Consulta de tablas de Apache Iceberg con base de datos de IA autónoma en una infraestructura de Exadata dedicada
Autonomous AI Database admite la consulta de tablas de Apache Iceberg.
Nota: El soporte para consultar tablas de Apache Iceberg está disponible en Oracle Database 19c a partir de la versión 19.28 y en Oracle Database 26ai a partir de la versión 23.9.
Configuraciones Soportadas
Se admiten estas configuraciones específicas:
-
Mesa Iceberg en Amazon Web Services AWS:
-
Tablas de iceberg registradas en AWS Glue Data Catalog, creadas con Spark o Athena.
Para obtener más información, consulte Uso del conector AWS Glue para leer y escribir tablas de Apache Iceberg con transacciones ACID y realizar viajes en el tiempo y Uso de tablas Iceberg.
-
Las tablas Iceberg se almacenan en AWS S3 proporcionando directamente la URL para el archivo de metadatos raíz.
-
-
Tablas de Iceberg en Oracle Cloud Infrastructure (OCI) Object Storage:
-
Tablas de iceberg generadas con OCI Data Flow mediante un catálogo de Hadoop.
Para obtener más información, consulte Ejemplos de Oracle Data Flow y Uso de un catálogo de Hadoop.
-
Las tablas de Iceberg se almacenan en OCI Object Storage proporcionando directamente la URL para el archivo de metadatos raíz.
-
Restricciones
-
Tablas de Iceberg particionadas
Oracle no soporta tablas particionadas de Iceberg.
-
Actualizaciones a nivel de fila de tablas Iceberg
Oracle no admite la fusión en lectura para las actualizaciones de tablas Iceberg. Las consultas que encuentren archivos eliminados en los metadatos de Iceberg fallarán. Para obtener más información sobre la fusión en lectura, consulte Enum RowLevelOperationMode.
-
Evolución del Esquema
El esquema de las tablas externas de Oracle es fijo y refleja la versión del esquema de Iceberg en el momento de la creación de la tabla externa. Las consultas fallan si los metadatos de Iceberg apuntan a una versión de esquema diferente a la utilizada para crear la tabla Iceberg. Si el esquema Iceberg cambia después de crear la tabla externa, se recomienda volver a crear la tabla externa.
Conceptos relacionados con la consulta de tablas Iceberg de Apache
Una comprensión de los siguientes conceptos es útil para consultar tablas de Apache Iceberg.
Catálogo de Iceberg
El catálogo Iceberg es un servicio que gestiona los metadatos de la tabla, como las instantáneas de la tabla, el esquema de la tabla y la información de partición. Para consultar la última instantánea de una tabla Iceberg, los motores de consulta primero deben acceder al catálogo y obtener la ubicación del archivo de metadatos más reciente. Ya hay una serie de implementaciones de catálogos disponibles, incluidas AWS Glue, Hive, Nessie y Hadoop. La base de datos de IA autónoma admite el catálogo AWS Glue y la implementación de HadoopCatalog utilizada por Spark.
Para obtener más información, consulte Concurrencia optimista.
Archivos de metadatos
El archivo de metadatos es un documento JSON que realiza un seguimiento de las instantáneas de la tabla, el esquema de partición y la información del esquema. El archivo de metadatos es el punto de entrada a una jerarquía de listas de manifiestos y archivos de manifiesto. Los manifiestos realizan un seguimiento de los archivos de datos de la tabla junto con información que incluye estadísticas de particiones y columnas. Consulte la Especificación de tabla de Iceberg para obtener más información.
Transacciones
Iceberg admite actualizaciones a nivel de fila en las tablas mediante la función de copia en escritura o fusión en lectura. La copia en escritura genera nuevos archivos de datos que reflejan las filas actualizadas, mientras que la fusión en lectura genera nuevos "archivos de supresión" que se deben fusionar con los archivos de datos durante la lectura. Oracle soporta la copia en escritura. Las consultas sobre tablas de iceberg fallan si encuentran un archivo de eliminación. Para obtener más información, consulte RowLevelOperationMode.
Evolución del Esquema
Iceberg apoya la evolución del esquema. Los cambios de esquema se reflejan en los metadatos de Iceberg mediante un ID de esquema. Tenga en cuenta que las tablas externas de Oracle tienen un esquema fijo, determinado por la versión de esquema más actual en el momento de la creación de la tabla. Las consultas de Iceberg fallan cuando los metadatos consultados apuntan a una versión de esquema diferente a la utilizada en el momento de la creación de la tabla. Para obtener más información, consulte Evolución del esquema.
Partición
Iceberg admite opciones avanzadas de partición, como la partición oculta y la evolución de la partición, que se basan en el procesamiento/modificación de los metadatos de la tabla sin costosos cambios en el diseño de los datos.
Ejemplos: Consulta de tablas Apache Iceberg
En estos ejemplos se muestra cómo consultar tablas de Apache Iceberg en Amazon Web Services (AWS) y Oracle Cloud Infrastructure (OCI), mediante un catálogo de datos y el uso de URL directas para el archivo de manifiesto raíz.
Para obtener información detallada sobre la creación de tablas externas para Apache Iceberg, consulte Procedimiento CREATE_EXTERNAL_TABLE para Apache Iceberg.
Consulta de una tabla Iceberg en AWS mediante un catálogo de datos de pegamento
En este ejemplo, consultamos la tabla Iceberg iceberg_parquet_time_dim. 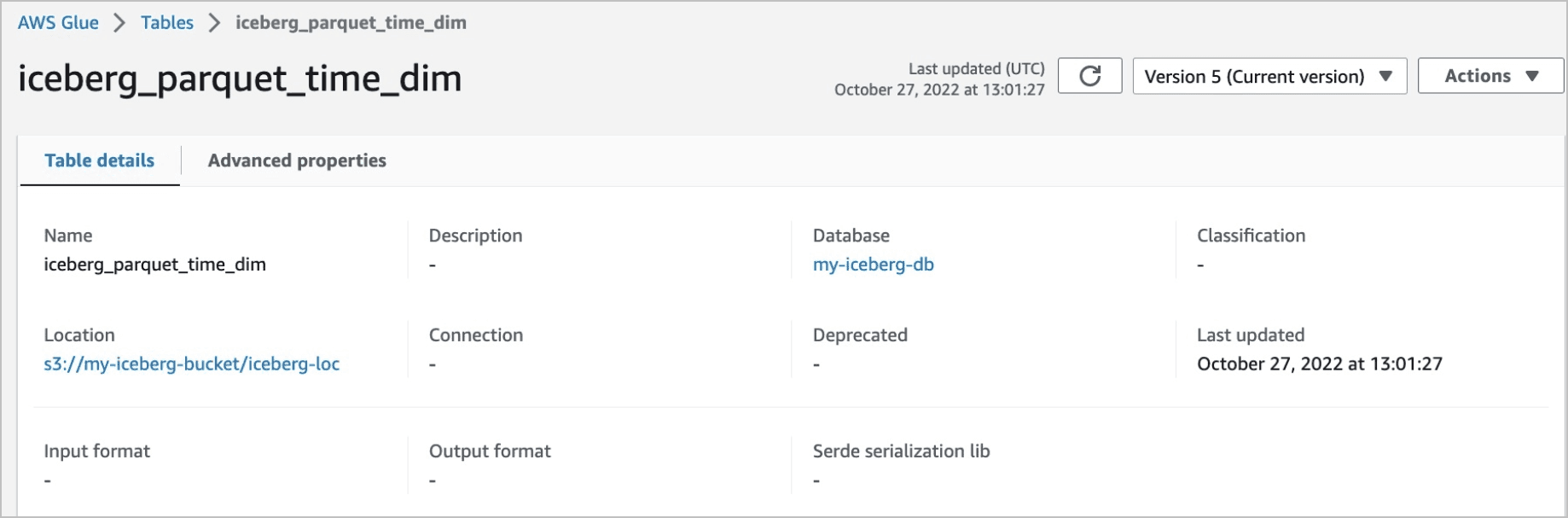
La tabla pertenece a la base de datos Glue my-iceberg-db y se almacena en la carpeta s3://my-iceberg-bucket/iceberg-loc.
Los detalles de la tabla para iceberg_parquet_time_dim se muestran aquí:
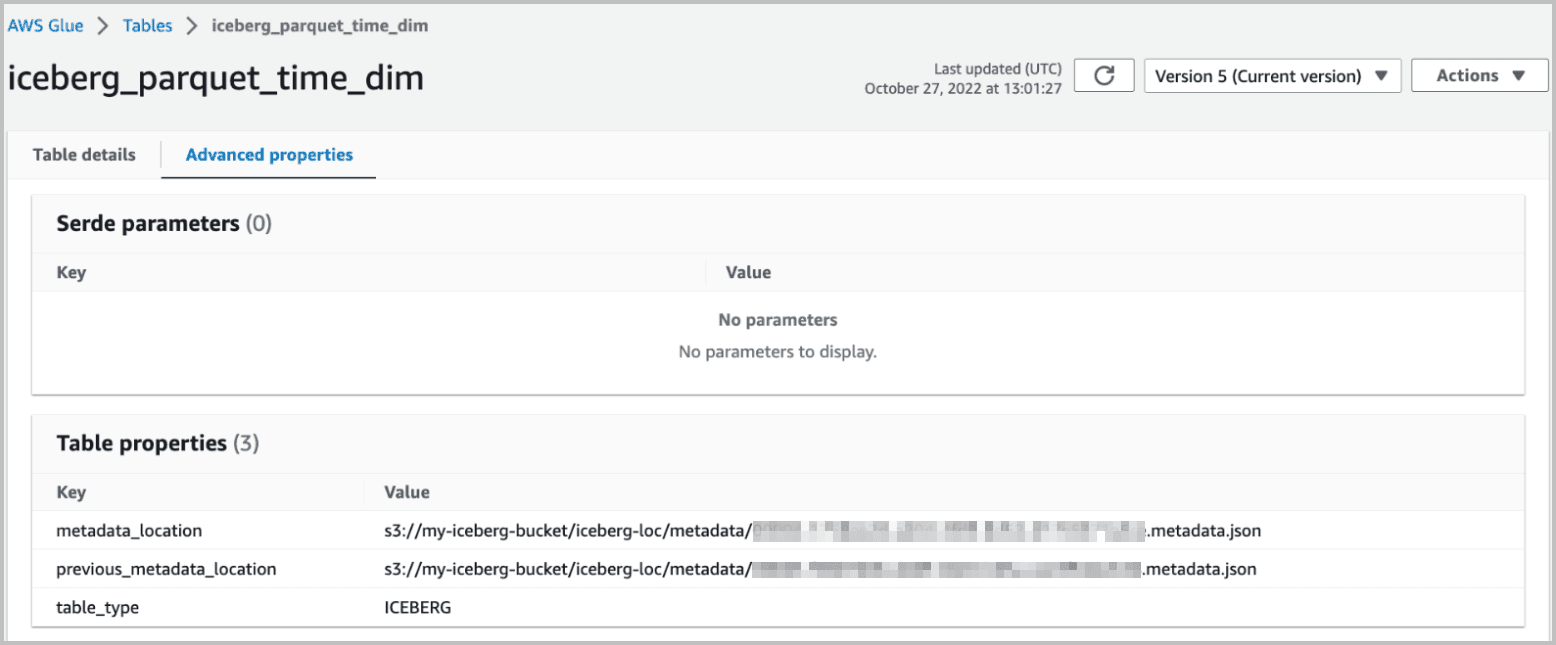
Descripción de la ilustración example_1_details_v1.png
Podemos crear una tabla externa para iceberg_parquet_time_dim de la siguiente manera:
BEGIN
DBMS_CLOUD.CREATE_EXTERNAL_TABLE (
table_name => 'iceberg_parquet_time_dim',
credential_name => 'AWS_CRED',
file_uri_list => '',
format =>
'{"access_protocol":
{
"protocol_type": "iceberg",
"protocol_config":
{
"iceberg_catalog_type": "aws_glue",
"iceberg_glue_region": "us-west-1",
"iceberg_table_path": "my-iceberg-db.iceberg_parquet_time_dim"
}
}
}'
);
END;
/En la sección protocol_config especificamos que la tabla utiliza AWS Glue como tipo de catálogo y establece la región del catálogo en us-west-1.
La credencial AWS_CRED se crea mediante dbms_cloud.create_credential con una clave de API de AWS. La instancia de Glue Data Catalog está determinada por el ID de cuenta asociado a AWS_CRED para la región us-west-1, ya que hay una única región de Glue Data Catalog para cada cuenta. El elemento iceberg_table_path de la sección protocol_config utiliza una ruta de acceso $database_name.$table_name para especificar el nombre de la tabla Glue y el nombre de la base de datos. Por último, los parámetros column_list y field_list quedan nulos porque el esquema de la tabla se deriva automáticamente de los metadatos de Iceberg.
Para obtener información adicional sobre la creación de la credencial, consulte Procedimiento CREATE_CREDENTIAL.
Para obtener información sobre los recursos de AWS Glue, consulte Especificación de ARN de recursos de AWS Glue.
Consulta de una tabla Iceberg en AWS mediante la ubicación del archivo de metadatos raíz
Si conocemos la ubicación del archivo de metadatos para una tabla Iceberg, podemos crear una tabla externa sin especificar un catálogo, de la siguiente manera:
BEGIN
DBMS_CLOUD.CREATE_EXTERNAL_TABLE (
table_name => 'iceberg_parquet_time_dim',
credential_name => 'AWS_CRED',
file_uri_list => 'https://my-iceberg-bucket.s3.us-west-1.amazonaws.com/iceberg-loc/metadata/00004-1758ee2d-a204-4fd9-8d52-d17e5371a5ce.metadata.json',
format =>'{"access_protocol":{"protocol_type":"iceberg"}}');
END;
/Utilizamos el parámetro file_uri_list para especificar la ubicación del archivo de metadatos en el formato de URL de estilo alojado virtual de AWS S3. Para obtener información sobre este formato, consulte Métodos para acceder a un cubo de AWS S3.
En este ejemplo, la base de datos accede al archivo de metadatos directamente, por lo que no es necesario proporcionar una sección protocol_config en el parámetro format. Cuando se utiliza la ubicación del archivo de metadatos para crear una tabla externa, la base de datos consulta la instantánea más reciente a la que hace referencia el archivo de metadatos. Las actualizaciones posteriores de la tabla Iceberg, que crean nuevas instantáneas y nuevos archivos de metadatos, no serán visibles para la base de datos.
Consulta de una tabla Iceberg que utiliza el catálogo de Hadoop en OCI
En este ejemplo, consultamos la tabla Iceberg icebergTablePy, creada mediante OCI Data Flow, donde Spark utiliza la implantación de HadoopCatalog para el catálogo Iceberg. HadoopCatalog utiliza un directorio warehouse y coloca los metadatos de Iceberg en una subcarpeta $database_name/$table_name en este directorio. También utiliza un archivo version-hint.text que contiene el número de versión de la versión más reciente del archivo de metadatos. Consulte Soporte de Iceberg en OCI Data Flow para ver el ejemplo de Github.
La tabla de ejemplo db.icebergTablePy se ha creado mediante una carpeta warehouse, denominada iceberg, en el cubo de OCI my-iceberg-bucket. El diseño de almacenamiento en OCI para la tabla icebergTablePy se muestra a continuación:
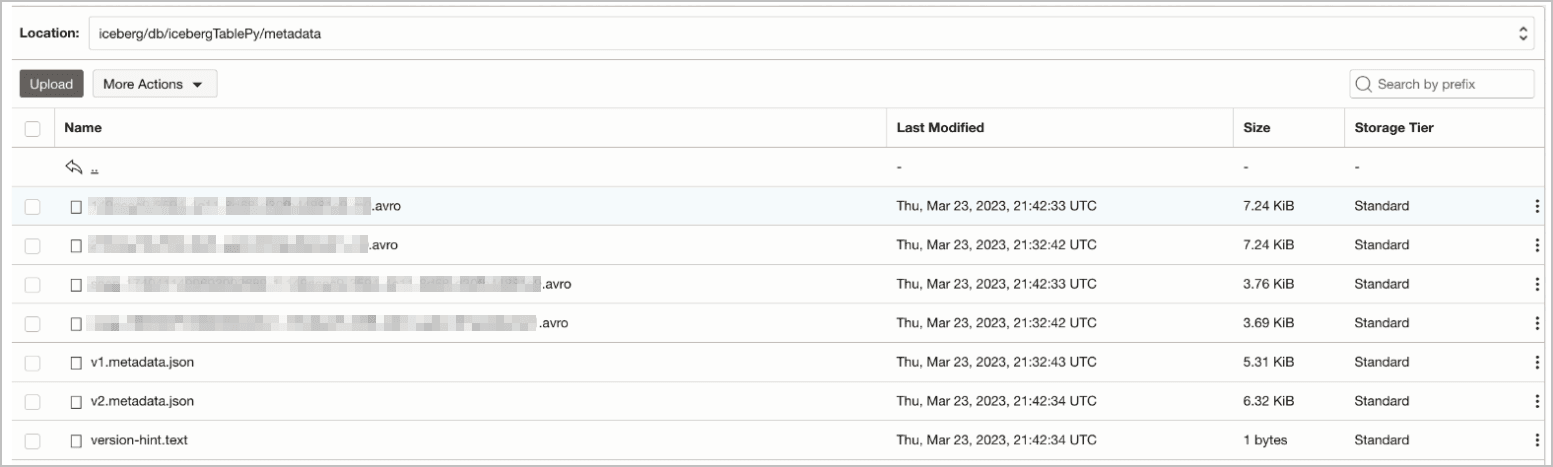
Descripción de la ilustración example_3_table_v1.png
Cree una tabla externa para la tabla db.icebergTablePy de la siguiente manera:
BEGIN
DBMS_CLOUD.CREATE_EXTERNAL_TABLE (
table_name => 'iceberg_parquet_time_dim3',
credential_name => 'OCI_CRED',
file_uri_list => '',
format =>'{"access_protocol":{"protocol_type":"iceberg",
"protocol_config":{"iceberg_catalog_type": "hadoop",
"iceberg_warehouse":"https://objectstorage.uk-cardiff-1.oraclecloud.com/n/my-tenancy/b/my-iceberg-bucket/o/iceberg",
"iceberg_table_path": "db.icebergTablePy"}}}');
END;
/Consulta de una tabla Iceberg en OCI mediante la ubicación del archivo de metadatos raíz
Podemos consultar la tabla Iceberg descrita en la sección anterior utilizando directamente la URL para el archivo de metadatos, de la siguiente manera:
BEGIN
DBMS_CLOUD.CREATE_EXTERNAL_TABLE (
table_name => 'iceberg_parquet_time_dim4',
credential_name => 'OCI_CRED',
file_uri_list => 'https://objectstorage.uk-cardiff-1.oraclecloud.com/n/my-tenancy/b/my-iceberg-bucket/o/iceberg/db/icebergTablePy/metadata/v2.metadata.json',
format =>'{"access_protocol":{"protocol_type":"iceberg"}}'
);
END;
/En este ejemplo, utilizamos el parámetro file_uri_list para especificar el URI para el archivo de metadatos mediante el formato nativo de URI de OCI. Al utilizar el URI del archivo de metadatos, la tabla externa siempre consulta la última instantánea almacenada en el archivo específico. Las actualizaciones posteriores que generan nuevas instantáneas y nuevos archivos de metadatos no son accesibles para la consulta.
Para obtener más información sobre el formato nativo de URI de OCI, consulte Formatos de URI de Cloud Object Storage.