Configuración de Data Flow
Para poder crear, gestionar y ejecutar aplicaciones en Data Flow, el administrador de inquilino (o cualquier usuario con privilegios elevados para crear cubos y cambiar políticas en IAM) debe crear grupos, un compartimento, almacenamiento y políticas asociadas en IAM.
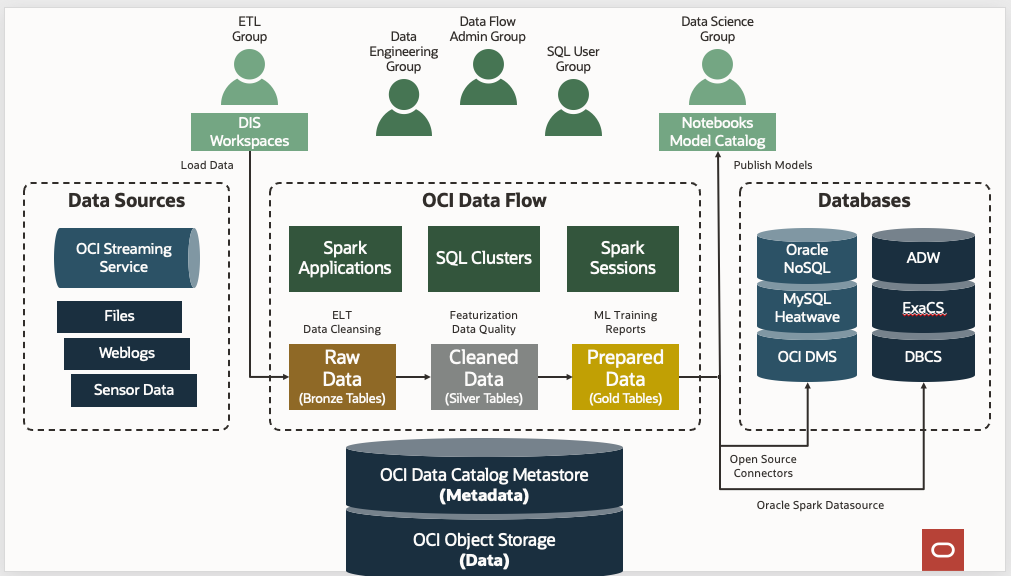 Estos son los pasos necesarios para configurar Data Flow:
Estos son los pasos necesarios para configurar Data Flow:- Definición de grupos de identidad.
- Configuración de cubos de compartimento y almacenamiento de objetos.
- Configuración de políticas de Identity and Access Management
Configurar grupos de identidades
Como práctica general, categorice los usuarios de Data Flow en tres grupos para separar claramente sus casos de uso y nivel de privilegios.
Cree los tres grupos siguientes en el servicio de identidad y agregue usuarios a cada grupo:
- administradores de flujo de datos
- Ingenieros de datos de flujo de datos
- dataflow-sql-users
- administradores de flujo de datos
- Los usuarios de este grupo son administradores o superusuarios de Data Flow. Tienen privilegios para realizar cualquier acción en Data Flow o para configurar y gestionar diferentes recursos relacionados con Data Flow. Gestionan aplicaciones que son propiedad de otros usuarios y ejecuciones iniciadas por cualquier usuario de su arrendamiento. Los administradores de flujos de datos no necesitan acceso de administración a los clusters de Spark aprovisionados bajo demanda por Data Flow, ya que estos clusters están totalmente gestionados por Data Flow.
- Ingenieros de datos de flujo de datos
- Los usuarios de este grupo tienen privilegios para gestionar y ejecutar aplicaciones y ejecuciones de Data Flow para sus trabajos de ingeniería de datos. Por ejemplo, ejecutando trabajos de carga de transformación de extracción (ETL) en clusters de Spark sin servidor bajo demanda de Data Flow. Los usuarios de este grupo no tienen ni necesitan acceso de administración a los clusters de Spark aprovisionados bajo demanda por Data Flow, ya que estos clusters están totalmente gestionados por Data Flow.
- dataflow-sql-users
- Los usuarios de este grupo tienen privilegios para ejecutar consultas SQL interactivas conectándose a clusters SQL interactivos de Data Flow a través de JDBC o ODBC.
Configuración de cubos de compartimento y almacenamiento de objetos
Siga estos pasos para crear un compartimento y cubos de Object Storage para Data Flow.