Développer des applications de flux de données
Découvrez la bibliothèque , y compris les modèles d'application Spark réutilisables et la sécurité des applications. Découvrez également comment créer et voir des applications, modifier ou supprimer des applications et appliquer des arguments ou des paramètres.
- Lors de la création d'applications à l'aide de la console
- Sous Options avancées, spécifiez la durée en durée maximale d'exécution en minutes.
- Lors de la création d'applications à l'aide de l'interface de ligne de commande
- Transmettre l'option de ligne de commande de
--max-duration-in-minutes <number> - Lors de la création d'applications à l'aide de la trousse SDK
- Indiquez un argument facultatif
max_duration_in_minutes - Lors de la création d'applications à l'aide de l'API
- Définir l'argument facultatif
maxDurationInMinutes
Modèles d'applications Spark réutilisables
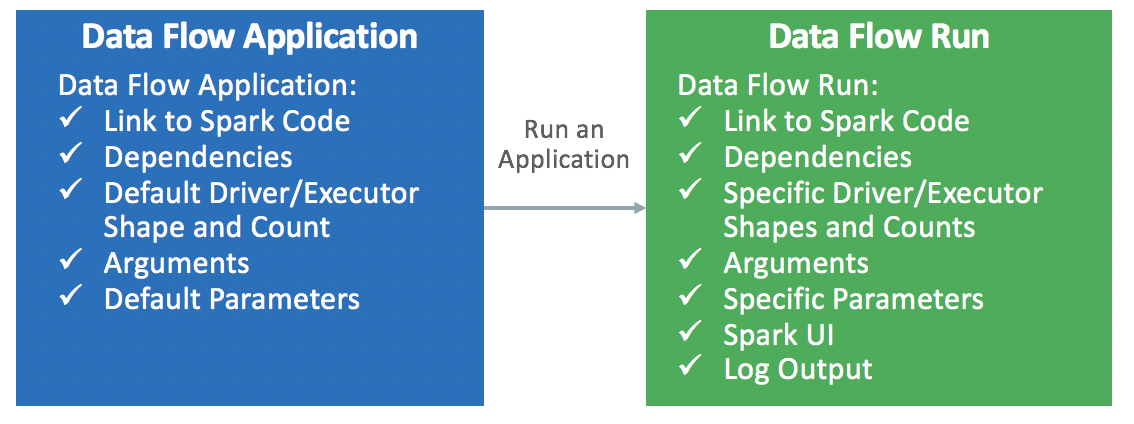
Une application est un modèle d'application Spark réutilisable à l'infini.
Les applications de flux de données comprennent une application Spark, ses dépendances, des paramètres par défaut et une ressource d'exécution par défaut. Après qu'un développeur Spark crée une application de flux de données, n'importe qui peut l'utiliser sans se soucier de la complexité du déploiement, de la configuration ou de l'exécution. Vous pouvez l'utiliser grâce aux analyses Spark dans des tableaux de bord personnalisés, des rapports, des scripts ou des appels d'API REST. 
Chaque fois que vous appelez l'application de flux de données, vous créez une exécution . Il alimente les détails du modèle d'application et le démarre sur un jeu de ressources IaaS spécifique.