Visión general de Data Flow
Obtenga más información sobre Data Flow y cómo puede utilizarlo para crear, compartir, ejecutar y ver fácilmente la salida de las aplicaciones de Apache Spark .
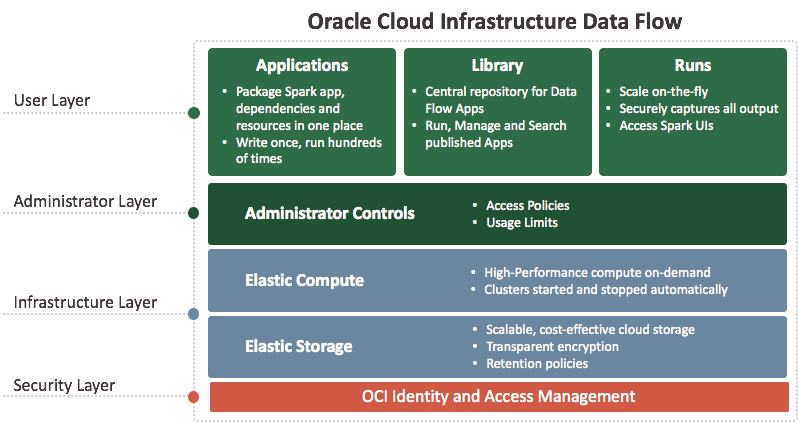
Definición de Oracle Cloud Infrastructure Data Flow
Data Flow es una plataforma sin servidor basada en la nube con una interfaz de usuario enriquecida. Permite a los desarrolladores y a los científicos de datos de Spark crear, editar y ejecutar trabajos de Spark a escala sin necesidad de disponer de clusters, de un equipo de operaciones o de conocimientos de Spark altamente especializados. No tener servidor significa que no hay ninguna infraestructura que desplegar o gestionar. La controlan completamente las API de REST, lo que permite una integración sencilla con aplicaciones o flujos de trabajo. Puede controlar Data Flow mediante esta API de REST. Puede ejecutar Data Flow desde la CLI, ya que los comandos de Data Flow están disponibles como parte de la interfaz de línea de comandos de Oracle Cloud Infrastructure. Puede:
-
Conecte a orígenes de datos de Apache Spark.
-
Cree aplicaciones Apache Spark reutilizables.
-
Inicie trabajos de Apache Spark rápidamente.
-
Cree aplicaciones Apache Spark mediante SQL, Python, Java, Scala o spark-submit.
-
Gestione todas las aplicaciones Apache Spark desde una sola plataforma.
-
Procese los datos en la nube o en la ubicación local en su centro de datos.
-
Cree bloques de creación de big data que pueda ensamblar fácilmente en aplicaciones de big data avanzadas.
