En Spark, la conectividad de Object Storage se utiliza para realizar consultas en la base de datos alojada en Object Storage mediante spark-sql, spark-shell, spark-submit, etc.
Requisitos previos:
- El usuario de Hadoop del cluster debe formar parte del grupo de Spark.
En Linux:
id bdsuser
uid=54330(bdsuser) gid=54339(superbdsgroup) groups=54339(superbdsgroup,985(hadoop),984(hdfs),980(hive),977(spark)
En guardabosques:

En Ranger, acceda al separador Users y verifique en la columna Groups que el usuario forma parte del grupo Spark.
- Los usuarios de Spark y Hadoop se deben agregar a las siguientes políticas en Ranger.
tag.download.auth.userspolicies.download.auth.users
Para verificarlo, en la interfaz de usuario de Ranger, seleccione Access Manager > Políticas basadas en recursos y, a continuación, seleccione el botón de edición para la instancia de Spark. Se muestra la ventana Propiedades de configuración.
Ejemplo:
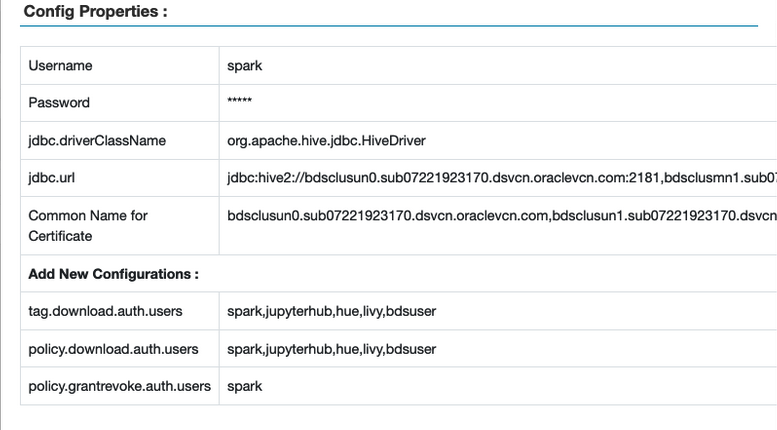
- Asegúrese de que el usuario de Hadoop se ha agregado a la política
all - database, table, column para proporcionar el privilegio SELECT en la base de datos, la tabla y las columnas. Para verificar:
- En la interfaz de usuario de Ranger, seleccione Access Manager (Gestor de acceso) > Resource Based Policies (Políticas basadas en recursos) y, a continuación, seleccione el repositorio SPARK3.
- Seleccione las políticas creadas para el usuario.
- Seleccione all - database, table, column y, a continuación, seleccione Edit.
- En la sección Permitir condiciones, verifique que se muestra el usuario de Hadoop, si no, agregue el usuario.
Nota
Puede utilizar nodos de cluster de Big Data Service para la configuración del servicio y ejemplos en ejecución. Para utilizar un nodo de límite, debe crear el nodo de límite y conectarse a él.
- (Opcional) Para utilizar un nodo de perímetro para configurar Object Storage, cree primero un nodo de perímetro y, a continuación, conéctese al nodo. A continuación, copie la clave de API del nodo un0 en el nodo de perímetro.
sudo dcli rsync -a <un0-hostname>:/opt/oracle/bds/.oci_oos/ /opt/oracle/bds/.oci_oos/
-
Cree un usuario con permisos suficientes y un archivo JCEKS con el valor de frase de contraseña necesario. Si va a crear un archivo JCEKS local, copie el archivo en todos los nodos y cambie los permisos de usuario.
sudo dcli -f <location_of_jceks_file> -d <location_of_jceks_file>
sudo dcli chown <user>:<group> <location_of_jceks_file>
-
Agregue una de las siguientes combinaciones
HADOOP_OPTS al perfil bash de usuario.
Opción 1:
export HADOOP_OPTS="$HADOOP_OPTS -DOCI_SECRET_API_KEY_ALIAS=<api_key_alias>
-DBDS_OSS_CLIENT_REGION=<api_key_region> -DOCI_SECRET_API_KEY_PASSPHRASE=<jceks_file_provider>"
Opción 2:
export HADOOP_OPTS="$HADOOP_OPTS -DBDS_OSS_CLIENT_AUTH_FINGERPRINT=<api_key_fingerprint>
-DBDS_OSS_CLIENT_AUTH_PASSPHRASE=<jceks_file_provider> -DBDS_OSS_CLIENT_AUTH_PEMFILEPATH=<api_key_pem_file_path>
-DBDS_OSS_CLIENT_AUTH_TENANTID=<api_key_tenant_id> -DBDS_OSS_CLIENT_AUTH_USERID=<api_key_user_id> -DBDS_OSS_CLIENT_REGION=<api_key_region>"
-
En Ambari, agregue las opciones de Hadoop a la plantilla hive-env para el acceso a Object Storage.
-
Acceda a Apache Ambari.
-
En la barra de herramientas lateral, en Servicios, seleccione Hive.
-
Seleccione Configs (Configuración).
-
Seleccione Avanzado.
-
En la sección Rendimiento, vaya a Advanced hive-env.
-
Vaya a hive-env template y, a continuación, agregue una de las siguientes opciones en la línea
if [ "$SERVICE" = "metastore" ]; then.
Opción 1:
export HADOOP_OPTS="$HADOOP_OPTS -DOCI_SECRET_API_KEY_ALIAS=<api_key_alias>
-DBDS_OSS_CLIENT_REGION=<api_key_region>
-DOCI_SECRET_API_KEY_PASSPHRASE=<jceks_file_provider>"
Opción 2:
export HADOOP_OPTS="$HADOOP_OPTS -DBDS_OSS_CLIENT_AUTH_FINGERPRINT=<api_key_fingerprint>
-DBDS_OSS_CLIENT_AUTH_PASSPHRASE=<jceks_file_provider> -DBDS_OSS_CLIENT_AUTH_PEMFILEPATH=<api_key_pem_file_path>
-DBDS_OSS_CLIENT_AUTH_TENANTID=<api_key_tenant_id> -DBDS_OSS_CLIENT_AUTH_USERID=<api_key_user_id>
-DBDS_OSS_CLIENT_REGION=<api_key_region>"
-
Reinicie todos los servicios necesarios a través de Ambari.
-
Ejecute uno de los siguientes comandos de ejemplo para iniciar el shell SQL de spark:
Ejemplo1:
spark-sql --conf spark.driver.extraJavaOptions="${HADOOP_OPTS}" --conf spark.executor.extraJavaOptions="${HADOOP_OPTS}"
Ejemplo 2: uso del alias de clave de API y la frase de contraseña.
spark-sql --conf spark.hadoop.OCI_SECRET_API_KEY_PASSPHRASE=<api_key_passphrase>
--conf spark.hadoop.OCI_SECRET_API_KEY_ALIAS=<api_key_alias>
--conf spark.hadoop.BDS_OSS_CLIENT_REGION=<api_key_region>
Ejemplo 3: uso de parámetros clave de API de IAM Service.
spark-sql --conf spark.hadoop.BDS_OSS_CLIENT_AUTH_USERID=<api_key_user_id>
--conf spark.hadoop.BDS_OSS_CLIENT_AUTH_TENANTID=<api_key_tenant_id>
--conf spark.hadoop.BDS_OSS_CLIENT_AUTH_FINGERPRINT=<api_key_fingerprint>
--conf spark.hadoop.BDS_OSS_CLIENT_AUTH_PEMFILEPATH=<api_key_pem_file_path>>
--conf spark.hadoop.BDS_OSS_CLIENT_REGION=<api_key_region> --conf spark.hadoop.BDS_OSS_CLIENT_AUTH_PASSPHRASE=<api_key_passphrase>
Nota Si hay algún problema con el espacio de pila de Java, transfiera el controlador y la memoria del ejecutor como parte de Spark SQL. Por ejemplo,
--driver-memory 2g –executor-memory 4g. Ejemplo de sentencia spark-sql:
spark-sql --conf spark.driver.extraJavaOptions="${HADOOP_OPTS}"
--conf spark.executor.extraJavaOptions="${HADOOP_OPTS}"
--driver-memory 2g --executor-memory 4g
-
Verifique la conectividad de Object Storage:
Ejemplo para tabla gestionada:
CREATE DATABASE IF NOT EXISTS <database_name> LOCATION 'oci://<bucket-name>@<namespace>/';
USE <database_name>;
CREATE TABLE IF NOT EXISTS <table_name> (id int, name string) partitioned by (part int, part2 int) STORED AS parquet;
INSERT INTO <table_name> partition(part=1, part2=1) values (333, 'Object Storage Testing with Spark SQL Managed Table');
SELECT * from <table_name>;
Ejemplo para tabla externa:
CREATE DATABASE IF NOT EXISTS <database_name> LOCATION 'oci://<bucket-name>@<namespace>/';
USE <database_name>;
CREATE EXTERNAL TABLE IF NOT EXISTS <table_name> (id int, name string) partitioned by (part int, part2 int) STORED AS parquet LOCATION 'oci://<bucket-name>@<namespace>/';
INSERT INTO <table_name> partition(part=1, part2=1) values (999, 'Object Storage Testing with Spark SQL External Table');
SELECT * from <table_name>;
- (Opcional) Utilice
pyspark con spark-submit con Object Storage.
Nota
Cree la base de datos y la tabla antes de realizar estos pasos.
-
Ejecute lo siguiente:
from pyspark.sql import SparkSession
import datetime
import random
import string
spark=SparkSession.builder.appName("object-storage-testing-spark-submit").config("spark.hadoop.OCI_SECRET_API_KEY_PASSPHRASE","<jceks-provider>").config("spark.hadoop.OCI_SECRET_API_KEY_ALIAS",
"<api_key_alias>").enableHiveSupport().getOrCreate()
execution_time = datetime.datetime.now().strftime("%m/%d/%Y, %H:%M:%S")
param1 = 12345
param2 = ''.join(random.choices(string.ascii_uppercase + string.digits, k = 8))
ins_query = "INSERT INTO <database_name>.<table_name> partition(part=1, part2=1) values ({},'{}')".format(param1,param2)
print("##################### Starting execution ##################" + execution_time)
print("query = " + ins_query)
spark.sql(ins_query).show()
spark.sql("select * from <database_name>.<table_name>").show()
print("##################### Execution finished #################")
-
Ejecute el siguiente comando desde
/usr/lib/spark/bin:
./spark-submit --conf spark.driver.extraJavaOptions="${HADOOP_OPTS}" --conf spark.executor.extraJavaOptions="${HADOOP_OPTS}" <location_of_python_file>