Visión General de Streaming con Apache Kafka
Oracle Cloud Infrastructure (OCI) Streaming con Apache Kafka es un servicio de OCI totalmente gestionado que permite crear y ejecutar clusters de Kafka en un arrendamiento de OCI con todas las funcionalidades de Apache Kafka.
Apache Kafka es una plataforma de transmisión de eventos de código abierto que se utiliza para crear aplicaciones de transmisión de datos en tiempo real. Con Apache Kafka, puede:
- Escribir y leer flujos de eventos
- Almacena flujos de eventos
- Procesar flujos de eventos en tiempo real o posteriormente
Con Streaming con Apache Kafka, obtiene todas las funcionalidades de Apache Kafka sin la sobrecarga que supone aprovisionar y gestionar la infraestructura subyacente.

Funciones
Streaming con Apache Kafka se ha creado con las siguientes funciones:
- Totalmente gestionado
- La transmisión con Apache Kafka está totalmente gestionada y automatiza actividades como la aplicación de parches, las actualizaciones, las copias de seguridad, la alta disponibilidad, la replicación entre regiones, la ampliación y la gestión del rendimiento.
- Durabilidad y disponible
- Cada cluster se configura con redundancia de almacenamiento y alta disponibilidad en los dominios de disponibilidad o los dominios de errores. Puede crear un cluster con un solo broker para los arrendamientos de desarrollo o prueba, o bien crear un cluster con al menos 3 brokers para los arrendamientos de producción para proporcionar alta disponibilidad.
- Compatibilidad de Apache Kafka
- La transmisión con Apache Kafka es 100% compatible con las API de Apache Kafka, lo que le permite utilizar aplicaciones escritas para Apache Kafka sin volver a escribir el código.
- Servicios integrados de OCI
-
- Utilizar OCI Vault para almacenar y gestionar de forma segura las credenciales de superusuario
- Uso de OCI Monitoring para métricas de cluster
- Uso de OCI Logging para logs de nivel de cluster
Caso de uso
Utilice Streaming con Apache Kafka en los siguientes escenarios:
- Captura de Datos de Cambio
- La captura de datos de cambio (CDC) es un estilo de diseño de aplicación en el que los cambios en el estado de la aplicación se registran como una secuencia de registros ordenada por tiempo. OCI Streaming con el soporte de Apache Kafka para el almacenamiento de datos de log a escala de la nube lo convierte en un excelente backend para una aplicación creada en este estilo. Puede desplegar cualquier conector de Kafka de código abierto, o Oracle Golden Gate, en una máquina virtual (VM), que sondea las bases de datos de origen en busca de datos nuevos o modificados en función de una columna de registro de hora de actualización y transmite fácilmente los datos a OCI Streaming con Apache Kafka. Por ejemplo, las empresas de comercio electrónico utilizan CDC con Kafka para realizar un seguimiento de las actualizaciones de pedidos en su base de datos para iniciar el procesamiento de pedidos y otros micro servicios de cumplimiento de pedidos.
-
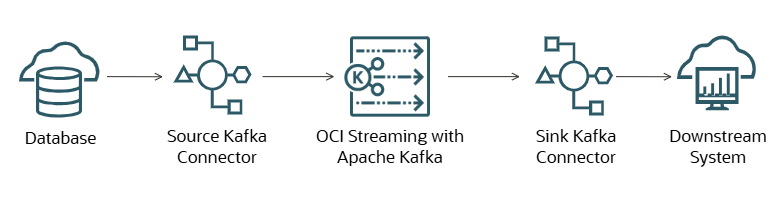
- Ingesta de métricas y registros
- Utiliza OCI Streaming con Apache Kafka como las métricas o el procesador de logs de diversos orígenes. Las herramientas de ingestión de logs, como Fluentd, Logstash o la API de productores de Kafka, pueden recopilar logs de diversas aplicaciones y colocarlos en temas de Kafka para el enriquecimiento y la agregación de datos. Con las API de Apache Kafka, puede enriquecer los datos abstrayendo los detalles de los logs y enviándolos a herramientas de análisis descendentes para seguir procesando y avanzar en las capacidades de búsqueda de logs.
-

- Análisis en tiempo Real
- Utiliza OCI Streaming con Apache Kafka para procesar y analizar flujos continuos de datos de dispositivos IOT u otras aplicaciones ascendentes para obtener información en tiempo real, detección de anomalías y análisis predictivos. Por ejemplo, las instituciones financieras utilizan el servicio para procesar fuentes de datos de mercado, detectar anomalías comerciales y tomar decisiones comerciales en tiempo real. Los minoristas analizan el comportamiento y las preferencias de los clientes en tiempo real para ofrecer recomendaciones y promociones personalizadas.
-

- Ingestión de datos de actividad web y móvil
- Utilice OCI Streaming con Apache Kafka para volver a crear un pipeline de seguimiento de actividad de usuario como un juego de fuentes de publicación-suscripción en tiempo real. Estas fuentes están disponibles para suscripción para una amplia gama de casos de uso, incluidos el procesamiento en tiempo real, la supervisión en tiempo real y la carga en Hadoop o en sistemas de almacenamiento de datos fuera de línea para el procesamiento y la generación de informes fuera de línea. Puede utilizar esta solución para los siguientes usos:
- Clickstream: Los casos de uso de Clickstream implican recopilar datos de la actividad del sitio web de múltiples productores y analizar los datos en tiempo real para proporcionar recomendaciones, como productos para comprar, artículos de noticias para leer y videos para ver.
- Análisis de juegos: las empresas de juegos monitorean constantemente el retraso de la red, el comportamiento del usuario y las actividades dentro del juego para ofrecer a los clientes microtransacciones dentro del juego, para reequilibrar la carga de la red, cambiar los parámetros del motor de renderizado y más. Todas estas acciones ocurren en tiempo real, en el orden de milisegundos a unos pocos segundos.
-

- Mensajes
- Utilice OCI Streaming con Apache Kafka para separar los componentes de sistemas grandes. Por ejemplo, los productores y consumidores pueden utilizar OCI Streaming con Apache Kafka como un autobús de mensajes asíncrono y actuar de forma independiente y a su propio ritmo.
-

Cuándo utilizar OCI Streaming con Apache Kafka frente a OCI Streaming
Revisa los detalles de OCI Streaming con Apache Kafka y OCI Streaming para encontrar la mejor solución para tus necesidades de Streaming.
| OCI Streaming | OCI Streams con Apache Kafka |
|---|---|
| Recomendado como bus de mensajería para comunicación de aplicación a aplicación. Ideal para cargas de trabajo pequeñas y medianas con menos de 500 particiones por región y arrendamiento. | Recomendado para el almacenamiento de datos distribuidos y el procesamiento de datos en tiempo real, incluidos CDC, análisis de flujos y procesamiento de datos IOT, sin límites en el número de particiones. |
| Gestionado y sin servidor | Gestionado, pero no sin servidor |
| Compatibilidad parcial con Apache Kafka | 100% compatible con Apache Kafka |
| Latencia de rendimiento ~ 200 ms de media, cuando el cluster se ajusta correctamente. | Latencia de rendimiento inferior a 100 ms cuando el cluster se ajusta correctamente. |
| Multi-inquilino: un único cluster contiene varios arrendamientos de clientes. | Un único inquilino: cada cluster está dedicado a un único arrendamiento. |
| Autenticación y autorización mediante IAM. | Autenticación mediante mTLS o SASL/SCRAM y autorización mediante ACL. |
| Límite flexible 15 y límite estricto 500 en particiones | Sin límite |
| Retención de almacenamiento 7 días | Sin límite |
| Sin límite de tamaño de almacenamiento | Límite de tamaño de almacenamiento de 16 TB por agente |
| Rendimiento de escritura por partición de 1 MB por segundo y rendimiento de lectura por partición de 2 MB por segundo. | Rendimiento: 10 MB por segundo. El rendimiento por defecto por partición en Apache Kafka no es un límite fijo ni fijo, sino una combinación de factores. Se estima que es de alrededor de 10 MB por segundo por partición. El rendimiento máximo por partición depende de la infraestructura y las configuraciones subyacentes, como el tamaño de lote, el códec de compresión, el factor de replicación y el tipo de reconocimiento. |
| Tamaño máximo del mensaje 1 MB | El tamaño máximo de mensaje por defecto se define en 1 MB para ayudar a los agentes a gestionar la memoria de forma eficaz. Esto se puede cambiar en la configuración del cluster. No hay límite de tamaño máximo, pero los mensajes muy grandes no se recomiendan y se consideran ineficaces y antipatrones en Apache Kafka. |
| Escala no soportada | Amplíe el número de agentes de hasta treinta (30) agentes por cluster y amplíe el número de OCPU hasta el máximo definido por las unidades de computación. |
| 50 grupos de consumidores por tema | No hay límite, pero cuanto más grupos de consumidores, más uso de red. |
| Funcionalidades compactadas: tema, producción idempotente, transacción y API de flujo no disponibles. | Funcionalidades compaccionadas tema, producción idempotente, transacción, flujo API soportado. |
| Métricas de baja cardinalidad limitadas disponibles | Amplias métricas de alta cardinalidad disponibles |
Identificadores de recursos
Streaming con Apache Kafka soporta clusters y solicitudes de trabajo como recursos de Oracle Cloud Infrastructure. La mayoría de los tipos de recursos tienen un identificador único asignado por Oracle denominado ID de Oracle Cloud (OCID). Para obtener información sobre el formato del OCID y otras formas de identificar los recursos, consulte Identificadores de recursos.
Regiones y dominios de disponibilidad
Oracle aloja sus servicios de OCI en regiones y dominios de disponibilidad. Una región es un área geográfica localizada, mientras que un Dominio de Disponibilidad es uno o más centros a los que se accede en una región. La transmisión con Apache Kafka se aloja en todas las regiones del dominio OC1.
Autenticación y autorización
Cada servicio de Oracle Cloud Infrastructure se integra con IAM con fines de autenticación y autorización para todas las interfaces (la consola, el SDK o la CLI, y la API de REST).
Un administrador de la organización debe definir grupos, compartimentos y políticas que controlen qué usuarios pueden acceder a qué servicios, qué recursos y el tipo de acceso. Por ejemplo, las políticas controlan quién puede crear usuarios nuevos, crear y gestionar la red en la nube, crear instancias, crear cubos, descargar objetos, etc. Para obtener más información, lea Introducción a las políticas.
Formas de acceder a Streaming con Apache Kafka
Puede acceder a Oracle Cloud Infrastructure (OCI) utilizando la consola (una interfaz basada en explorador), la API de REST o la CLI deOCI. En los temas de esta documentación, se incluyen instrucciones para utilizar la consola, la API y CLI. Para obtener una lista de los SDK disponibles, consulte Software development kits e interfaz de línea de comandos.
Consola: para acceder a Streaming con Apache Kafka mediante la consola, debe utilizar un explorador soportado. Para ir a la página del inicio de sesión de la consola, abra el menú de navegación en la parte superior de esta página y seleccione Consola de Infraestructura. Se le solicitará que introduzca el inquilino en la nube, el nombre de usuario y la contraseña.
API: para acceder a Streaming con Apache Kafka a través de API, la documentación de la API de REST proporciona la mayor funcionalidad, pero requiere experiencia en programación. Referencia de la API y puntos finales proporciona información detallada sobre los puntos final y los enlaces a la API disponible, incluida la API de Streaming with Apache Kafka API. La transmisión con la API de Apache Kafka le permite crear y gestionar los clusters de Kafka y los archivos de configuración. Utilice las API de Apache Kafka para las operaciones de cliente.
CLI: la CLI de OCI le permite crear y gestionar los clusters de Kafka y los archivos de configuración. Utilice las CLI de Apache Kafka para operaciones de cliente. Utilice el entorno de Cloud Shell para ejecutar las CLI.