Utilisation de carnets pour la connexion au service de flux de données
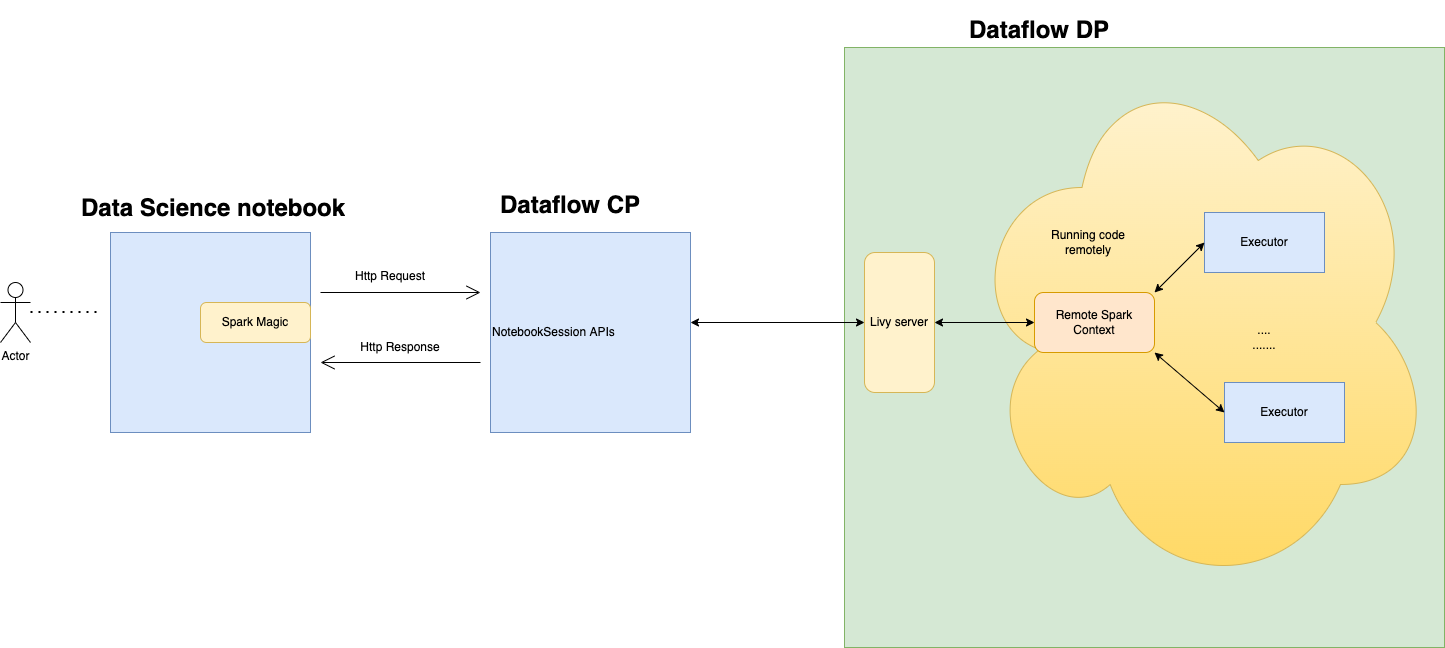
Vous pouvez vous connecter au service de flux de données et exécuter une application Apache Spark à partir d'une session de carnet du service de science des données. Ces sessions vous permettent d'exécuter des charges de travail Spark interactives sur une grappe de flux de données de longue durée au moyen d'une intégration Apache Livy.
Le service de flux de données utilise des carnets Jupyter entièrement gérés pour permettre aux experts en science des données et aux ingénieurs de données de créer, de visualiser, de collaborer et de déboguer des applications d'ingénierie des données et de science des données. Vous pouvez écrire ces applications en Python, Scala et PySpark. Vous pouvez également connecter une session de carnet du service de science des données au service de flux de données pour exécuter des applications. Les noyaux et les applications du service de flux de données s'exécutent sur Oracle Cloud Infrastructure Data Flow. Le service de flux de données est un service Apache Spark entièrement géré qui effectue des tâches de traitement sur des jeux de données extrêmement grands, sans avoir à déployer ou gérer l'infrastructure. Pour plus d'informations, consultez la documentation sur le service de flux de données.
Apache Spark est un système de calcul distribué conçu pour traiter des données à grande échelle. Il prend en charge les traitements SQL, par lots et de flux de données, ainsi que les tâches d'apprentissage automatique à grande échelle. Spark SQL offre une prise en charge de type base de données. Pour interroger des données structurées, utilisez Spark SQL. Il s'agit d'une mise en oeuvre SQL standard ANSI.
Le service de flux de données est un service Apache Spark entièrement géré qui effectue des tâches de traitement sur des jeux de données extrêmement grands, sans infrastructure à déployer ou gérer. Vous pouvez utiliser le service de diffusion en continu Spark pour effectuer une extraction, une transformation et un chargement en nuage sur vos données produites en continu. Il permet une livraison rapide des applications, car vous pouvez vous concentrer sur le développement, et non sur la gestion de l'infrastructure.
Apache Livy est une interface REST vers Spark. Soumettez des tâches Spark tolérantes aux pannes à partir du carnet en utilisant des méthodes synchrones et asynchrones pour extraire la sortie.
SparkMagic permet une communication interactive avec Spark à l'aide de Livy. Utilisez la directive magique %%spark dans une cellule de code JupyterLab. Les commandes SparkMagic sont disponibles pour Spark 3.2.1 et l'environnement Conda du service de flux de données.
Les sessions du service de flux de données prennent en charge l'ajustement automatique des capacités des grappes du service de flux de données. Pour plus d'informations, voir Ajustement automatique dans la documentation sur le service de flux de données. Les sessions du service de flux de données prennent en charge l'utilisation d'environnements Conda en tant qu'environnements d'exécution Spark personnalisables.
- Limitations
-
-
Les sessions du service de flux de données durent jusqu'à 7 jours ou 10 080 minutes (maxDurationInMinutes).
- Les sessions du service de flux de données ont une valeur de délai d'attente par défaut de 480 minutes (8 heures) (idleTimeoutInMinutes). Vous pouvez configurer une valeur différente.
- La session du service de flux de données est disponible uniquement par l'intermédiaire d'une session de carnet du service de science des données.
- Seule la version Spark 3.2.1 est prise en charge.
-
Regardez la vidéo du tutoriel sur l'utilisation du service de science des données avec le service de flux de données. Consultez également la documentation sur la trousse SDK Oracle Accelerated Data Science pour plus d'informations sur l'intégration des services de science des données et de flux de données.