À propos des pipelines de données sur une base de données d'IA autonome
Les pipelines de données Autonomous AI Database sont soit des pipelines de chargement, soit des pipelines d'exportation.
Les pipelines de chargement fournissent un chargement incrémentiel continu de données à partir de sources externes (à mesure que les données arrivent dans le magasin d'objets, elles sont chargées dans une table de base de données). Les pipelines d'exportation fournissent une exportation incrémentielle continue des données vers le magasin d'objets (à mesure que de nouvelles données apparaissent dans une table de base de données, elles sont exportées vers le magasin d'objets). Les pipelines utilisent le programmateur de base de données pour charger ou exporter en continu des données incrémentielles.
Les pipelines de données Autonomous AI Database fournissent les éléments suivants :
-
Opérations unifiées : Les pipelines vous permettent de charger ou d'exporter des données rapidement et facilement et de répéter ces opérations à intervalles réguliers pour obtenir de nouvelles données. L'ensemble
DBMS_CLOUD_PIPELINEfournit un jeu unifié de procédures PL/SQL pour la configuration du pipeline et pour la création et le démarrage d'une tâche programmée pour les opérations de chargement ou d'exportation. -
Traitement des données programmé : Les pipelines surveillent leur source de données et chargent ou exportent périodiquement les données à mesure que de nouvelles données arrivent.
-
Haute performance : Les pipelines ajustent les opérations de transfert de données en fonction des ressources disponibles sur votre base de données d'IA autonome. Les pipelines utilisent par défaut le parallélisme pour toutes les opérations de chargement ou d'exportation et sont ajustés en fonction des ressources d'UC disponibles dans votre base de données d'intelligence artificielle autonome ou d'un attribut de priorité configurable.
-
Atomicité et récupération : Les pipelines garantissent l'atomicité afin que les fichiers du magasin d'objets soient chargés exactement une fois pour un pipeline de chargement.
-
Surveillance et dépannage : Les pipelines fournissent des journaux et des tables de statut détaillés qui vous permettent de surveiller et de déboguer les opérations de pipeline.
-
Compatibilité multinuage : Les pipelines sur Autonomous AI Database prennent en charge le basculement facile entre les fournisseurs en nuage sans modification d'application. Les pipelines prennent en charge tous les formats d'URI de données d'identification et de magasin d'objets pris en charge par Autonomous AI Database (stockage d'objets Oracle Cloud Infrastructure Object Storage, Amazon S3, Azure Blob Storage, Google Cloud Storage et magasins d'objets compatibles avec Amazon S3).
Cycle de vie du pipeline de données
L'ensemble DBMS_CLOUD_PIPELINE fournit des procédures pour créer, configurer, tester et démarrer un pipeline. Le cycle de vie et les procédures du pipeline sont les mêmes pour les pipelines de chargement et d'exportation.
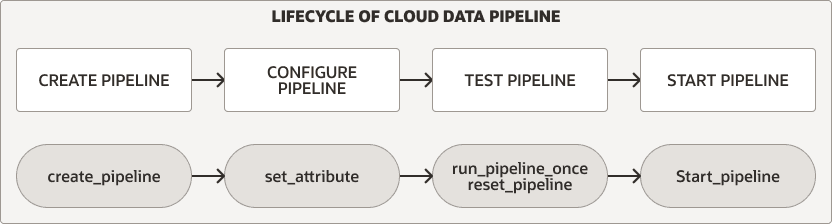
Description de l'illustration pipeline_lifecycle.png
Pour l'un ou l'autre type de pipeline, vous effectuez les étapes suivantes pour créer et utiliser un pipeline :
-
Créez et configurez le pipeline. Pour plus d'informations, voir Créer et configurer des pipelines.
-
Testez un nouveau pipeline. Pour plus d'informations, voir Tester les pipelines.
-
Démarrez un pipeline. Pour plus d'informations, voir Démarrer un pipeline.
En outre, vous pouvez surveiller, arrêter ou supprimer des pipelines :
-
Pendant qu'un pipeline est en cours d'exécution, pendant le test ou lors d'une utilisation régulière après le démarrage du pipeline, vous pouvez surveiller le pipeline. Pour plus d'informations, voir Surveiller et dépanner les pipelines.
-
Vous pouvez arrêter un pipeline et le redémarrer ultérieurement, ou supprimer un pipeline lorsque vous avez terminé d'utiliser le pipeline. Pour plus d'informations, voir Arrêter un pipeline et Supprimer un pipeline.
Charger les pipelines
Utilisez un pipeline de chargement pour le chargement incrémentiel continu de données à partir de fichiers externes dans le magasin d'objets dans une table de base de données. Un pipeline de chargement identifie périodiquement les nouveaux fichiers dans le magasin d'objets et charge les nouvelles données dans la table de base de données.
Un pipeline de chargement fonctionne comme suit (certaines de ces fonctions peuvent être configurées à l'aide des attributs de pipeline) :
-
Les fichiers du magasin d'objets sont chargés en parallèle dans une table de base de données.
-
Un pipeline de chargement utilise le nom du fichier de stockage d'objets pour identifier et charger de manière unique les fichiers plus récents.
-
Une fois qu'un fichier du magasin d'objets a été chargé dans la table de base de données, si le contenu du fichier change dans le magasin d'objets, il ne sera plus chargé.
-
Si le fichier de stockage d'objets est supprimé, cela n'a aucune incidence sur les données de la table de base de données.
-
-
En cas d'échec, un pipeline de chargement relance automatiquement l'opération. Des tentatives sont tentées à chaque exécution ultérieure de la tâche programmée du pipeline.
-
Dans les cas où les données d'un fichier ne sont pas conformes à la table de base de données, elles sont marquées comme
FAILEDet peuvent être vérifiées pour déboguer et résoudre le problème.- En cas d'échec du chargement d'un fichier, le pipeline ne s'arrête pas et continue de charger les autres fichiers.
-
Les pipelines de chargement prennent en charge plusieurs formats de fichier d'entrée, notamment JSON, CSV, XML, Avro, ORC et Parquet.

Description de l'illustration load-pipeline.svg
La migration à partir de bases de données non Oracle est un cas d'utilisation possible pour un pipeline de chargement. Lorsque vous devez migrer vos données d'une base de données non Oracle vers Oracle Autonomous AI Database sur une infrastructure Exadata dédiée, vous pouvez extraire les données et les charger dans Autonomous AI Database (le format Oracle Data Pump ne peut pas être utilisé pour les migrations à partir de bases de données non Oracle). En utilisant un format de fichier générique tel que CSV pour exporter des données à partir d'une base de données non Oracle, vous pouvez enregistrer vos données dans des fichiers et charger les fichiers dans le magasin d'objets. Créez ensuite un pipeline pour charger les données dans Autonomous AI Database. L'utilisation d'un pipeline de chargement pour charger un grand jeu de fichiers CSV offre des avantages importants tels que la tolérance aux pannes et les opérations de reprise et de nouvelle tentative. Pour une migration avec un jeu de données volumineux, vous pouvez créer plusieurs pipelines, un par table pour les fichiers de base de données non Oracle, afin de charger des données dans Autonomous AI Database.
Exporter les pipelines
Utilisez un pipeline d'exportation pour l'exportation incrémentielle continue des données de la base de données vers le magasin d'objets. Un pipeline d'exportation identifie périodiquement les données candidates et les charge dans le magasin d'objets.
Il existe trois options de pipeline d'exportation (les options d'exportation sont configurables à l'aide des attributs de pipeline) :
-
Exporter les résultats incrémentiels d'une interrogation vers le magasin d'objets à l'aide d'une colonne de date ou d'horodatage comme clé pour le suivi des données plus récentes.
-
Exporter les données incrémentielles d'une table vers le magasin d'objets à l'aide d'une colonne de date ou d'horodatage comme clé pour le suivi des données plus récentes.
-
Exportez les données d'une table vers un magasin d'objets à l'aide d'une interrogation pour sélectionner des données sans référence à une colonne de date ou d'horodatage (de sorte que le pipeline exporte toutes les données sélectionnées par l'interrogation pour chaque exécution du programmateur).
Les pipelines d'exportation ont les fonctions suivantes (certains d'entre eux sont configurables à l'aide des attributs de pipeline) :
-
Les résultats sont exportés en parallèle vers le magasin d'objets.
-
En cas d'échec, une tâche de pipeline suivante répète l'opération d'exportation.
-
Les pipelines d'exportation prennent en charge plusieurs formats de fichier d'exportation, notamment CSV, JSON, Parquet ou XML.
Pipelines gérés par Oracle
La base de données autonome avec intelligence artificielle sur une infrastructure Exadata dédiée fournit des pipelines intégrés pour exporter des journaux spécifiques vers un magasin d'objets au format JSON. Ces pipelines sont préconfigurés et sont démarrés et détenus par l'utilisateur ADMIN.
Les pipelines gérés par Oracle sont les suivants :
-
ORA$AUDIT_EXPORT: Ce pipeline exporte les journaux de vérification de base de données vers le magasin d'objets au format JSON et s'exécute toutes les 15 minutes après le démarrage du pipeline (en fonction de la valeur de l'attributinterval). -
ORA$APEX_ACTIVITY_EXPORT: Ce pipeline exporte le journal d'activité de l'espace de travail Oracle APEX vers le magasin d'objets au format JSON. Ce pipeline est préconfiguré avec l'interrogation SQL pour extraire les enregistrements d'activité APEX et s'exécute toutes les 15 minutes après le démarrage du pipeline (en fonction de la valeur de l'attributinterval).
Pour configurer et démarrer un pipeline géré par Oracle :
-
Déterminez le pipeline géré Oracle à utiliser :
ORA$AUDIT_EXPORTouORA$APEX_ACTIVITY_EXPORT. -
Définissez les attributs
credential_nameetlocation.Note :
credential_nameest une valeur obligatoire dans une base de données d'intelligence artificielle autonome sur une infrastructure Exadata dédiée.Par exemple :
BEGIN DBMS_CLOUD_PIPELINE.SET_ATTRIBUTE( pipeline_name => 'ORA$AUDIT_EXPORT', attribute_name => 'credential_name', attribute_value => 'DEF_CRED_OBJ_STORE' ); DBMS_CLOUD_PIPELINE.SET_ATTRIBUTE( pipeline_name => 'ORA$AUDIT_EXPORT', attribute_name => 'location', attribute_value => 'https://objectstorage.us-phoenix-1.oraclecloud.com/n/namespace-string/b/bucketname/o/' ); END; /Les données de journal de la base de données sont exportées vers l'emplacement de magasin d'objets que vous spécifiez.
Voir SET_ATTRIBUTE pour plus d'informations.
-
Facultativement, définissez les attributs
interval,formatoupriority.Voir SET_ATTRIBUTE pour plus d'informations.
-
Démarrez le pipeline.
Voir START_PIPELINE pour plus d'informations.