Dans Spark, la connectivité du stockage d'objets est utilisée pour effectuer des interrogations sur une base de données hébergée dans le stockage d'objets à l'aide de spark-sql, spark-shell, spark-submit, etc.
Préalables :
- L'utilisateur Hadoop dans la grappe doit faire partie du groupe Spark.
Sous Linux :
id bdsuser
uid=54330(bdsuser) gid=54339(superbdsgroup) groups=54339(superbdsgroup,985(hadoop),984(hdfs),980(hive),977(spark)
Dans Ranger :

Dans Ranger, accédez à l'onglet Users et vérifiez dans la colonne Groups que l'utilisateur fait partie du groupe Spark.
- Les utilisateurs Spark et Hadoop doivent être ajoutés aux politiques suivantes dans Ranger.
tag.download.auth.userspolicies.download.auth.users
Pour vérifier, dans l'interface utilisateur de Ranger, sélectionnez Gestionnaire d'accès > Politiques basées sur les ressources, puis sélectionnez le bouton Modifier pour l'instance Spark. La fenêtre Propriétés de configuration s'affiche.
Exemple :
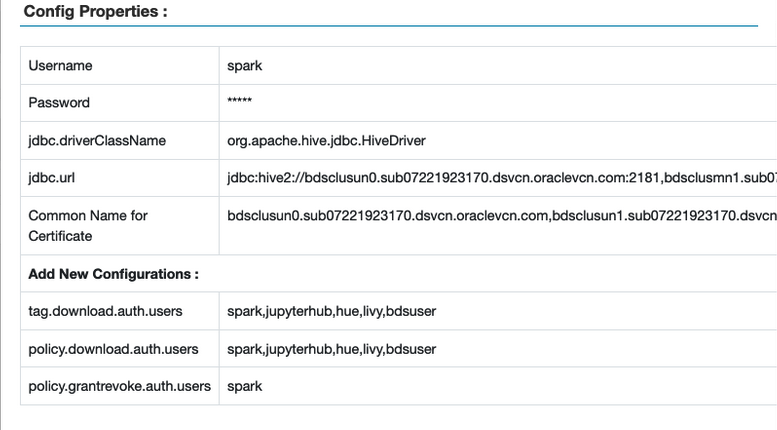
- Assurez-vous que l'utilisateur Hadoop est ajouté à la politique
all - database, table, column pour fournir le privilège SELECT sur la base de données, la table et les colonnes. Pour vérifier :
- Dans l'interface utilisateur Ranger, sélectionnez Gestionnaire d'accès > Politiques basées sur les ressources, puis sélectionnez le référentiel SPARK3.
- Sélectionnez les politiques créées pour l'utilisateur.
- Sélectionnez all - database, table, colonne, puis Edit (Modifier).
- Dans la section Conditions d'autorisation, vérifiez que l'utilisateur Hadoop est répertorié, sinon, ajoutez-le.
Note
Vous pouvez utiliser les noeuds de grappe du service de mégadonnées pour la configuration du service et des exemples d'exécution. Pour utiliser un noeud d'arête, vous devez créer un noeud d'arête et vous y connecter.
- (Facultatif) Pour utiliser un noeud de périphérie de réseau pour configurer le stockage d'objets, créez d'abord un noeud de périphérie de réseau, puis connectez-vous au noeud. Copiez ensuite la clé d'API du noeud un0 vers le noeud de périphérie de réseau.
sudo dcli rsync -a <un0-hostname>:/opt/oracle/bds/.oci_oos/ /opt/oracle/bds/.oci_oos/
-
Créez un utilisateur disposant d'autorisations suffisantes et un fichier JCEKS avec la valeur de phrase secrète requise. Si vous créez un fichier JCEKS local, copiez-le sur tous les noeuds et modifiez les autorisations de l'utilisateur.
sudo dcli -f <location_of_jceks_file> -d <location_of_jceks_file>
sudo dcli chown <user>:<group> <location_of_jceks_file>
-
Ajoutez l'une des combinaisons
HADOOP_OPTS suivantes au profil bash de l'utilisateur.
Option 1 :
export HADOOP_OPTS="$HADOOP_OPTS -DOCI_SECRET_API_KEY_ALIAS=<api_key_alias>
-DBDS_OSS_CLIENT_REGION=<api_key_region> -DOCI_SECRET_API_KEY_PASSPHRASE=<jceks_file_provider>"
Option 2 :
export HADOOP_OPTS="$HADOOP_OPTS -DBDS_OSS_CLIENT_AUTH_FINGERPRINT=<api_key_fingerprint>
-DBDS_OSS_CLIENT_AUTH_PASSPHRASE=<jceks_file_provider> -DBDS_OSS_CLIENT_AUTH_PEMFILEPATH=<api_key_pem_file_path>
-DBDS_OSS_CLIENT_AUTH_TENANTID=<api_key_tenant_id> -DBDS_OSS_CLIENT_AUTH_USERID=<api_key_user_id> -DBDS_OSS_CLIENT_REGION=<api_key_region>"
-
Dans Ambari, ajoutez les options Hadoop au modèle ruche-env pour l'accès au stockage d'objets.
-
Accédez à Apache Ambari.
-
Dans la barre d'outils latérale, sous Services, sélectionnez Hive.
-
Sélectionnez Configs.
-
Sélectionnez Avancé.
-
Dans la section Performance, allez à Hive-env avancé.
-
Allez au modèle ruche-env, puis ajoutez l'une des options suivantes sous la ligne
if [ "$SERVICE" = "metastore" ]; then.
Option 1 :
export HADOOP_OPTS="$HADOOP_OPTS -DOCI_SECRET_API_KEY_ALIAS=<api_key_alias>
-DBDS_OSS_CLIENT_REGION=<api_key_region>
-DOCI_SECRET_API_KEY_PASSPHRASE=<jceks_file_provider>"
Option 2 :
export HADOOP_OPTS="$HADOOP_OPTS -DBDS_OSS_CLIENT_AUTH_FINGERPRINT=<api_key_fingerprint>
-DBDS_OSS_CLIENT_AUTH_PASSPHRASE=<jceks_file_provider> -DBDS_OSS_CLIENT_AUTH_PEMFILEPATH=<api_key_pem_file_path>
-DBDS_OSS_CLIENT_AUTH_TENANTID=<api_key_tenant_id> -DBDS_OSS_CLIENT_AUTH_USERID=<api_key_user_id>
-DBDS_OSS_CLIENT_REGION=<api_key_region>"
-
Redémarrez tous les services requis via Ambari.
-
Exécutez l'une des commandes suivantes pour lancer l'interpréteur de commandes spark SQL :
Exemple 1 :
spark-sql --conf spark.driver.extraJavaOptions="${HADOOP_OPTS}" --conf spark.executor.extraJavaOptions="${HADOOP_OPTS}"
Exemple 2 : Utilisation de l'alias de clé d'API et de la phrase secrète.
spark-sql --conf spark.hadoop.OCI_SECRET_API_KEY_PASSPHRASE=<api_key_passphrase>
--conf spark.hadoop.OCI_SECRET_API_KEY_ALIAS=<api_key_alias>
--conf spark.hadoop.BDS_OSS_CLIENT_REGION=<api_key_region>
Exemple 3 : Utilisation des paramètres de clé d'API du service IAM.
spark-sql --conf spark.hadoop.BDS_OSS_CLIENT_AUTH_USERID=<api_key_user_id>
--conf spark.hadoop.BDS_OSS_CLIENT_AUTH_TENANTID=<api_key_tenant_id>
--conf spark.hadoop.BDS_OSS_CLIENT_AUTH_FINGERPRINT=<api_key_fingerprint>
--conf spark.hadoop.BDS_OSS_CLIENT_AUTH_PEMFILEPATH=<api_key_pem_file_path>>
--conf spark.hadoop.BDS_OSS_CLIENT_REGION=<api_key_region> --conf spark.hadoop.BDS_OSS_CLIENT_AUTH_PASSPHRASE=<api_key_passphrase>
Note En cas de problème avec l'espace de tas Java, transmettez la mémoire du pilote et de l'exécuteur dans le cadre de Spark SQL. Par exemple.
--driver-memory 2g –executor-memory 4g. Exemple d'énoncé spark-sql :
spark-sql --conf spark.driver.extraJavaOptions="${HADOOP_OPTS}"
--conf spark.executor.extraJavaOptions="${HADOOP_OPTS}"
--driver-memory 2g --executor-memory 4g
-
Vérifiez la connectivité du service de stockage d'objets :
Exemple de table gérée :
CREATE DATABASE IF NOT EXISTS <database_name> LOCATION 'oci://<bucket-name>@<namespace>/';
USE <database_name>;
CREATE TABLE IF NOT EXISTS <table_name> (id int, name string) partitioned by (part int, part2 int) STORED AS parquet;
INSERT INTO <table_name> partition(part=1, part2=1) values (333, 'Object Storage Testing with Spark SQL Managed Table');
SELECT * from <table_name>;
Exemple de table externe :
CREATE DATABASE IF NOT EXISTS <database_name> LOCATION 'oci://<bucket-name>@<namespace>/';
USE <database_name>;
CREATE EXTERNAL TABLE IF NOT EXISTS <table_name> (id int, name string) partitioned by (part int, part2 int) STORED AS parquet LOCATION 'oci://<bucket-name>@<namespace>/';
INSERT INTO <table_name> partition(part=1, part2=1) values (999, 'Object Storage Testing with Spark SQL External Table');
SELECT * from <table_name>;
- (Facultatif) Utilisez
pyspark avec spark-submit avec le stockage d'objets.
Note
Créez la base de données et la table avant d'effectuer ces étapes.
-
Exécutez la commande suivante :
from pyspark.sql import SparkSession
import datetime
import random
import string
spark=SparkSession.builder.appName("object-storage-testing-spark-submit").config("spark.hadoop.OCI_SECRET_API_KEY_PASSPHRASE","<jceks-provider>").config("spark.hadoop.OCI_SECRET_API_KEY_ALIAS",
"<api_key_alias>").enableHiveSupport().getOrCreate()
execution_time = datetime.datetime.now().strftime("%m/%d/%Y, %H:%M:%S")
param1 = 12345
param2 = ''.join(random.choices(string.ascii_uppercase + string.digits, k = 8))
ins_query = "INSERT INTO <database_name>.<table_name> partition(part=1, part2=1) values ({},'{}')".format(param1,param2)
print("##################### Starting execution ##################" + execution_time)
print("query = " + ins_query)
spark.sql(ins_query).show()
spark.sql("select * from <database_name>.<table_name>").show()
print("##################### Execution finished #################")
-
Exécutez la commande suivante à partir de
/usr/lib/spark/bin :
./spark-submit --conf spark.driver.extraJavaOptions="${HADOOP_OPTS}" --conf spark.executor.extraJavaOptions="${HADOOP_OPTS}" <location_of_python_file>