Aperçu du service de flux de données
Découvrez le service de flux de données et voyez comment l'utiliser pour créer, partager, exécuter des applications Apache Spark et en voir la sortie en toute facilité.
Qu'est-ce qu'Oracle Cloud Infrastructure Data Flow
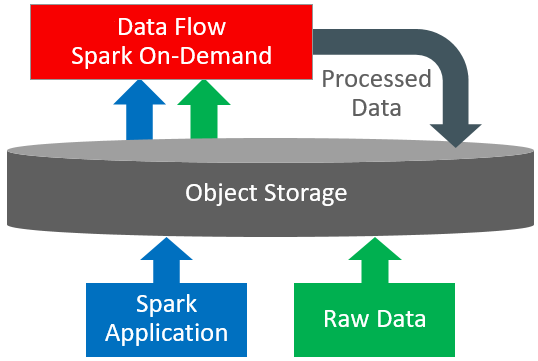
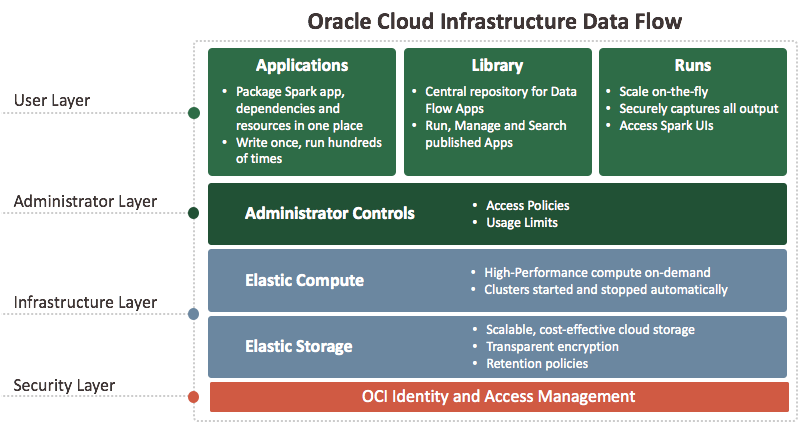
Data Flow est une plate-forme sans serveur en nuage avec une interface utilisateur enrichie. Il permet aux développeurs Spark et aux spécialistes des données de créer, de modifier et d'exécuter des tâches Spark, quelle que soit l'échelle, sans grappes, équipe d'exploitation ni connaissances hautement spécialisées sur Spark. Sans serveur signifie qu'il n'y a aucune infrastructure à déployer ou à gérer. Le service est entièrement piloté par des API REST et permet ainsi une intégration facile à des applications ou des flux de travail. Vous pouvez contrôler le service de flux de données à l'aide de cette API REST. Vous pouvez exécuter le service de flux de données à partir de l'interface de ligne de commande, car les commandes du service de flux de données sont disponibles dans l'interface de ligne de commande d'Oracle Cloud Infrastructure. Vous pouvez :
-
Établir des connexions à des sources de données Apache Spark.
-
Créer des applications Apache Spark réutilisables
-
Lancez rapidement des tâches Apache Spark.
-
Créer des applications Apache Spark en SQL, Python, Java ou Scala ou spark-submit.
-
Gérer toutes les applications Apache Spark à partir d'une seule plate-forme.
-
Traiter les données dans le nuage ou sur place dans votre centre de données.
-
Créer des blocs de mégadonnées pouvant être assemblés facilement dans des applications de mégadonnées avancées.