Ejecución de una aplicación con el editor de código
En la consola, puede utilizar el editor de códigos para ejecutar una aplicación de Data Flow.
Debe haber creado
configpara la autenticación de usuario, como se describe en Uso del editor de códigos.-
Seleccione el logotipo de Oracle O.
Se muestra una lista de plugins disponibles.
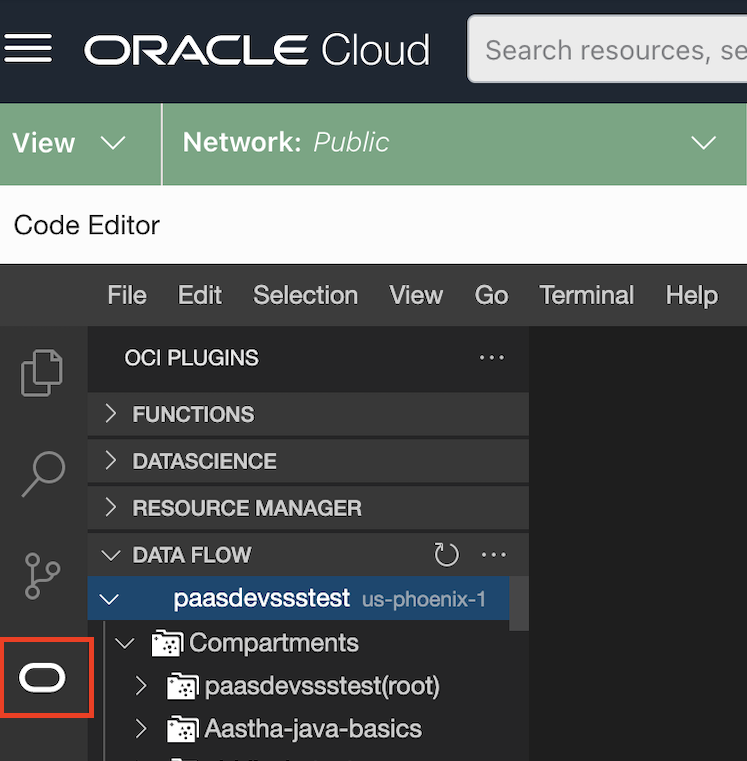
-
Haga clic con el botón derecho en el proyecto que desea ejecutar y seleccione Ejecutar localmente.
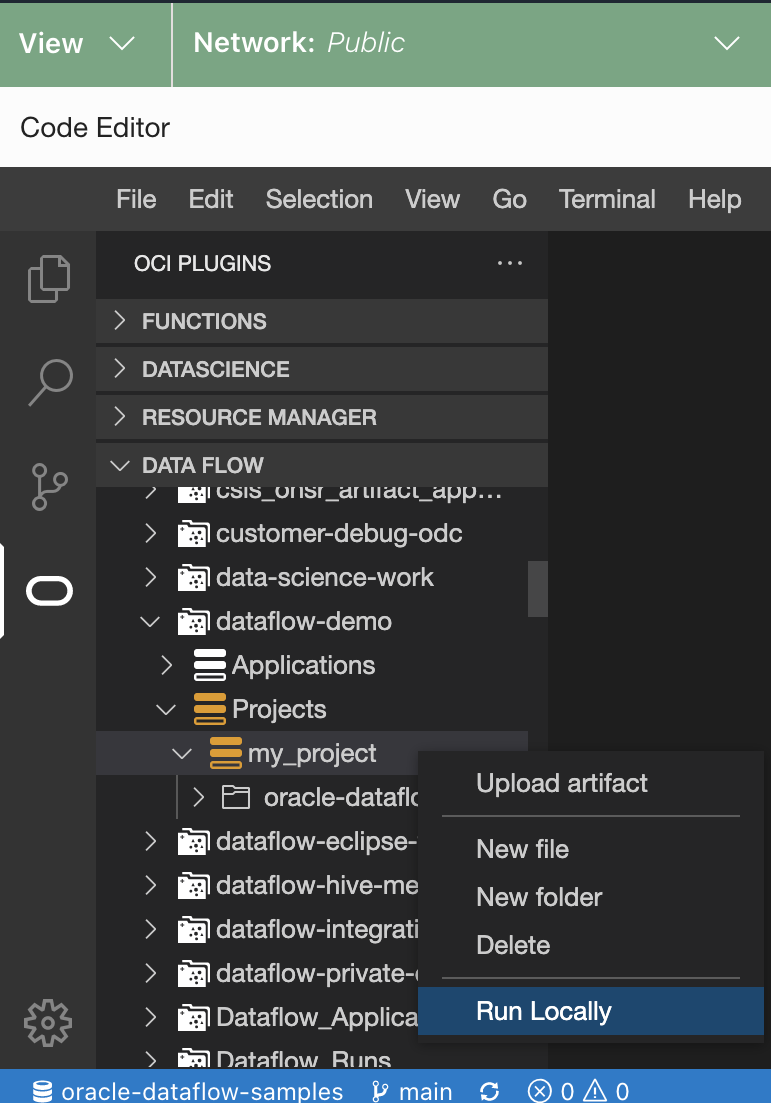 Se abre la ventana Ejecutar aplicación.
Se abre la ventana Ejecutar aplicación. -
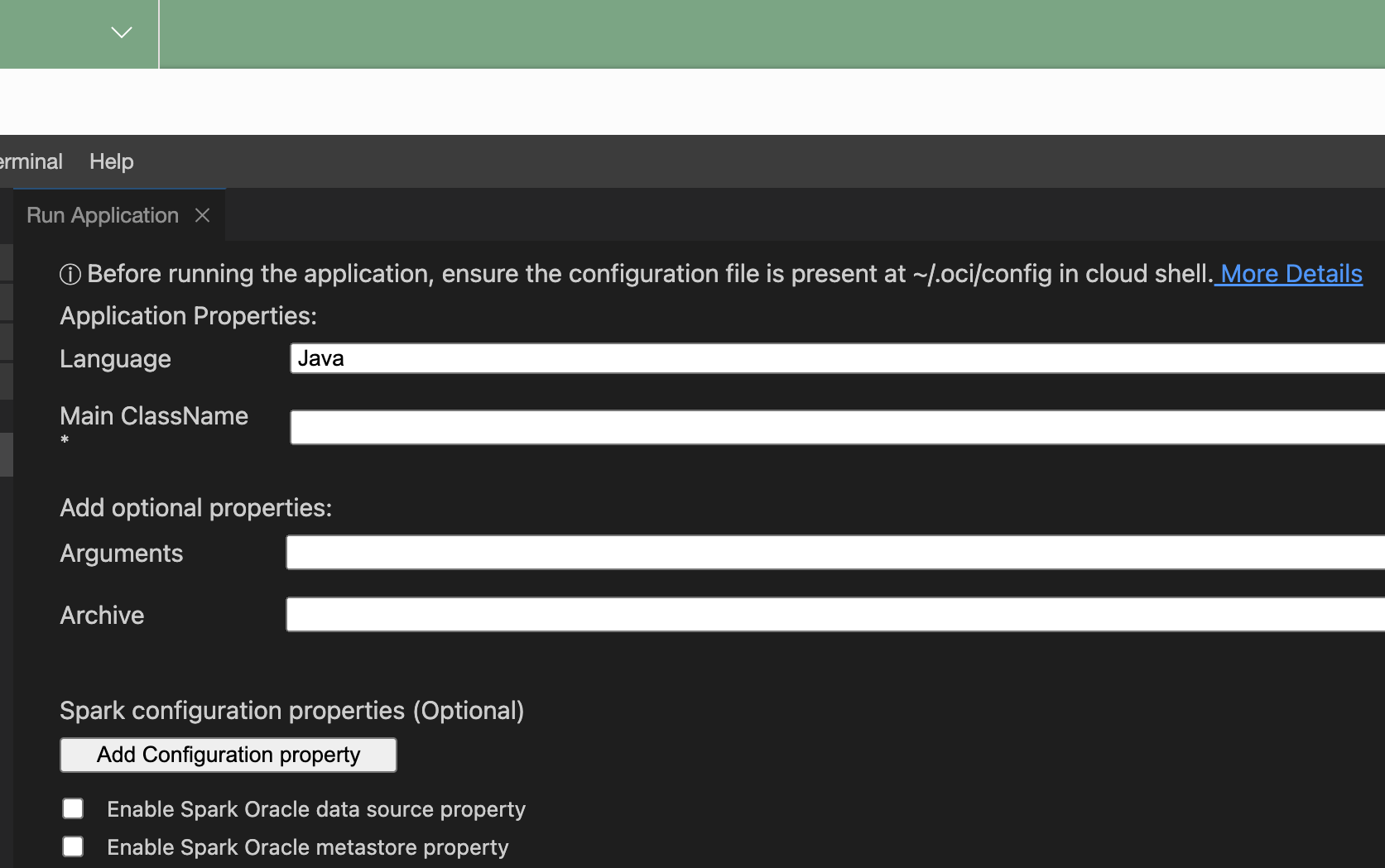
Proporcione las siguientes propiedades de aplicación:
- Idioma: uno de Java, Python o Scala.
- Principal ClassName: nombre de clase principal ejecutado en el proyecto. Para Python, es Nombre de archivo principal.
- Argumentos: argumentos de línea de comandos esperados por la aplicación Spark.
- conf: cualquier configuración adicional para que se ejecute la aplicación.
- jars: archivo JAR de terceros que necesita la aplicación.
- Compruebe Activar propiedad de origen de datos de Oracle de Spark para utilizar el origen de datos de Oracle de Spark.
- Compruebe Activar propiedad de metastore de Oracle de Spark para utilizar un metastore.
- Seleccione un compartimento.
- Seleccione un Metasore.

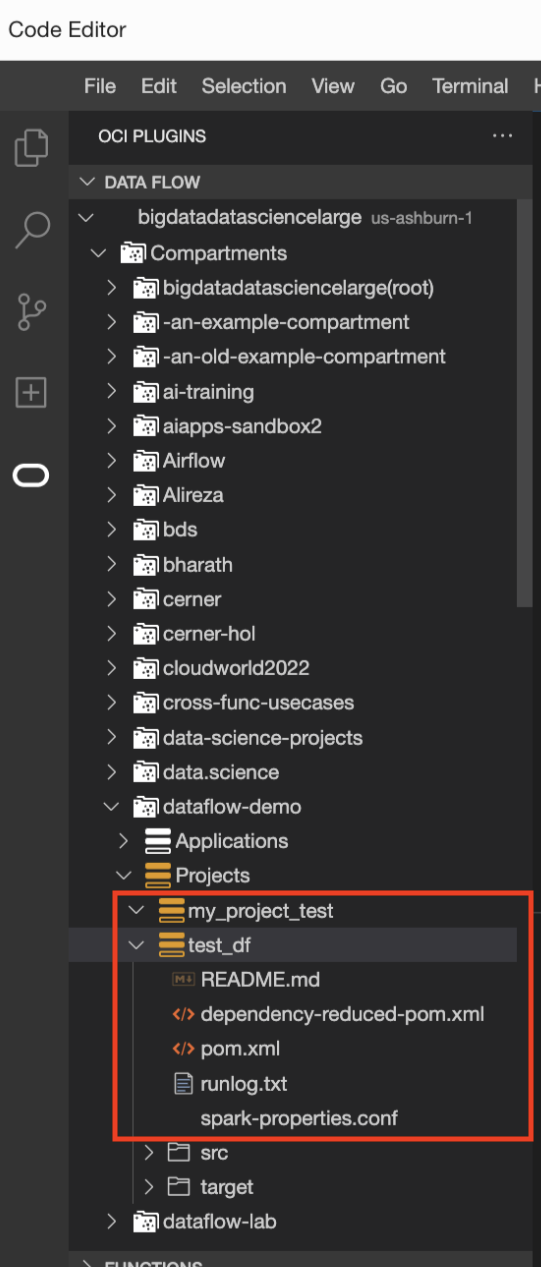
- (Opcional) Compruebe el estado de la aplicación desde la bandeja de notificaciones. Al seleccionar la bandeja Notificaciones, se proporciona información de estado más detallada.

- (Opcional) Seleccione runlog.txt para comprobar los archivos log.
- (Opcional) Cargue el artefacto en Data Flow.
- Haga clic con el botón derecho en el proyecto en cuestión.
- Seleccione Cargar artefacto.
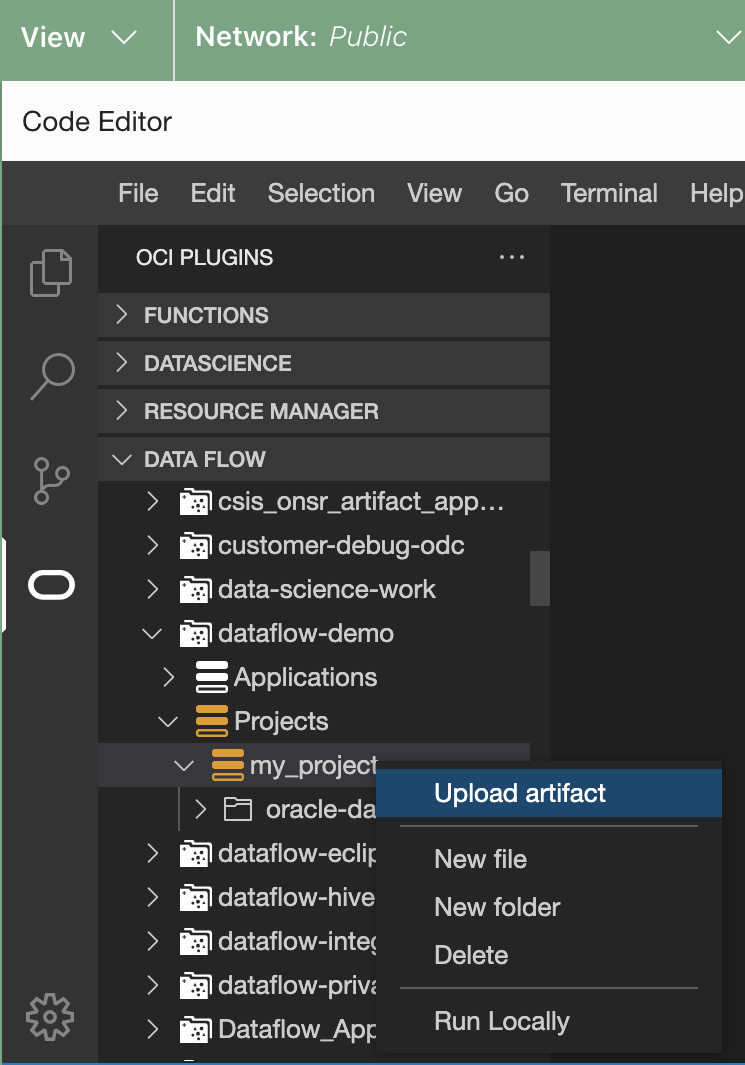
- Seleccione el idioma.
- Introduzca el espacio de nombres de Object Storage.
- Introduzca el nombre del cubo.
-
Seleccione el logotipo de Oracle O.
Esta tarea no se puede realizar mediante la CLI.
Esta tarea no se puede realizar con la API.