Uso de la Búsqueda con Plugins de Alertas y Notificaciones OpenSearch
Utilice los plugins de alerta y notificación integrados de OpenSearch para supervisar el estado del cluster, las métricas de rendimiento y los problemas operativos.
Ajustar y optimizar correctamente los clusters OpenSearch es fundamental para el rendimiento y la rentabilidad. Con el tiempo, los patrones de uso del cluster pueden cambiar, lo que lleva a una sobrecarga, un aumento de latencias o errores. La supervisión y las alertas proactivas son esenciales para detectar y mitigar posibles problemas antes de que se intensifiquen.
OpenSearch tiene un plugin de supervisión y alertas incorporado que puede ayudar a crear dichas alertas. En este tema, se proporciona orientación sobre la configuración de alertas, la integración con el servicio Oracle Notification (ONS) y la mitigación de problemas comunes.
OpenSearch Plugin de alertas
El plugin de alertas proporciona supervisión y notificación de eventos en OpenSearch. Utiliza API de REST para crear alertas complejas basadas en métricas de cluster y nodo. El plugin de alertas contiene las siguientes funciones:
- Supervisiones de canales: combina varias condiciones de diferentes salidas de API de REST para crear alertas complejas.
- Intervalos controlados: define la frecuencia con la que se evalúan las alertas para evitar la fatiga de las notificaciones.
- Soporte de RBAC: utiliza el control de acceso basado en roles para gestionar alertas.
Para obtener más información sobre la supervisión de OpenSearch, consulte Supervisión.
Métricas y Alertas Soportadas
Puede configurar el plugin de alertas para las siguientes métricas:
- Estado del cluster: cambios de estado (verde, amarillo, rojo).
- Métricas de nodo: alto uso de disco, CPU y presión de JVM.
- Métricas de partición horizontal: particiones horizontales grandes, recuentos excesivos de particiones horizontales.
- Métricas de tarea: tareas bloqueadas o rechazadas, recuentos altos de tareas de desplazamiento.
- Limitación: limitación de índice o consulta.
Configuración de alertas
Puede configurar alertas en las salidas de las siguientes API OpenSearch:
- _cluster/estado
- _cluster/estadísticas
- _cluster/configuración
- _nodos/estadísticas
- _cat/índices
- _cat/pending_tasks
- _cat/recuperación
- _cat/shards
- _cat/snapshots
- _cat/tareas
Para obtener más información, consulte Supervisiones de métricas por cluster.
Plugin de notificación OpenSearch
Utilice el plugin de notificaciones para obtener notificaciones automáticas sobre las alertas configuradas mediante el plugin de alertas. El servicio de notificación de Oracle (ONS) está integrado con el plugin de notificación. Puede crear canales mediante el plugin de notificación que envía notificaciones al tema de ONS configurado. A continuación, puede enlazar estos canales a alertas para recibir notificaciones sobre la activación de alertas.
A continuación se muestra un ejemplo de una notificación de alerta:
Monitor Test index stats just entered alert status. Please investigate the issue.
- Trigger: test
- Severity: 2
- Period start: 2025-02-06-06T08:48:45.047Z
- Period end: 2025-02-06-06T08:49:45.047ZPara obtener más información sobre el plugin de notificaciones OpenSearch, consulte Notificaciones.
Servicio de notificaciones de Oracle (ONS)
El servicio Oracle Cloud Infrastructure Notifications (ONS) difunde mensajes seguros y altamente fiables a componentes distribuidos a través de un patrón de publicación-suscripción. Puede utilizarlo para aplicaciones alojadas en Oracle Cloud Infrastructure y de forma externa. Utilice ONS para recibir notificaciones cuando se disparen reglas o alarmas de eventos, o para publicar directamente un mensaje.
ONS soporta los siguientes canales para la entrega de mensajes:
- Correo electrónico
- Funciones
- Punto final HTTP (para aplicaciones externas)
- PagerDuty
- Slack
- SMS
Para obtener más información sobre el servicio OCI Notification, consulte Notifications.
En la siguiente imagen se muestra cómo se emiten las notificaciones mediante ONS:
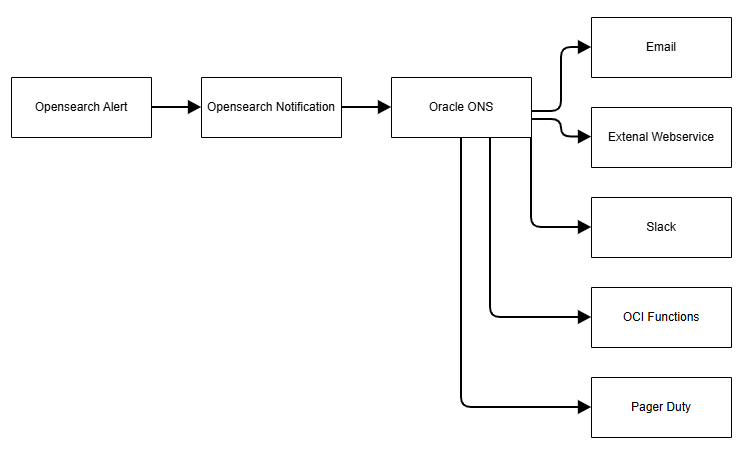
Alertas de Ejemplo con Notificaciones
Puede crear alertas para supervisar la mayoría de las áreas importantes de OpenSearch que pueden afectar al rendimiento del cluster OpenSearch. Las mejores prácticas consisten en configurar alertas de nivel de advertencia que indiquen que algunos parámetros se vuelven problemáticos, de modo que se puedan realizar acciones correctivas antes de que el cluster OpenSearch pase a un estado incorrecto.
En las siguientes secciones, se proporcionan alertas de nivel de advertencia y error que se pueden configurar en el cluster OpenSearch.
Canal de Notificación
Antes de crear alertas, le recomendamos que configure un canal de notificación. Puede utilizar su suscripción al canal de ONS para obtener notificaciones automáticas a través de varios métodos de comunicación, incluidos correo electrónico, Slack, funciones de OCI, flujos y otros.
El siguiente ejemplo muestra cómo crear un canal de notificación:
{
"config_id": "sample-id",
"name": "test-ons1",
"config": {
"name": "test-ons1",
"description": "send notifications",
"config_type": "ons",
"is_enabled": true,
"ons": {
"topic_id": "ocid1.onstopic.oc1.iad.amaaaaaawtpq47yar24xitgso2wble2a5shal52r6zoc6eyth3jzsmbvxspa"
}
}
}Cluster Estado
Su cluster OpenSearch tiene los siguientes estados:
- Verde: todas las particiones horizontales disponibles.
- Amarillo: algunas particiones horizontales de réplica no están disponibles. El rendimiento puede verse afectado debido a que hay menos réplicas disponibles.
- Rojo: algunas particiones horizontales principales no están disponibles. El rojo indica que los datos no están disponibles, lo que provoca un fallo en las consultas a las particiones horizontales no disponibles.
Configuración de alertas de cluster amarillo
Utilice la siguiente configuración para configurar alertas amarillas para el cluster:
POST: {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "ClusterHealthYellow",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "CLUSTER_HEALTH",
"path": "_cluster/health",
"path_params": "",
"url": "http://localhost:9200/_cluster/health",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "xElVw5YBqFMdxmRChxIO",
"name": "Check cluster health",
"severity": "1",
"condition": {
"script": {
"source": "ctx.results[0].status == \"yellow\"",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
],
"delete_query_index_in_every_run": false,
"owner": "alerting"
}Configuración de alertas de cluster amarillo
Utilice la siguiente configuración para configurar alertas rojas para el cluster:
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "ClusterHealthRed",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "CLUSTER_HEALTH",
"path": "_cluster/health",
"path_params": "",
"url": "http://localhost:9200/_cluster/health",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "xElVw5YBqFMdxmRChxIO",
"name": "Check cluster health",
"severity": "1",
"condition": {
"script": {
"source": "ctx.results[0].status == \"red\"",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
],
"delete_query_index_in_every_run": false,
"owner": "alerting"
}Número de nodos
Utilice la siguiente configuración para especificar el número de nodos del cluster:
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "ClusterNodesUnavailable",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "CLUSTER_HEALTH",
"path": "_cluster/health",
"path_params": "",
"url": "http://localhost:9200/_cluster/health",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "xElVw5YBqFMdxmRChxIO",
"name": "Check all nodes available",
"severity": "1",
"condition": {
"script": {
"source": "ctx.results[0].number_of_nodes< 8",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
],
"delete_query_index_in_every_run": false,
"owner": "alerting"
}Solución de incidencias
El estado del cluster puede convertirse en amarillo o rojo debido a varios motivos, como un fallo en la restauración, la desconexión temporal de los nodos y el llenado del disco. Aunque el equipo de OCI OpenSearch debe solucionar algunos problemas, puede solucionarlos y solucionarlos usted mismo.
Siga estos pasos para solucionar los problemas por sí mismo:
- Obtenga una lista de todas las particiones horizontales mediante la API de particiones horizontales de Cat para hacerse una idea de las particiones horizontales que no están asignadas.
- Si el cluster OpenSearch es rojo:
- Compruebe el motivo de asignación de las particiones horizontales no asignadas mediante la API de asignación de CAT.
- Utilice la API de reenrutamiento forzado para intentar la reasignación de particiones horizontales, si el problema era temporal y se mitiga.
- Si la explicación de asignación de particiones horizontales menciona un intento de restauración fallido, restaure el cluster a un estado correcto conocido anterior.
- Si el problema continúa, póngase en contacto con el equipo de OCI OpenSearch.
- Si el cluster OpenSearch es amarillo:
- Compruebe si el número de nodos es igual o mayor que el número máximo de réplicas para un índice.
- Compruebe el motivo de asignación de las particiones horizontales no asignadas mediante la API de asignación de CAT
- Si el problema parece ser temporal, utilice la API de desvío forzado para reasignar las particiones horizontales.
Si uno o más nodos del cluster no están disponibles durante un período prolongado, póngase en contacto con el equipo de OCI OpenSearch. Estos síntomas indican que algo podría estar mal con la infraestructura subyacente.
Estadísticas de nivel de nodo
Todos los nodos OpenSearch deben tener un buen buffer en términos de todas las métricas básicas, como CPU, RAM y espacio en disco, para que funcionen de manera óptima. Alcanzar los niveles críticos de estas métricas puede reducir las latencias, aumentar las demoras y, finalmente, provocar que los nodos se bloqueen o salgan del cluster.
Se pueden definir dos niveles de alertas en estas métricas: uno para un nivel de advertencia y otro para un nivel crítico.
Alto disco/CPU/JVM
Nivel de Advertencia
Utilice la siguiente configuración para especificar una alerta de nivel de advertencia para los nodos OpenSearch:
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"name": "DiskUsage",
"monitor_type": "cluster_metrics_monitor",
"enabled": false,
"enabled_time": null,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "NODES_STATS",
"path": "_nodes/stats",
"path_params": "",
"url": "http://localhost:9200/_nodes/stats"
}
}
],
"triggers": [
{
"query_level_trigger": {
"name": "test",
"severity": "2",
"condition": {
"script": {
"source": "for (entry in ctx.results[0].nodes.entrySet())\n\n{\n\n if ((entry.getValue().fs.total.total_in_bytes -entry.getValue().fs.total.free_in_bytes)*100/entry.getValue().fs.total.total_in_bytes > 70) {\n\n return true;\n\n}\n\n}\n\nreturn false;",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
]
}Nivel Crítico
Utilice la siguiente configuración para especificar una alerta de nivel crítico para los nodos OpenSearch:
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"name": "DiskUsage",
"monitor_type": "cluster_metrics_monitor",
"enabled": false,
"enabled_time": null,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "NODES_STATS",
"path": "_nodes/stats",
"path_params": "",
"url": "http://localhost:9200/_nodes/stats"
}
}
],
"triggers": [
{
"query_level_trigger": {
"name": "test",
"severity": "2",
"condition": {
"script": {
"source": "for (entry in ctx.results[0].nodes.entrySet())\n\n{\n\n if ((entry.getValue().fs.total.total_in_bytes -entry.getValue().fs.total.free_in_bytes)*100/entry.getValue().fs.total.total_in_bytes > 85) {\n\n return true;\n\n}\n\n}\n\nreturn false;",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
]
}Solución de problemas
Para un uso elevado del disco, intente aumentar el tamaño del disco o configurar políticas de ISM para depurar datos antiguos.
Revise las configuraciones de tráfico y nodo, si el cluster está bajo estrés debido a los parámetros de nodo durante mucho tiempo, normalmente indica un cluster poco configurado.
Tareas Pendientes
La lista de tareas pendientes especifica qué tareas OpenSearch se están realizando en qué nodos. La mayoría de las tareas OpenSearch, aparte de algunas como la operación de reindexación, son tareas pequeñas que OpenSearch dividió de los esfuerzos más grandes.
Utilice la siguiente configuración para mostrar las tareas pendientes para los nodos OpenSearch:
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "pending_tasks",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"enabled_time": 1746584774661,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "CAT_TASKS",
"path": "_cat/tasks",
"path_params": "",
"url": "http://localhost:9200/_cat/tasks",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "jUOQqJYBQxJTy-1pqNIF",
"name": "test",
"severity": "1",
"condition": {
"script": {
"source": "for (item in ctx.results[0].tasks){\n\nif(item.running_time_in_nanos> 300000000000) return true;\n}\nreturn false\n",
"lang": "painless"
}
},
"actions": [{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}]
}
}
],
"delete_query_index_in_every_run": false
}Solución de problemas
Las tareas pendientes pueden indicar una sobrecarga en el nodo, un estado incorrecto del nodo o parámetros incorrectos para la tarea. Utilice la siguiente guía para solucionar problemas relacionados con nodos pendientes:
- Si el cluster está ejecutando fusiones de varios tipos o índices masivos, realice una fusión forzada para resolver el problema, ya que fusiona todo en una sola acción.
- Si el cluster experimenta que la configuración de actualización del cluster se bloquea, podría indicar un problema con el estado del nodo o las colas del nodo. Intente suprimir las tareas paradas o reiniciar el nodo para solucionar el problema.
- Si el cluster experimenta que las instantáneas de tipo se atasquen, podría indicar un problema con el repositorio. Compruebe la configuración del repositorio. Póngase en contacto con el equipo de OCI OpenSearch si el error está relacionado con copias de seguridad automatizadas.
Tareas y threads rechazados
Los threads rechazados indican un alto nivel de limitación entre tareas. Por ejemplo, podría ser cuando hay tanta actividad, muchas solicitudes de índice y búsqueda que no se pueden servir se limitan en su lugar.
Utilice la siguiente configuración para mostrar las tareas y los threads rechazados:
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "Rejected threads",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "NODES_STATS",
"path": "_nodes/stats",
"path_params": "",
"url": "http://localhost:9200/_nodes/stats",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "1kNRrpYBQxJTy-1pGtJ9",
"name": "rejected thread pool",
"severity": "1",
"condition": {
"script": {
"source": "for (entry in ctx.results[0].nodes.entrySet())\n{\n for (e in entry.getValue().thread_pool.entrySet()) {\n if(e.getValue().rejected>10){\n return true;\n}\n\n}\n\n}\n\nreturn false;",
"lang": "painless"
}
},
"actions": [{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}]
}
}
],
"delete_query_index_in_every_run": false,
"owner": "alerting"
}Solución de problemas
Las tareas rechazadas pueden indicar una sobrecarga en el sistema. Revise el tipo de tareas rechazadas. Compruebe si el tráfico de estas tareas se puede reducir o si la configuración/estructura de la tarea ha cambiado.
Si la función de búsqueda se está limitando, compruebe si se puede optimizar la consulta de búsqueda.
Si la función de indexación se está limitando, compruebe si puede actualizar la velocidad de indexación o la configuración en bloque, o si puede dividir el índice y las particiones horizontales en tareas más pequeñas.
Estadísticas de nivel de índice
Tamaño de partición horizontal
Los datos de índice se almacenan en estructuras independientes, conocidas como particiones horizontales. Cada partición horizontal está formada por segmentos, que se cargan en la memoria OpenSearch para ayudar a la función de búsqueda. Las particiones horizontales en el rango de 30-50 GB o más grandes conducen a segmentos más grandes, lo que conduce a un mayor uso de memoria. El tamaño correcto de las particiones horizontales es importante para el rendimiento del cluster. Los tamaños de partición horizontal normalmente se pueden controlar mediante políticas de gestión del ciclo de vida de índices (ILM). Para los índices que no tienen ILM, puede configurar alertas en tamaños de partición horizontal para evitar que los índices se vuelvan demasiado grandes.
Utilice la siguiente configuración para mostrar las particiones horizontales y sus tamaños:
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "Big shard size",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "CAT_SHARDS",
"path": "_cat/shards",
"path_params": "",
"url": "http://localhost:9200/_cat/shards",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "pkOWqJYBQxJTy-1pO9Im",
"name": "big shards",
"severity": "1",
"condition": {
"script": {
"source": "for (item in ctx.results[0].shards)\nif((item.store != null)&&(item.store.contains(\"gb\"))&&(item.store.length()>4)\n&&(Double.parseDouble(item.store.substring(0,item.store.length()-3))>30)) return true\n",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
],
"delete_query_index_in_every_run": false
}Solución de problemas
Configure la política de ILM del cluster para renovar los índices cuando alcancen un tamaño determinado.
Aumente el número de particiones horizontales para los índices existentes que han crecido mediante la función de reindexación. Para índices grandes de más de 100 GB, siga estas mejores prácticas:
- Divida la tarea en partes más pequeñas mediante la API de consulta.
- Defina el tamaño de lote adecuado y el número de solicitudes por segundo.
Indexación anterior
Cuando los datos se indexan en el cluster, OpenSearch inicialmente los escribe en un archivo translog. A continuación, el proceso OpenSearch recoge entradas de este archivo a intervalos regulares para ingerir los datos en sus estructuras de Apache Lucene, creando segmentos adecuados con los objetos internos necesarios, como tokenizadores, datos de campo, etc. Las altas tasas de ingestión o un cluster poco configurado pueden provocar un retraso en el proceso de ingestión. Aquí, el tamaño del archivo translog crece junto con el retraso en la indexación de documentos. Puede supervisar este comportamiento mediante las estadísticas de indexación.
Utilice la siguiente configuración para supervisar la demora de índices:
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "UncommittedSize large",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "NODES_STATS",
"path": "_nodes/stats",
"path_params": "",
"url": "http://localhost:9200/_nodes/stats",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "4Ulmw5YBqFMdxmRCWBL3",
"name": "Uncommited size",
"severity": "1",
"condition": {
"script": {
"source": "for (entry in ctx.results[0].nodes.entrySet())\n{ if (entry.getValue().indices.translog.uncommitted_size_in_bytes>1000000000) { \n return true;\n }\n}\nreturn false;",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
],
"delete_query_index_in_every_run": false,
"owner": "alerting"
}Solución de problemas
Al solucionar problemas de indexación con retraso, realice las siguientes tareas:
- Revisar la presión de indexación.
- Revise el resto de las estadísticas de nodo, como CPU, memoria y estadísticas de E/S de disco.
Considere las siguientes opciones en función de los resultados de las tareas anteriores:
- Reducir la presión de indexación.
- Aumente la configuración de los nodos.
- Aumente el valor refresh_interval si el translog no es demasiado alto.
Limitación
OpenSearch almacena datos en forma de segmentos Lucene. Los segmentos se condensan y se fusionan continuamente para recopilar muchas operaciones en los mismos documentos. Cuando la velocidad de indexación necesaria es mayor que la que puede alojar el cluster OpenSearch, estas fusiones se limitan. Puede supervisar la limitación mediante estadísticas de indexación y actualizar el umbral de limitación para cumplir sus requisitos.
Utilice la siguiente configuración para configurar la limitación:
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "Merge Throttling",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "NODES_STATS",
"path": "_nodes/stats",
"path_params": "",
"url": "http://localhost:9200/_nodes/stats",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"name": "Merge Throttling",
"severity": "1",
"condition": {
"script": {
"source": "for (entry in ctx.results[0].nodes.entrySet())\n{ if (entry.getValue().indices.merges.total_throttled_time_in_millis>300000) { \n return true;\n }\n}\nreturn false;",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
],
"delete_query_index_in_every_run": false,
"owner": "alerting"
}
Solución de problemas
Al solucionar problemas de limitación, realice las siguientes tareas:
- Revisar la presión de indexación.
- Revise el resto de las estadísticas de nodo, como CPU, memoria y estadísticas de E/S de disco.
Considere las siguientes opciones en función de los resultados de las tareas anteriores:
- Reducir la presión de indexación.
- Aumente la configuración de los nodos.
- Aumente el valor refresh_interval si el translog no es demasiado alto.
Buscar
Desplazamientos
La búsqueda con desplazamiento se utiliza cuando se esperan muchos resultados. Sin embargo, el uso de demasiados desplazamientos ocupa memoria en OpenSearch porque debe mantener el contexto, lo que lleva a un rendimiento deficiente. La alerta f se puede utilizar para mantener una pestaña en el número de desplazamientos constantemente abiertos.
Utilice la siguiente configuración para realizar un seguimiento del número de desplazamientos abiertos de forma consistente.
POST {{host}}/_plugins/_alerting/monitors/
{
"type": "monitor",
"schema_version": 0,
"name": "Large Number of Open Scrolls",
"monitor_type": "cluster_metrics_monitor",
"enabled": true,
"schedule": {
"period": {
"interval": 1,
"unit": "MINUTES"
}
},
"inputs": [
{
"uri": {
"api_type": "NODES_STATS",
"path": "_nodes/stats",
"path_params": "",
"url": "http://localhost:9200/_nodes/stats",
"clusters": []
}
}
],
"triggers": [
{
"query_level_trigger": {
"id": "4Ulmw5YBqFMdxmRCWBL3",
"name": "Open Scrolls",
"severity": "1",
"condition": {
"script": {
"source": "for (entry in ctx.results[0].nodes.entrySet())\n{ if (entry.getValue().indices.search.scroll_current>200) { \n return true;\n }\n}\nreturn false;",
"lang": "painless"
}
},
"actions": [
{
"id": "notification585623",
"name": "Notify test",
"destination_id": "0WZDw5YBwxP9poIbQC8c",
"message_template": {
"source": "Monitor {{ctx.monitor.name}} just entered alert status. Please investigate the issue.\n - Trigger: {{ctx.trigger.name}}\n - Severity: {{ctx.trigger.severity}}\n - Period start: {{ctx.periodStart}}\n - Period end: {{ctx.periodEnd}}",
"lang": "mustache"
},
"throttle_enabled": true,
"subject_template": {
"source": "Alerting Notification action",
"lang": "mustache"
},
"throttle": {
"value": 30,
"unit": "MINUTES"
}
}
]
}
}
],
"delete_query_index_in_every_run": false,
"owner": "alerting"
}