Uso de OKE para mejorar la ubicación de los datos para la actividad de Cassandra y Spark
Introducción
Apache Cassandra es una base de datos distribuida sin maestro en la que cada nodo posee rangos de tokens. Apache Spark es un motor de recursos informáticos distribuido que puede utilizar el conector Spark-Cassandra para leer las réplicas de Cassandra. En Kubernetes, los pods se programan sin saber dónde se encuentran los datos, por lo que no se garantiza la localidad de los datos.
En este tutorial se muestra cómo OKE puede mejorar la localidad con los primitivos de Kubernetes: StatefulSets (identidad estable para Cassandra), etiquetas de nodo y afinidad/antiafinidad para coubicar ejecutores de Spark con los pods de Cassandra, de modo que las lecturas se sirven desde el mismo nodo (ideal) o, en el peor de los casos, un salto a la réplica en la misma ubicación.
Objetivos
- Despliegue un cluster y un bastión de OKE de 3 nodos (ORM o Terraform).
- Coloque Cassandra y Spark en dos nodos con etiquetas + afinidad.
- Ejecute y verifique un trabajo de lectura de Spark en Cassandra.
- Observe el tráfico entre nodos con los logs de flujo de VCN.
Requisitos
- Arrendamiento de OCI con permisos para VCN, OKE, Compute, Logging (logs de flujo); supervisión opcional.
- Par de claves SSH para acceso bastión.
- Conocimientos básicos de Kubernetes (nodos, etiquetas, pods, etc.).
Tarea 1: Despliegue del entorno con OCI Resource Manager (ORM) (recomendado).
-
Haga clic a continuación para abrir la pila en la consola de OCI:

-
Siga el flujo guiado para:
-
Acepte las condiciones de uso.
-
Inserte una clave SSH y seleccione el dominio de disponibilidad.
-
Puede dejar el resto de los valores por defecto para desplegar una VCN, un cluster de OKE y un bastión.
-
Inicie la pila.
-
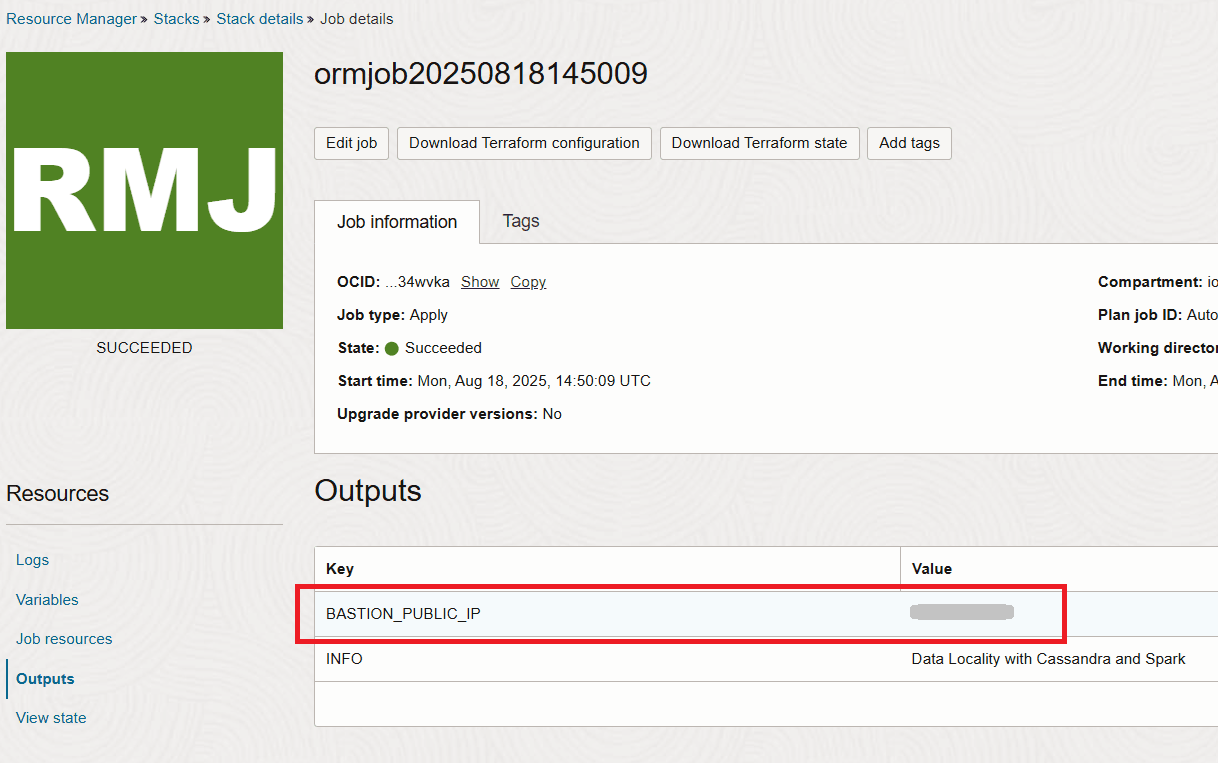
Cuando termine la pila, obtendrá la IP del bastión en la sección de salida.
Tarea 2: Conexión al bastión y verificación del despliegue
El aprovisionamiento inicial de infraestructura se completa en unos 15 minutos, pero la configuración completa (mediante cloud-init en el bastión) tarda unos 20 minutos más en instalar Helm, desplegar Cassandra y Spark y ejecutar el trabajo de lectura.
-
Para supervisar el proceso, utilice SSH en el bastión:
ssh -i <path-to-private-key> opc@<bastion_public_ip> -
Ejecute el siguiente comando para supervisar el progreso del script cloudinit.
tail -f /var/log/oke-automation.log -
La pila se completa cuando ve los 3 valores iniciales de Cassandra que se están leyendo y el mensaje Cloud-init complete.
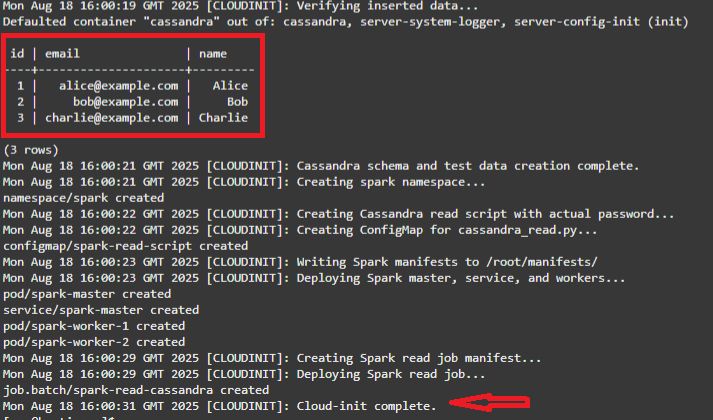
Nota: Lo que ha hecho el script cloudinit es lo siguiente:
- Instale kubectl, Helm, la CLI de OCI (principales de instancia), recupere kubeconfig.
- Esperar trabajadores
- Etiquete los dos primeros nodos con:
spark-locality=true, data-locality=enabled, and node-role=zone-a/zone-b - Instalar el gestor de certificados y el operador k8ssandra (CRD)
- Aplicar K8ssandraCluster
- Espera a Cassandra
- Crear testks.users e insertar 3 filas
- Cree el espacio de nombres de spark; cree ConfigMap con /scripts/cassandra_read.py (lee testks.users)
- Despliegue el maestro, el servicio y dos trabajadores de Spark (nodeSelector spark-locality: "true", worker anti-affinity)
- Enviar trabajo spark-read-cassandra
-
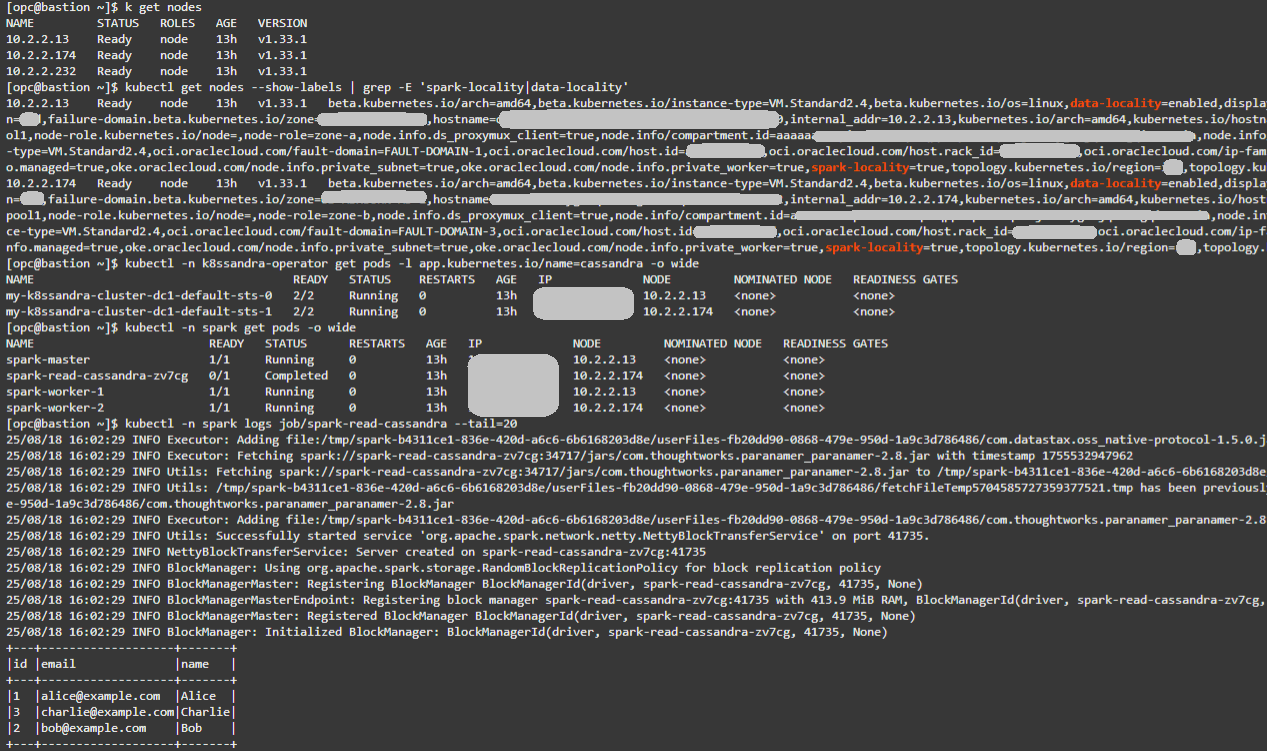
En la máquina virtual bastión, confirme los nodos existentes:
kubectl get nodes -
Confirmar etiquetas de localidad. Espere dos nodos con spark-locality=true y data-locality=enabled.
kubectl get nodes --show-labels | grep -E 'spark-locality|data-locality' -
Verifique la ubicación de Cassandra:
kubectl -n k8ssandra-operator get pods -l app.kubernetes.io/name=cassandra -o wide -
Verifique la ubicación de Spark:
kubectl -n spark get pods -o wide -
Compruebe los logs de trabajos de lectura de Spark. Debería ver los 3 registros de testks.users y una ejecución correcta.
kubectl -n spark logs job/spark-read-cassandra --tail=20
Consejo: la coincidencia de valores de NODE en los pods de Cassandra y Spark confirma la ubicación conjunta y las condiciones ideales para la localidad. Para obtener resultados de log de flujo más concluyentes, inserte filas adicionales en testks.users mediante cqlsh. Los conjuntos de datos más grandes generarán más tráfico de lectura, lo que facilitará la observación de los efectos de localidad frente a los de no localidad.
A continuación, puede ver una salida de ejemplo para los comandos anteriores:
Tarea 3: Observación de los efectos de red con logs de flujo de VCN
Utilice los logs de flujo de VCN para comprender dónde fluye el tráfico de Cassandra durante las lecturas de Spark. La automatización actual utiliza Flannel (VXLAN), que afecta lo que pueden ver los logs de flujo.
Lo que cambia con el CNI
- Flannel (VXLAN, este laboratorio):
- El tráfico de pod del mismo nodo permanece en el puente de host → no hay entrada de log de flujo de VCN.
- El tráfico de pod entre nodos se encapsula como UDP
(VXLAN). De manera predeterminada, Flannel utiliza el puerto 8472, pero si ese puerto no está disponible, puede seleccionar otro puerto UDP alto. El puerto exacto puede variar según el despliegue.
- Redes de pods nativos de VCN (NPN):
- Los pod obtienen IP de VCN y el tráfico se enruta en L3 sin superposición.
- Los logs de flujo muestran los puertos de aplicación reales (para Cassandra: TCP 9042).
-
Active los logs de flujo en la subred de trabajador.
En la consola de OCI, active los logs de flujo para la subred de trabajador de OKE. Vuelva a ejecutar (o espere) el trabajo de lectura de Spark para generar tráfico.
-
Logs de flujo de consulta (seleccione la ruta que coincide con el cluster)
Si utiliza esta automatización (Flannel/VXLAN): utilice una consulta avanzada similar a:
search "<your-flow-log-OCID>"
| where data.protocolName = 'UDP'
| where data.destinationPort = <vxlan-port>
Sustituya
- El tráfico de pod a pod se encapsula en UDP
entre IP de nodo de trabajador (en lugar del puerto 9042 de Cassandra). - Lecturas del mismo nodo: no hay ninguna entrada del log de flujo de VCN (el tráfico permanece local).
- Lecturas entre nodos: visibles como flujos UDP 14789 entre IP de nodos de trabajador en la siguiente imagen.
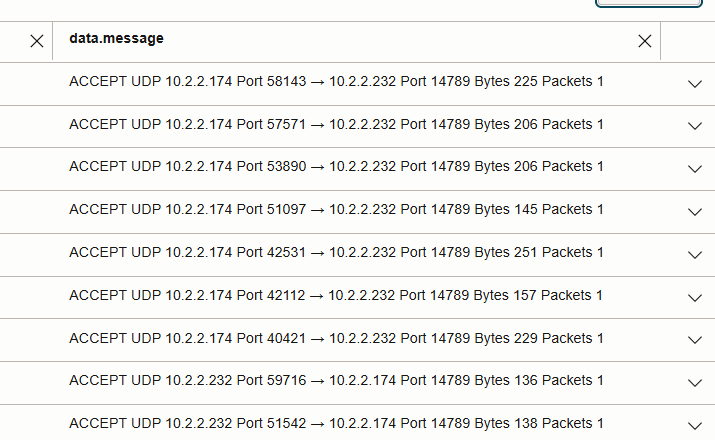
- Al comparar los recuentos de paquetes con UDP 14789, se resalta el efecto de la localidad de los datos frente a la no localidad.
Si el cluster utiliza NPN:
- Filtre directamente para TCP dstPort = 9042 entre IP de pod/worker.
- Debe ver las lecturas/escrituras de Cassandra CQL como flujos 9042. (idealmente muy poco)
Nota: Los logs de flujo pueden tardar unos minutos en ingerir nuevas entradas.
Consideraciones clave
-
Clusters con más de 3 nodos:
La localidad es más importante a medida que aumenta el tamaño del cluster. Sin reglas de colocación, los ejecutores de Spark pueden ejecutarse en nodos sin réplicas locales, lo que provoca muchas lecturas remotas. La ubicación conjunta garantiza que las lecturas sean locales o, en el peor de los casos, un solo salto a otra réplica.
- Beneficios de la coubicación:
- Lecturas locales de salto cero → latencia más baja.
- Menos lecturas entre nodos → uso de ancho de banda reducido y menor contención.
- Mayor rendimiento para trabajos de Spark que leen Cassandra en paralelo.
- Mecanismos utilizados en esta automatización:
- StatefulSets → identidades de pod de Cassandra estables.
- Las etiquetas de nodo (
spark-locality,data-locality) → designan nodos para la ubicación conjunta. - Afinidad de pod/antiafinidad → Ejecutores de Spark programados en nodos Cassandra, equilibrados entre ellos.
- K8ssandra Operador → despliegue y gestión declarativa de Cassandra.
- ConfigMap + trabajo de Spark → valida las lecturas de Cassandra y genera tráfico.
- Logs de flujo de VCN → observe y confirme los efectos de localidad.
- Fuera del alcance de OKE (factores de nivel de aplicación):
- Programación de tareas de Spark y asignación de particiones.
- Factor de replicación de Cassandra y nivel de consistencia.
- Lógica de conector Spark-Cassandra para seleccionar réplicas.
Enlaces relacionados
Proporcione enlaces a recursos adicionales. Esta sección es opcional; suprímala si no es necesario.
Acuses de recibo
- Autores: Adina Nicolescu (arquitecto principal de la nube)
Más recursos de aprendizaje
Explore otros laboratorios en docs.oracle.com/learn o acceda a más contenido de aprendizaje gratuito en el canal YouTube de Oracle Learning. Además, visite education.oracle.com/learning-explorer para convertirse en un explorador de Oracle Learning.
Para obtener documentación sobre el producto, visite Oracle Help Center.
Use OKE to Improve Data Locality for Cassandra and Spark Activity
G53297-01