Content's behavior and your application. See the readme.txt file in this directory for detailed information.
samples
Directory containing the original set of Clean Content sample documents.
targets
Directory containing documents that exercise all the targets Clean Content can
identify for the various supported file formats. Oracle uses these documents
internally as one part of Clean Content's automated QA process.
exception
Directory containing a series of Microsoft Word documents built specifically to trigger Clean Content to generate certain exceptions, including null pointer exception and out of memory exception. The document names indicate the Java exception they generate. These documents were developed to help customers build QA processes that include exception testing. It should be noted that these documents do not exercise flaws in Clean Content
rather certain bytes have been modified and are tested by Clean Content's Microsoft
Word transform which in turn triggers these specific exceptions on purpose.
Architecture
Java
The core of the SDK is a set of Java classes that perform the actual analysis, scrubbing, extraction and export. These classes are delivered as CleanContent.jar. If your application is written in Java or has direct access to Java classes (a web site using Java Server Pages for example) the jar can be used directly through the Clean Content C/C++ API. For more information, see Clean Content C/C++ API.
What Java runtime to use?
If you are already using Java, then you probably have an existing Java Runtime Environment (JRE) that you use or require. If you plan on using Clean Content's C/C++ or .NET interfaces, then this might be the first time you are been exposed to the JRE choices available to you. Clean Content requires a Java Standard Edition 6 compatible JRE and ships with four version of Oracle's JRE 6 (in the jres subdirectory of the SDK).
C/C++
Clean Content's C/C++ API is built on top of the Clean Content Java API allowing your C or C++ application to run Clean Content "in process" for maximum performance while getting all the stability and safety features of Java. For this, you need to provide a native code library (For example, CleanContentAPI.dll or libCleanContentAPI.so) that does all the work of loading the Java VM into your process and interfacing with Clean Content's Java core. For this, you don't need to "install Java" on the target system. The Java components (CleanContent.jar and the JRE subdirectory) may be local to your application with no impact on the rest of the system. In this instance, Java is extra DLLs or SOs that is dynamically loaded into your process.
This architecture was selected to meet the requirement of high-performance in-process parsing while still protecting your process from the problems often caused by the limitless variations of complex, malformed, hacked and truncated documents. The C and C++ APIs provide the interfaces that meet your application's needs while the Java VM provides a stable and well-tested platform that protects your use from wild pointers and buffer overflows that plague parsers written in native code. Running these documents inside a VM protects your applications while avoiding the complexity and performance problems of "out of process" solutions.
.NET
Clean Content's .NET API is built on top of the C API using .NET's interop services. As with the C/C++ API, the .NET API runs Clean Content "in process" (the Common Language Runtime and the Java Virtual Machine can coexist in the same process) for maximum performance and ease of integration all without requiring you or your customer to "install Java." Please review the C/C++ section above for further details.
Using the API
Initialization
The Java API requires no per-process or per-thread initialization and your code may immediately begin creating SecureRequest objects. The C/C++ and .NET APIs. However, require per-process and per-thread initialization to interface correctly with the underlying Java VM. In these environments, the following guidelines followed for initialization
- BFStartup (in C/C++) or SecureHelper.Startup (in .NET) must be called before any other calls to this API.
- BFShutdown or SecureHelper.Shutdown must be called after all other calls to the API and must be called in the same thread that called BFStartup/SecureHelper.Startup
- Each new thread that wants to process documents must call BFAttachThread or SecureHelper.AttachThread before any other calls to this API. This is not required for the thread that calls BFStartup/SecureHelper.Startup.
- A thread that called BFAttachThread/SecureHelper.AttachThread must call BFDetachThread or SecureHelper.DetachThread after its last call to this API. This is not required for the thread that calls BFStartup/SecureHelper.Startup.
- Each thread should create its own SecureRequest and use it only in that thread. This is not a hard and fast rule but it is simplest and safest. For example, an application that has thousands of threads might choose instead to create a small pool of SecureRequest objects to service those threads as long as each SecureRequest is used only in one thread at a time and the thread follows the rules above.
Basic Use
A developer's primary interaction in this API is with a SecureRequest object or handle in the case of the C API (from now on this document will use object/class/method semantics, C API users should be aware that a SecureRequest handle is equivalent to a SecureRequest object). This class contains mostly methods that allow the developer to get and set a collection of typesafe options found in the SecureOptions object. Also, SecureOptions contains methods for executing the request and for getting the results. This follows Clean Content's basic design philosophy for long-term APIs which favors extensible, typesafe, self-describing options over more concrete methods attached directly to the SecureRequest.
The basic execution flow of a simple application that needs to process multiple
documents is as follows.
- Call Startup (C, C++ and .NET only)
- Create a new SecureRequest object
- Use that object's various setOption methods with the options in
SecureOptions to define what parts
of the each document should be analyzed or scrubbed and/or to set
extraction, export and other processing parameters.
- Set the SourceDocument option to define the next document to be processed. If all documents are done go to step 8.
- Call the SecureRequest's execute method.
- Use the SecureRequest's getResponse method to determine the
outcome of the operation.
- Return to step #4
- Call Shutdown (C, C++ and .NET only)
Below are code samples for complete Java, C++ and C# programs that show how to analyze a single document for targets. Notice that the .NET API requires explicit Close methods for SecureRequest and SecureResponse objects. For more details see the .NET Install and Coding Guidelines.
import net.bitform.api.secure.SecureRequest;
import net.bitform.api.secure.SecureOptions;
import net.bitform.api.secure.SecureResponse;
import net.bitform.api.options.ScrubOption;
import net.bitform.api.options.Option;
import net.bitform.api.options.AnalyzeOption;
import java.io.File;
import java.io.IOException;
public class Main {
public static void main(String[] args) {
// Create a request
SecureRequest request = new SecureRequest();
// Only analysis will occur and no output file
// will be created regardless of other settings
request.setOption(SecureOptions.JustAnalyze, true);
// Set the document to be analyzed
request.setOption(SecureOptions.SourceDocument, new File("c:/temp/test.doc"));
try {
// Execute the request
request.execute();
// Get the response object
SecureResponse response = request.getResponse();
// Check for success
if (response.getResult(SecureOptions.WasProcessed)) {
// Print information about the document
System.out.println("The file has a format of " + response.getResult(SecureOptions.SourceFormat).getName());
System.out.println("The file contains the following targets...");
// Print a list of targets present in the document
Option[] options = SecureOptions.getInstance().getAllOptions();
for (int j = 0; j < options.length; j++) {
if (options[j] instanceof ScrubOption) {
if (response.getResult((ScrubOption) options[j]) == ScrubOption.Reaction.EXISTS)
System.out.println(options[j].getName());
} else if (options[j] instanceof AnalyzeOption) {
if (response.getResult((AnalyzeOption) options[j]) == AnalyzeOption.Reaction.EXISTS)
System.out.println(options[j].getName());
}
}
} else {
// Processing failed
System.out.println("Document processing failed");
}
} catch (IOException e) {
// An exception occured
System.out.println("Document caused an exception");
e.printStackTrace();
}
}
}
#include <iostream>
#include <tchar.h>
#include <malloc.h>
using namespace std;
#include "secureapi.h"
#ifdef BFWIN
#include <windows.h>
#endif
int main(int argc, _TCHAR* argv[])
{
try {
// Initialize the Clean Content API
BFSecureRequest::Startup(BFSTARTUPFEATURE_DEBUG);
// Create a request
BFSecureRequest * request = new BFSecureRequest();
// Only analysis will occur and no output file
// will be created regardless of other settings
request->SetOption(BFSecureOptions::JustAnalyze, true);
// Set the document to be analyzed
request->SetOption(BFSecureOptions::SourceDocument, L"c:/temp/test.doc");
// Execute the request
request->Execute();
// Get the response object
BFSecureResponse * response = request->GetSecureResponse();
// Check for success
if (response->GetBooleanResult(BFSecureOptions::WasProcessed)) {
// Print information about the document
FileFormats format = response->GetFileFormatResult(BFSecureOptions::SourceFormat);
std::wstring formatname;
BFSecureRequest::GetFileFormatName(format, formatname);
wcout << L"The file has a format of " << formatname << endl;
wcout << L"The file contains the following targets..." << endl;
// Print scrub targets that exist in the document
int scrubCount;
const ScrubOptions * so = BFSecureOptions::GetAllScrubOptions(&scrubCount);
for (int i = 0; i < scrubCount; i++) {
ScrubOptionReactions result = response->GetScrubResult(so[i]);
if (result == ScrubOption_Reaction_Exists) {
wchar_t name[1024];
BFGetOptionName(so[i],name,1024,NULL);
wcout << name << endl;
}
}
// Print analyze targets that exist in the document
int analyzeCount;
const AnalyzeOptions * ao = BFSecureOptions::GetAllAnalyzeOptions(&analyzeCount);
for (int i = 0; i < analyzeCount; i++) {
ScrubOptionReactions result = response->GetAnalyzeResult(ao[i]);
if (result == ScrubOption_Reaction_Exists) {
wchar_t name[1024];
BFGetOptionName(ao[i],name,1024,NULL);
wcout << name << endl;
}
}
} else {
// Processing failed
wcout << L"Document processing failed" << endl;
}
BFSecureRequest::Shutdown();
} catch (BFTransformException & ex) {
wcout << ex.wwhat() << endl;
wcout << ex.wextended() << endl;
BFTransformException * cause = ex.getCause();
while (cause != NULL) {
wcout << cause->wwhat() << endl;
wcout << cause->wextended() << endl;
cause = cause->getCause();
}
}
return 0;
}
using System;
using System.Collections.Generic;
using System.Text;
using System.IO;
using CleanContent;
namespace Main
{
class Program
{
static void Main(string[] args)
{
// Initialize API
SecureHelper.Startup(true);
// Create a request
SecureRequest request = new SecureRequest();
// Only analysis will occur and no output file
// will be created regardless of other settings
request.SetOption(SecureOptions.JustAnalyze, true);
// Set the document to be analyzed
request.SetOption(SecureOptions.SourceDocument, new FileInfo("c:/temp/test.doc"));
try
{
// Execute the request
request.Execute();
// Get the response object
SecureResponse response = request.GetResponse();
// Check for success
if (response.GetResult(SecureOptions.WasProcessed))
{
// Print information about the document
Console.WriteLine("The file has a format of " + response.GetResult(SecureOptions.SourceFormat).Name);
Console.WriteLine("The file contains the following targets...");
// Print a list of targets present in the document
Option[] options = SecureOptions.AllOptions;
foreach (Option option in options)
{
if (option is ScrubOption)
{
if (response.GetResult((ScrubOption)option) == ScrubOption.Reaction.EXISTS)
Console.WriteLine(option.Name);
}
else if (option is AnalyzeOption)
{
if (response.GetResult((AnalyzeOption)option) == AnalyzeOption.Reaction.EXISTS)
Console.WriteLine(option.Name);
}
}
}
else
{
// Processing failed
Console.WriteLine("Document processing failed");
}
// Close the response
response.Close();
}
catch (TransformException e)
{
// An exception occured
Console.WriteLine("Document caused an exception");
Console.WriteLine(e.ToString());
}
// Close the request
request.Close();
// Uninitialize API
SecureHelper.Shutdown();
}
}
}
Request
The SecureRequest object represents a reusable request to perform actions on a document. A single SecureRequest is created and reused to process as many documents as necessary within a separate thread (see Threading for details). SecureRequest objects act as a container for options that describe how the source document should be processed and the developer may use them as such. For example, if a developer needed to process documents in three different ways depending on the situation they might create three SecureRequest objects, load each with the proper options (using setOption) then use the appropriate one for each document.
XML Persistence
The SecureRequest object includes readXML and writeXML methods that allow its state (the options that have been set using setOption) to be written to and read from an XML file. While the XML is fairly self explanatory, the schema is not fixed and is currently not documented so developers should resist the urge to generate XML in this schema themselves.
Response
After a call to a SecureRequest object's execute method the developer should retrieve a SecureResponse object using the getResponse method and then query this object for the results of the processing using its getResult methods. Like the SecureRequest object's setOption method the SecureResponse object's getResult method takes options contained in the SecureOptions class. Options that are valid to provide to getResult include the following.
ProcessingStatus
Provides the result of processing the document. Returns one of the following:
- ProcessingStatusOption.Processed
The document was successfully processed. All of the options and targets below are valid.
- ProcessingStatusOption.NotIdentified
The file format of the document could not be determined. Only LoggedError and LoggedWarning options are valid.
- ProcessingStatusOption.NotSupported
The file format of the document was determined but is not supported by Clean Content. Only SourceFormat, LoggedError and LoggedWarning options are valid.
- ProcessingStatusOption.CausedException
The document caused an exception during processing. Only SourceFormat, LoggedError and LoggedWarning options are valid.
- ProcessingStatusOption.Timeout
Document processing was interrupted because it took longer than the value in the RequestTimeout option. Only SourceFormat, LoggedError and LoggedWarning options are valid.
SourceFormat
The file format of the source document.
LoggedError
True if an error was logged, false if not.
LoggedWarning
True if a warning was logged, false if not.
ScrubbedFormat
The file format of the scrubbed document. If null is returned then the file format is the same as the SourceFormat (see above). If a file format is returned then the format was changed. Currently this only occurs when macros are scrubbed from a Office 2007/2010 document that contains macros. In these cases the extension of the scrubbed document must be changed or Office 2007/2010 will not open the scrubbed document! The new extension can be retrieved from the file format using the getExtension method. For example, if a Word document with macros (.docm) is scrubbed and macros are removed then this option will return FileFormat.WORD2007 while the SourceFormat (see above) option will be FileFormat.WORD2007MACROS.
The file format of the scrubbed document. If null is returned, then the file format is the same as the SourceFormat. If a file format is returned, then the format was changed. Currently, this only occurs when macros are scrubbed from an Office 2007/2010 document that contains macros. In these cases, the extension of the scrubbed document must be changed, or Office 2007/2010 will not open the scrubbed document. The new extension can be retrieved from the file format using the getExtension method. For example, if a Word document with macros (.docm) is scrubbed and macros are removed, then this option will return FileFormat.WORD2007 while the SourceFormat option will be FileFormat.WORD2007MACROS.
DecryptionStatus
Provides information about decryption of the processed document. Returns one of the following:
- DecryptionStatusOption.NotEncrypted
The document was not encrypted.
- DecryptionStatusOption.DecryptedWithDefaultPassword
Parts of the document were encrypted and have been decrypted using one of the passwords baked into the original application.
- DecryptionStatusOption.DecryptedWithPasswordList
Parts of the document were encrypted and have been decrypted using one of the passwords provided through the PasswordList option.
- DecryptionStatusOption.DecryptionFailed
Parts of the document were encrypted but could not be decrypted with any of the default or PasswordList passwords. If a UI is available this would likely trigger a password dialog box for the user.
- DecryptionStatusOption.DecryptionNotSupported
Parts of the document were encrypted but the encryption method is not supported by Clean Content.
WasProcessed deprecated
True if the document was successfully processed, false if not.
WasIdentified deprecated
True if the format of the document could be determined, false if not.
WasSupported deprecated
True if the document's file format is supported. For example, we may be able to identify some document types (like RTF, WordPerfect, etc.) but do not currently support processing them.
WasException deprecated
True if an exception was thrown during processing. Even though the developer's code will catch the exception, the SecureResponse can still be retrieved and will reflect the fact an exception was thrown.
WasTimeout deprecated
True if processing was interrupted because it took longer than the value in the RequestTimeout option, false if not.
In addition to the options above, any target (see Targets below) may be passed to getResult in order to determine if that target exists in the source document and if it was removed.
Below are code samples for complete Java, C++ and C# programs that deal with all possible results in SecureResponse.
import net.bitform.api.secure.SecureRequest;
import net.bitform.api.secure.SecureOptions;
import net.bitform.api.secure.SecureResponse;
import net.bitform.api.options.ScrubOption;
import net.bitform.api.options.EnumOptionValue;
import net.bitform.api.FileFormat;
import net.bitform.api.SharedOptions;
import java.io.File;
import java.io.IOException;
public class Response {
public static void main(String[] args) {
// Create a request
SecureRequest request = new SecureRequest();
// Set the default scrubbing behavior to NONE
request.setOption(SecureOptions.DefaultScrubBehavior, ScrubOption.Action.NONE);
// Set just Macros and Code to be scrubbed
request.setOption(SecureOptions.MacrosAndCode,ScrubOption.Action.SCRUB);
// Set the document to be scrubbed.
// In this case it's a Word 2007 document containing macros
File sourceDocument = new File("c:/temp/test.docm");
request.setOption(SecureOptions.SourceDocument, sourceDocument);
// Set the scrubbed document
File scrubbedDocument = new File("c:/temp/out/",sourceDocument.getName());
request.setOption(SecureOptions.ScrubbedDocument, scrubbedDocument);
IOException requestException = null;
try {
// Execute the request
request.execute();
} catch (IOException ex) {
// Save the exception
requestException = ex;
}
// Get the response object
// Note that the request is still valid (and can be reused) after an exception
SecureResponse response = request.getResponse();
// Do complete result check
EnumOptionValue status = response.getResult(SecureOptions.ProcessingStatus);
if (status == SecureOptions.ProcessingStatusOption.Processed) {
FileFormat sourceFormat = response.getResult(SecureOptions.SourceFormat);
System.out.println("The document "+sourceDocument.getName()+
" was identified as "+sourceFormat.getName()+" and was processed correctly.");
FileFormat scrubbedFormat = response.getResult(SecureOptions.ScrubbedFormat);
if (scrubbedFormat != null) {
// The file format (and therefore the file extension) has changed so we
// need to rename the scrubbed document. This code just renames the scrubbed file
// by tacking on the new extension.
File newScrubbedDocument = new File(scrubbedDocument.getParentFile(),
scrubbedDocument.getName()+"."+scrubbedFormat.getExtension());
if (newScrubbedDocument.exists()) newScrubbedDocument.delete();
scrubbedDocument.renameTo(newScrubbedDocument);
}
} else if (status == SecureOptions.ProcessingStatusOption.NotIdentified) {
System.out.println("The document "+sourceDocument.getName()+" could not be identified.");
} else if (status == SecureOptions.ProcessingStatusOption.NotSupported) {
FileFormat sourceFormat = response.getResult(SecureOptions.SourceFormat);
System.out.println("The document "+sourceDocument.getName()+
" was identified as "+sourceFormat.getName()+" but that format is not supported.");
} else if (status == SecureOptions.ProcessingStatusOption.CausedException) {
System.out.println("The document "+sourceDocument.getName()+" caused an exception.");
if (requestException != null) requestException.printStackTrace();
} else if (status == SecureOptions.ProcessingStatusOption.Timeout) {
FileFormat sourceFormat = response.getResult(SecureOptions.SourceFormat);
System.out.println("The document "+sourceDocument.getName()+
" was identified as "+sourceFormat.getName()+" but processing timed out.");
} else {
System.out.println("Invalid ProcessingStatus! This will never happen.");
}
if (response.getResult(SecureOptions.LoggedWarning)) {
System.out.println("Warnings were logged.");
}
if (response.getResult(SecureOptions.LoggedError)) {
System.out.println("Errors were logged.");
}
}
}
#include <iostream>
#include <tchar.h>
#include <malloc.h>
using namespace std;
#include "secureapi.h"
#ifdef BFWIN
#include <windows.h>
#endif
int main(int argc, _TCHAR* argv[])
{
// Initialize the Clean Content API
BFSecureRequest::Startup(BFSTARTUPFEATURE_DEBUG);
// Create a request
BFSecureRequest * request = new BFSecureRequest();
// Set the default scrubbing behavior to NONE
request->SetOption(BFSecureOptions::DefaultScrubBehavior,ScrubOption_Action_None);
// Set just Macros and Code to be scrubbed
request->SetOption(BFSecureOptions::MacrosAndCode,ScrubOption_Action_Scrub);
// Set the document to be scrubbed
// In this case it's a Word 2007 document containing macros
std::wstring sourceDocument(L"c:/temp/test.docm");
request->SetOption(BFSecureOptions::SourceDocument, sourceDocument);
// Set the scrubbed document
std::wstring scrubbedDocument(L"c:/temp/out/test.docm");
request->SetOption(BFSecureOptions::ScrubbedDocument, scrubbedDocument);
// Execute the request
BFTransformException requestException;
try {
request->Execute();
} catch (BFTransformException & ex) {
// Note that we just collect the exception information
// here. Exceptions do not put the request in an invalid
// state so 'normal' retreval of the response may continue.
// The response will show that the request caused an
// exception.
requestException = ex;
}
// Get the response object
BFSecureResponse * response = request->GetSecureResponse();
// Get the status
int status = response->GetEnumResult(BFSecureOptions::ProcessingStatus);
switch(status) {
case SecureOptions_ProcessingStatus_Processed:
{
FileFormats sourceFormat = response->GetFileFormatResult(BFSecureOptions::SourceFormat);
std::wstring sourceFormatName;
BFSecureRequest::GetFileFormatName(sourceFormat, sourceFormatName);
wcout << L"The document " << sourceDocument <<
" was identified as " << sourceFormatName <<
" and was processed correctly." << endl;
FileFormats scrubbedFormat = response->GetFileFormatResult(BFSecureOptions::ScrubbedFormat);
if (scrubbedFormat != NULL) {
// The file format (and therefore the file extension) has changed so we
// need to rename the scrubbed document. This code just renames the scrubbed
// file by tacking on the new extension.
//
// In this particular case the scrubbed .docm file must be renamed .docx
// or it will not open in Microsoft Office.
std::wstring scrubbedFormatExtension;
BFSecureRequest::GetFileFormatExtension(scrubbedFormat, scrubbedFormatExtension);
std::wstring newScrubbedDocument(scrubbedDocument);
newScrubbedDocument.append(L".");
newScrubbedDocument.append(scrubbedFormatExtension);
_wremove(newScrubbedDocument.c_str());
_wrename(scrubbedDocument.c_str(),newScrubbedDocument.c_str());
}
}
break;
case SecureOptions_ProcessingStatus_NotIdentified:
wcout << L"The document " << sourceDocument <<
" could not be indentified." << endl;
break;
case SecureOptions_ProcessingStatus_NotSupported:
{
FileFormats sourceFormat = response->GetFileFormatResult(BFSecureOptions::SourceFormat);
std::wstring sourceFormatName;
BFSecureRequest::GetFileFormatName(sourceFormat, sourceFormatName);
wcout << L"The document " << sourceDocument <<
" was identified as " << sourceFormatName <<
" but that format is not supported." << endl;
}
break;
case SecureOptions_ProcessingStatus_CausedException:
{
wcout << L"The document " << sourceDocument <<
" caused an exception." << endl;
wcout << requestException.wwhat() << endl;
wcout << requestException.wextended() << endl;
BFTransformException * cause = requestException.getCause();
while (cause != NULL) {
wcout << cause->wwhat() << endl;
wcout << cause->wextended() << endl;
cause = cause->getCause();
}
}
break;
case SecureOptions_ProcessingStatus_Timeout:
wcout << L"The document " << sourceDocument <<
" timed out." << endl;
break;
}
BFSecureRequest::Shutdown();
return 0;
}
using System;
using System.Collections.Generic;
using System.Text;
using System.IO;
using CleanContent;
namespace Main
{
class Response
{
static void Main(string[] args)
{
// Initialize API
SecureHelper.Startup(true);
// Create a request
SecureRequest request = new SecureRequest();
// Set the default scrubbing behavior to NONE
request.SetOption(SecureOptions.DefaultScrubBehavior, ScrubOption.Action.NONE);
// Set just Macros and Code to be scrubbed
request.SetOption(SecureOptions.MacrosAndCode, ScrubOption.Action.SCRUB);
// Set the document to be analyzed
// In this case it's a Word 2007 document containing macros
FileInfo sourceDocument = new FileInfo("c:/temp/test.docm");
request.SetOption(SecureOptions.SourceDocument, sourceDocument);
// Set the scrubbed document
FileInfo scrubbedDocument = new FileInfo("c:/temp/out/" + sourceDocument.Name);
request.SetOption(SecureOptions.ScrubbedDocument, scrubbedDocument);
// Execute the request
TransformException requestException = null;
try
{
request.Execute();
}
catch (TransformException e)
{
requestException = e;
}
// Get the response object
SecureResponse response = request.GetResponse();
// Get status
FileFormat sourceFormat = response.GetResult(SecureOptions.SourceFormat);
int status = response.GetResult(SecureOptions.ProcessingStatus);
switch (status)
{
case SecureOptions.ProcessingStatusOption.Processed:
Console.WriteLine("The document " + sourceDocument.Name +
" was identified as '" + sourceFormat.Name +
"' and was processed correctly.");
FileFormat scrubbedFormat = response.GetResult(SecureOptions.ScrubbedFormat);
if (scrubbedFormat != null)
{
// The file format (and therefore the file extension) has
// changed so we need to rename the scrubbed document.
// This code just renames the scrubbed file by appending
// the new extension.
//
// In this particular case the scrubbed .docm file must be
// renamed .docx or it will not open in Microsoft Office.
FileInfo newScrubbedDocument = new FileInfo(scrubbedDocument.FullName +
"." + scrubbedFormat.Extension);
if (newScrubbedDocument.Exists) newScrubbedDocument.Delete();
scrubbedDocument.MoveTo(newScrubbedDocument.FullName);
}
int decryptionStatus = response.GetResult(SecureOptions.DecryptionStatus);
switch (decryptionStatus)
{
case SecureOptions.DecryptionStatusOption.NotEncrypted:
// Standard case
break;
case SecureOptions.DecryptionStatusOption.DecryptedWithDefaultPassword:
Console.WriteLine("The document is encrypted and was " +
"decrypted with the default passsword");
break;
case SecureOptions.DecryptionStatusOption.DecryptedWithPasswordList:
// This won't happen here because the code above does not
// provide a password list.
Console.WriteLine("The document is encrypted and was " +
"decrypted with the one of the passwords provided");
break;
case SecureOptions.DecryptionStatusOption.DecryptionFailed:
Console.WriteLine("The document is encrypted and " +
"could not be decrypted with either the default " +
"or provided passwords");
break;
case SecureOptions.DecryptionStatusOption.DecryptionNotSupported:
Console.WriteLine("The document is encrypted and " +
"the encryption format is not supported ");
break;
}
break;
case SecureOptions.ProcessingStatusOption.Timeout:
Console.WriteLine("The document " + sourceDocument.Name +
" was identified as " + sourceFormat.Name +
" but processing timed out.");
break;
case SecureOptions.ProcessingStatusOption.NotSupported:
Console.WriteLine("The document " + sourceDocument.Name +
" was identified as " + sourceFormat.Name +
" but that format is not supported.");
break;
case SecureOptions.ProcessingStatusOption.NotIdentified:
Console.WriteLine("The document " + sourceDocument.Name +
" could not be identified.");
break;
case SecureOptions.ProcessingStatusOption.CausedException:
Console.WriteLine("The document " + sourceDocument.Name +
" caused an exception.");
Console.WriteLine(requestException.ToString());
break;
}
// Close the response
response.Close();
// Close the request
request.Close();
// Uninitialize API
SecureHelper.Shutdown();
}
}
}
Document IO
The SourceDocument, ScrubbedDocument, ResultDocument, ResultTranform, ExportDocument, ExportReplacementDocument options all require the developer to provide a stream of bytes. In the case of the ScrubbedDocument, ResultDocument and ExportDocument options the stream of bytes must be writable. The developer has several ways to do this.
Normal file
If the file is on a local or remote storage then a path name is the easiest way to provide a document to the API. To accomplish this in Java a File object is provided, in C/C++ a path name is provided and in .NET a FileInfo object is provided.
Java InputStream
Even though an InputStream is a valid type for the SourceDocument option, the execute method will throw an exception unless the InputStream is an instance of FileInputStream. The same is true for using OutputStream with the ResultDocument and ScrubbedDocument options. The reason for this has to do with the nature of the file formats being processed. These formats dictate that the parser seek all over the document in order to parse it correctly. Since an InputStream is non-seekable Clean Content would have to buffer the entire document in memory in order to work correctly. It was felt that doing such a memory intensive process "behind the back" of the developer was not acceptable. Developers that need to process InputStream objects using Clean Content should read them into a ByteBuffer and pass the ByteBuffer to the SourceDocument option.
Any kind of InputStream may be provided to the ResultTransform option.
In memory
In some instances the developer has a document already in memory or needs a document written to memory. "On the wire" email attachment processing is a good example of this. In these cases the document can be passed directly to the API without the need to persist it to storage. To accomplish this in Java a ByteBuffer is provided, in C/C++ a pointer to memory is provided and in .NET a MemoryStream is provided.
ISSUE: In the case of output documents (ScrubbedDocument, ResultDocument and ExportDocument) a developer using the C/C++ interface has no way of knowing how much of the memory block provided was filled with output. A long term solution to this issue is in the works but for now C/C++ developers can use a channel (see Channel section and sample code below) to resolve this issue. The following sample code shows the workaround for this issue.
#include <iostream>
#include <tchar.h>
#include <malloc.h>
using namespace std;
#include "secureapi.h"
#ifdef BFWIN
#include <windows.h>
#endif
int main(int argc, _TCHAR* argv[])
{
try {
// Initialize the Clean Content API
BFSecureRequest::Startup(BFSTARTUPFEATURE_DEBUG);
// Create a request
BFSecureRequest * request = new BFSecureRequest();
// Scrub everything
request->SetOption(BFSecureOptions::JustAnalyze,FALSE);
request->SetOption(BFSecureOptions::DefaultScrubBehavior,ScrubOption_Action_Scrub);
// Define a channel that writes to an expandable memory buffer
class MyChannel: public BFChannel {
private:
char * buf;
long bufincrement;
long bufsize;
long filesize;
public:
MyChannel(long inc) {
buf = new char[inc];
bufincrement = inc;
bufsize = inc;
filesize = 0;
}
long Read(void * buffer, BFINT32 count, BFINT64 position) {
cout << "Read " << count << " bytes at " << position << endl;
if (position >= filesize) {
return 0;
}
if (position+count > filesize) {
count = filesize-position;
}
memcpy(buffer,&(buf[position]),count);
return count;
}
void Write(void * buffer, BFINT32 count, BFINT64 position) {
cout << "Write " << count << " bytes at " << position << endl;
if (position+count > filesize) filesize = position+count;
if (filesize > bufsize) {
// Enlarge buffer
long newbufsize = bufsize + bufincrement;
while (filesize > newbufsize) newbufsize += bufincrement;
char * newbuf = new char[newbufsize];
memcpy(newbuf,buf,bufsize);
delete buf;
buf = newbuf;
bufsize = newbufsize;
cout << "Buffer enlarged to " << bufsize << " bytes" << endl;
}
memcpy(&(buf[position]),buffer,count);
}
BFINT64 Size() {
return filesize;
}
long Supports() {
return BFCHANNELCANWRITE | BFCHANNELCANREAD;
}
void Close() {
// Write out the buffer to a file
FILE * out = _wfopen(L"c:/temp/test.channel.doc",L"wb");
fwrite(buf,1,filesize,out);
fclose(out);
}
void Truncate(BFINT64 size) {
filesize = size;
}
};
// Set the document to be scrubbed
request->SetOption(BFSecureOptions::SourceDocument, L"c:/temp/test.doc");
// Create a channel for the scrubbed document with a starting buffer size and increment of 20k bytes
MyChannel mychannel = MyChannel(1024*20);
// Set the scrubbed document
request->SetOption(BFSecureOptions::ScrubbedDocument, &mychannel);
// Add some properties to check that increasing the size of the ScrubbedDocument works
for (int i = 0; i < 1000; i++) {
wchar_t name[128];
wchar_t value[128];
wsprintf(name,L"CustomProperty%i",i);
wsprintf(value,L"This is the value of custom property %i",i);
SecureOptions_StringProperty prop;
BFNewStringProperty(name,name,&prop,NULL);
request->SetOption(prop.action,SecureOptions_Properties_Action_AddOrReplace);
request->SetOption(prop.newValue,value);
}
// Execute the request
request->Execute();
// Get the response object
BFSecureResponse * response = request->GetSecureResponse();
// Check for success
if (response->GetBooleanResult(BFSecureOptions::WasProcessed)) {
// Print information about the document
FileFormats format = response->GetFileFormatResult(BFSecureOptions::SourceFormat);
std::wstring formatname;
BFSecureRequest::GetFileFormatName(format, formatname);
wcout << L"The file has a format of " << formatname << endl;
} else {
// Processing failed
wcout << L"Document processing failed" << endl;
}
BFSecureRequest::Shutdown();
} catch (BFTransformException & ex) {
wcout << ex.wwhat() << endl;
wcout << ex.wextended() << endl;
BFTransformException * cause = ex.getCause();
while (cause != NULL) {
wcout << cause->wwhat() << endl;
wcout << cause->wextended() << endl;
cause = cause->getCause();
}
}
return 0;
}
Channel
Sometimes a file exists in a non-traditional storage medium that cannot be referenced by an operating system path. A file saved in a database BLOB is an example of this. In this case, the application can provide its own "channel" to the document by implementing a few simple functions like Read, Size, Close, etc. To accomplish this in Java a SimpleChannel is provided, in C/C++ a pointer to a list of functions is provided and in .NET a Stream is provided.
Targets
Clean Content's main focus is on the discovery (analysis) and removal (scrubbing) of various parts of documents (targets) that represent security or disclosure risks. The possible targets for analysis and scrubbing make up the bulk of the options in SecureOptions. Developers should carefully review these targets to clearly understand the implications of scrubbing them.
Any given target may be set to one of the following values.
Default
Use the value of the special DefaultScrubBehavior target
None
Don't perform any action on the target. Setting a target to this value does not guarantee that the target will not be analyzed and reported on, only that such an analysis is not necessary. None acts just like Analyze for most targets except those that take significant additional processing to analyze.
Analyze
Report the existence of the target but don't attempt to scrub or otherwise remove it
Scrub
Report the existence of the target and remove it
Alternative Text 

Risk level
Description
Each graphic image and shape in a document may include an optional piece of text that can be used in place of the image when viewing the document in a constrained environment.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
There is very limited risk associated with alternative text. However, since this text is only accessible through formatting options associated with the image, it may be overlooked during a visual review of the document prior to release.
Applies to
Microsoft Word 97 thru 2003
Microsoft Excel 97 thru 2003
Microsoft PowerPoint 97 thru 2003
Microsoft Word 2007 and above
Microsoft Excel 2007 and above
Microsoft PowerPoint 2007 and above
In Java
SecureOptions.AlternativeText
In C
SecureOptions_AlternativeText
In C++
BFSecureOptions::AlternativeText
In C#
SecureOptions.AlternativeText
Apps For Office
Risk level
Description
Apps for Office allow for integration of 3rd party applications into the Office applications using web technologies. There are two types of Web extensions; content and taskpane. Web extensions enable 3rd party applications to tightly integrate into Office using web based interfaces like JavaScript, HTML5, CSS3. A Web extension runs inside of a web page frame within Office. The web page is served by some web server and the page has access to the Office document object model allowing rich feature connections between document content and the 3rd party web app. Content extensions contribute to content directly within a frame of the document. Taskpane extensions enable user interactions that enhance the authoring process but don’t directly generate document content (for example a dictionary app).
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Apps for Office provides for an interaction between document content and a remote web server that opens a certain risk level regardless of the security strength employed to prevent intrusion.
Applies to
Microsoft Word 2007 and above
Microsoft PowerPoint 2007 and above
Microsoft Excel 2007 and above
In Java
SecureOptions.AppsForOffice
In C
SecureOptions_AppsForOffice
In C++
BFSecureOptions::AppsForOffice
In C#
SecureOptions.AppsForOffice
Audio and Video Paths
Risk level
Description
Microsoft PowerPoint supports linking to audio and video files using the 'Insert > Movies and Sounds > Movie from File' and 'Insert > Movies and Sounds > Sound from File' commands. Use of this feature results in storing a potentially sensitive link to a local or network file path. Note that this type of path can also be removed only when it is considered sensitive using the Sensitive Content Links target .
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
The storage of an external local or network file path caused by linking to audio and video files exposes an organization to multiple risks. The first risk is that sensitive information may be contained in the directory hierarchy exposed by the path. For example, the directory structure may use a taxonomy that includes information such as a client’s name or identifier. The second risk is that the path information can provide a view into the corporate network topology. This opens an organization to a network intrusion risk. While this risk is mitigated by proper network security, it remains a social engineering threat by providing confidential information to hackers attempting to infiltrate a corporate network. The social engineering risk is elevated when path information is combined with other sensitive data like valid user names, email addresses, and email subject lines.
Applies to
Microsoft PowerPoint 97 thru 2003
Microsoft PowerPoint 2007 and above
In Java
SecureOptions.AudioVideoFilePaths
In C
SecureOptions_AudioVideoFilePaths
In C++
BFSecureOptions::AudioVideoFilePaths
In C#
SecureOptions.AudioVideoFilePaths
Author History
Risk level
Description
Up to the last 10 authors that saved the document are stored in an area of the document that is inaccessible using the Word application. In Word 97 and Word 2000 this information also contains the paths where the document was saved and may include sensitive user logon or network share information.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
The saving of the author history within Microsoft Word documents poses several risks including exposure of personal information, local or network paths, and an audit trail of previous revisions. Personal information will typically include the user names associated with the last 10 revisions of the document. Local or network paths will identify where each revision was saved, opening the risks associated with exposing file paths. The combination of user names and file paths provides an audit trail of previous revisions that may not be desirable. The risk associated with exposing this information often depends on the type of document being considered and the potential reviewers of the document. For example, documents that may be targets of legal discovery and documents that may be published to the web pose a higher risk than other documents.
Applies to
Microsoft Word 97 thru 2003
In Java
SecureOptions.AuthorHistory
In C
SecureOptions_AuthorHistory
In C++
BFSecureOptions::AuthorHistory
In C#
SecureOptions.AuthorHistory
Associated options
The following options affect the behavior of the Author History target.
AuthorHistoryContainsPaths
The hidden author history contains the last 10 fully qualified path names where the document was saved.
AuthorHistoryContainsShares
The hidden author history contains network share names. This information can provide dangerous insight into an organization's internal network.
Clipped Text
Risk level
Description
The PDF file format allows a clipping path to be established that limits the region of the page affected by painting operations including text drawing. The page boundary inherently establishes the initial clipping region and it can be adjusted from there as needed. This target detects the existence of text that is drawn outside the current clipping region and is therefore not visible.
Default behavior
Discovers but does not scrub the target
Risk
Text drawn outside the current clipping region is not visible when displayed by viewing applications. This may occur for a variety of reasons and may result in the unintentional disclosure of information. For example, spreadsheet cells that have wrapping turned off, and presentations with text boxes moved off slide, may result in clipped text when printed to PDF.
Applies to
Adobe PDF
In Java
SecureOptions.ClippedText
In C
SecureOptions_ClippedText
In C++
BFSecureOptions::ClippedText
In C#
SecureOptions.ClippedText
Color Obfuscated Text
Risk level
Description
The font color of some document text closely matches the background color of the text resulting in text that is not visible in the authoring application. This feature targets the more common ways to obfuscate text by setting the text color to match a solid background color and includes consideration for numerous cases where the background is inherited from underlying objects. Complex backgrounds that include underlying images, objects, shapes, and transparency may inadvertantly generate false positives and false negatives.
Default behavior
Discovers but does not scrub the target
Risk
Making a font color closely match the background color can result in certain text being obfuscated to casual readers of a document. This may occur accidentally or be used as means to hide text at various points in the document life cycle and may result in the unintentional disclosure of information.
Applies to
Microsoft Word 97 thru 2003
Microsoft Excel 97 thru 2003
Microsoft PowerPoint 97 thru 2003
Microsoft Word 2007 and above
Microsoft Excel 2007 and above
Microsoft PowerPoint 2007 and above
Adobe PDF
In Java
SecureOptions.ColorObfuscatedText
In C
SecureOptions_ColorObfuscatedText
In C++
BFSecureOptions::ColorObfuscatedText
In C#
SecureOptions.ColorObfuscatedText
Associated options
The following options affect the behavior of the Color Obfuscated Text target.
ColorObfuscatedTextRemediation
Option that effects how remediation of color obfuscated text is performed.
Comments
Content Properties
Risk level
Description
Content properties are viewable in Office using the 'File > Properties > Contents' command. They are document properties that provide a view into some of the content within the document. These properties include: Title and Headings in Word documents, Sheet Names and Named Ranges in Excel documents, and Fonts Used, Design Template, and Slide Titles in PowerPoint documents.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Content properties, for the most part, represent little or no risk since they primarily mirror some visible content from the document. An exception to this rule occurs when an Office document is encrypted but the content properties remain accessible. This hole in the Office encryption feature has been closed in recent versions. However, patching the application will not address existing documents unless they are loaded and resaved by the updated application.
Applies to
Microsoft Word 97 thru 2003
Microsoft Excel 97 thru 2003
Microsoft PowerPoint 97 thru 2003
Microsoft Word 2007 and above
Microsoft Excel 2007 and above
Microsoft PowerPoint 2007 and above
In Java
SecureOptions.ContentProperties
In C
SecureOptions_ContentProperties
In C++
BFSecureOptions::ContentProperties
In C#
SecureOptions.ContentProperties
Custom Properties
Risk level
Description
Custom document properties can be created using the 'File > Properties > Custom' command. They may include user defined properties or application generated properties. Custom properties include: Checked by, Client, Date completed, Department, Destination, Disposition, Division, Document number, Editor, Forward to, Group, Language, Mailstop, Matter, Office, Owner, Project, Publisher, Purpose, Received from, Recorded by, Recorded date, Reference, Source, Status, Telephone number, Typist, and all other user defined properties and application generated properties.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
The risk associated with custom properties varies according to their use. Custom properties are often used by software applications to associate metadata with a document. For example, content management systems may use custom properties to assist document categorization and facilitate tracking the document lifecycle. Custom properties are also used by individual users to assist in categorization or carry additional information about the document. Depending on the implementation this information may range from innocuous to highly sensitive.
Applies to
Microsoft Word 97 thru 2003
Microsoft Excel 97 thru 2003
Microsoft PowerPoint 97 thru 2003
Microsoft Word 2007 and above
Microsoft Excel 2007 and above
Microsoft PowerPoint 2007 and above
Adobe PDF
In Java
SecureOptions.CustomProperties
In C
SecureOptions_CustomProperties
In C++
BFSecureOptions::CustomProperties
In C#
SecureOptions.CustomProperties
Custom XML
Risk level
Description
Custom XML data added to the document through various means
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Arbirary XML could contain almost any information. This is most likely a problem in cases where a malicious user is attempting to hide information inside a document.
In Word 2007 the XML Structure feature allows XML-like information to be included inline with the text of the document.
Some tools (including Microsoft SharePoint) add additional information to Office 2007 and above documents using CustomXMLParts.
In Word 2003 the XML Structure feature allows XML tags to be included inline with the text of the document.
Office Binary files may contain an additional storage named MsoDataStore that includes custom xml parts for the purpose of round tripping custom xml with new versions of Office.
Office Binary files may contain an additional storage named MsoDataStore that includes custom xml parts for the purpose of round tripping custom xml with new versions of Office.
Office Binary files may contain an additional storage named MsoDataStore that includes custom xml parts for the purpose of round tripping custom xml with new versions of Office.
Applies to
Microsoft Word 2007 and above
MSOOX
Microsoft Word 2003
Microsoft Excel 97 thru 2003
Microsoft Word 97 thru 2003
Microsoft PowerPoint 97 thru 2003
In Java
SecureOptions.CustomXML
In C
SecureOptions_CustomXML
In C++
BFSecureOptions::CustomXML
In C#
SecureOptions.CustomXML
Database Queries
Risk level
Description
Microsoft Office supports powerful connectivity to databases that results in database connection and query information being stored in Office documents. This information may include a path or URL to a database server, the database username, database password and SQL query strings, all of which can be highly sensitive information.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
The use of database queries to bring external data into Excel is a powerful feature that comes with several serious security risks. Specifically, this feature creates the potential that unauthorized users will be able to independently query a sensitive database at will. In order to allow the query to be updated, whether user initiated or automatic, the document retains the database query parameters. This information may include a file path or URL reference to the database server, SQL query strings that identify the requested data, and the password required to access the database. A file path to the database server opens all of the security threats associated with exposing file paths. SQL query strings can be used to infer the structure of the database. Storing the database password in the Office document is an option the user may choose when creating the query. This option is often activated in order to avoid having to re-enter the password each time the data is updated. This information opens an organization to SQL injection attacks. Proper network security may prevent any external access to the database server but this provides little peace of mind in the event of a network security breach. Internal access, however, may represent an even greater threat since the recipients of the sensitive information are likely behind the firewall but possibly prohibited from accessing the database. Consider an example where the finance department distributes a spreadsheet that at face value simply includes a list of employees by department, but buried within the underlying query lies all the information required to access an employee database filled with confidential data. Extreme caution should be used when releasing spreadsheets that contain database queries.
Applies to
Microsoft Word 97 thru 2003
Microsoft Word 2007 and above
Microsoft Excel 97 thru 2003
Microsoft Excel 2007 and above
In Java
SecureOptions.DatabaseQueries
In C
SecureOptions_DatabaseQueries
In C++
BFSecureOptions::DatabaseQueries
In C#
SecureOptions.DatabaseQueries
Default scrub behavior
Description
Defines the behavior of a ScrubOption that has the value of DEFAULT. Setting this option to DEFAULT itself has the same effect as setting it to NONE.
Default behavior
Discovers but does not scrub the target
Applies to
All formats
In Java
SecureOptions.DefaultScrubBehavior
In C
SecureOptions_DefaultScrubBehavior
In C++
BFSecureOptions::DefaultScrubBehavior
In C#
SecureOptions.DefaultScrubBehavior
Document Variables
Risk level
Description
Document variables are named pieces of data that can be attached to PowerPoint documents.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Document variables carry the risk of exposing sensitive information that was not intended to be distributed with the document. These variables are typically added to a document by 3rd party Office add-ins and serve the purpose of supporting features of the add-in across multiple edits of the document by saving data into the document. This data is often harmless programming state information but can be any data and can also be attached to and retrieved from the document using visual basic programming.
Document variables can be added to Microsoft PowerPoint files using visual basic code to attach name/value pairs to the document, slides, or specific shapes. Depending on usage, this information may include sensitive textual content that is not intended to be released with the document. This data is not readily accessible to the user from the application interface.
Applies to
Microsoft PowerPoint 97 thru 2003
In Java
SecureOptions.DocumentVariables
In C
SecureOptions_DocumentVariables
In C++
BFSecureOptions::DocumentVariables
In C#
SecureOptions.DocumentVariables
Embedded Objects
Risk level
Description
The Office embedded object feature (Insert > Object..) allows embedding an object into the document that is created and served by another application. The resulting object data may then contain any of the hidden and sensitive data issues found in the serving application. Adobe PDF documents may include attached documents through the embedded files feature of the PDF format. Files embedded in a PDF document are detected under this analysis option.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Office applications leverage embeddings to seamlessly work with each other as well as with other applications to create compound documents. Including a spreadsheet table in a Word document or a chart in a presentation is common and useful. In order for any application to allow an embedding to be edited in its native application, the primary document includes a complete copy of the application data associated with the object. This data is in addition to the graphic rendition of the object that is used for display and printing. It is in this data that security risks can be found. Any security threat that has been identified in documents created by an application can also manifest itself when that application serves an embedding. An additional security concern has been found to exist when using embeddings within documents that have been encrypted using the Office security options. Surprisingly, embedded objects are not encrypted along with the primary document. For example, if an Excel chart is added to a Word document that is then encrypted using Word’s security options, the chart and the entire supporting spreadsheet will be left unencrypted within the Word document. Scrubbing embeddings will remove the ability to make further edits to the embedding while maintaining the most recent graphic rendition of the object. Adobe PDF documents include a feature defined as embedded files that are detected with this option. Files embedded within a PDF document carry a risk because they can also be automatically launched via actions that can be attached to form fields and other automated actions.
Applies to
Microsoft Word 97 thru 2003
Microsoft Word 2007 and above
Microsoft Excel 97 thru 2003
Microsoft Excel 2007 and above
Microsoft Excel 2007 Binary
Microsoft PowerPoint 97 thru 2003
Microsoft PowerPoint 2007 and above
Adobe PDF
In Java
SecureOptions.EmbeddedObjects
In C
SecureOptions_EmbeddedObjects
In C++
BFSecureOptions::EmbeddedObjects
In C#
SecureOptions.EmbeddedObjects
Encryption
Risk level
Description
The document is encrypted and most analysis and scrubbing requests cannot be accomplished. This is distinguished from ScrubOptions.WeakProtectionin that it cannot be easily circumvented short of brute force or dictionary based password attacks. However, using the Microsoft Office encryption feature (Tools > Options > Security > Password to open) does not encrypt the entire document, potentially leaving document properties and embeddings into Word and Excel unencrypted. Both Office and PDF documents can be encrypted with a default password. Clean Content will test the default password and decrypt the document when used on PowerPoint and PDF documents.
Default behavior
Discovers but does not scrub the target
Risk
Encrypting documents using the Microsoft Office security options can provide a strong level of security against unauthorized access to documents. However, this form of encryption does not always safeguard the entire content of the document. Specifically, document properties and embeddings can remain unencrypted leaving the unsuspecting author vulnerable to unexpected information exposure. Additionally, issues with the Office encryption implementation have been published and reported to Microsoft. It can be expected that Microsoft will continue to address any holes in this area with patch releases to some versions of Office. It can also be expected that existing documents and non-patched versions of Office will continue to propagate these problems. The security threat posed by partially encrypted and poorly encrypted documents is based heavily on the document content and can range from low to very high.
Applies to
Microsoft Word 97 thru 2003
Microsoft Excel 97 thru 2003
Microsoft PowerPoint 97 thru 2003
Microsoft Word 2007 and above
Microsoft Excel 2007 and above
Microsoft PowerPoint 2007 and above
Adobe PDF
In Java
SecureOptions.Encryption
In C
SecureOptions_Encryption
In C++
BFSecureOptions::Encryption
In C#
SecureOptions.Encryption
Excel Data Model
Risk level
Description
Indicates the Excel workbook contains a relational data source and corresponding connection information to other data sources. Office Excel 2013 introduced the Data Model extension to allow integrating data from multiple tables, effectively building a relational data source inside an Excel workbook. The data model leverages a binary stream that stores a tabular data model of all data that has been imported into the data model. It also includes the definition of each data source, including connection information required for external data sources (connection strings and potentially passwords), as well as relationships between tables, user-defined hierarchical relationships between columns, and calculated columns that are a function of existing columns. Scrubbing of this data is not supported due to the complexities of disconnecting dependencies from tables, queries, pivot tables. Detection is provided to allow the risk to be surfaced and reviewed.
Default behavior
Discovers but does not scrub the target
Risk
This Excel data model provides a rich mechanism for building a relational database inside an excel file for use within sheets to produce tables, pivot tables, and pivot charts. However, it carries substantial risk in that large quantities of data and connection information can be persisted in an Excel file that may not be desirable to release even though filtered use of that data within the spreadsheet is acceptable to release.
Applies to
Microsoft Excel 2007 and above
In Java
SecureOptions.ExcelDataModel
In C
SecureOptions_ExcelDataModel
In C++
BFSecureOptions::ExcelDataModel
In C#
SecureOptions.ExcelDataModel
Extreme Cells
Risk level
Description
The Extreme Cells target indicates that ranges of spreadsheet cells within the document are located an extreme distance from other cell ranges. The definition of an extreme cell range can be controlled by setting two options; Extreme Cell Horizontal Gap Allowance and Extreme Cell Vertcal Gap Allowance.
Default behavior
Discovers but does not scrub the target
Risk
Extreme cell content may not be readily visible to casual readers of a document. This may occur accidentally or be used as a means to hide text at various points in the document life cycle and may result in the unintentional disclosure of information.
Applies to
Microsoft Excel 97 thru 2003
Microsoft Excel 2007 and above
In Java
SecureOptions.ExtremeCells
In C
SecureOptions_ExtremeCells
In C++
BFSecureOptions::ExtremeCells
In C#
SecureOptions.ExtremeCells
Associated options
The following options affect the behavior of the Extreme Cells target.
ExtremeCellHorizontalGapAllowance
This option defines the maximum number of columns allowed between two cell ranges before they are treated as being two non-contiguous cell ranges. When an otherwise contiguous block of cells are separated by a greater number of columns they may be treated as extreme cells during analysis.
ExtremeCellVerticalGapAllowance
This option defines the maximum number of rows allowed between two cell ranges before they are treated as being two non-contiguous cell ranges. When an otherwise contiguous block of cells are separated by a greater number of rows they may be treated as extreme cells during analysis.
Extreme Indenting
Risk level
Description
The Extreme Indenting target indicates that indent, margin, gutter or other settings could result in text that is off the page or outside a table or column. Such text will not display or print. Note that the existence of the Extreme Indenting target does not guarantee that text is hidden; only that text may be hidden.
Default behavior
Discovers but does not scrub the target
Risk
Moving text into positions where it is not visible to casual readers of a document. This may occur accidentally or be used as a means to hide text at various points in the document life cycle and may result in the unintentional disclosure of information.
Applies to
Microsoft Word 2007 and above
Microsoft Word 97 thru 2003
In Java
SecureOptions.ExtremeIndenting
In C
SecureOptions_ExtremeIndenting
In C++
BFSecureOptions::ExtremeIndenting
In C#
SecureOptions.ExtremeIndenting
Extreme Objects
Risk level
Description
The Extreme Objects target identifies embedded, linked, and graphic objects that have been positioned in such a way that a majority of the object may fall outside the reasonable viewing area when viewed or printed in the authoring application. This may include objects positioned outside the slide or speaker note frame in PowerPoint, and in an extreme cell range in Excel documents. Extreme objects are reported but modifications can only be made upon author review in the authoring application.
Default behavior
Discovers but does not scrub the target
Risk
Extreme objects may not be readily visible to casual readers of a document. This may occur accidentally or be used as a means to hide embeddings at various points in the document life cycle and may result in the unintentional disclosure of information.
Objects embedded into Excel spreadsheets may be considered extreme if the object is bound to cells that are located in an extreme cell range as defined by the Extreme Cells target. Note that such an object will trigger both an Extreme Object and an Extreme Cell notification.
Objects embedded into Excel spreadsheets may be considered extreme if the object is bound to cells that are located in an extreme cell range as defined by the Extreme Cells target. Note that such an object will trigger both an Extreme Object and an Extreme Cell notification.
Objects embedded into PowerPoint presentations may be considered extreme if 50% of the bounding rectangle of the embedding is positioned outside of the slide or speaker note frame.
Objects embedded into PowerPoint presentations may be considered extreme if 50% of the bounding rectangle of the embedding is positioned outside of the slide or speaker note frame.
Applies to
Microsoft Excel 97 thru 2003
Microsoft Excel 2007 and above
Microsoft PowerPoint 97 thru 2003
Microsoft PowerPoint 2007 and above
In Java
SecureOptions.ExtremeObjects
In C
SecureOptions_ExtremeObjects
In C++
BFSecureOptions::ExtremeObjects
In C#
SecureOptions.ExtremeObjects
Fast Save Data
Risk level
Description
The fast save feature in Microsoft Word and PowerPoint is set using the 'Tools > Options > Save > Allow fast saves' command. When fast save is activated deleted text and data can remain in the file even though it is no longer visible or accessible from within the application. Adobe PDF documents may also include earlier revisions of nearly any type of content through the Incremental Update feature of the file format.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
The fast save feature of Microsoft Word and PowerPoint is designed to decrease the time required to save a document to disk. This is accomplished by attaching changes to the end of the existing document rather than completely rewriting the modified document. Unfortunately, this will result in leaving deleted text and data in the document long after it was apparently removed by the user. This creates the risk of exposing the previous state of a document to recipients. A second risk is that this feature of Office can be used to transfer confidential information through documents in a way that will circumvent most content filtering technologies. The occurrence of this feature in Word documents is low because the Fast Save option was turned off by default with the release of Office 2000, though upgrading Office in place may maintain the state of this option. This risk remains a threat in existing, pre-Office 2000 Word documents. This feature is still on by default as of the current release of Microsoft PowerPoint. As a result, it is common for PowerPoint documents to include multiple prior versions. This is particularly concerning when considering the frequency with which pre-existing presentations are modified for a slightly different audience. Imagine the risk of distributing a sales presentation to one prospect that was given earlier to another prospect, knowing that the prior version is buried somewhere in the file. Adobe PDF documents include a similar feature known as Incremental Updates that is detected under this option due to its similarity to fast save.
The fast save feature is enabled by default in Word 97, enabled by default in Word 2000 if it was upgraded from Word 97 and disabled by default in new installations of Word 2000 and above. It can be enabled by the user in all versions of Word.
The fast save feature is enabled by default in all versions of PowerPoint and results in many versions of modified slides remaining in the file.
The incremental update feature of Adobe PDF may be implemented by PDF generation tools that make modifications to an existing PDF document.
Applies to
Microsoft Word 97 thru 2003
Microsoft PowerPoint 97 thru 2003
Adobe PDF
In Java
SecureOptions.FastSaveData
In C
SecureOptions_FastSaveData
In C++
BFSecureOptions::FastSaveData
In C#
SecureOptions.FastSaveData
Headers and Footers
Hidden Cells
Risk level
Description
Spreadsheet rows, columns, or worksheets that have been hidden. Hidden cells may contain sensitive data that requires user review prior to release. Hidden cells can be identified during analysis and can be made visible by setting the Unhide Hidden Cells option. Hidden cells are not deleted or cleared when cleaned since they may be required to resolve references from visible cells.
Default behavior
Discovers but does not scrub the target
Risk
It is common for spreadsheets to include entire columns, rows, or even sheets of data that are hidden from view. This is often done to prevent recipients from accessing sensitive information. The hidden data might be necessary in order to support a less sensitive calculation or chart. For example, a sheet of employee salaries may support a chart that shows relative salary expense by department. The salary data is sensitive but the chart is not. Unfortunately, simply hiding the cells does not safeguard access to the data since recipients can simply unhide the cells. Using sheet protection with a password is a common approach to prevent recipients from accessing hidden cells. However, this safeguard is a weak form of protection because the feature does not encrypt the underlying hidden data and can be easily disabled by hacking a few bytes in the file. Workbook and file level security options with passwords can be used to prevent modifications and encrypt the underlying data thus providing stronger security. Consequently, hiding cells within unencrypted documents should never be considered a secure method of preventing unauthorized access to those cells. Due to the fact that hidden cells may support visible cell calculations, removing hidden cells requires modification by the user directly within the application.
Applies to
Microsoft Excel 97 thru 2003
Microsoft Excel 2007 and above
In Java
SecureOptions.HiddenCells
In C
SecureOptions_HiddenCells
In C++
BFSecureOptions::HiddenCells
In C#
SecureOptions.HiddenCells
Hidden Slides
Risk level
Description
The PowerPoint hidden slide feature (Slide Show > Hide Slide) allows individual slides to be hidden during the slide show and printing of the presentation. Hidden slides may contain information that is not intended for general release.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Hidden slides are often used to tailor a presentation to a particular audience or to adjust a presentation to meet a required time allotment. In many cases, exposing the hidden slides does not represent any type of privacy or security concern. In some cases, however, the hidden slide may contain data not intended for the target audience, creating a risk of leaking sensitive information. Any presentation that contains hidden slides should be reviewed prior to distribution in order to determine whether the slide should be removed.
Applies to
Microsoft PowerPoint 97 thru 2003
In Java
SecureOptions.HiddenSlides
In C
SecureOptions_HiddenSlides
In C++
BFSecureOptions::HiddenSlides
In C#
SecureOptions.HiddenSlides
Hidden Text
Risk level
Description
Text that has been intentionally hidden (Format > Font... > Font > Hidden) by the user may contain sensitive information that should be reviewed or removed before distributing the document.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
The use of hidden text exposes the author to unintended information disclosure. Hidden text may be used for internal commentary, temporary display and print removal, or as a method of deleting text so that it can be later retrieved if desired. It is less common to find hidden text that provides intended useful content because this is usually done with comments. Releasing documents that contain hidden text to third parties is considered a high security risk when not first reviewed by the author.
Applies to
Microsoft Word 97 thru 2003
Microsoft Word 2007 and above
In Java
SecureOptions.HiddenText
In C
SecureOptions_HiddenText
In C++
BFSecureOptions::HiddenText
In C#
SecureOptions.HiddenText
Hybrid Excel 95 97 Book Stream
Risk level
Description
Microsoft substantially changed the Excel format between Excel 95 and Excel 97. In order to maintain backwards compatbility with Excel 95 it was possible to store both versions of the file inside the XLS document. This target detects and optionally scrubs the 'Book' stream that hodls the Excel 95 version of the workbooks.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
The 'Book' stream in a Hybrid Excel document essentially holds a duplicate copy of the workbooks found in an Excel document. Scrubbing this stream will remove any risk associated with the content in this stream. Clean Content does not scrub the contents of the Book stream based on specific targets but instead allows the entire stream to be removed with this target.
Applies to
Microsoft Excel 97 thru 2003
In Java
SecureOptions.HybridExcel9597BookStream
In C
SecureOptions_HybridExcel9597BookStream
In C++
BFSecureOptions::HybridExcel9597BookStream
In C#
SecureOptions.HybridExcel9597BookStream
Invalid XML
Risk level
Description
Many applications that use XML formats, especially Microsoft's Office, do not strictly follow the XML format's schema when writing out documents. This target indicates that one or more invalid elements have been found and ignored.
Default behavior
Discovers but does not scrub the target
Risk
Invalid elements pose two problems. First they may contain extra hidden data that is not visible to the user in the application. Second, although Office itself might open the document, other readers such as viewers on smartphones, search engines, etc. may not be able to process the document.
In Java
SecureOptions.InvalidXML
In C
SecureOptions_InvalidXML
In C++
BFSecureOptions::InvalidXML
In C#
SecureOptions.InvalidXML
Unknown XML
Risk level
Description
Many applications that use XML formats, especially Microsoft's Office, have situations where any element may appear or an particular namespace may be ignored. This target indicates that such an element is in a namespace that is not known and can therefore cannot be validated.
Default behavior
Discovers but does not scrub the target
Risk
Unknown elements are a risk only if intentional hiding and disclosure of data is concern.
In Java
SecureOptions.UnknownXML
In C
SecureOptions_UnknownXML
In C++
BFSecureOptions::UnknownXML
In C#
SecureOptions.UnknownXML
Linked Objects
Risk level
Description
The Office linked object feature (Insert > Object...) allows linking to an external file that is managed and rendered by another application. These links can expose local and network path information.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Office applications enable the primary document to include references to external documents that are then rendered directly into the primary document. Using this feature stores a file path or URL to the external document within the primary document. This is done to allow automatic updates to the primary document that incorporate changes to the linked document and to allow direct authoring of the external document within the primary document framework. The existence of path information that supports this feature opens an organization to network intrusion and social engineering risks. Removing the link information can be done without affecting the most recent rendering of the linked object.
Applies to
Microsoft Word 97 thru 2003
Microsoft Word 2007 and above
Microsoft PowerPoint 2007 and above
Microsoft Excel 2007 and above
Microsoft Excel 97 thru 2003
Microsoft PowerPoint 97 thru 2003
In Java
SecureOptions.LinkedObjects
In C
SecureOptions_LinkedObjects
In C++
BFSecureOptions::LinkedObjects
In C#
SecureOptions.LinkedObjects
Macros and Code
Risk level
Description
Microsoft Office includes support for Visual Basic and can be used to create everything from simple macros to data entry forms to full blown applications. Visual Basic can also be used to create macro viruses that travel with documents. Adobe PDF documents may contain code in the form of Java Script.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
The risk associated with macros and code being present within inbound documents is a well known virus threat. The risk associated with outbound documents includes the unintended redistribution of viruses and the potential disclosure of sensitive information contained within an otherwise valid macro. Information disclosure can come in the form of user names, code comments, and potentially confidential approaches to programmatically accessing corporate resources. Macros and code are often used to support the document creation process but are not intended or desired in the final version of the document. In other examples, macros and code provide important and useful functions to the recipient as might be the case with controls and forms. Determining the risk associated with releasing documents that contain macros and code typically requires user review.
Adobe PDF documents may contain code in the form of Java Script.
Applies to
Microsoft Word 97 thru 2003
Microsoft Word 2007 and above
Microsoft Excel 2007 and above
Microsoft Excel 2007 Binary
Microsoft PowerPoint 2007 and above
Microsoft Excel 97 thru 2003
Microsoft PowerPoint 97 thru 2003
Adobe PDF
In Java
SecureOptions.MacrosAndCode
In C
SecureOptions_MacrosAndCode
In C++
BFSecureOptions::MacrosAndCode
In C#
SecureOptions.MacrosAndCode
Meeting Minutes
Risk level
Description
Meeting minutes can be attached to PowerPoint documents with the PowerPoint Meeting Minder feature and are typically associated with an action item list. The action item list is included in the presentation as part of a slide or series of slides. The associated minutes are accessible only through the Meeting Minder user interface.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Meeting minutes may be unexpectedly released with a presentation because the minutes are not displayed as part of any slide but instead require manual review of the Meeting Minder minutes and may therefore be overlooked during review.
Applies to
Microsoft PowerPoint 97 thru 2003
In Java
SecureOptions.MeetingMinutes
In C
SecureOptions_MeetingMinutes
In C++
BFSecureOptions::MeetingMinutes
In C#
SecureOptions.MeetingMinutes
Office GUID Property
Risk level
Description
The Office GUID property is a document property created by versions of Microsoft Office prior to the release of Office 2000. This globally unique identifier (GUID) can be used to identify the computer from which the document originated.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Documents containing the Office GUID property expose an organization or individual to the risk of losing anonymity. The Office GUID property can be used to uniquely identify the machine on which a document originated. It can also be used to determine if multiple documents originated on the same machine. This property is no longer stored in Office documents as of the release of Office 2000 and is consequently now considered a low risk element. Archived documents and documents created with older versions of Office are still at risk of this disclosure.
Applies to
Microsoft Word 97 thru 2003
Microsoft Excel 97 thru 2003
Microsoft PowerPoint 97 thru 2003
In Java
SecureOptions.OfficeGUIDProperty
In C
SecureOptions_OfficeGUIDProperty
In C++
BFSecureOptions::OfficeGUIDProperty
In C#
SecureOptions.OfficeGUIDProperty
Office XML Rogue Parts
Risk level
Description
This target identifies the existence of parts that are not referenced or required by the document. When this target is set to Analyze and the OfficeXMLPartValidation option is enabled, the extracted output will contain a Collection element of type OfficeXMLPartDisclosureRisks that includes each rogue part using an OfficeXMLPartRisk element that provides further information about the part. Parts of this type are always removed when the OfficeXMLPartValidation option is enabled.
Default behavior
Discovers but does not scrub the target
Risk
Rogue parts are not referenced by any other part and are not required in the document under the Open Packaging Conventions. This part represents a serious disclosure risk and is always automatically removed during a Clean Content scrub process. This type of part can occur due to intentional hiding of additional files into an Office ZIP container or due to the use of the 'trash' feature of the Open Packaging Conventions.
Applies to
Microsoft Word 2007 and above
Microsoft Excel 2007 and above
Microsoft PowerPoint 2007 and above
In Java
SecureOptions.OfficeXMLRogueParts
In C
SecureOptions_OfficeXMLRogueParts
In C++
BFSecureOptions::OfficeXMLRogueParts
In C#
SecureOptions.OfficeXMLRogueParts
Office XML Unexpected Parts
Risk level
Description
This target identifies the existence of parts that may represent a disclosure risk if the offending part is not further inspected by human or machine review. When this target is set to Analyze and the OfficeXMLPartValidation option is enabled, the extracted output will contain a Collection element of type OfficeXMLPartDisclosureRisks that includes each unexpected part using an OfficeXMLPartRisk element that provides further information about the part.
Default behavior
Discovers but does not scrub the target
Risk
Unexpected parts are part that are referenced in a context that Clean Content does not understand and therefore the part could not be analyzed. This type of part is not removed by the scrubbing process because doing so may break the document structure. This part can represent either an intentional disclosure risk or be a valid part that Clean Content does not yet process.
Applies to
Microsoft Word 2007 and above
Microsoft Excel 2007 and above
Microsoft PowerPoint 2007 and above
In Java
SecureOptions.OfficeXMLUnexpectedParts
In C
SecureOptions_OfficeXMLUnexpectedParts
In C++
BFSecureOptions::OfficeXMLUnexpectedParts
In C#
SecureOptions.OfficeXMLUnexpectedParts
Office XML Unanalyzed Parts
Risk level
Description
This target identifies the existence of parts that may represent a disclosure risk if the offending part is not scrubbed from the document or further inspected by human or machine review. When this target is set to Analyze and the OfficeXMLPartValidation option is enabled, the extracted output will contain a Collection element of type OfficeXMLPartDisclosureRisks that includes each unanalyzed part using an OfficeXMLPartRisk element that provides further information about the part.
Default behavior
Discovers but does not scrub the target
Risk
Unanalyzed Parts are used an expected and valid context that is understood by Clean Content but the part data is not analyzed by Clean Content. This type of part may happen with binary and certain custom xml parts. Some, like the printer settings part, may be removed during a scrub process under a particular scrub target. Others, like embedded font parts, may require external analysis to determine the level of risk.
Applies to
Microsoft Word 2007 and above
Microsoft Excel 2007 and above
Microsoft PowerPoint 2007 and above
In Java
SecureOptions.OfficeXMLUnanalyzedParts
In C
SecureOptions_OfficeXMLUnanalyzedParts
In C++
BFSecureOptions::OfficeXMLUnanalyzedParts
In C#
SecureOptions.OfficeXMLUnanalyzedParts
Office XML Alternate Content Parts
Risk level
Description
This target identifies the existence of parts that may represent a disclosure risk if the offending part is not scrubbed from the document or further inspected by human or machine review. When this target is set to Analyze and the OfficeXMLPartValidation option is enabled, the extracted output will contain a Collection element of type OfficeXMLPartDisclosureRisks that includes each Alternate Content Choice part using an OfficeXMLPartRisk element that provides further information about the part.
Default behavior
Discovers but does not scrub the target
Risk
The Office Open XML specification includes an extension that allows portions of document content to be defined in multiple forms. This type of part is one that is referenced from within the Choice context of an Alternate Content block. The Clean Content scrub process is designed to always remove the Choice portion of AlternateContent and retain the Fallback portion. This type of part is considered a disclosure risk only because it is not always accessible to human review from the authoring application.
Applies to
Microsoft Word 2007 and above
Microsoft Excel 2007 and above
Microsoft PowerPoint 2007 and above
In Java
SecureOptions.OfficeXMLAlternateContentParts
In C
SecureOptions_OfficeXMLAlternateContentParts
In C++
BFSecureOptions::OfficeXMLAlternateContentParts
In C#
SecureOptions.OfficeXMLAlternateContentParts
Outlook Properties
Risk level
Description
Outlook properties are custom document properties that may be added by Microsoft Outlook to Office documents when they are sent as attachments. These properties include the author, email address, subject of the email, and review cycle identifiers associated with the attachment.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
The Microsoft Outlook practice of adding email metadata properties into Office attachments can result in unintended and sensitive information disclosure. The property metadata may include the sender’s email address, email display name, routing identifiers, and the subject line of the email message to which the document was attached. Disclosing this information to the recipient of the email message does not represent a direct threat because the recipient receives most of this information from the email headers by default. However, inserting this information into the attached documents without any user intervention or awareness allows this information to continue to travel with the document well beyond the initial email recipient. If the document is subsequently published to the web it will publicly expose a valid email address, the associated user display name, and a valid related email subject line. The dangers of this release of information can range from simple embarrassment to confidential leaks and, at minimum, present spammers with additional opportunity.
Applies to
Microsoft Word 97 thru 2003
Microsoft Excel 97 thru 2003
Microsoft PowerPoint 97 thru 2003
In Java
SecureOptions.OutlookProperties
In C
SecureOptions_OutlookProperties
In C++
BFSecureOptions::OutlookProperties
In C#
SecureOptions.OutlookProperties
Overlapped Objects
Risk level
Description
The Overlapped Objects target identifies embedded, linked, and graphic objects that have been covered by another object thus obscuring some portion of the underlying object. At least 50% of an object must be covered to be treated as overlapped. Overlapped objects are reported but modifications can only be made upon author review in the authoring application.
Default behavior
Discovers but does not scrub the target
Risk
Overlapped objects may not be readily visible to casual readers of a document. This may occur accidentally or be used as a means to hide embeddings at various points in the document life cycle and may result in the unintentional disclosure of information.
Applies to
Microsoft Excel 2007 and above
Microsoft Excel 97 thru 2003
Microsoft PowerPoint 2007 and above
Microsoft PowerPoint 97 thru 2003
In Java
SecureOptions.OverlappedObjects
In C
SecureOptions_OverlappedObjects
In C++
BFSecureOptions::OverlappedObjects
In C#
SecureOptions.OverlappedObjects
Overlapped Text
Risk level
Description
Text may be covered by graphics elements that are drawn after the text operations. This target detects specific use cases where that may occur including rectangles and thick lines that are a known source of poor PDF text redaction. Detection of overlapped text is limited to specific use cases due to the complexity of the transparent imaging model. However, the common cases associated with poor text redaction are covered.
Default behavior
Discovers but does not scrub the target
Risk
Overlapped text is not visible when displayed by viewing applications. This may occur for a variety of reasons and may result in the unintentional disclosure of information. There have been many cases of poorly redacted PDF documents that have a black rectangle covering text that cannnot be seen but is still accessible through copy and paste operations.
Applies to
Adobe PDF
In Java
SecureOptions.OverlappedText
In C
SecureOptions_OverlappedText
In C++
BFSecureOptions::OverlappedText
In C#
SecureOptions.OverlappedText
PDF Actions
Risk level
Description
The PDF format supports a set of interactive features called actions. Example actions include jumping to a particular destination in a document, thread, or URI location, launching an external file, playing a sound or movie, importing or submitting form data, executing JavaScript code, and numerous other interactive features. Actions can be associated with outline items, annotations, form fields, pages, or the document as a whole and can be triggered based on specific user or document interactions like opening the document, viewing a page, or selecting an outline item. Each triggering event can execute one or more actions in sequence. Each type of action is given its own scrub target while this target is provided to cover all actions in a single target.
Default behavior
Discovers but does not scrub the target
Risk
Each type of action poses a particular type of risk. Some, like launching a file or executing JavaScript can be very risky while others like jumping a page in the document have minimal risk. The risk associated with each individual action is covered under the action specific target.
Applies to
Adobe PDF
In Java
SecureOptions.PDFActions
In C
SecureOptions_PDFActions
In C++
BFSecureOptions::PDFActions
In C#
SecureOptions.PDFActions
Sub-targets
The following targets are sub-targets of the PDF Actions target.
PDF GoTo Actions
Risk level
Description
The GoTo action can be executed from a variety of triggering events and causes the Viewer software to change the current view of the document to specific location within the document.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
The GoTo action poses minimal risks since it simply describes a destination location in the current document.
Applies to
Adobe PDF
In Java
SecureOptions.PDFGoToActions
In C
SecureOptions_PDFGoToActions
In C++
BFSecureOptions::PDFGoToActions
In C#
SecureOptions.PDFGoToActions
PDF GoToR Actions
Risk level
Description
The GoToR (Go to remote location) action can be executed from a variety of triggering events and causes the Viewer software to change the current view to a specific location in another PDF file.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
The GoToR action poses two types of risk. First, the description of the PDF file to load is stored as a file specification that can disclose network share information. Second, the action may launch an unsanitized external PDF file that may pose any of the many security risks associated with PDF documents.
Applies to
Adobe PDF
In Java
SecureOptions.PDFGoToRActions
In C
SecureOptions_PDFGoToRActions
In C++
BFSecureOptions::PDFGoToRActions
In C#
SecureOptions.PDFGoToRActions
PDF GoToE Actions
Risk level
Description
The GoToE (Go to remote location) action can be executed from a variety of triggering events and causes the Viewer software to change the current view to a specific location in another PDF file that is embedded in this or another PDF file..
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
The GoToE action poses two types of risk. First, the embedding to load can be located in another PDF file as a file specification that can disclose network share information. Second, the action may launch an unsanitized external or embedded PDF file that may pose any of the many security risks associated with PDF documents.
Applies to
Adobe PDF
In Java
SecureOptions.PDFGoToEActions
In C
SecureOptions_PDFGoToEActions
In C++
BFSecureOptions::PDFGoToEActions
In C#
SecureOptions.PDFGoToEActions
PDF Launch Actions
Risk level
Description
The Launch action can be executed from a variety of triggering events and causes the Viewer software to launch an application or open or print a document.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
The launch action is a very risky for multiple reasons. First, it executes an external application that may result in a data attack risk. Second, it stores the location of the application or document to launch as a file specfication or platform specific commands resulting in a data disclosure risk.
Applies to
Adobe PDF
In Java
SecureOptions.PDFLaunchActions
In C
SecureOptions_PDFLaunchActions
In C++
BFSecureOptions::PDFLaunchActions
In C#
SecureOptions.PDFLaunchActions
PDF Thread Actions
Risk level
Description
The Thread action can be executed from a variety of triggering events and causes the Viewer software to change the current view of the document to specific location in an article thread within the document.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
A thread action, similar to the GoTo action, poses minimal risks since it simply describes a destination location in the current document.
Applies to
Adobe PDF
In Java
SecureOptions.PDFThreadActions
In C
SecureOptions_PDFThreadActions
In C++
BFSecureOptions::PDFThreadActions
In C#
SecureOptions.PDFThreadActions
PDF URI Actions
Risk level
Description
The URI action can be executed from a variety of triggering events and causes the Viewer software to resolve and open a resource described by a Uniform Resource Identifier.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
The URI action can be executed due to a user interaction like clicking on a hyperlink or be atuomatically activated when a document is opened or combined with other actions in a sequence. This action can lead to a malicious PDF launching a URI that is an exploit or site containing an exploit, resulting in a data attack risk. Since the URI can reference a network share there is also a risk of data disclosure.
Applies to
Adobe PDF
In Java
SecureOptions.PDFURIActions
In C
SecureOptions_PDFURIActions
In C++
BFSecureOptions::PDFURIActions
In C#
SecureOptions.PDFURIActions
PDF Sound Actions
Risk level
Description
The Sound action can be executed from a variety of triggering events and causes the Viewer software to play the associated sound object.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
The Sound action can be used to initiate a data attack in a malformed PDF by leveraging an exploit in the player software. The stream associated with sounds may also contain author or source information that represents a data disclosure risk.
Applies to
Adobe PDF
In Java
SecureOptions.PDFSoundActions
In C
SecureOptions_PDFSoundActions
In C++
BFSecureOptions::PDFSoundActions
In C#
SecureOptions.PDFSoundActions
PDF Movie Actions
Risk level
Description
The Movie action can be executed from a variety of triggering events and causes the Viewer software to play the associated movie object that is stored as an external file.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
The Movie action can be used to initiate a data attack in a malformed PDF by leveraging an exploit in the player software. Since the location of the movie is described as a file specification and can reference a network share there is also a risk of data disclosure. There is also a risk of intential data disclosure because the action may only play a clip from a larger movie while leaving the remainder of the movie hidden from view but still accessible.
Applies to
Adobe PDF
In Java
SecureOptions.PDFMovieActions
In C
SecureOptions_PDFMovieActions
In C++
BFSecureOptions::PDFMovieActions
In C#
SecureOptions.PDFMovieActions
PDF Hide Actions
Risk level
Description
The Hide action can be executed from a variety of triggering events and causes the Viewer software to change the visibility of annotations and form fields.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
The Hide action represents a significant data hiding risk because it can hide the existence of annotations and form fields.
Applies to
Adobe PDF
In Java
SecureOptions.PDFHideActions
In C
SecureOptions_PDFHideActions
In C++
BFSecureOptions::PDFHideActions
In C#
SecureOptions.PDFHideActions
PDF Named Actions
Risk level
Description
The Named action can be executed from a variety of triggering events and causes the Viewer software to change the current view of the document to a specific named location in the current document. The supported named locations include NextPage, PrevPage, FirstPage, LastPage.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
The Named action generally represents minimal risk because it simply describes a predefined destination location in the current document. However, the specification allows for the use of non-portable named locations that may pose a minor risk.
Applies to
Adobe PDF
In Java
SecureOptions.PDFNamedActions
In C
SecureOptions_PDFNamedActions
In C++
BFSecureOptions::PDFNamedActions
In C#
SecureOptions.PDFNamedActions
PDF Set OCG State Actions
Risk level
Description
The Set OCG State action can be executed from a variety of triggering events and sets the state of one or morel optional content groups.Optional content refers to sections of content in a PDF document that can be selectively viewed or hidden. Optional content features are typically seen in interactive PDF documents like CAD drawings or Maps.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
The Set OCG State represents a risk because it can dynamically cause portions of documents to be hidden form view.
Applies to
Adobe PDF
In Java
SecureOptions.PDFSetOCGStateActions
In C
SecureOptions_PDFSetOCGStateActions
In C++
BFSecureOptions::PDFSetOCGStateActions
In C#
SecureOptions.PDFSetOCGStateActions
PDF Rendition Actions
Risk level
Description
The Rendition action can be executed from a variety of triggering events and controls the playback of multimedia content. The rendition action was introduced in PDF 1.5 to allow a far richer mechanism to control multimedia playback than supported by the earlier release Movie and Sound actions. Rendition actions can make use of extensive options to describe the location and sequence of multimedia content, the player to be used, allow for JavaScript execution to further control the playback, as well as many other parameters. Rendition actions are closely tied to a Screen annotation that specifies the region of a page where media clips are played.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
The Rendition action can be used to initiate a data attack in a malformed PDF by leveraging an exploit in the player software. Since the location of the media can be described as a file specification and can reference a network share there is also a risk of data disclosure. There is also a risk of unintential data disclosure because the action may only play a clip from a larger movie while leaving the remainder of the movie hidden from view but still accessible. Lastly, since a Rendition action can cause the execution of JavaScript it carries all of the risks associated with JavaScript execution.
Applies to
Adobe PDF
In Java
SecureOptions.PDFRenditionActions
In C
SecureOptions_PDFRenditionActions
In C++
BFSecureOptions::PDFRenditionActions
In C#
SecureOptions.PDFRenditionActions
PDF GoTo3D View Actions
Risk level
Description
The GoTo3D View action can be executed from a variety of triggering events and controls the view of a 3D annotation. PDF supports a rich collection of features to define and view three-dimensional objects, such as those used by CAD software. This action targets a 3D annotation and can change how the 3D artwork appears to the user by setting parameters such as lighting, rendering, and projection that control the virtual camera illustrating the 3D artwork.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
The GoTo3D View action can modify the view of 3D artwork and thus presents a hidden data risk.
Applies to
Adobe PDF
In Java
SecureOptions.PDFGoTo3DViewActions
In C
SecureOptions_PDFGoTo3DViewActions
In C++
BFSecureOptions::PDFGoTo3DViewActions
In C#
SecureOptions.PDFGoTo3DViewActions
PDF Rich Media Actions
PDF JavaScript Actions
Risk level
Description
The JavaScript action can be executed from a variety of triggering events and causes Javascript code to be executed by the Java interpreter supported by the PDF Viewer. This is often used to dynamically control the view of a PDF document, particularly forms.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
The execution of JavaScript found with a PDF document presents a significant data risk attack and has become one of the most common methods of delivering exploits. Note that developers of PDF malware have gone to great extremes to hide dangerous JavaScript inside PDF documents in ways that are not easily detected by scanning filters.
Applies to
Adobe PDF
In Java
SecureOptions.PDFJavaScriptActions
In C
SecureOptions_PDFJavaScriptActions
In C++
BFSecureOptions::PDFJavaScriptActions
In C#
SecureOptions.PDFJavaScriptActions
PDF Submit Form Actions
PDF Reset Form Actions
PDF Import Data Actions
Risk level
Description
The Import Data action imports Forms Data Format (FDF), XFSD, or XML into the interactive form fields of the PDF document and can be executed from a variety of triggering events.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
The Import Data action present the risk of introducing new content from an external file that may not have been sanitized. This data may be sensitive or malicious presenting a data disclosure risk. The name of the external file may also present a data disclosure risk. It is also possible that the imported data presents a data attack risk if not formatted properly.
Applies to
Adobe PDF
In Java
SecureOptions.PDFImportDataActions
In C
SecureOptions_PDFImportDataActions
In C++
BFSecureOptions::PDFImportDataActions
In C#
SecureOptions.PDFImportDataActions
PDF Transition Actions
Risk level
Description
The Transition action is used in a sequence of actions to define transition appearances during the sequence. It can be executed from a variety of triggering events.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
The Transition action can control the display of a document and presents some risk that normally visible data appears hidden when executed in a specified sequence.
Applies to
Adobe PDF
In Java
SecureOptions.PDFTransitionActions
In C
SecureOptions_PDFTransitionActions
In C++
BFSecureOptions::PDFTransitionActions
In C#
SecureOptions.PDFTransitionActions
PDF Unknown Actions
Risk level
Description
Clean Content supports scrub targets for all PDF actions defined through Version 1.7 and the supplement to ISO 32000. Any PDF action that is not in the list of supported action is treated as an Unknown action. The most likely occurrence of an Unknown action is either due to an PDF file specification update supporting new actions or due to an attempt to create a custom action.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
An Unknown action presents a data disclosure risk because the action structures may be used to store any sort of data.
Applies to
Adobe PDF
In Java
SecureOptions.PDFUnknownActions
In C
SecureOptions_PDFUnknownActions
In C++
BFSecureOptions::PDFUnknownActions
In C#
SecureOptions.PDFUnknownActions
PDF Alternate Images
Risk level
Description
Alternate images are additional versions of an image that may be used by readers though there is no clear description on when or why.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Applies to
Adobe PDF
In Java
SecureOptions.PDFAlternateImages
In C
SecureOptions_PDFAlternateImages
In C++
BFSecureOptions::PDFAlternateImages
In C#
SecureOptions.PDFAlternateImages
PDF Deprecated Postscript Objects
Risk level
Description
Postscript objects embedded inside PDF documents. These objects are no longer recommended to be included in PDF documents.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Applies to
Adobe PDF
In Java
SecureOptions.PDFDeprecatedPostscriptObjects
In C
SecureOptions_PDFDeprecatedPostscriptObjects
In C++
BFSecureOptions::PDFDeprecatedPostscriptObjects
In C#
SecureOptions.PDFDeprecatedPostscriptObjects
PDF Alternate Presentations
Risk level
Description
Alternate Presentations allow a PDF document to be viewed in a slide show like manner. PDF 1.4 allowed a page to be viewed for a specified duration before moving into an automatic or user enabled page transition phase. PDF 1.5 allowed for a more extensive, JavaScript driven, alternate presentation rendering. This PDF feature is seldom used and has ben deprecated by ISO 32000-1. This target addresses both forms.
Default behavior
Discovers but does not scrub the target
Risk
Alternate presentations carry some risk because they can be used to hide data from the user by presenting only a subset, or even a completely different rendering, of the documents content. This can be done through transition effects, using an alternate image of a page, or even ignoring pages found in the document.
Applies to
Adobe PDF
In Java
SecureOptions.PDFAlternatePresentations
In C
SecureOptions_PDFAlternatePresentations
In C++
BFSecureOptions::PDFAlternatePresentations
In C#
SecureOptions.PDFAlternatePresentations
PDF Private Application Data
Risk level
Description
The PDF file format supports storing private data in PDF documents to allow extended functionality to be created by an application. This data is stored in the Page-Piece dictionary construct described in the PDF Reference manual. For example, it is common for applications such as Adobe Illustrator and Adobe Photoshop to store additional data using this feature. The Embedded Search Index feature supported by Adobe Acrobat is also enabled using this approach.The PDF Private Application Data target provides a general target for detecting and removing any private application data found in PDF documents that leverage the PieceInfo entry to store a Page-Piece construct.
Default behavior
Discovers but does not scrub the target
Risk
Private Application Data can contain any data that a PDF application chooses to store in a PDF document. Examples include document properties, application specific metadata, and an embedded search index that may include a private form of every word in a document. It creates a significant risk of unintended data disclosure.
Applies to
Adobe PDF
In Java
SecureOptions.PDFPrivateApplicationData
In C
SecureOptions_PDFPrivateApplicationData
In C++
BFSecureOptions::PDFPrivateApplicationData
In C#
SecureOptions.PDFPrivateApplicationData
Sub-targets
The following targets are sub-targets of the PDF Private Application Data target.
PDF Embedded Search Index
Risk level
Description
Adobe Acrobat supports an option to embed a search index into a PDF document. The search index makes user searches faster, particularly in large documents. This index is a private data structure supported by Adobe and may retain content from previous versions of the document. This scrub target is a child of the more general PDF Private Application Data target in order to allow this target to be scrubbed while leaving other private application data if desired.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
The PDF Embedded Search Index is private application data used by Adobe Acrobat. Since the index may not always be up to date it may retain content from a previous version of the document.
Applies to
Adobe PDF
In Java
SecureOptions.PDFEmbeddedSearchIndex
In C
SecureOptions_PDFEmbeddedSearchIndex
In C++
BFSecureOptions::PDFEmbeddedSearchIndex
In C#
SecureOptions.PDFEmbeddedSearchIndex
PDF Other Private Application Data
Risk level
Description
The PDF file format supports storing private data in PDF documents to allow extended functionality to be created by an application. This scrub target specifically addresses private application data other than the Embedded Search Index private application data. The Embedded Search Index data is addressed by a specific target in order to provide explicit control over that use case.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Private Application Data can contain any data that a PDF application chooses to store in a PDF document. Examples include document properties, application specific metadata, and an embedded search index that may include a private form of every word in a document. It creates a significant risk of unintended data disclosure.
Applies to
Adobe PDF
In Java
SecureOptions.PDFOtherPrivateApplicationData
In C
SecureOptions_PDFOtherPrivateApplicationData
In C++
BFSecureOptions::PDFOtherPrivateApplicationData
In C#
SecureOptions.PDFOtherPrivateApplicationData
PDF Web Capture Information
PDF Legal Attestation
Risk level
Description
The PDF file format supports including information that describes the existence of any content that may result in unexpected rendering of a document. This information is commonly included in documents that also include a document certification signature. It can be used by PDF applications to determine the trustworthiness of a document. The information primarily indicates the use of certain PDF features like JavaScript, Launching, URI's, multimedia objects, and the like that may result in a document that will render differently in different environments.
Default behavior
Discovers but does not scrub the target
Risk
There is very little risk to this information with the exception that it may be inaccurate, particularly if left in a document across multiple modifications by applications that do not keep it up to date. This can result in unworthy trust of the document content.
Applies to
Adobe PDF
In Java
SecureOptions.PDFLegalAttestation
In C
SecureOptions_PDFLegalAttestation
In C++
BFSecureOptions::PDFLegalAttestation
In C#
SecureOptions.PDFLegalAttestation
PDF Digital Signatures
Risk level
Description
Digital signatures are used to authenticate the identity of the author and the contents of the document and may come in three forms. Digital signatures can be used for approval signatures, modifications and detection prevention, and to enable usage rights that are not available without the required signature.
Default behavior
Discovers but does not scrub the target
Risk
Signatures may contain information that is not viewable, introducing hidden data risk. Signatures may also reveal the identity of the author and this might be undesirable in certain environments. Scrubbing a document will almost certainly invalidate any digital signatures. Note that it is common for the use of digital signatures to be accompanied by password protected encryption that may prevent cleansing of the document entirely.
Applies to
Adobe PDF
In Java
SecureOptions.PDFDigitalSignatures
In C
SecureOptions_PDFDigitalSignatures
In C++
BFSecureOptions::PDFDigitalSignatures
In C#
SecureOptions.PDFDigitalSignatures
PDF Thumbnail Images
Risk level
Description
Thumbnail images are typically used to provide a representation of each page in a PDF document that allows viewers to quickly render an image of each page. They can also be associated with an external file reference. Thumbnails have been deprecated from use in PDF as of ISO 32000-1 and can safely be scrubbed from files.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Thumbnail images can be used to hide data from the user since they are often ignored by viewing technology in favor of regenerating an image when required.
Applies to
Adobe PDF
In Java
SecureOptions.PDFThumbnailImages
In C
SecureOptions_PDFThumbnailImages
In C++
BFSecureOptions::PDFThumbnailImages
In C#
SecureOptions.PDFThumbnailImages
PDF Annotations
Risk level
Description
The PDF format supports a set of interactive features called annotations. Example annotations include text, file attachments, watermarks, redaction, rich-media and numerous other interactive features. Each type of annotation has been categorized into a scrub target in order to provide finer control over detection and removal of the various types of annotations. This target is provided to cover all annotations in a single target.
Default behavior
Discovers but does not scrub the target
Risk
Each type of annotation poses a particular type of risk. Some, like hiding text content, referencing external links, or embedding rich media content that may present a vulnerability. The risk associated with each individual annotation is covered under the annotation specific target.
Applies to
Adobe PDF
In Java
SecureOptions.PDFAnnotations
In C
SecureOptions_PDFAnnotations
In C++
BFSecureOptions::PDFAnnotations
In C#
SecureOptions.PDFAnnotations
Sub-targets
The following targets are sub-targets of the PDF Annotations target.
PDF Text And Free Text Annotations
Risk level
Description
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Applies to
Adobe PDF
In Java
SecureOptions.PDFTextAndFreeTextAnnotations
In C
SecureOptions_PDFTextAndFreeTextAnnotations
In C++
BFSecureOptions::PDFTextAndFreeTextAnnotations
In C#
SecureOptions.PDFTextAndFreeTextAnnotations
PDF Line Markup Annotations
Risk level
Description
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Applies to
Adobe PDF
In Java
SecureOptions.PDFLineMarkupAnnotations
In C
SecureOptions_PDFLineMarkupAnnotations
In C++
BFSecureOptions::PDFLineMarkupAnnotations
In C#
SecureOptions.PDFLineMarkupAnnotations
PDF Text Markup Annotations
Risk level
Description
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Applies to
Adobe PDF
In Java
SecureOptions.PDFTextMarkupAnnotations
In C
SecureOptions_PDFTextMarkupAnnotations
In C++
BFSecureOptions::PDFTextMarkupAnnotations
In C#
SecureOptions.PDFTextMarkupAnnotations
PDF Graphical Markup Annotations
Risk level
Description
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Applies to
Adobe PDF
In Java
SecureOptions.PDFGraphicalMarkupAnnotations
In C
SecureOptions_PDFGraphicalMarkupAnnotations
In C++
BFSecureOptions::PDFGraphicalMarkupAnnotations
In C#
SecureOptions.PDFGraphicalMarkupAnnotations
PDF File Attachment Annotations
Risk level
Description
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Applies to
Adobe PDF
In Java
SecureOptions.PDFFileAttachmentAnnotations
In C
SecureOptions_PDFFileAttachmentAnnotations
In C++
BFSecureOptions::PDFFileAttachmentAnnotations
In C#
SecureOptions.PDFFileAttachmentAnnotations
PDF Screen Annotations
Risk level
Description
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Applies to
Adobe PDF
In Java
SecureOptions.PDFScreenAnnotations
In C
SecureOptions_PDFScreenAnnotations
In C++
BFSecureOptions::PDFScreenAnnotations
In C#
SecureOptions.PDFScreenAnnotations
PDF Printers Mark Annotations
Risk level
Description
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Applies to
Adobe PDF
In Java
SecureOptions.PDFPrintersMarkAnnotations
In C
SecureOptions_PDFPrintersMarkAnnotations
In C++
BFSecureOptions::PDFPrintersMarkAnnotations
In C#
SecureOptions.PDFPrintersMarkAnnotations
PDF Watermark Annotations
Risk level
Description
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Applies to
Adobe PDF
In Java
SecureOptions.PDFWatermarkAnnotations
In C
SecureOptions_PDFWatermarkAnnotations
In C++
BFSecureOptions::PDFWatermarkAnnotations
In C#
SecureOptions.PDFWatermarkAnnotations
PDF Redaction Annotations
Risk level
Description
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Applies to
Adobe PDF
In Java
SecureOptions.PDFRedactionAnnotations
In C
SecureOptions_PDFRedactionAnnotations
In C++
BFSecureOptions::PDFRedactionAnnotations
In C#
SecureOptions.PDFRedactionAnnotations
PDF Projection Annotations
Risk level
Description
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Applies to
Adobe PDF
In Java
SecureOptions.PDFProjectionAnnotations
In C
SecureOptions_PDFProjectionAnnotations
In C++
BFSecureOptions::PDFProjectionAnnotations
In C#
SecureOptions.PDFProjectionAnnotations
PDF 3D Artwork Annotations
Risk level
Description
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Applies to
Adobe PDF
In Java
SecureOptions.PDF3DArtworkAnnotations
In C
SecureOptions_PDF3DArtworkAnnotations
In C++
BFSecureOptions::PDF3DArtworkAnnotations
In C#
SecureOptions.PDF3DArtworkAnnotations
PDF Sound Annotations
Risk level
Description
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Applies to
Adobe PDF
In Java
SecureOptions.PDFSoundAnnotations
In C
SecureOptions_PDFSoundAnnotations
In C++
BFSecureOptions::PDFSoundAnnotations
In C#
SecureOptions.PDFSoundAnnotations
PDF Movie Annotations
Risk level
Description
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Applies to
Adobe PDF
In Java
SecureOptions.PDFMovieAnnotations
In C
SecureOptions_PDFMovieAnnotations
In C++
BFSecureOptions::PDFMovieAnnotations
In C#
SecureOptions.PDFMovieAnnotations
PDF Link Annotations
Risk level
Description
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Applies to
Adobe PDF
In Java
SecureOptions.PDFLinkAnnotations
In C
SecureOptions_PDFLinkAnnotations
In C++
BFSecureOptions::PDFLinkAnnotations
In C#
SecureOptions.PDFLinkAnnotations
PDF Rich Media Annotations
PDF Trap Network Annotations
Risk level
Description
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Applies to
Adobe PDF
In Java
SecureOptions.PDFTrapNetworkAnnotations
In C
SecureOptions_PDFTrapNetworkAnnotations
In C++
BFSecureOptions::PDFTrapNetworkAnnotations
In C#
SecureOptions.PDFTrapNetworkAnnotations
Presentation Notes
Risk level
Description
The PowerPoint notes feature allows notes to be associated with each slide. Notes may contain general content or internal commentary that should be reviewed or removed prior to distributing a presentation.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Presentation notes, also referred to as speaker notes, are commonly used to document specific points the speaker would like to make during the presentation. In most cases these notes represent useful additional content that can be safely shared with any recipient of the presentation document. Often times, however, these notes are written in a style that is targeted at the speaker alone and are not intended to be directly shared with the audience. In other cases, the notes are used to facilitate collaboration between multiple authors or reviewers working on the presentation. Distributing or publishing a presentation that includes speaker notes carries the risk of disclosing unintended or even confidential information.
Applies to
Microsoft PowerPoint 97 thru 2003
Microsoft PowerPoint 2007 and above
In Java
SecureOptions.PresentationNotes
In C
SecureOptions_PresentationNotes
In C++
BFSecureOptions::PresentationNotes
In C#
SecureOptions.PresentationNotes
Printer Information
Routing Slip
Risk level
Description
The email routing feature of Microsoft Office (File > Send To > Routing Recipient) stores the email addresses and user names of recipients in the document.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Email routing slips are introduced into documents that enable the document routing feature. Each routing slip may contain the email display name and email address of the originator and all recipients of the routed document. The routing slip can also contain the subject line, message body, and the date and time stamp of the routing email. This information will remain in the document after it has been routed and can expose an organization to the release of sensitive information. This exposure may be of particular concern with documents that are a target of legal discovery and documents that are made available to the public via electronic distribution or publication.
Applies to
Microsoft Word 97 thru 2003
Microsoft Excel 97 thru 2003
Microsoft PowerPoint 97 thru 2003
In Java
SecureOptions.RoutingSlip
In C
SecureOptions_RoutingSlip
In C++
BFSecureOptions::RoutingSlip
In C#
SecureOptions.RoutingSlip
Scenarios
Risk level
Description
Microsoft Excel supports entering multiple data models within specific areas of a spreadsheet (Tools > Scenario...). Once a specific scenario is selected the remaining scenarios may expose data models that should not be exposed once the document is released to an outside party.
Default behavior
Discovers but does not scrub the target
Risk
The use of the scenario feature in Excel carries the risk of unintended information disclosure. The Scenario feature provides a powerful mechanism to quickly analyze multiple models within a spreadsheet. The scenarios will often include comments, with a user name and date and time stamp, in addition to multiple data models. Scenarios are considered a low risk in terms of unintended information disclosure but do carry some risk because they will not be obvious to the author when reviewing the visible content.
Applies to
Microsoft Excel 97 thru 2003
Microsoft Excel 2007 and above
In Java
SecureOptions.Scenarios
In C
SecureOptions_Scenarios
In C++
BFSecureOptions::Scenarios
In C#
SecureOptions.Scenarios
Sensitive Content Links
Risk level
Description
Microsoft Office and Acrobat PDF include a number of features that allow referencing an external document that is then pulled into the primary document while maintaining the original link. In Microsoft Office 2007 and above, the insert picture feature is an example that allows the inserted picture to optionally retain the link to the original file. Microsoft PowerPoint through versions up to 2003 allows external links to Audio and Video files. Microsoft Word (through 2003) uses an include field to provide non-OLE based linking to external files (Insert > Field->IncludeText and Insert > Field > IncludePicture). Any of these examples may contain fully qualified local paths or network paths. A content link is considered sensitive if it begins with 'file:' or begins with a drive letter followed by a colon or it begins with two backward slashes or it matches any of the regular expressions defined using the Sensitive Links Regular Expressions option. Note that OLE based linking is handled by the Linked Objects target.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Sensitive paths and URI's carry the risk of exposing sensitive local and network file paths which can provide insight into an organization's internal network structure. The release of path information carries the risks of network intrusion, sensitive information exposure, and social engineering threats.
Applies to
Microsoft PowerPoint 97 thru 2003
Microsoft Word 97 thru 2003
Microsoft Excel 2007 and above
Microsoft PowerPoint 2007 and above
Microsoft Word 2007 and above
In Java
SecureOptions.SensitiveContentLinks
In C
SecureOptions_SensitiveContentLinks
In C++
BFSecureOptions::SensitiveContentLinks
In C#
SecureOptions.SensitiveContentLinks
Sensitive Hyperlinks
Risk level
Description
The Adobe PDF (link annotations) and the Office hyperlink feature (Insert->Hyperlink) allows the creation of links to various locations. Two of the possibilities, fully qualified local paths and network paths, can provide unwanted insight into an organization's internal structure. A hyperlink is considered sensitive if it begins with 'file:' or begins with a drive letter followed by a colon or it matches any of the regular expressions defined using the Sensitive Links Regular Expressions option.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Sensitive hyperlinks are hyperlinks to a resource located on a local or network drive. As such, they carry the risks associated with exposing path information. This includes the release of confidential network topology information and sensitive directory naming conventions. Releasing network resource names can subject an organization to network security risks through direct intrusion attempts and through social engineering attacks.
Applies to
Microsoft Word 97 thru 2003
Microsoft Word 2007 and above
Microsoft Excel 97 thru 2003
Microsoft Excel 2007 and above
Microsoft Excel 2007 Binary
Microsoft PowerPoint 97 thru 2003
Microsoft PowerPoint 2007 and above
Adobe PDF
In Java
SecureOptions.SensitiveHyperlinks
In C
SecureOptions_SensitiveHyperlinks
In C++
BFSecureOptions::SensitiveHyperlinks
In C#
SecureOptions.SensitiveHyperlinks
Sensitive INCLUDE Fields
Risk level
Description
The Microsoft Word include field feature provides non-OLE based linking to external files (Insert > Field->IncludeText and Insert > Field > IncludePicture). These fields may contain fully qualified local paths or network paths.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Sensitive INCLUDE fields carry the risk of exposing sensitive local and network file paths which can provide insight into an organization's internal network structure. The release of path information carries the risks of network intrusion, sensitive information exposure, and social engineering threats.
Applies to
Microsoft Word 97 thru 2003
Microsoft Word 2007 and above
In Java
SecureOptions.SensitiveIncludeFields
In C
SecureOptions_SensitiveIncludeFields
In C++
BFSecureOptions::SensitiveIncludeFields
In C#
SecureOptions.SensitiveIncludeFields
Size Obfuscated Text
Risk level
Description
The sizes of some of the character in the document are below the value defined by the SizeObfuscatedTextMinimum or above the value defined by SizeObfuscatedTextMaximum
Default behavior
Discovers but does not scrub the target
Risk
By making characters sizes very small or very large certain text can be obfuscated to casual readers of a document. In addition, sizes below the lower threshold may be out of conformance with government or organizational accessibility guidelines.
Applies to
Microsoft Word 97 thru 2003
Microsoft Word 2007 and above
Microsoft Excel 97 thru 2003
Microsoft Excel 2007 and above
Microsoft PowerPoint 97 thru 2003
Microsoft PowerPoint 2007 and above
In Java
SecureOptions.SizeObfuscatedText
In C
SecureOptions_SizeObfuscatedText
In C++
BFSecureOptions::SizeObfuscatedText
In C#
SecureOptions.SizeObfuscatedText
Associated options
The following options affect the behavior of the Size Obfuscated Text target.
SizeObfuscatedTextMinimum
Character sizes below this value (expressed in points) will be flaged by the SizeObfuscatedText target and will be reset to this value if SizeObfuscatedText is set to SCRUB.
SizeObfuscatedTextMaximum
Character sizes above this value (expressed in points) will be flaged by the SizeObfuscatedText target and will be reset to this value if SizeObfuscatedText is set to SCRUB.
Smart Tags
Statistic Properties
Risk level
Description
Statistic properties (File > Properties > Statistics) are document properties that include: Created, Modified, Accessed, Printed, Last saved by, Revision number, Total editing time, Pages, Paragraphs, Lines, Words, Characters, Bytes, Notes, Hidden Slides, Multimedia clips, and Presentation format. Additional application maintained properties in this category include: Application name, Hyperlinks changed flag, Links up to date flag, and Scale flag. Some or all of these properties should be reviewed or removed prior to document distribution.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Statistic properties are document properties that track editing details about the document. For example, the amount of time spent editing the document, the number of paragraphs and pages in the document, and when the document was created, last modified, or accessed. Releasing most of this information with the document raises little or no security concerns but is made available for review due to its nature as metadata. The various date and time stamp statistics might expose a level of undesirable tracking information in extremely security conscious environments, or in environments where such information can be correlated to time and billing or raise concern about a document’s creation and revision dates. Consider the scenario whereby an author is contracted to produce a document for a client, and the client discovers that the ensuing document was actually created prior to the parties’ relationship.
Applies to
Microsoft Word 97 thru 2003
Microsoft Excel 97 thru 2003
Microsoft PowerPoint 97 thru 2003
Microsoft Word 2007 and above
Microsoft Excel 2007 and above
Microsoft PowerPoint 2007 and above
Adobe PDF
In Java
SecureOptions.StatisticProperties
In C
SecureOptions_StatisticProperties
In C++
BFSecureOptions::StatisticProperties
In C#
SecureOptions.StatisticProperties
StructuredDocumentTags
Summary Properties
Risk level
Description
Summary properties (File > Properties > Summary) are document properties that include: Title, Subject, Author, Manager, Company, Category, Keywords, Comment, Hyperlink Base, Template, and Preview Picture. Some or all of these properties should be reviewed or removed prior to document distribution.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Summary properties include a collection of metadata that summarizes the document along with attributes of the author or environment of the document. This data is considered a low risk security element for most users. However, one should consider whether properties like author, category, keywords, and comment need be exposed when releasing a document to wider distribution. A second risk is that encrypted Office documents created prior to version 2003 have unencrypted document properties, partially exposing some information about a document believed to be password protected.
Applies to
Microsoft Word 97 thru 2003
Microsoft Excel 97 thru 2003
Microsoft PowerPoint 97 thru 2003
Microsoft Word 2007 and above
Microsoft Excel 2007 and above
Microsoft PowerPoint 2007 and above
Adobe PDF
In Java
SecureOptions.SummaryProperties
In C
SecureOptions_SummaryProperties
In C++
BFSecureOptions::SummaryProperties
In C#
SecureOptions.SummaryProperties
Template Name
Risk level
Description
If a template other than Normal.dot is used, the document will contain a full path to the template file. This can expose local path or network share information.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Use of templates other than Normal.dot will result in exposure of a fully qualified local or network path to the template. This element can carry all of the risks associated with exposing file paths, including network intrusion and social engineering attacks, as well as revealing confidential naming conventions.
Applies to
Microsoft Word 97 thru 2003
Microsoft Word 2007 and above
In Java
SecureOptions.TemplateName
In C
SecureOptions_TemplateName
In C++
BFSecureOptions::TemplateName
In C#
SecureOptions.TemplateName
Tracked Changes
Risk level
Description
The change tracking feature of Microsoft Office tracks insertions, deletions and formatting changes made to the document. Such changes contain deleted text and author and date information that may be unintentionally left in the document upon distribution.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Tracking changes in documents is a powerful feature that enhances the collaboration process by providing valuable change history. It can be useful for individual authoring and indispensable when multiple authors and reviewers are involved. But a very high information disclosure risk comes with this power. Documents often reach points in their lifecycle where tracked changes should either be accepted or rejected and a clean version of the document should be saved. This is required when it is no longer desirable to share the history of deletions and additions with the next group of recipients of the document. Many organizations have experienced the fallout associated with releasing a document with change tracking still enabled. The results can range from embarrassing to adversely affecting business, and depending on the sensitivity of the content, can even be used to support evidence discovery for litigation.
Applies to
Microsoft Word 97 thru 2003
Microsoft Word 2007 and above
Microsoft Excel 97 thru 2003
Microsoft Excel 2007 and above
In Java
SecureOptions.TrackedChanges
In C
SecureOptions_TrackedChanges
In C++
BFSecureOptions::TrackedChanges
In C#
SecureOptions.TrackedChanges
Uninitialized Docfile Data
Risk level
Description
The Microsoft Office binary file formats, among many other formats, leverage the Docfile file format (aka Structured Storage or Microsoft Compound File Binary File Format) to store a collection of data streams within a single file. This file allocation method allows data sectors to be allocated and freed as needed by the application (i.e. Word, Excel, and PowerPoint). This scrub target detects and optionally scrubs data sectors that are not currently in use but contain uninitialized (non-zero) data, including extra data sectors that may have been concatenated to the end of a valid file but are not intended to be part of the actual file.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Uninitialized docfile data can contain portions of previous document edits including properties, text, and images, representing an unintentional data disclosure. These logically free sectors can also be used to intentionally hide data that may not be processed by the authoring application or filtering technologies. Concatenating any file to any Office binary file format provides a simple way to hide data in what can otherwise appear to be free docfile sectors.
Applies to
Microsoft Word 97 thru 2003
Microsoft Excel 97 thru 2003
Microsoft PowerPoint 97 thru 2003
Microsoft Docfile
In Java
SecureOptions.UninitializedDocfileData
In C
SecureOptions_UninitializedDocfileData
In C++
BFSecureOptions::UninitializedDocfileData
In C#
SecureOptions.UninitializedDocfileData
User Names
Risk level
Description
A number of Office features cause user names to be saved in the document including the document properties Author and Last Saved By, document routing recipients, Word comment and tracked change authors, Excel scenario authors, file sharing participants, and the last user to edit a Microsoft Excel document or view a Microsoft PowerPoint document.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
The existence of user names in documents represents a potential privacy breach and can also create an unintended audit trail of authors. User names can be carried with comments, change tracking, email routing information, document properties, and author history, to name a few. Keeping track of the users involved in the document creation process provides useful information and is often not considered an information disclosure risk. However, user names are a form of personal information and there are many scenarios where releasing that information is not desirable. When a document is going to be shared with a larger audience, such as published to the web, the question of whether user names represent an undesired release of personal information is worth consideration. Even documents that are only shared with a small group through email may unexpectedly disclose the names of users that have touched the document at some point in its history. This risk can be classified as very serious for scenarios where there are regulatory mandates (e.g. HIPAA) that identify the release of personal information as illegal.
Applies to
Microsoft Word 97 thru 2003
Microsoft Excel 97 thru 2003
Microsoft PowerPoint 97 thru 2003
Microsoft Word 2007 and above
Microsoft Excel 2007 and above
Microsoft PowerPoint 2007 and above
Adobe PDF
In Java
SecureOptions.UserNames
In C
SecureOptions_UserNames
In C++
BFSecureOptions::UserNames
In C#
SecureOptions.UserNames
Versions
Risk level
Description
The versioning feature (File > Versions) in Microsoft Word allows multiple historical versions of a document to be saved within a single file. Versioning is useful during document creation but potentially sensitive once a document is released.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
The version feature of Microsoft Word carries with it a high risk of unintended information disclosure. This feature allows the author to archive the current state of a document into the file so that it can be extracted at a later time if required. Users that rely upon this feature as a form of version control run the risk of accidentally releasing older versions of the document that are not intended to be viewed by the recipient. The severity of this threat is heavily dependent on the sensitivity of the document content.
Applies to
Microsoft Word 97 thru 2003
In Java
SecureOptions.Versions
In C
SecureOptions_Versions
In C++
BFSecureOptions::Versions
In C#
SecureOptions.Versions
Weak Protections
Risk level
Description
Weak protections are features of an application that appear to provide a strong level of protection against specific user actions on the document but in fact can be easily removed from the file without access to a password. A protection is only considered weak if it requires a password to remove the protection. Protections that don't require passwords are considered simple but not weak since they don't imply any additional password based strength.
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
Weak protections carry the risk of leading the user to believe that controls placed on the document are safely protected when they are not. The weakness lies in the fact that because the document is not encrypted, the protection can be easily disabled by hacking the file to overwrite or clear the protection commands. Since these features do not attempt to modify the viewing of a document, they don’t pose any direct information disclosure threats. However, if the protection is removed the user will have access to more features that may indirectly expose additional information. An example of this risk occurs when assuming that a spreadsheet which includes sheet protection will effectively prevent recipients from examining hidden cells. Once sheet protection is removed the user will then be able to unhide the cells and expose potentially sensitive information.
The Microsoft Word protection features (Tools > Options... > Security > Password to modify) and (Tools > Protect Document... > Password (optional)) are weak protections because they do not result in encrypting the file and are easily circumvented with minor changes to the underlying file.
The Microsoft Excel 97 thru 2003 protection features (Tools > Options... > Security > Password to modify) and (Tools > Protection > Protect Sheet... > Password to unprotect sheet) are weak protections because they do not result in encrypting the file and are easily circumvented with minor changes to the underlying file.
The Microsoft Excel 2007 and above protection features (Save As > Tools > General Options ... > Password to modify) and (Review > Protect Sheet... > Password to unprotect sheet) are weak protections because they do not result in encrypting the file and are easily circumvented with minor changes to the underlying file.
Applies to
Microsoft Word 2007 and above
Microsoft Word 97 thru 2003
Microsoft Excel 97 thru 2003
Microsoft Excel 2007 and above
In Java
SecureOptions.WeakProtections
In C
SecureOptions_WeakProtections
In C++
BFSecureOptions::WeakProtections
In C#
SecureOptions.WeakProtections
XMP Metadata Streams
GPS location information
Risk level
Description
Metadata may have location information about the source of the document or the location of the authors or consumers
Default behavior
Uses the value of the DefaultScrubBehavior option
Risk
The existence of location information in documents represents a potential privacy breach. Keeping track of the locations involved in the document creation process provides useful information and is often not considered an information disclosure risk. However, locations are a form of personal information and there are many scenarios where releasing that information is not desirable. When a document is going to be shared with a larger audience, such as published to the web, the question of whether location information represents an undesired release of personal information is worth consideration. Even documents that are only shared with a small group through email may unexpectedly disclose the locations of users that have touched the document at some point in its history. This risk can be classified as very serious for scenarios where there are regulatory mandates (e.g. HIPAA) that identify the release of personal information as illegal.
Applies to
Exstensible Metadata Platform
In Java
SecureOptions.GPSData
In C
SecureOptions_GPSData
In C++
BFSecureOptions::GPSData
In C#
SecureOptions.GPSData
Analysis and Scrubbing
Analysis and scrubbing of documents is achieved through use of the following options.
SourceDocument
The file to be analyzed or scrubbed
ScrubbedDocument
File that will contain a scrubbed version of the SourceDocument after scrubbing
ScrubInPlace - Removed in 2009.1
Ignore the ScrubbedDocument option and scrub the SourceDocument directly
JustAnalyze
Ignore all target settings and just analyze the document without changing it or writing a scrubbed version
DefaultScrubBehavior
A "special" target that sets default behavior for any target option not explicitly set
Response
For every target there is a result (reaction) describing if the target was found and if so, if it was scrubbed. The methods in the SecureRespone object reuse the same targets.
Sample code
The following sample code scrubs and reports on just the Comments and Tracked Changes targets but leave all other targets alone.
import net.bitform.api.secure.SecureRequest;
import net.bitform.api.secure.SecureOptions;
import net.bitform.api.secure.SecureResponse;
import net.bitform.api.options.ScrubOption;
import java.io.File;
import java.io.IOException;
public class Scrub {
public static void main(String[] args) {
// Create a request
SecureRequest request = new SecureRequest();
// Set the default scrubbing behavior to NONE
request.setOption(SecureOptions.DefaultScrubBehavior,ScrubOption.Action.NONE);
// Set Comments and Tracked Changes to be scrubbed
request.setOption(SecureOptions.Comments,ScrubOption.Action.SCRUB);
request.setOption(SecureOptions.TrackedChanges,ScrubOption.Action.SCRUB);
// Set the document to be scrubbed
request.setOption(SecureOptions.SourceDocument, new File("c:/temp/test.doc"));
// Set the scrubbed document
request.setOption(SecureOptions.ScrubbedDocument, new File("c:/temp/test.scrubbed.doc"));
try {
// Execute the request
request.execute();
// Get the response object
SecureResponse response = request.getResponse();
// Check for success
if (response.getResult(SecureOptions.WasProcessed)) {
// Print information about the document
System.out.println("The file has a format of " + response.getResult(SecureOptions.SourceFormat).getName());
// Print results of scrubbing Comments and Tracked Changes
if (response.getResult(SecureOptions.Comments) == ScrubOption.Reaction.DOESNOTEXIST) {
System.out.println("The document did not contain Comments");
} else if (response.getResult(SecureOptions.Comments) == ScrubOption.Reaction.SCRUBBED) {
System.out.println("Comment were removed from the document");
}
if (response.getResult(SecureOptions.TrackedChanges) == ScrubOption.Reaction.DOESNOTEXIST) {
System.out.println("The document did not contain Tracked Changes");
} else if (response.getResult(SecureOptions.TrackedChanges) == ScrubOption.Reaction.SCRUBBED) {
System.out.println("Tracked Changes were removed from the document");
}
} else {
// Processing failed
System.out.println("Document processing failed");
}
} catch (IOException e) {
// An exception occured
System.out.println("Document caused an exception");
e.printStackTrace();
}
}
}
#include <iostream>
#include <tchar.h>
#include <malloc.h>
using namespace std;
#include "secureapi.h"
#ifdef BFWIN
#include <windows.h>
#endif
int main(int argc, _TCHAR* argv[])
{
try {
// Initialize the Clean Content API
BFSecureRequest::Startup(BFSTARTUPFEATURE_DEBUG);
// Create a request
BFSecureRequest * request = new BFSecureRequest();
// Set the default scrubbing behavior to NONE
request->SetOption(BFSecureOptions::DefaultScrubBehavior,ScrubOption_Action_None);
// Set Comments and Tracked Changes to be scrubbed
request->SetOption(BFSecureOptions::Comments,ScrubOption_Action_Scrub);
request->SetOption(BFSecureOptions::TrackedChanges,ScrubOption_Action_Scrub);
// Set the document to be scrubbed
request->SetOption(BFSecureOptions::SourceDocument, L"c:/temp/test.doc");
// Set the scrubbed document
request->SetOption(BFSecureOptions::ScrubbedDocument, L"c:/temp/test.scrubbed.doc");
// Execute the request
request->Execute();
// Get the response object
BFSecureResponse * response = request->GetSecureResponse();
// Check for success
if (response->GetBooleanResult(BFSecureOptions::WasProcessed)) {
// Print information about the document
FileFormats format = response->GetFileFormatResult(BFSecureOptions::SourceFormat);
std::wstring formatname;
BFSecureRequest::GetFileFormatName(format, formatname);
wcout << L"The file has a format of " << formatname << endl;
// Print results of scrubbing Comments and Tracked Changes
if (response->GetScrubResult(BFSecureOptions::Comments) == ScrubOption_Reaction_DoesNotExist) {
wcout << L"The document does not contain Comments" << endl;
} else if (response->GetScrubResult(BFSecureOptions::Comments) == ScrubOption_Reaction_Scrubbed) {
wcout << L"Comments were removed from the document" << endl;
}
if (response->GetScrubResult(BFSecureOptions::TrackedChanges) == ScrubOption_Reaction_DoesNotExist) {
wcout << L"The document does not contain Tracked Changes" << endl;
} else if (response->GetScrubResult(BFSecureOptions::TrackedChanges) == ScrubOption_Reaction_Scrubbed) {
wcout << L"Tracked Changes were removed from the document" << endl;
}
} else {
// Processing failed
wcout << L"Document processing failed" << endl;
}
BFSecureRequest::Shutdown();
} catch (BFTransformException & ex) {
wcout << ex.wwhat() << endl;
wcout << ex.wextended() << endl;
BFTransformException * cause = ex.getCause();
while (cause != NULL) {
wcout << cause->wwhat() << endl;
wcout << cause->wextended() << endl;
cause = cause->getCause();
}
}
return 0;
}
using System;
using System.Collections.Generic;
using System.Text;
using System.IO;
using CleanContent;
namespace Main
{
class Scrub
{
static void Main(string[] args)
{
// Initialize API
SecureHelper.Startup(true);
// Create a request
SecureRequest request = new SecureRequest();
// Set the default scrubbing behavior to NONE
request.SetOption(SecureOptions.DefaultScrubBehavior, ScrubOption.Action.NONE);
// Set Comments and Tracked Changes to be scrubbed
request.SetOption(SecureOptions.Comments, ScrubOption.Action.SCRUB);
request.SetOption(SecureOptions.TrackedChanges, ScrubOption.Action.SCRUB);
// Set the document to be analyzed
request.SetOption(SecureOptions.SourceDocument, new FileInfo("c:/temp/test.doc"));
// Set the scrubbed document
request.SetOption(SecureOptions.ScrubbedDocument, new FileInfo("c:/temp/test.scrubbed.doc"));
try
{
// Execute the request
request.Execute();
// Get the response object
SecureResponse response = request.GetResponse();
// Check for success
if (response.GetResult(SecureOptions.WasProcessed))
{
// Print information about the document
Console.WriteLine("The file has a format of " + response.GetResult(SecureOptions.SourceFormat).Name);
// Print results of scrubbing Comments and Tracked Changes
if (response.GetResult(SecureOptions.Comments) == ScrubOption.Reaction.DOESNOTEXIST) {
Console.WriteLine("The document did not contain Comments");
} else if (response.GetResult(SecureOptions.Comments) == ScrubOption.Reaction.SCRUBBED) {
Console.WriteLine("Comment were removed from the document");
}
if (response.GetResult(SecureOptions.TrackedChanges) == ScrubOption.Reaction.DOESNOTEXIST) {
Console.WriteLine("The document did not contain Tracked Changes");
} else if (response.GetResult(SecureOptions.TrackedChanges) == ScrubOption.Reaction.SCRUBBED) {
Console.WriteLine("Tracked Changes were removed from the document");
}
}
else
{
// Processing failed
Console.WriteLine("Document processing failed");
}
// Close the response
response.Close();
}
catch (TransformException e)
{
// An exception occured
Console.WriteLine("Document caused an exception");
Console.WriteLine(e.ToString());
}
// Close the request
request.Close();
// Uninitialize API
SecureHelper.Shutdown();
}
}
}
Hyperlink testing using regular expressions
The behavior of the SensitiveHyperlinks target may be modified by using a regular expression to extend the definition of "sensitive". The following sample code shows the extended API calls necessary to identify or scrub hyperlinks based on regular expression matching. Regular expression testing is in addition to the standard test for sensitivity.
request.setOption(SecureOptions.SensitiveHyperlinks,ScrubOption.Action.SCRUB);
String[] regexs = new String[] {".*yahoo.*",".*msn.*"};
request.setOption(SecureOptions.SensitiveHyperlinksRegex,regexs);
request.execute();
request->SetOption(BFSecureOptions::SensitiveHyperlinks,ScrubOption_Action_Scrub);
std::wstring regexs[2] = {L".*yahoo.*",L".*msn.*"};
request->SetOption(BFSecureOptions::SensitiveHyperlinksRegex,regexs,2);
request->Execute();
request.SetOption(SecureOptions.SensitiveHyperlinks,ScrubOption.Action.SCRUB);
string[] regexs = new string[] {".*yahoo.*",".*msn.*"};
request.SetOption(SecureOptions.SensitiveHyperlinksRegex,regexs);
request.Execute();
Modification of properties
As a special extension to scrubbing, Clean Content can also add, modify and remove document properties from Microsoft Office documents. The following code sample shows how to replace the Author property (or add one if no Author property exists), replace the Company property (only if a Company property already exists), remove the Title property and add a new custom property called State.
import net.bitform.api.secure.SecureRequest;
import net.bitform.api.secure.SecureOptions;
import net.bitform.api.secure.SecureResponse;
import net.bitform.api.options.ScrubOption;
import java.io.File;
import java.io.IOException;
public class Properties {
public static void main(String[] args) {
// Create a request
SecureRequest request = new SecureRequest();
// Set the default scrubbing behavior to NONE
request.setOption(SecureOptions.DefaultScrubBehavior, ScrubOption.Action.NONE);
// Default is to leave all properties alone
request.setOption(SecureOptions.Properties.defaultAction, SecureOptions.Properties.Action.None);
// Add or replace Author with "Larry"
request.setOption(SecureOptions.Properties.Author.action, SecureOptions.Properties.Action.AddOrReplace);
request.setOption(SecureOptions.Properties.Author.newValue, "Larry");
// Replace Company, if it already exists in the document, with "Oracle"
request.setOption(SecureOptions.Properties.Company.action, SecureOptions.Properties.Action.Replace);
request.setOption(SecureOptions.Properties.Company.newValue, "Oracle");
// Remove the Title property
request.setOption(SecureOptions.Properties.Title.action, SecureOptions.Properties.Action.Scrub);
// Create a new custom property and add it to the document
SecureOptions.Properties.StringProperty stateprop = SecureOptions.Properties.newStringProperty("State","The state in which the document was created");
request.setOption(stateprop.action, SecureOptions.Properties.Action.AddOrReplace);
request.setOption(stateprop.newValue, "California");
// Set the document modify
request.setOption(SecureOptions.SourceDocument, new File("c:/temp/test.doc"));
// Set the modified document
request.setOption(SecureOptions.ScrubbedDocument, new File("c:/temp/test.properties.doc"));
try {
// Execute the request
request.execute();
// Get the response object
SecureResponse response = request.getResponse();
// Check for success
if (response.getResult(SecureOptions.WasProcessed)) {
// Print information about the document
System.out.println("The file has a format of " + response.getResult(SecureOptions.SourceFormat).getName());
} else {
// Processing failed
System.out.println("Document processing failed");
}
} catch (IOException e) {
// An exception occured
System.out.println("Document caused an exception");
e.printStackTrace();
}
}
}
#include <iostream>
#include <tchar.h>
#include <malloc.h>
using namespace std;
#include "secureapi.h"
#ifdef BFWIN
#include <windows.h>
#endif
int main(int argc, _TCHAR* argv[])
{
try {
// Initialize the Clean Content API
BFSecureRequest::Startup(BFSTARTUPFEATURE_DEBUG);
// Create a request
BFSecureRequest * request = new BFSecureRequest();
// Set the default scrubbing behavior to NONE
request->SetOption(BFSecureOptions::DefaultScrubBehavior,ScrubOption_Action_None);
// Default is to leave all properties alone
request->SetOption(SecureOptions_Properties_DefaultAction_action,SecureOptions_Properties_Action_None);
// Add or replace Author with "Larry"
request->SetOption(SecureOptions_Properties_Author_action,SecureOptions_Properties_Action_AddOrReplace);
request->SetOption(SecureOptions_Properties_Author_newValue,L"Larry");
// Replace Company, if it already exists in the document, with "Oracle"
request->SetOption(SecureOptions_Properties_Company_action,SecureOptions_Properties_Action_Replace);
request->SetOption(SecureOptions_Properties_Company_newValue,L"Oracle");
// Remove the Title property
request->SetOption(SecureOptions_Properties_Title_action,SecureOptions_Properties_Action_Scrub);
// Create a new custom property and add it to the document
SecureOptions_StringProperty stateprop;
BFNewStringProperty(L"State",L"The state in which the document was created",&stateprop,NULL);
request->SetOption(stateprop.action,SecureOptions_Properties_Action_AddOrReplace);
request->SetOption(stateprop.newValue,L"California");
// Set the document to be scrubbed
request->SetOption(BFSecureOptions::SourceDocument, L"c:/temp/test.doc");
// Set the scrubbed document
request->SetOption(BFSecureOptions::ScrubbedDocument, L"c:/temp/test.properties.doc");
// Execute the request
request->Execute();
// Get the response object
BFSecureResponse * response = request->GetSecureResponse();
// Check for success
if (response->GetBooleanResult(BFSecureOptions::WasProcessed)) {
// Print information about the document
FileFormats format = response->GetFileFormatResult(BFSecureOptions::SourceFormat);
std::wstring formatname;
BFSecureRequest::GetFileFormatName(format, formatname);
wcout << L"The file has a format of " << formatname << endl;
} else {
// Processing failed
wcout << L"Document processing failed" << endl;
}
BFSecureRequest::Shutdown();
} catch (BFTransformException & ex) {
wcout << ex.wwhat() << endl;
wcout << ex.wextended() << endl;
BFTransformException * cause = ex.getCause();
while (cause != NULL) {
wcout << cause->wwhat() << endl;
wcout << cause->wextended() << endl;
cause = cause->getCause();
}
}
return 0;
}
using System;
using System.Collections.Generic;
using System.Text;
using System.IO;
using CleanContent;
namespace Main
{
class Properties
{
static void Main(string[] args)
{
// Initialize API
SecureHelper.Startup(true);
// Create a request
SecureRequest request = new SecureRequest();
// Set the default scrubbing behavior to NONE
request.SetOption(SecureOptions.DefaultScrubBehavior, ScrubOption.Action.NONE);
// Default is to leave all properties alone
request.SetOption(SecureOptions.Properties.defaultAction, SecureOptions.Properties.Action.None);
// Add or replace Author with "Larry"
request.SetOption(SecureOptions.Properties.Author.action, SecureOptions.Properties.Action.AddOrReplace);
request.SetOption(SecureOptions.Properties.Author.newValue, "Larry");
// Replace Company, if it already exists in the document, with "Oracle"
request.SetOption(SecureOptions.Properties.Company.action, SecureOptions.Properties.Action.Replace);
request.SetOption(SecureOptions.Properties.Company.newValue, "Oracle");
// Remove the Title property
request.SetOption(SecureOptions.Properties.Title.action, SecureOptions.Properties.Action.Scrub);
// Create a new custom property and add it to the document
SecureOptions.Properties.StringProperty stateprop = SecureOptions.Properties.newStringProperty("State", "The state in which the document was created");
request.SetOption(stateprop.action, SecureOptions.Properties.Action.AddOrReplace);
request.SetOption(stateprop.newValue, "California");
// Set the document modify
request.SetOption(SecureOptions.SourceDocument, new FileInfo("c:/temp/test.doc"));
// Set the modified document
request.SetOption(SecureOptions.ScrubbedDocument, new FileInfo("c:/temp/test.properties.doc"));
try
{
// Execute the request
request.Execute();
// Get the response object
SecureResponse response = request.GetResponse();
// Check for success
if (response.GetResult(SecureOptions.WasProcessed))
{
// Print information about the document
Console.WriteLine("The file has a format of " + response.GetResult(SecureOptions.SourceFormat).Name);
}
else
{
// Processing failed
Console.WriteLine("Document processing failed");
}
// Close the response
response.Close();
}
catch (TransformException e)
{
// An exception occured
Console.WriteLine("Document caused an exception");
Console.WriteLine(e.ToString());
}
// Close the request
request.Close();
// Uninitialize API
SecureHelper.Shutdown();
}
}
}
Modification of Microsoft Word Fields
As a special extension to scrubbing, Clean Content can also modify and remove Fields in Microsoft Word documents. The following sample code shows the extended API calls necessary to scrub all Fields from a Microsoft Word document except for Date Fields, in addition all Author fields will be scrubbed and have their contents replaced by the string "Larry".
import net.bitform.api.secure.SecureRequest;
import net.bitform.api.secure.SecureOptions;
import net.bitform.api.secure.SecureResponse;
import net.bitform.api.options.ScrubOption;
import java.io.File;
import java.io.IOException;
public class Fields {
public static void main(String[] args) {
// Create a request
SecureRequest request = new SecureRequest();
// Set the default scrubbing behavior to NONE
request.setOption(SecureOptions.DefaultScrubBehavior, ScrubOption.Action.NONE);
// Default is to scrub all fields
request.setOption(SecureOptions.Fields.defaultAction, SecureOptions.Fields.Action.Scrub);
// Don't scrub Date fields
request.setOption(SecureOptions.Fields.Date.action, SecureOptions.Fields.Action.None);
// Scrub the Author field and replace the text with "Larry"
request.setOption(SecureOptions.Fields.Author.action, SecureOptions.Fields.Action.ScrubAndReplace);
request.setOption(SecureOptions.Fields.Author.newValue, "Larry");
// Set the document modify
request.setOption(SecureOptions.SourceDocument, new File("c:/temp/test.doc"));
// Set the modified document
request.setOption(SecureOptions.ScrubbedDocument, new File("c:/temp/test.fields.doc"));
try {
// Execute the request
request.execute();
// Get the response object
SecureResponse response = request.getResponse();
// Check for success
if (response.getResult(SecureOptions.WasProcessed)) {
// Print information about the document
System.out.println("The file has a format of " + response.getResult(SecureOptions.SourceFormat).getName());
} else {
// Processing failed
System.out.println("Document processing failed");
}
} catch (IOException e) {
// An exception occured
System.out.println("Document caused an exception");
e.printStackTrace();
}
}
}
#include <iostream>
#include <tchar.h>
#include <malloc.h>
using namespace std;
#include "secureapi.h"
#ifdef BFWIN
#include <windows.h>
#endif
int main(int argc, _TCHAR* argv[])
{
try {
// Initialize the Clean Content API
BFSecureRequest::Startup(BFSTARTUPFEATURE_DEBUG);
// Create a request
BFSecureRequest * request = new BFSecureRequest();
// Set the default scrubbing behavior to NONE
request->SetOption(BFSecureOptions::DefaultScrubBehavior,ScrubOption_Action_None);
// Default is to scrub all fields
request->SetOption(SecureOptions_Fields_DefaultAction_action,SecureOptions_Fields_Action_Scrub);
// Don't scrub Date fields
request->SetOption(SecureOptions_Fields_Date_action,SecureOptions_Fields_Action_None);
// Scrub the Author field and replace the text with "Larry"
request->SetOption(SecureOptions_Fields_Author_action,SecureOptions_Fields_Action_ScrubAndReplace);
request->SetOption(SecureOptions_Fields_Author_newValue,L"Larry");
// Set the document to be scrubbed
request->SetOption(BFSecureOptions::SourceDocument, L"c:/temp/test.doc");
// Set the scrubbed document
request->SetOption(BFSecureOptions::ScrubbedDocument, L"c:/temp/test.fields.doc");
// Execute the request
request->Execute();
// Get the response object
BFSecureResponse * response = request->GetSecureResponse();
// Check for success
if (response->GetBooleanResult(BFSecureOptions::WasProcessed)) {
// Print information about the document
FileFormats format = response->GetFileFormatResult(BFSecureOptions::SourceFormat);
std::wstring formatname;
BFSecureRequest::GetFileFormatName(format, formatname);
wcout << L"The file has a format of " << formatname << endl;
} else {
// Processing failed
wcout << L"Document processing failed" << endl;
}
BFSecureRequest::Shutdown();
} catch (BFTransformException & ex) {
wcout << ex.wwhat() << endl;
wcout << ex.wextended() << endl;
BFTransformException * cause = ex.getCause();
while (cause != NULL) {
wcout << cause->wwhat() << endl;
wcout << cause->wextended() << endl;
cause = cause->getCause();
}
}
return 0;
}
using System;
using System.Collections.Generic;
using System.Text;
using System.IO;
using CleanContent;
namespace Main
{
class Fields
{
static void Main(string[] args)
{
// Initialize API
SecureHelper.Startup(true);
// Create a request
SecureRequest request = new SecureRequest();
// Set the default scrubbing behavior to NONE
request.SetOption(SecureOptions.DefaultScrubBehavior, ScrubOption.Action.NONE);
// Default is to scrub all fields
request.SetOption(SecureOptions.Fields.defaultAction, SecureOptions.Fields.Action.Scrub);
// Don't scrub Date fields
request.SetOption(SecureOptions.Fields.Date.action, SecureOptions.Fields.Action.None);
// Scrub the Author field and replace the text with "Larry"
request.SetOption(SecureOptions.Fields.Author.action, SecureOptions.Fields.Action.ScrubAndReplace);
request.SetOption(SecureOptions.Fields.Author.newValue, "Larry");
// Set the document modify
request.SetOption(SecureOptions.SourceDocument, new FileInfo("c:/temp/test.doc"));
// Set the modified document
request.SetOption(SecureOptions.ScrubbedDocument, new FileInfo("c:/temp/test.fields.doc"));
try
{
// Execute the request
request.Execute();
// Get the response object
SecureResponse response = request.GetResponse();
// Check for success
if (response.GetResult(SecureOptions.WasProcessed))
{
// Print information about the document
Console.WriteLine("The file has a format of " + response.GetResult(SecureOptions.SourceFormat).Name);
}
else
{
// Processing failed
Console.WriteLine("Document processing failed");
}
// Close the response
response.Close();
}
catch (TransformException e)
{
// An exception occured
Console.WriteLine("Document caused an exception");
Console.WriteLine(e.ToString());
}
// Close the request
request.Close();
// Uninitialize API
SecureHelper.Shutdown();
}
}
}
Header/Footer removal and modification using regular expressions
As a special extension to scrubbing, Clean Content can also conditionally remove, remove just text or replace text in headers and footers using the HeadersFootersSearch, HeadersFootersBehavior and HeadersFootersReplace options. These options are only valid when the HeadersFooters scrub target is set to Scrub. If these options are empty, all headers and footers are scrubbed completely.
The code shows setting the HeadersFooters options in such a way that any header or footer containing the text "abc" will be left alone; any header or footer containing the text "123" will be scrubbed for text but other items like fields, images, page number, etc. will be left alone; any header or footer containing the text "Joe" will be left alone except "Joe" will be replaced by "Jim"; and all other headers and footers will be scrubbed completely.
import net.bitform.api.options.EnumOptionValue;
import net.bitform.api.options.ScrubOption;
import net.bitform.api.secure.SecureOptions;
import net.bitform.api.secure.SecureRequest;
import net.bitform.api.secure.SecureResponse;
import java.io.File;
import java.io.IOException;
public class Headers {
public static void main(String[] args) {
// Create a request
SecureRequest request = new SecureRequest();
// Set the default scrubbing behavior to NONE
request.setOption(SecureOptions.DefaultScrubBehavior, ScrubOption.Action.NONE);
// Scrub headers and footers
request.setOption(SecureOptions.HeadersFooters, ScrubOption.Action.SCRUB);
// List of regular expressions to match in headers and footers
String[] search = new String[]{
".*abc.*",
".*123.*",
"(.*)Joe(.*)"
};
// List of behaviors to take on a match condition
EnumOptionValue[] behavior = new EnumOptionValue[]{
SecureOptions.HeadersFootersBehaviorOption.Leave,
SecureOptions.HeadersFootersBehaviorOption.ScrubText,
SecureOptions.HeadersFootersBehaviorOption.Replace
};
// List of replacement text items
String[] replace = new String[]{
null,
null,
"$1Jim$2"
};
// Set the lists
request.setOption(SecureOptions.HeadersFootersSearch, search);
request.setOption(SecureOptions.HeadersFootersBehavior, behavior);
request.setOption(SecureOptions.HeadersFootersReplace, replace);
// Set the document modify
request.setOption(SecureOptions.SourceDocument, new File("c:/temp/test.doc"));
// Set the modified document
request.setOption(SecureOptions.ScrubbedDocument, new File("c:/temp/test.headers.doc"));
try {
// Execute the request
request.execute();
// Get the response object
SecureResponse response = request.getResponse();
// Check for success
if (response.getResult(SecureOptions.WasProcessed)) {
// Print information about the document
System.out.println("The file has a format of " + response.getResult(SecureOptions.SourceFormat).getName());
} else {
// Processing failed
System.out.println("Document processing failed");
}
} catch (IOException e) {
// An exception occured
System.out.println("Document caused an exception");
e.printStackTrace();
}
}
}
#include <iostream>
#include <tchar.h>
#include <malloc.h>
using namespace std;
#include "secureapi.h"
#ifdef BFWIN
#include <windows.h>
#endif
int main(int argc, _TCHAR* argv[])
{
try {
// Initialize the Clean Content API
BFSecureRequest::Startup(BFSTARTUPFEATURE_DEBUG);
// Create a request
BFSecureRequest * request = new BFSecureRequest();
// Set the default scrubbing behavior to NONE
request->SetOption(BFSecureOptions::DefaultScrubBehavior,ScrubOption_Action_None);
// Scrub headers and footers
request->SetOption(BFSecureOptions::HeadersFooters,ScrubOption_Action_Scrub);
// Set search terms
std::wstring search[] = {
L".*abc.*",
L".*123.*",
L"(.*)Joe(.*)"
};
request->SetOption(BFSecureOptions::HeadersFootersSearch, search, 3);
// Set behaviors
int behavior[] = {
SecureOptions_HeadersFootersBehavior_Leave,
SecureOptions_HeadersFootersBehavior_ScrubText,
SecureOptions_HeadersFootersBehavior_Replace
};
request->SetOption(BFSecureOptions::HeadersFootersBehavior, behavior, 3);
// Set replacement text
std::wstring replace[] = {
L"",
L"",
L"$1Jim$2"
};
request->SetOption(BFSecureOptions::HeadersFootersReplace, replace, 3);
// Set the document to be scrubbed
request->SetOption(BFSecureOptions::SourceDocument, L"c:/temp/test.doc");
// Set the scrubbed document
request->SetOption(BFSecureOptions::ScrubbedDocument, L"c:/temp/test.headers.doc");
// Execute the request
request->Execute();
// Get the response object
BFSecureResponse * response = request->GetSecureResponse();
// Check for success
if (response->GetBooleanResult(BFSecureOptions::WasProcessed)) {
// Print information about the document
FileFormats format = response->GetFileFormatResult(BFSecureOptions::SourceFormat);
std::wstring formatname;
BFSecureRequest::GetFileFormatName(format, formatname);
wcout << L"The file has a format of " << formatname << endl;
} else {
// Processing failed
wcout << L"Document processing failed" << endl;
}
BFSecureRequest::Shutdown();
} catch (BFTransformException & ex) {
wcout << ex.wwhat() << endl;
wcout << ex.wextended() << endl;
BFTransformException * cause = ex.getCause();
while (cause != NULL) {
wcout << cause->wwhat() << endl;
wcout << cause->wextended() << endl;
cause = cause->getCause();
}
}
return 0;
}
using System;
using System.Collections.Generic;
using System.Text;
using System.IO;
using CleanContent;
namespace Main
{
class Headers
{
static void Main(string[] args)
{
// Initialize API
SecureHelper.Startup(true);
// Create a request
SecureRequest request = new SecureRequest();
// Set the default scrubbing behavior to NONE
request.SetOption(SecureOptions.DefaultScrubBehavior, ScrubOption.Action.NONE);
// Scrub headers and footers
request.SetOption(SecureOptions.HeadersFooters, ScrubOption.Action.SCRUB);
// List of regular expressions to match in headers and footers
string[] search = new string[]{
".*abc.*",
".*123.*",
"(.*)Joe(.*)"
};
// List of behaviors to take on a match condition
int[] behavior = new int[]{
SecureOptions.HeadersFootersBehaviorOption.Leave,
SecureOptions.HeadersFootersBehaviorOption.ScrubText,
SecureOptions.HeadersFootersBehaviorOption.Replace
};
// List of replacement text items
string[] replace = new string[]{
null,
null,
"$1Jim$2"
};
// Set the lists
request.SetOption(SecureOptions.HeadersFootersSearch, search);
request.SetOption(SecureOptions.HeadersFootersBehavior, behavior);
request.SetOption(SecureOptions.HeadersFootersReplace, replace);
// Set the document modify
request.SetOption(SecureOptions.SourceDocument, new FileInfo("c:/temp/test.doc"));
// Set the modified document
request.SetOption(SecureOptions.ScrubbedDocument, new FileInfo("c:/temp/test.headers.doc"));
try
{
// Execute the request
request.Execute();
// Get the response object
SecureResponse response = request.GetResponse();
// Check for success
if (response.GetResult(SecureOptions.WasProcessed))
{
// Print information about the document
Console.WriteLine("The file has a format of " + response.GetResult(SecureOptions.SourceFormat).Name);
}
else
{
// Processing failed
Console.WriteLine("Document processing failed");
}
// Close the response
response.Close();
}
catch (TransformException e)
{
// An exception occured
Console.WriteLine("Document caused an exception");
Console.WriteLine(e.ToString());
}
// Close the request
request.Close();
// Uninitialize API
SecureHelper.Shutdown();
}
}
}
Extraction
In addition to analysis and scrubbing, Clean Content can extract the text, property and structural information from documents. The OutputType option tells the API if and how this data should be delivered. Possible values for this option include:
NoOutput
Disables text extraction (this is the default)
ToText
Outputs just the text to a simple text file. The ResultDocument option defines where the text will be written. The ToTextEncoding option controls the encoding of the text. If ToTextEncoding is set to UTF16, the text output is in Unicode UTF-16, the byte order is the platform's native order, the line separator is the platform's native line separator and the first character is always the Unicode Byte Order Mark (BOM). If ToTextEncoding is set to UTF8, the text output is in Unicode UTF-8 and the line separator is the platform's native line separator.
ToXML
Output complete text, property and structure information to an XML file. The ResultDocument option defines where the XML will be written. In addition, the TransformResult (a boolean) and ResultTransform (a document) options allow an XSLT process to be applied to the XML before it reaches the ResultDocument.
ToHandler
Output complete text, property and structure information to a developer provided element handler (much like a SAX content handler). The ElementHandler option defines where the data will be written to. This is by far the fastest way to receive the extracted data.
Schema
In the ToXML and ToHandler cases the data will conform to the XML Schema http://www.bitform.net/xml/schema/elements.xsd. This schema is available in the in the docs directory of this SDK.
Sample code - XML output
This code shows extraction to an XML file by setting OutputType to ToXML
import net.bitform.api.secure.SecureRequest;
import net.bitform.api.secure.SecureOptions;
import net.bitform.api.secure.SecureResponse;
import net.bitform.api.options.ScrubOption;
import net.bitform.api.options.EnumOptionValue;
import java.io.File;
import java.io.IOException;
public class ToXml {
public static void main(String[] args) {
// Create a request
SecureRequest request = new SecureRequest();
// Don't scrub
request.setOption(SecureOptions.JustAnalyze, true);
// Set the document to extract data from
request.setOption(SecureOptions.SourceDocument, new File("c:/temp/test.doc"));
// Setup for XML output
request.setOption(SecureOptions.OutputType,SecureOptions.OutputTypeOption.ToXML);
// Set the XML output document
request.setOption(SecureOptions.ResultDocument, new File("c:/temp/test.doc.xml"));
try {
// Execute the request
request.execute();
// Get the response object
SecureResponse response = request.getResponse();
// Check for success
if (response.getResult(SecureOptions.WasProcessed)) {
// Print information about the document
System.out.println("The file has a format of " + response.getResult(SecureOptions.SourceFormat).getName());
} else {
// Processing failed
System.out.println("Document processing failed");
}
} catch (IOException e) {
// An exception occured
System.out.println("Document caused an exception");
e.printStackTrace();
}
}
}
#include <iostream>
#include <tchar.h>
#include <malloc.h>
using namespace std;
#include "secureapi.h"
#ifdef BFWIN
#include <windows.h>
#endif
int main(int argc, _TCHAR* argv[])
{
try {
// Initialize the Clean Content API
BFSecureRequest::Startup(BFSTARTUPFEATURE_DEBUG);
// Create a request
BFSecureRequest * request = new BFSecureRequest();
// Don't scrub
request->SetOption(BFSecureOptions::JustAnalyze,TRUE);
// Set the document to extract data from
request->SetOption(BFSecureOptions::SourceDocument, L"c:/temp/test.doc");
// Setup for XML output
request->SetOption(BFSecureOptions::OutputType,SecureOptions_OutputType_ToXML);
// Set the XML output document
request->SetOption(BFSecureOptions::ResultDocument,L"c:/temp/test.doc.xml");
// Execute the request
request->Execute();
// Get the response object
BFSecureResponse * response = request->GetSecureResponse();
// Check for success
if (response->GetBooleanResult(BFSecureOptions::WasProcessed)) {
// Print information about the document
FileFormats format = response->GetFileFormatResult(BFSecureOptions::SourceFormat);
std::wstring formatname;
BFSecureRequest::GetFileFormatName(format, formatname);
wcout << L"The file has a format of " << formatname << endl;
} else {
// Processing failed
wcout << L"Document processing failed" << endl;
}
BFSecureRequest::Shutdown();
} catch (BFTransformException & ex) {
wcout << ex.wwhat() << endl;
wcout << ex.wextended() << endl;
BFTransformException * cause = ex.getCause();
while (cause != NULL) {
wcout << cause->wwhat() << endl;
wcout << cause->wextended() << endl;
cause = cause->getCause();
}
}
return 0;
}
using System;
using System.Collections.Generic;
using System.Text;
using System.IO;
using CleanContent;
namespace Main
{
class ToXml
{
static void Main(string[] args)
{
// Initialize API
SecureHelper.Startup(true);
// Create a request
SecureRequest request = new SecureRequest();
// Don't scrub
request.SetOption(SecureOptions.JustAnalyze, true);
// Set the document to extract data from
request.SetOption(SecureOptions.SourceDocument, new FileInfo("c:/temp/test.doc"));
// Setup for XML output
request.SetOption(SecureOptions.OutputType, SecureOptions.OutputTypeOption.ToXML);
// Set the XML output document
request.SetOption(SecureOptions.ResultDocument, new FileInfo("c:/temp/test.doc.xml"));
try
{
// Execute the request
request.Execute();
// Get the response object
SecureResponse response = request.GetResponse();
// Check for success
if (response.GetResult(SecureOptions.WasProcessed))
{
// Print information about the document
Console.WriteLine("The file has a format of " + response.GetResult(SecureOptions.SourceFormat).Name);
}
else
{
// Processing failed
Console.WriteLine("Document processing failed");
}
// Close the response
response.Close();
}
catch (TransformException e)
{
// An exception occured
Console.WriteLine("Document caused an exception");
Console.WriteLine(e.ToString());
}
// Close the request
request.Close();
// Uninitialize API
SecureHelper.Shutdown();
}
}
}
Sample code - Element handler
This code shows extraction to an developer provided element handler by setting OutputType to ToHandler
import net.bitform.api.elements.*;
import net.bitform.api.secure.SecureOptions;
import net.bitform.api.secure.SecureRequest;
import net.bitform.api.secure.SecureResponse;
import java.io.File;
import java.io.IOException;
import java.nio.CharBuffer;
public class ToHandler {
public static void main(String[] args) {
// Create a request
SecureRequest request = new SecureRequest();
// Don't scrub
request.setOption(SecureOptions.JustAnalyze, true);
// Set the document to extract data from
request.setOption(SecureOptions.SourceDocument, new File("c:/temp/test.doc"));
// Setup for XML output
request.setOption(SecureOptions.OutputType, SecureOptions.OutputTypeOption.ToHandler);
// Simple element handler class
class MyHandler extends BaseElementHandler {
/* Override just a few elements */
public void startContent(ContentElement element) throws IOException {
System.out.println("Format of content is " + element.format.getName());
}
public void endContent(Element element) throws IOException {
System.out.println("Content ends");
}
public void startStringProperty(StringPropertyElement element) throws IOException {
System.out.println("String property " + element.name + " has a value of " + element.value);
}
public void text(CharBuffer buffer) throws IOException {
System.out.println(buffer.toString());
}
public void startDateProperty(DatePropertyElement element) throws IOException {
System.out.println(element.value);
}
}
// Set the handler
request.setOption(SecureOptions.ElementHandler, new MyHandler());
try {
// Execute the request
request.execute();
// Get the response object
SecureResponse response = request.getResponse();
// Check for success
if (response.getResult(SecureOptions.WasProcessed)) {
// Print information about the document
System.out.println("The file has a format of " + response.getResult(SecureOptions.SourceFormat).getName());
} else {
// Processing failed
System.out.println("Document processing failed");
}
} catch (IOException e) {
// An exception occured
System.out.println("Document caused an exception");
e.printStackTrace();
}
}
}
#include <iostream>
#include <tchar.h>
#include <malloc.h>
using namespace std;
#include "secureapi.h"
#ifdef BFWIN
#include <windows.h>
#endif
int main(int argc, _TCHAR* argv[])
{
try {
// Initialize the Clean Content API
BFSecureRequest::Startup(BFSTARTUPFEATURE_DEBUG);
// Create a request
BFSecureRequest * request = new BFSecureRequest();
// Don't scrub
request->SetOption(BFSecureOptions::JustAnalyze,TRUE);
// Set the document to extract data from
request->SetOption(BFSecureOptions::SourceDocument, L"c:/temp/test.doc");
// Simple element handler class
class MyHandler : public BFBaseElementHandler {
/* Override just a few elements */
void StartContent(BFContentElement * element) {
std::wstring formatName;
BFSecureRequest::GetFileFormatName((FileFormats)element->format,formatName);
wcout << L"Format of content is " << formatName << endl;
}
void EndContent(BFElement * element) {
wcout << L"Content ends" << endl;
}
void StartStringProperty(BFStringPropertyElement * element) {
wcout << L"String property " << element->name << L" has value " << element->value << endl;
}
void Text(void * buffer, BFINT32 count) {
wchar_t * chars = (wchar_t * )buffer;
chars[count] = 0x00;
#ifdef BFWIN
// The following code gets around a problem with Windows console
// output of Unicode characters over 255.
// In the real world you (the developer) would be doing something
// more interesting with the Unicode text.
for (int i = 0; i < count; i++) if (chars[i] > 255) chars[i] = '.';
// End Windows fix
#endif
wcout << chars << endl;
}
};
MyHandler myElementHandler = MyHandler();
// Setup for element handler output
request->SetOption(BFSecureOptions::OutputType,SecureOptions_OutputType_ToHandler);
// Set the element handler
request->SetOption(BFSecureOptions::ElementHandler,&myElementHandler);
// Execute the request
request->Execute();
// Get the response object
BFSecureResponse * response = request->GetSecureResponse();
// Check for success
if (response->GetBooleanResult(BFSecureOptions::WasProcessed)) {
// Print information about the document
FileFormats format = response->GetFileFormatResult(BFSecureOptions::SourceFormat);
std::wstring formatname;
BFSecureRequest::GetFileFormatName(format, formatname);
wcout << L"The file has a format of " << formatname << endl;
} else {
// Processing failed
wcout << L"Document processing failed" << endl;
}
BFSecureRequest::Shutdown();
} catch (BFTransformException & ex) {
wcout << ex.wwhat() << endl;
wcout << ex.wextended() << endl;
BFTransformException * cause = ex.getCause();
while (cause != NULL) {
wcout << cause->wwhat() << endl;
wcout << cause->wextended() << endl;
cause = cause->getCause();
}
}
return 0;
}
using System;
using System.Collections.Generic;
using System.Text;
using System.IO;
using System.Runtime.InteropServices;
using System.Diagnostics;
using CleanContent;
namespace Main
{
class ToHandler
{
// Simple element handler class
class MyHandler : BaseElementHandler
{
/* Override just a few elements */
public override void StartContent(IntPtr handler, ref ElementHandler.ContentElement element)
{
Console.WriteLine("Format of content is " + element.format.Description);
}
public override void EndContent(IntPtr handler, ref ElementHandler.Element element)
{
Console.WriteLine("Content ends");
}
public override void StartStringProperty(IntPtr handler, ref ElementHandler.StringPropertyElement element)
{
Console.WriteLine("String property " + element.name + " has a value of " + element.value);
}
public override void StartDateProperty(IntPtr handler, ref ElementHandler.DatePropertyElement element)
{
Console.WriteLine("Date property " + element.name + " has a value of " + element.value.ToLongDateString());
}
public override void Text(IntPtr handler, char[] text, int length)
{
Console.WriteLine(text, 0, length);
}
}
static void Main(string[] args)
{
// Initialize API
SecureHelper.Startup(true);
// Create a request
SecureRequest request = new SecureRequest();
// Don't scrub
request.SetOption(SecureOptions.JustAnalyze, true);
// Set the document to extract data from
request.SetOption(SecureOptions.SourceDocument, new FileInfo("c:/temp/test.doc"));
// Setup for XML output
request.SetOption(SecureOptions.OutputType, SecureOptions.OutputTypeOption.ToHandler);
// Set the handler
MyHandler mh = new MyHandler();
request.SetOption(SecureOptions.ElementHandler, mh);
try
{
// Execute the request
request.Execute();
// Get the response object
SecureResponse response = request.GetResponse();
// Check for success
if (response.GetResult(SecureOptions.WasProcessed))
{
// Print information about the document
Console.WriteLine("The file has a format of " + response.GetResult(SecureOptions.SourceFormat).Name);
}
else
{
// Processing failed
Console.WriteLine("Document processing failed");
}
// Close the response
response.Close();
}
catch (TransformException e)
{
// An exception occured
Console.WriteLine("Document caused an exception");
Console.WriteLine(e.ToString());
}
// Close the request
request.Close();
// Uninitialize API
SecureHelper.Shutdown();
}
}
}
PowerPoint Fingerprinting
When extracting data from PowerPoint documents the developer may also choose to receive a fingerprints (a MD5 hash of the relevant data) for the content and/or appearance of each slide by setting the GenerateSlideContentFingerprint and GenerateSlideAppearanceFingerprint options. Fingerprint values are received through the startFingerprint method of your ElementHandler or through the fingerprint element in the XML output. For more details see the technical note on PowerPoint fingerprinting.
Recursion into embeddings
During analysis, scrubbing and extraction Clean Content may encounter embedded objects. For example an Excel spreadsheet may be embedded in a Word document. Clean Content allows embedded objects of certain types to be recursively processed for analysis, scrubbing and extraction. For example, when scrubbing a Word document it is possible to set these options so that all embedded Word, Excel and PowerPoint documents are also scrubbed (not removed). The EmbeddingRecurseList option provides a list of file formats that should be recurred into and the EmbeddingRecurseDepth option defines the maximum depth of the recursion.
There are two important things to note about recursion. First is that recursion into a particular embedded object overrides the EmbeddedObjects scrub target. That is even if the EmbeddedObjects target is set to SCRUB, embedded objects that are recurred into are not totally removed (the behavior of the EmbeddedObjects target) but scrubbed with the same options as the main document. Second is that all options that hold for the main document hold for embedded objects that are recurred into including extraction. This allows text, property and structure information to be extracted from embedded objects to any depth required.
Sample code
The following code shows how to recur into all first level Word, Excel and PowerPoint documents but not recur any deeper. All embedded objects that are not Word, Excel and PowerPoint or are below the first level will be completely removed leaving only their cached image. Word, Excel and PowerPoint embeddings at the first level (that is direct child embeddings of the source document ) will be scrubbed of Comments but otherwise left intact.
Note that if extraction were enabled (which it isn't in this sample code) the output would include text, structure and other data from first level Word, Excel and PowerPoint embeddings.
import net.bitform.api.secure.SecureRequest;
import net.bitform.api.secure.SecureOptions;
import net.bitform.api.secure.SecureResponse;
import net.bitform.api.options.ScrubOption;
import net.bitform.api.FileFormat;
import java.io.File;
import java.io.IOException;
public class Recur {
public static void main(String[] args) {
// Create a request
SecureRequest request = new SecureRequest();
// Set the default scrubbing behavior to NONE
request.setOption(SecureOptions.DefaultScrubBehavior, ScrubOption.Action.NONE);
// Set Embedded Objects and Comments to be scrubbed
request.setOption(SecureOptions.EmbeddedObjects,ScrubOption.Action.SCRUB);
request.setOption(SecureOptions.Comments,ScrubOption.Action.SCRUB);
// Recur into Word, Excel and PowerPoint embeddings,
// Embedded Objects and Comments in these embedding types will also be scrubbed
request.setOption(SecureOptions.EmbeddingRecurseList, new FileFormat[] {FileFormat.WORD8, FileFormat.EXCEL8, FileFormat.POWERPOINT8});
// Recur into only the first level of embeddings
request.setOption(SecureOptions.EmbeddingRecurseDepth, 1);
// Set the document to be scrubbed
request.setOption(SecureOptions.SourceDocument, new File("c:/temp/test.doc"));
// Set the scrubbed document
request.setOption(SecureOptions.ScrubbedDocument, new File("c:/temp/test.recur.doc"));
try {
// Execute the request
request.execute();
// Get the response object
SecureResponse response = request.getResponse();
// Check for success
if (response.getResult(SecureOptions.WasProcessed)) {
// Print information about the document
System.out.println("The file has a format of " + response.getResult(SecureOptions.SourceFormat).getName());
} else {
// Processing failed
System.out.println("Document processing failed");
}
} catch (IOException e) {
// An exception occured
System.out.println("Document caused an exception");
e.printStackTrace();
}
}
}
#include <iostream>
#include <tchar.h>
#include <malloc.h>
using namespace std;
#include "secureapi.h"
#ifdef BFWIN
#include <windows.h>
#endif
int main(int argc, _TCHAR* argv[])
{
try {
// Initialize the Clean Content API
BFSecureRequest::Startup(BFSTARTUPFEATURE_DEBUG);
// Create a request
BFSecureRequest * request = new BFSecureRequest();
// Set the default scrubbing behavior to NONE
request->SetOption(BFSecureOptions::DefaultScrubBehavior, ScrubOption_Action_None);
// Set Embedded Objects and Comments to be scrubbed
request->SetOption(BFSecureOptions::EmbeddedObjects, ScrubOption_Action_Scrub);
request->SetOption(BFSecureOptions::Comments ,ScrubOption_Action_Scrub);
// Recur into one level of Word, Excel and PowerPoint embeddings
// Embedded Objects and Comments in these embedding types will also be scrubbed
// All other embedding types will be removed completely
enum FileFormats formats[] = {BFFileFormat::WORD8, BFFileFormat::EXCEL8, BFFileFormat::POWERPOINT8};
request->SetOption(BFSecureOptions::EmbeddingRecurseList, formats, 3);
request->SetOption(BFSecureOptions::EmbeddingRecurseDepth, 1);
// Set the document to be scrubbed
request->SetOption(BFSecureOptions::SourceDocument, L"c:/temp/test.doc");
// Set the scrubbed document
request->SetOption(BFSecureOptions::ScrubbedDocument, L"c:/temp/test.recur.doc");
// Execute the request
request->Execute();
// Get the response object
BFSecureResponse * response = request->GetSecureResponse();
// Check for success
if (response->GetBooleanResult(BFSecureOptions::WasProcessed)) {
// Print information about the document
FileFormats format = response->GetFileFormatResult(BFSecureOptions::SourceFormat);
std::wstring formatname;
BFSecureRequest::GetFileFormatName(format, formatname);
wcout << L"The file has a format of " << formatname << endl;
} else {
// Processing failed
wcout << L"Document processing failed" << endl;
}
BFSecureRequest::Shutdown();
} catch (BFTransformException & ex) {
wcout << ex.wwhat() << endl;
wcout << ex.wextended() << endl;
BFTransformException * cause = ex.getCause();
while (cause != NULL) {
wcout << cause->wwhat() << endl;
wcout << cause->wextended() << endl;
cause = cause->getCause();
}
}
return 0;
}
using System;
using System.Collections.Generic;
using System.Text;
using System.IO;
using CleanContent;
namespace Main
{
class Recur
{
static void Main(string[] args)
{
// Initialize API
SecureHelper.Startup(true);
// Create a request
SecureRequest request = new SecureRequest();
// Set the default scrubbing behavior to NONE
request.SetOption(SecureOptions.DefaultScrubBehavior, ScrubOption.Action.NONE);
// Set Embedded Objects and Comments to be scrubbed
request.SetOption(SecureOptions.EmbeddedObjects, ScrubOption.Action.SCRUB);
request.SetOption(SecureOptions.Comments, ScrubOption.Action.SCRUB);
// Recur into Word, Excel and PowerPoint embeddings,
// Embedded Objects and Comments in these embedding types will also be scrubbed
request.SetOption(SecureOptions.EmbeddingRecurseList, new FileFormat[] { FileFormat.WORD8, FileFormat.EXCEL8, FileFormat.POWERPOINT8 });
// Recur into only the first level of embeddings
request.SetOption(SecureOptions.EmbeddingRecurseDepth, 1);
// Set the document to be analyzed
request.SetOption(SecureOptions.SourceDocument, new FileInfo("c:/temp/test.doc"));
// Set the scrubbed document
request.SetOption(SecureOptions.ScrubbedDocument, new FileInfo("c:/temp/test.recur.doc"));
try
{
// Execute the request
request.Execute();
// Get the response object
SecureResponse response = request.GetResponse();
// Check for success
if (response.GetResult(SecureOptions.WasProcessed))
{
// Print information about the document
Console.WriteLine("The file has a format of " + response.GetResult(SecureOptions.SourceFormat).Name);
}
else
{
// Processing failed
Console.WriteLine("Document processing failed");
}
// Close the response
response.Close();
}
catch (TransformException e)
{
// An exception occured
Console.WriteLine("Document caused an exception");
Console.WriteLine(e.ToString());
}
// Close the request
request.Close();
// Uninitialize API
SecureHelper.Shutdown();
}
}
}
Embedding Export
Clean Content allows embedded objects and images of certain types to be exported to stand alone files for further processing or display. The EmbeddingExportList option provides a list of file formats that should be exported, the EmbeddingExportDirectory option provides the default directory where exported embeddings and images should be placed and EmbeddingExportBaseFileName provides the default file name prefix to use for exported files. In addition, the developer may track or modify the locations of exported embedding and images using the ExportDocument option during the startEmbeddedContent method in an element handler.
Sample code
The following code shows how to export all Excel, Windows Metafile, Windows Enhanced Metafile, JPEG and PNG embeddings in a document. Files like test.doc.em1.xls, test.doc.em2.wmf, test.doc.em3.png, test.doc.em4.jpg will be placed in the c:\temp directory along with the XML extracted from the document. The XML will reference the exported image files.
import net.bitform.api.secure.SecureRequest;
import net.bitform.api.secure.SecureOptions;
import net.bitform.api.secure.SecureResponse;
import net.bitform.api.options.ScrubOption;
import net.bitform.api.FileFormat;
import java.io.File;
import java.io.IOException;
public class Export {
public static void main(String[] args) {
// Create a request
SecureRequest request = new SecureRequest();
// Don't scrub
request.setOption(SecureOptions.JustAnalyze,true);
// Export Excel, Windows Metafile, JPEG and PNG embeddings to c:\temp using names starting with 'test.doc.em'
request.setOption(SecureOptions.EmbeddingExportList, new FileFormat[] {FileFormat.EXCEL8, FileFormat.WMF, FileFormat.EMF, FileFormat.JPEG,FileFormat.PNG});
request.setOption(SecureOptions.EmbeddingExportDirectory, new File("c:/temp"));
request.setOption(SecureOptions.EmbeddingExportBaseFileName, "test.doc.em");
// Set the source document
request.setOption(SecureOptions.SourceDocument, new File("c:/temp/test.doc"));
// Setup for XML output
request.setOption(SecureOptions.OutputType,SecureOptions.OutputTypeOption.ToXML);
// Set the XML output document
request.setOption(SecureOptions.ResultDocument, new File("c:/temp/test.doc.xml"));
try {
// Execute the request
request.execute();
// Get the response object
SecureResponse response = request.getResponse();
// Check for success
if (response.getResult(SecureOptions.WasProcessed)) {
// Print information about the document
System.out.println("The file has a format of " + response.getResult(SecureOptions.SourceFormat).getName());
} else {
// Processing failed
System.out.println("Document processing failed");
}
} catch (IOException e) {
// An exception occured
System.out.println("Document caused an exception");
e.printStackTrace();
}
}
}
#include <iostream>
#include <tchar.h>
#include <malloc.h>
using namespace std;
#include "secureapi.h"
#ifdef BFWIN
#include <windows.h>
#endif
int main(int argc, _TCHAR* argv[])
{
try {
// Initialize the Clean Content API
BFSecureRequest::Startup(BFSTARTUPFEATURE_DEBUG);
// Create a request
BFSecureRequest * request = new BFSecureRequest();
// Don't scrub
request->SetOption(BFSecureOptions::JustAnalyze, TRUE);
// Export Excel, Windows Metafile, JPEG and PNG embeddings to c:\temp
// using names starting with 'test.doc.embedding'
enum FileFormats formats[] = {BFFileFormat::EXCEL8, BFFileFormat::WMF, BFFileFormat::EMF, BFFileFormat::JPEG, BFFileFormat::PNG};
request->SetOption(BFSecureOptions::EmbeddingExportList, formats, 5);
request->SetOption(BFSecureOptions::EmbeddingExportDirectory, L"c:/temp");
request->SetOption(BFSecureOptions::EmbeddingExportBaseFileName, L"test.doc.embedding");
// Set the source document
request->SetOption(BFSecureOptions::SourceDocument, L"c:/temp/test.doc");
// Setup for XML output
request->SetOption(BFSecureOptions::OutputType,SecureOptions_OutputType_ToXML);
// Set the XML output document
request->SetOption(BFSecureOptions::ResultDocument,L"c:/temp/test.doc.xml");
// Execute the request
request->Execute();
// Get the response object
BFSecureResponse * response = request->GetSecureResponse();
// Check for success
if (response->GetBooleanResult(BFSecureOptions::WasProcessed)) {
// Print information about the document
FileFormats format = response->GetFileFormatResult(BFSecureOptions::SourceFormat);
std::wstring formatname;
BFSecureRequest::GetFileFormatName(format, formatname);
wcout << L"The file has a format of " << formatname << endl;
} else {
// Processing failed
wcout << L"Document processing failed" << endl;
}
BFSecureRequest::Shutdown();
} catch (BFTransformException & ex) {
wcout << ex.wwhat() << endl;
wcout << ex.wextended() << endl;
BFTransformException * cause = ex.getCause();
while (cause != NULL) {
wcout << cause->wwhat() << endl;
wcout << cause->wextended() << endl;
cause = cause->getCause();
}
}
return 0;
}
using System;
using System.Collections.Generic;
using System.Text;
using System.IO;
using CleanContent;
namespace Main
{
class Export
{
static void Main(string[] args)
{
// Initialize API
SecureHelper.Startup(true);
// Create a request
SecureRequest request = new SecureRequest();
// Don't scrub
request.SetOption(SecureOptions.JustAnalyze, true);
// Export Excel, Windows Metafile, JPEG and PNG embeddings to c:\temp using names starting with 'test.doc.em'
request.SetOption(SecureOptions.EmbeddingExportList, new FileFormat[] { FileFormat.EXCEL8, FileFormat.WMF, FileFormat.EMF, FileFormat.JPEG, FileFormat.PNG });
request.SetOption(SecureOptions.EmbeddingExportDirectory, new DirectoryInfo("c:/temp"));
request.SetOption(SecureOptions.EmbeddingExportBaseFileName, "test.doc.em");
// Set the document to extract data from
request.SetOption(SecureOptions.SourceDocument, new FileInfo("c:/temp/test.doc"));
// Setup for XML output
request.SetOption(SecureOptions.OutputType, SecureOptions.OutputTypeOption.ToXML);
// Set the XML output document
request.SetOption(SecureOptions.ResultDocument, new FileInfo("c:/temp/test.doc.xml"));
try
{
// Execute the request
request.Execute();
// Get the response object
SecureResponse response = request.GetResponse();
// Check for success
if (response.GetResult(SecureOptions.WasProcessed))
{
// Print information about the document
Console.WriteLine("The file has a format of " + response.GetResult(SecureOptions.SourceFormat).Name);
}
else
{
// Processing failed
Console.WriteLine("Document processing failed");
}
// Close the response
response.Close();
}
catch (TransformException e)
{
// An exception occured
Console.WriteLine("Document caused an exception");
Console.WriteLine(e.ToString());
}
// Close the request
request.Close();
// Uninitialize API
SecureHelper.Shutdown();
}
}
}
Embedding Replacement
Along with exporting embeddings and images Clean Content allows a developer using an element handler to replace embedded objects and images with ones of their choosing within certain strict limitations. Replacement is achieved through the use of the following options during the startEmbeddedContent and processEmbeddedContent methods within an element handler provided by the developer.
ExportDocument
Describes the location where this embedded object or image is being saved and allows the location to be overridden on an embedding by embedding basis. See Export options above.
ExportPossibleReplacementFormats
Describes the possible formats that this embedded object or image can be replaced with
ExportMaximumReplacementSize
Describes the maximum number of bytes that can be provided to replace this embedded object or image. If the value of this option is 0 (zero) then any size replacement is allowed.
ExportReplacementFormat
Set by the developer to describe the format of the bytes provided to replace this embedded object or image
ExportReplacementDocument
Set by the developer to describe the file that contains the bytes provided to replace this embedded object or image
Sample code
The following code replaces every Windows Metafile with a single PNG where possible. While this is somewhat useless behavior it demonstrates the basic code structure.
import net.bitform.api.FileFormat;
import net.bitform.api.elements.BaseElementHandler;
import net.bitform.api.elements.EmbeddedContentElement;
import net.bitform.api.options.FileOptionValue;
import net.bitform.api.options.ScrubOption;
import net.bitform.api.secure.SecureOptions;
import net.bitform.api.secure.SecureRequest;
import net.bitform.api.secure.SecureResponse;
import java.io.File;
import java.io.IOException;
public class Replace {
public static void main(String[] args) {
// Create a request
SecureRequest request = new SecureRequest();
// Need to be scrubbing since we need a ScrubbedDocument to hold replacements but don't really want to
// scrub anything else
request.setOption(SecureOptions.JustAnalyze, false);
request.setOption(SecureOptions.DefaultScrubBehavior, ScrubOption.Action.NONE);
// Export Windows Metafiles
request.setOption(SecureOptions.EmbeddingExportList, new FileFormat[]{FileFormat.WMF, FileFormat.EMF});
request.setOption(SecureOptions.EmbeddingExportDirectory, new File("c:/temp"));
request.setOption(SecureOptions.EmbeddingExportBaseFileName, "metafile");
// Set the source document
request.setOption(SecureOptions.SourceDocument, new File("c:/temp/test.doc"));
// Element handler to replace metafiles with PNGs
class MyHandler extends BaseElementHandler {
// The start of embedded content
// This sample just prints out the file path but a real world application
// might want to process the embedding, possibly to the generate a replacement
// in another format.
public void startEmbeddedContent(EmbeddedContentElement element) throws IOException {
if (element.exportOptions != null) {
FileOptionValue file = element.exportOptions.getOption(SecureOptions.ExportDocument);
if (file.isFile()) {
System.out.println("The exported embedding is in " + file.getFile().getAbsolutePath());
}
}
}
// This method gives the developer to opportunity to replace the embedding
public void processEmbeddedContent(EmbeddedContentElement element) throws IOException {
// If this image can be replaced
if (element.isReplaceable) {
// Replace with a small, fixed PNG
File replacementFile = new File("c:/temp/small.png");
long maxFileSize = element.exportOptions.getOption(SecureOptions.ExportMaximumReplacementSize);
// If the PNG will fit in the space available
// or there is no limit (maxFileSize == 0)
if (maxFileSize == 0 || maxFileSize >= replacementFile.length()) {
FileFormat[] formats = element.exportOptions.getOption(SecureOptions.ExportPossibleReplacementFormats);
for (int i = 0; i < formats.length; i++) {
// If PNG is one of the possible replacement formats, replace the image
if (formats[i] == FileFormat.PNG) {
element.exportOptions.setOption(SecureOptions.ExportReplace, true);
element.exportOptions.setOption(SecureOptions.ExportReplacementFormat, FileFormat.PNG);
element.exportOptions.setOption(SecureOptions.ExportReplacementDocument, replacementFile);
break;
}
}
}
}
}
}
// Setup for output to my element handler
request.setOption(SecureOptions.OutputType, SecureOptions.OutputTypeOption.ToHandler);
request.setOption(SecureOptions.ElementHandler, new MyHandler());
// Set scrubbed document
request.setOption(SecureOptions.ScrubbedDocument, new File("c:/temp/test.replace.doc"));
try {
// Execute the request
request.execute();
// Get the response object
SecureResponse response = request.getResponse();
// Check for success
if (response.getResult(SecureOptions.WasProcessed)) {
// Print information about the document
System.out.println("The file has a format of " + response.getResult(SecureOptions.SourceFormat).getName());
} else {
// Processing failed
System.out.println("Document processing failed");
}
} catch (IOException e) {
// An exception occured
System.out.println("Document caused an exception");
e.printStackTrace();
}
}
}
#include <iostream>
#include <tchar.h>
#include <malloc.h>
#include <sys/types.h>
#include <sys/stat.h>
using namespace std;
#include "secureapi.h"
#ifdef BFWIN
#include <windows.h>
#endif
int main(int argc, _TCHAR* argv[])
{
try {
// Initialize the Clean Content API
BFSecureRequest::Startup(BFSTARTUPFEATURE_DEBUG);
// Create a request
BFSecureRequest * request = new BFSecureRequest();
// Need to be scrubbing since we need a ScrubbedDocument to hold
// replacements but don't really want to scrub anything else
request->SetOption(BFSecureOptions::JustAnalyze, FALSE);
request->SetOption(BFSecureOptions::DefaultScrubBehavior, ScrubOption_Action_None);
// Export Windows Metafiles
enum FileFormats formats[] = {BFFileFormat::WMF, BFFileFormat::EMF};
request->SetOption(BFSecureOptions::EmbeddingExportList, formats, 2);
// Set the document to be scrubbed
request->SetOption(BFSecureOptions::SourceDocument, L"c:/temp/test.doc");
// Set the scrubbed document
request->SetOption(BFSecureOptions::ScrubbedDocument, L"c:/temp/test.replace.doc");
// Element handler to replace metafiles with PNGs
class MyHandler : public BFBaseElementHandler {
// The start of embedded content
// This sample just prints out the file path but a real world application
// might want to process the embedding, possibly to the generate a replacement
// in another format.
void StartEmbeddedContent(BFEmbeddedContentElement * element) {
// Use the exportOptions handle to create a BFOptionSet.
// The handle could also be used directly with the appropriate C options functions
BFOptionSet exportOptions(element->exportOptions);
// Show the file name there the embedding will be exported
if (exportOptions.IsValid()) {
std::wstring fileName;
exportOptions.GetOption(BFSecureOptions::ExportDocument, fileName);
wcout << "The exported embedding is in " << fileName << endl;
}
}
// This method gives the developer to opportunity to replace the embedding
void ProcessEmbeddedContent(BFEmbeddedContentElement * element) {
// Use the exportOptions handle to create a BFOptionSet.
// The handle could also be used directly with the appropriate C options functions
BFOptionSet exportOptions(element->exportOptions);
// If this image can be replaced
if (element->isReplaceable == BFTRUE) {
// Replace with small fixed PNG
wstring replacementFile(L"c:\\temp\\small.png");
BFINT64 maxFileSize = exportOptions.GetOption(BFSecureOptions::ExportMaximumReplacementSize);
// If the PNG will fit in the space available
// or there is no limit (maxFileSize == 0)
struct _stat buf;
_wstat(replacementFile.c_str(), &buf);
if (maxFileSize == 0 || maxFileSize >= buf.st_size) {
enum FileFormats formats[20];
int formatCount = 20;
exportOptions.GetOption(BFSecureOptions::ExportPossibleReplacementFormats,formats,&formatCount);
// If PNG is one of the possible replacement formats, replace the image
for (int i = 0; i < formatCount ; i++) {
if (formats[i] == BFFileFormat::PNG) {
exportOptions.SetOption(BFSecureOptions::ExportReplace,true);
exportOptions.SetOption(BFSecureOptions::ExportReplacementFormat,BFFileFormat::PNG);
exportOptions.SetOption(BFSecureOptions::ExportReplacementDocument,replacementFile);
break;
}
}
}
}
}
};
MyHandler myElementHandler = MyHandler();
// Setup for element handler output
request->SetOption(BFSecureOptions::OutputType,SecureOptions_OutputType_ToHandler);
// Set the element handler
request->SetOption(BFSecureOptions::ElementHandler,&myElementHandler);
// Execute the request
request->Execute();
// Get the response object
BFSecureResponse * response = request->GetSecureResponse();
// Check for success
if (response->GetBooleanResult(BFSecureOptions::WasProcessed)) {
// Print information about the document
FileFormats format = response->GetFileFormatResult(BFSecureOptions::SourceFormat);
std::wstring formatname;
BFSecureRequest::GetFileFormatName(format, formatname);
wcout << L"The file has a format of " << formatname << endl;
} else {
// Processing failed
wcout << L"Document processing failed" << endl;
}
BFSecureRequest::Shutdown();
} catch (BFTransformException & ex) {
wcout << ex.wwhat() << endl;
wcout << ex.wextended() << endl;
BFTransformException * cause = ex.getCause();
while (cause != NULL) {
wcout << cause->wwhat() << endl;
wcout << cause->wextended() << endl;
cause = cause->getCause();
}
}
return 0;
}
using System;
using System.Collections.Generic;
using System.Text;
using System.IO;
using System.Runtime.InteropServices;
using System.Diagnostics;
using CleanContent;
namespace Main
{
class Replace
{
// Element handler class to replace images with small PNG
class MyHandler : BaseElementHandler
{
// The start of embedded content
// This sample just prints out the file path but a real world application
// might want to process the embedding, possibly to the generate a replacement
// in another format.
public override void StartEmbeddedContent(IntPtr handler, ref EmbeddedContentElement element)
{
if (element.exportOptions != null) {
FileInfo file = element.exportOptions.GetOption(SecureOptions.ExportDocument);
Console.WriteLine("The exported embedding is of type "+element.format.Name+" and will be exported to the file " + file.FullName);
}
}
// This method gives the developer to opportunity to replace the embedding
public override void ProcessEmbeddedContent(IntPtr handler, ref EmbeddedContentElement element)
{
// If this image can be replaced
if (element.isReplaceable)
{
// Replace with a small, fixed PNG
FileInfo replacementFile = new FileInfo("c:/temp/small.png");
long maxFileSize = element.exportOptions.GetOption(SecureOptions.ExportMaximumReplacementSize);
// If the PNG will fit in the space available
// or there is no limit (maxFileSize == 0)
if (maxFileSize == 0 || maxFileSize >= replacementFile.Length)
{
FileFormat[] formats = element.exportOptions.GetOption(SecureOptions.ExportPossibleReplacementFormats);
for (int i = 0; i < formats.Length; i++)
{
// If PNG is one of the possible replacement formats, replace the image
if (formats[i] == FileFormat.PNG)
{
element.exportOptions.SetOption(SecureOptions.ExportReplace, true);
element.exportOptions.SetOption(SecureOptions.ExportReplacementFormat, FileFormat.PNG);
element.exportOptions.SetOption(SecureOptions.ExportReplacementDocument, replacementFile);
break;
}
}
}
}
}
}
static void Main(string[] args)
{
// Initialize API
SecureHelper.Startup(true);
// Create a request
SecureRequest request = new SecureRequest();
// Need to be scrubbing since we need a ScrubbedDocument to hold replacements but don't really want to
// scrub anything else
request.SetOption(SecureOptions.JustAnalyze, false);
request.SetOption(SecureOptions.DefaultScrubBehavior, ScrubOption.Action.NONE);
// Export Windows Metafiles
request.SetOption(SecureOptions.EmbeddingExportList, new FileFormat[] { FileFormat.WMF, FileFormat.EMF });
request.SetOption(SecureOptions.EmbeddingExportDirectory, new DirectoryInfo("c:/temp"));
request.SetOption(SecureOptions.EmbeddingExportBaseFileName, "metafile");
// Set source document
request.SetOption(SecureOptions.SourceDocument, new FileInfo("c:/temp/test.doc"));
// Setup for output to my element handler
request.SetOption(SecureOptions.OutputType, SecureOptions.OutputTypeOption.ToHandler);
request.SetOption(SecureOptions.ElementHandler, new MyHandler());
// Set scrubbed document
request.SetOption(SecureOptions.ScrubbedDocument, new FileInfo("c:/temp/test.replace.doc"));
try
{
// Execute the request
request.Execute();
// Get the response object
SecureResponse response = request.GetResponse();
// Check for success
if (response.GetResult(SecureOptions.WasProcessed))
{
// Print information about the document
Console.WriteLine("The file has a format of " + response.GetResult(SecureOptions.SourceFormat).Name);
}
else
{
// Processing failed
Console.WriteLine("Document processing failed");
}
// Close the response
response.Close();
}
catch (TransformException e)
{
// An exception occured
Console.WriteLine("Document caused an exception");
Console.WriteLine(e.ToString());
}
// Close the request
request.Close();
// Uninitialize API
SecureHelper.Shutdown();
}
}
}
PowerPoint Disassembly/Assembly
Preliminary & subject to change
As a special extension to Clean Content, PowerPoint files may been broken into individual slides, each in its own standalone PowerPoint file (disassembly) and a PowerPoint file may be created from a collection of other PowerPoint files (assembly).
Disassembly reuses many of the options from Embedding Export (see above). The EmbeddingExportDirectory option provides the default directory where disassembled slides should be placed and EmbeddingExportBaseFileName provides the default file name prefix to use for exported slides. In addition, the developer may track or modify the locations of exported slides using the ExportDocument option during the startExportDocument method in an element handler. Disassembly is triggered by setting the JustDisassemble option to true.
Assembly is triggered by setting the JustAssemble option to true. It generates a new PowerPoint created from the files provided in the AssembleFileList option. As with disassembly the resulting PowerPoint is placed in EmbeddingExportDirectory using the name prefix EmbeddingExportBaseFileName and may be overridden using the startExportDocument method in an element handler.
Disassembly Sample
import net.bitform.api.FileFormat;
import net.bitform.api.elements.BaseElementHandler;
import net.bitform.api.elements.ExportDocumentElement;
import net.bitform.api.options.FileOptionValue;
import net.bitform.api.secure.SecureOptions;
import net.bitform.api.secure.SecureRequest;
import net.bitform.api.secure.SecureResponse;
import java.io.File;
import java.io.IOException;
public class Disassemble {
public static void main(String[] args) {
// Create a request
SecureRequest request = new SecureRequest();
// Don't scrub
request.setOption(SecureOptions.JustAnalyze, true);
// Set to disassemble
request.setOption(SecureOptions.JustDisassemble, true);
// Disassemble to c:\temp\out using names starting with 'test.ppt.slide'
request.setOption(SecureOptions.EmbeddingExportDirectory, new File("c:/temp/out"));
request.setOption(SecureOptions.EmbeddingExportBaseFileName, "test.ppt.slide");
// Set the document to disassemble
request.setOption(SecureOptions.SourceDocument, new File("c:/temp/test.ppt"));
// Set a handler that just prints out the names of the files as they get exported
request.setOption(SecureOptions.ElementHandler, new BaseElementHandler() {
public void startExportDocument(ExportDocumentElement element) throws IOException {
FileOptionValue file = element.exportOptions.getOption(SecureOptions.ExportDocument);
if (file.isFile()) {
System.out.println(file.getFile().getName());
}
}
});
try {
// Execute the request
request.execute();
// Get the response object
SecureResponse response = request.getResponse();
// Make sure the SourceDocument was PowerPoint since that's all
// Clean Content currently supports
FileFormat format = response.getResult(SecureOptions.SourceFormat);
if (format.is(FileFormat.POWERPOINT8)) {
// Check for success
if (response.getResult(SecureOptions.WasProcessed)) {
// Print information about the document
System.out.println("The file was disassembled");
} else {
// Processing failed
System.out.println("Document processing failed");
}
} else {
System.out.println("Files of the format " + format.getName() + " cannot be disassembled");
}
} catch (IOException e) {
// An exception occured
System.out.println("Document caused an exception");
e.printStackTrace();
}
}
}
Assembly Sample
import net.bitform.api.secure.SecureRequest;
import net.bitform.api.secure.SecureOptions;
import net.bitform.api.secure.SecureResponse;
import net.bitform.api.FileFormat;
import net.bitform.api.elements.BaseElementHandler;
import net.bitform.api.elements.ExportDocumentElement;
import net.bitform.api.options.FileOptionValue;
import java.io.File;
import java.io.IOException;
public class Assemble {
public static void main(String[] args) {
// Create a request
SecureRequest request = new SecureRequest();
// Don't scrub
request.setOption(SecureOptions.JustAnalyze,true);
// Set to assemble
request.setOption(SecureOptions.JustAssemble,true);
// Assemble three PowerPoint files
File[] files = {
new File("c:/temp/test1.ppt"),
new File("c:/temp/test2.ppt"),
new File("c:/temp/test3.ppt")
};
request.setOption(SecureOptions.AssembleFileList,files);
// Assemble to c:\temp\out using name starting with 'result'
request.setOption(SecureOptions.EmbeddingExportDirectory, new File("c:/temp/out"));
request.setOption(SecureOptions.EmbeddingExportBaseFileName, "result");
// Set the document to use as a template for masters, etc.
request.setOption(SecureOptions.SourceDocument, new File("c:/temp/test.ppt"));
// Set a handler that just prints out the name of the file as it gets exported
request.setOption(SecureOptions.ElementHandler, new BaseElementHandler() {
public void startExportDocument(ExportDocumentElement element) throws IOException {
FileOptionValue file = element.exportOptions.getOption(SecureOptions.ExportDocument);
if (file.isFile()) {
System.out.println(file.getFile().getName());
}
}
});
try {
// Execute the request
request.execute();
// Get the response object
SecureResponse response = request.getResponse();
// Make sure the SourceDocument was PowerPoint since that's all
// Clean Content currently supports
FileFormat format = response.getResult(SecureOptions.SourceFormat);
if (format.is(FileFormat.POWERPOINT8)) {
// Check for success
if (response.getResult(SecureOptions.WasProcessed)) {
// Print information about the document
System.out.println("The files were assembled");
} else {
// Processing failed
System.out.println("Document processing failed");
}
} else {
System.out.println("Files of the format "+format.getName()+" cannot be assembled");
}
} catch (IOException e) {
// An exception occured
System.out.println("Document caused an exception");
e.printStackTrace();
}
}
}
Threading
In deciding how to introduce this API into your code, one major factor to consider is how your application uses or will use threads to process documents. While a complete discussion of this topic is outside the scope of this document, the following guidelines may provide some direction.
- For each thread in which you want to process documents, create a separate SecureRequest object and reuse it for multiple documents but only within the thread that created it. This is not a hard requirement but it is the safest way to proceed.
- Do not process documents in threads handling UI activity unless you are willing to force the user (and the UI) to wait for completion of the analysis or scrub.
- A very general performance guideline is to use four threads per processor to process documents. This assumes (perhaps incorrectly) that the developer wants all the power of the machine directed at analysis or scrubbing. This is a guideline only. Actual scalability is based on a large number of factors including the machine architecture, IO subsystem performance, exactly what API calls are used, if any result documents are being produced, if reporting is enabled and many other factors.
Timeouts
Clean Content has two options that control when and how a given SecureRequest will be stopped if it has not been completed in a certain amount of time.
The RequestTimeout options defines the number of milliseconds in elapsed time the SecureRequest is allowed to process before an attempt is made to stop it. Choosing a correct value for this option can be tricky because real world documents show a huge range of processing times depending on their size, format, and content, all the way for a few milliseconds to a minute of more. The default is two minutes but depending on the hardware, the IO subsystem, how many concurrent requests are running, and many other factors the customer may choose to pick a more or less conservative number.
The TimeoutUsingThreadStop option defines how Clean Content should go about stopping a SecureRequest when the timeout value has been reached. If set to false (the default) then Clean Content will use Java's standard synchronous thread interruption methodology (Thread.interrupt). This method will interrupt most requests which have been driven into a loop by a malformed input document, however it won't be able to interrupt requests in the extremely rare cases where an input document drives Clean Content into a tight infinite loop. If this option is set to true, then five seconds after attempting a synchronous thread interruption Clean Content will use Java's deprecated Thead.stop method. Use of this method is strongly discouraged by Oracle and customers should review the documentation Stop parameter and Java Thread Primitive Deprecation before setting this option to true. That being said, some customers may feel the risk associated with using Thead.stop may be worth it to avoid 'stuck' threads in these extremely rare cases. We advise some very focused QA when using this option.
To help the customer test timeouts the SDK provides two files in the samplefiles\exception directory. Timeout.doc purposely drives Clean Content into an infinite loop that can be timed out synchronous (Thread.interrupt) and will allow customers to test that case. InfiniteLoop.doc purposely drives Clean Content into a tight infinite loop that can only be timed out if TimeoutUsingThreadStop is set to true.
Note: In order to prevent InfiniteLoop.doc being used in a Denial of Service attack against Clean Content it only loops for one minute allowing for QA (assuming the RequestTimeout option is set to something low like 40 seconds) but not for a DOS attack.
Exception Handling
Clean Content is expected to handle any source document no matter how complex, malformed, hacked or truncated. Processing of such documents is an inherently garbage in/garbage out situation and developers running large numbers of documents (100,000 or more) can expect to see a wide array of exceptions occurring during the SecureRequest execute method. As of version 2007.1 all checked and many unchecked exceptions are caught internally by Clean Content and wrapped in TransformException which is a subclass of IOException. This means that as of version 2007.1 developers need only trap IOException during the execute method. Developers may then call the TransformException getCause method to get more detailed information on the underlying exception.
The unchecked exceptions trapped and wrapped during the execute method include...
- RuntimeException
Many of these exceptions trap what in self contained code might be called "programming errors" such as NullPointerException. In code that deals with documents of this complexity such errors generally occur when malformed documents take the code down illegal or unexpected paths of execution.
- OutOfMemoryError
A malformed document may lead to excessive allocation. NOTE: Some products/customers choose to set the JVM debug option -XX:+HeapDumpOnOutOfMemoryError in servers environments. This option should be avoided for JVM's running Clean Content since malformed documents may drive the code into attempting huge allocation thereby producing an OutOfMemoryError exception which is fully recoverable. Much recent work has gone in to identifying these situations before they happen but Clean Content cannot guarantee that an OutOfMemoryError exception will never be thrown.
- StackOverflowError
A malformed document may lead to excessive method calls or stack allocation.
The developer is assured failure atomicity and may continue to use the SecureRequest which threw the exception.
In order to facilitate testing of exceptional conditions the Clean Content SDK includes a number of specifically modified Microsoft Word documents that trigger Clean Content to generate certain exceptions. These document are in the SDK's samplefiles/exception directory. The document names indicate the exceptions they generate. Note that these documents DO NOT exercise "bugs" in Clean Content. They have been modified to have specific data in an innocuous location that the Word transform picks up on and purposely causes the given exception.
Install and Coding Guidelines
Java
Compilation and distribution
Your application must compile and ship with CleanContent.jar from the java/lib directory of the SDK. As with all jar files this one must be included in the classpath of your Java application.
C/C++
General
Including secureapi.h
In order to use the Clean Content's C/C++ API you must include the file secureapi.h from the SDK's c/include directory in your C or C++ source code. It defines all the C API entry points, structures, etc. If included in a C++ source file, secureapi.h also defines the classes in the C++ API. It should be noted that CleanContentAPI library (CleanContentAPI.dll, CleanContentAPI.so, CleanContentAPI.a, etc.) does not include or export the C++ API classes (only the C API functions). The classes are declared and defined right in secureapi.h using the "headers only" model. This avoids name mangling and other C++ compiler/linker interoperability issues.
Include files are located in the SDK at c/include.
Getting the right pieces is critical!
Over 50% of the issues Oracle sees from customers using the C/C++ API relate to getting all the pieces of the technology in the right location so the platform specific C/C++ library can find them during the BFStartup() function. Please read the Installation and Distribution section for your platform carefully and thoroughly!
Windows
Compiling and Linking
Library
The library CleanContentAPI.lib must be linked with your application and CleanContentAPI.dll must be delivered (see below) with your application. CleanContentAPI.dll has no dependencies (such as MFC or ATL) other than standard Win32 libraries.
The Windows library is located in the SDK at c/lib/windows/x86 for Win32 and c/lib/windows/x64 for Win64.
Installation and Distribution
Your Windows distribution must include these three components.
CleanContentAPI.dll
This DLL must be linked with your application and be available to your application at run time. Any standard method of making this DLL available to your EXE will work including placing it in the same directory as your EXE or putting its location on the PATH.
Oracle strongly advises against placing this DLL in the WINDOWS or SYSTEM directory unless you have complete control of the environment (if your product is a hardware appliance for example). It is possible that another vendor's product that also uses Clean Content (perhaps a different version) will be installed on the same system so keeping this DLL as isolated as possible is in everyone's best interest.
CleanContent.jar
This is the Clean Content Java code that does all the real work. You have two options for locating this file. The best option is to place it in the same directory as CleanContentAPI.dll where it will be found automatically. If that structure does not work for your application you may set the BITFORM_JARPATH environment variable to the directory containing this file. This environment variable may be set in a batch file that starts your application or using Windows' SetEnvironemntVariable() function within your code before calling BFStartup(). We strongly recommend against setting this environment variable globally to avoid conflicts with other vendor's software. Do not use the runtime library _putenv() routine to set BITFORM_JARPATH.
Java Runtime Environment (JRE)
This is a set of DLLs and other files that make up the Java Virtual Machine. There are several options available as to where you get the JRE and where it gets placed in your application's directory structure. Note that this SDK ships with 4 JREs (Win32, Win64, Linux32 and Linux64) but any given platform only needs one JRE.
Where to get it...
Option 1
This SDK includes Windows Java 1.5 JREs in the jres/Windows/x86/jre and jres/Windows/x64/jre directories. Either of these directories (including all files and subdirectories) may be shipped with your application.
Option 2
You may use any other Java 1.5 or above JRE. For example, if your application already ships with a JRE you can reuse it.
Where to put it...
Option 1
The simplest option is to place the JRE in a jre subdirectory of the directory where CleanContentAPI.dll exists.
Option 2
Place the JRE anywhere you like and set BITFORM_JREPATH environment variable to the jre directory. This environment variable may be set in a batch file that starts your application or using Windows' SetEnvironmentVariable() function within your code before calling BFStartup(). We strongly recommend against setting this environment variable globally to avoid conflicts with other vendors software. Do not use the runtime library _putenv() routine to set BITFORM_JREPATH.
Example 1
The simplest possible distribution looks like this:
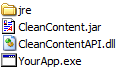
In this case CleanContentAPI.dll will discover the jar and the jre, no environment variables need to be set.
Example 2
Let's say your distribution looked like the one below and you know there is a compatible Java Runtime Environment at c:\components\jre.
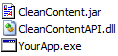
Your source code might include the following lines:
SetEnvironmentVariableA("BITFORM_JREPATH","c:\\components\\jre");
BFStartup(BFSTARTUPFEATURE_DEBUG);
Linux
Compiling and Linking
Static Library
To use the Clean Content static library simply link with CleanContentAPI.a in either the c/lib/linux/x86/lib or c/lib/linux/x64/lib directories of the SDK depending on your platform.
Shared Library
To use the Clean Content shared library, the library CleanContentAPI must be linked with your application. This library is a shared object located in either the c/lib/linux/x86/lib or c/lib/linux/x64/lib directory of the SDK. The contents of this directory follow Linux library naming standards as follows:
libCleanContentAPI.so.4.0.0
This is the real shared library
libCleanContentAPI.so.4
This is a symbolic link to libCleanContentAPI.so.4.0.0 and represents its "soname". This is the name that executables linked to this library will look for.
libCleanContentAPI.so
This is also a symbolic link to libCleanContentAPI.so.4.0.0 and represents its "link name ". This is the name that the linker will look for when your application is linked using -lCleanContentAPI.
Installation and Distribution
A Linux distribution must includes two and possibly three components.
libCleanContentAPI.so.4.0.0 (shared library linking only)
This is a shared library that must be linked with your application and must be available to your application at runtime along with a symbolic link of the name libCleanContentAPI.so.4. Like any other shared library your application must be able to find libCleanContentAPI.so.4 at runtime. This can be accomplished in any of the Linux standard ways including the following:
- By placing libCleanContentAPI.so.4.0.0 in any of the standard library directories (like usr/lib) and running ldconfig. This will create the libCleanContentAPI.so.4 symbolic link automatically.
- By placing libCleanContentAPI.so.4.0.0 and libCleanContentAPI.so.4 in any directory you like and including that directory in the LD_LIBRARY_PATH environment variable. It must be set in the script that starts your application or through some other method that makes it available to your application at startup. It is recommend that LD_LIBRARY_PATH not be set globally.
- By placing libCleanContentAPI.so.4.0.0 and libCleanContentAPI.so.4 in any directory you like and including that directory in /usr/ld.so.conf.
- By placing libCleanContentAPI.so.4.0.0 and libCleanContentAPI.so.4 in any directory you like and including that directory in your application's library search path using the linker's -rpath option.
CleanContent.jar
This is the Clean Content Java code that does all the real work. You have two options for locating this file. The best option is to place it in the same directory as your application where it will be found automatically using /proc/self/exe. If that structure does not work for your application you may set the BITFORM_JARPATH environment variable to the directory containing this file (not the file itself). This environment variable may be set in a script file that starts your application or using the _putenv() function within your code before calling BFStartup(). We strongly recommend against setting this environment variable globally to avoid conflicts with other vendors software.
Java Runtime Environment (JRE)
This is a set of SOs and other files that make up the Java Virtual Machine. There are several options available as to where you get the JRE and where it gets placed in your application's directory structure. Note that this SDK ships with 4 JREs (Win32, Win64, Linux32 and Linux64) but any given platform only needs one JRE.
Where to get it...
Option 1
This SDK includes Linux Java 1.5 JREs in the jres/Linux/x86/jre and jres/Linux/x64/jre directories. Either of these directories (including all files and subdirectories) may be shipped with your application.
Option 2
You may use any other Java 1.5 or above JRE. For example, if your application already ships with a JRE you can reuse it.
Where to put it...
Option 1
The simplest option is to place (or link) the JRE in a jre subdirectory of your application's directory as found using /proc/self/exe.
Option 2
Place the JRE anywhere you like and set BITFORM_JREPATH environment variable to the jre directory. This environment variable may be set in a script file that starts your application or using the _putenv() function within your code before calling BFStartup(). Oracle strongly recommends against setting this environment variable globally to avoid conflicts with other vendors software.
Distribution Examples
Example 1
The simplest possible distribution looks like this:

In this case the Clean Content code in libCleanContentAPI.so that is linked to yourapp will discover the JAR file and the JRE directory.
Example 2
Let's say your distribution looked like the one below and you know there is compatible Java Runtime Environment at /usr/java/j2re1.5.0.

Your source code might include the following lines:
_putenv("BITFORM_JREPATH=/usr/java/j2re1.5.0");
BFStartup(BFSTARTUPFEATURE_DEBUG);
Compiling the C/C++ API on other platforms
The SDKs c directory contains a standard autoconf/automake/libtool based build process that should work on any reasonable unix-like OS that provides both a Java 1.5 or above Java Development Kit (JDK) and a recent GNU compiler tool chain. Steps to rebuild the C/C++ API library are as follows;
- Find or get a Java 1.5 compatible JDK for your OS.
Note: This must be a JDK which allows one to develop java applications not just a JRE which only allows one to run them.
- Set the JAVA_HOME environment variable to the root of the JDK. For example something like this...
export JAVA_HOME=/usr/lib/jvm/java-1.6.0
- Change to the c directory of the Clean Content SDK
- Run .\configure
- If configure completes successfully then run make all install
- Results will be placed in a sub-directory under c/lib named using uname
.NET
Close methods
Due to some unfortunate details of the Clean Content architecture and .NET object finalization the .NET API requires that the developer call explicit Close methods for SecureRequest and SecureResponse objects. Failure to call Close on these object types will result in memory leakage.
Getting the right pieces is critical!
Over 50% of the issues Oracle sees from customers using the .NET API relate to getting all the pieces of the technology in the right location so the .NET assembly can find them during the SecureHelper.Startup method. Please read the Installation and Distribution section carefully and thoroughly!
Compiling and Linking
Assembly
The Clean Content .NET API is provided as a single dll called CleanContentNET.dll. No installation into the GAC is provided or required.
Installation and Distribution
A .NET distribution includes four components.
CleanContentNET.dll
This .NET assembly must be referenced by your application and available to your application at run time under the rules of the .NET Framework. The simplest way to make this happen is to place it in the same folder as your application.
CleanContentAPI.dll
This is the Clean Content C API DLL on which the .NET API relies. It can be found in the c/lib/windows/x86 or c/lib/windows/x64 directory of the SDK. It must be placed in a location where if can be found by CleanContentNET.dll following the rules of the .NET DllImport attribute. The simplest and best way to make this happen is to place it in the same folder as CleanContentNET.dll.
CleanContent.jar
This is the Clean Content Java code that does all the real work. It can be found in the java/lib directory of the SDK. You have two options for locating this file. The best option is to place it in the same directory as CleanContentAPI.dll where it will be found automatically. If that structure does not work for your application you may set the BITFORM_JARPATH environment variable to the directory containing this file. This environment variable may be set in a batch file that starts your application or using .NET's System.Environment.SetEnvironemntVariable method within your code before calling SecureHelper.Startup. We strongly recommend against setting this environment variable globally to avoid conflicts with other vendor's software.
Java Runtime Environment (JRE)
This is a set of DLLs and other files that make up the Java Virtual Machine. There are several options available as to where you get the JRE and where it gets placed in your application's directory structure.
Where to get it...
Option 1
This SDK includes 32 bit and 64 bit Java 1.5 JREs in the jres\Windows\x86\jre and jres\Windows\x64\jre directories. One of these directories (including all files and subdirectories) may be shipped with your application.
Option 2
You may use any other Java 1.5 or later version of Sun's JRE. For example, if your application already ships with a JRE you can reuse it.
Where to put it...
Option 1
The simplest option is to place the JRE in a jre subdirectory of the directory where CleanContentAPI.dll exists.
Option 2
Place the JRE anywhere you like and set the environment variable BITFORM_JREPATH to the jre directory. This environment variable may be set in a batch file that starts your application or using .NET's System.Environment.SetEnvironemntVariable method within your code before calling SecureHelper.Startup. We strongly recommend against setting this environment variable globally to avoid conflicts with other vendor's software.
Distribution Examples
Example 1
The simplest possible distribution looks like this:
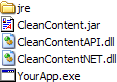
In this case your application will find CleanContentNET.dll, CleanContentNET.dll will find CleanContentAPI.dll, and CleanContentAPI.dll will find the jar and the JRE. No environment variables need to be set.
Example 2
Let's say your distribution looked like the one below and you know there is compatible Java Runtime Environment at c:\components\jre.
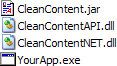
Your source code might include the following lines:
System.Environment.SetEnvironmentVariable("BITFORM_JREPATH","c:\\components\\jre");
SecureHelper.Startup(true);
Copyright © 2010, 2018, Oracle and/or its affiliates. All rights reserved.